 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
An Image-based Generator Architecture for Synthetic Image Refinement
Aug 10, 2021
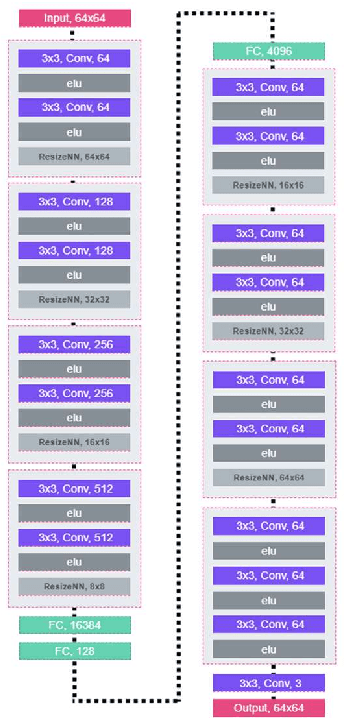
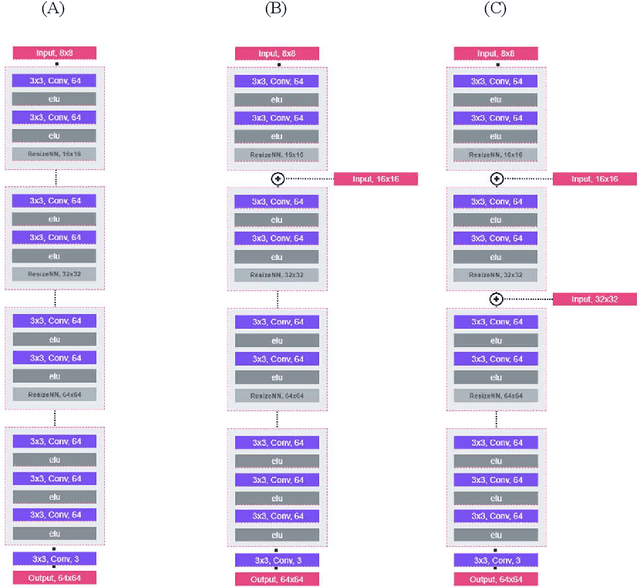

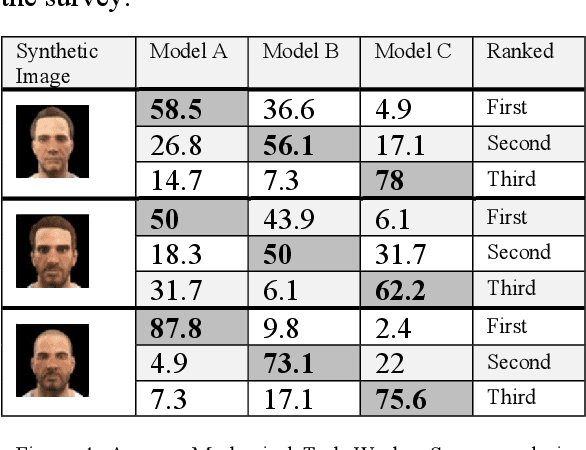
Proposed are alternative generator architectures for Boundary Equilibrium Generative Adversarial Networks, motivated by Learning from Simulated and Unsupervised Images through Adversarial Training. It disentangles the need for a noise-based latent space. The generator will operate mainly as a refiner network to gain a photo-realistic presentation of the given synthetic images. It also attempts to resolve the latent space's poorly understood properties by eliminating the need for noise injection and replacing it with an image-based concept. The new flexible and simple generator architecture will also give the power to control the trade-off between restrictive refinement and expressiveness ability. Contrary to other available methods, this architecture will not require a paired or unpaired dataset of real and synthetic images for the training phase. Only a relatively small set of real images would suffice.
Alleviating the Transit Timing Variations bias in transit surveys. II. RIVERS: Twin resonant Earth-sized planets around Kepler-1972 recovered from Kepler's false positive
Jan 27, 2022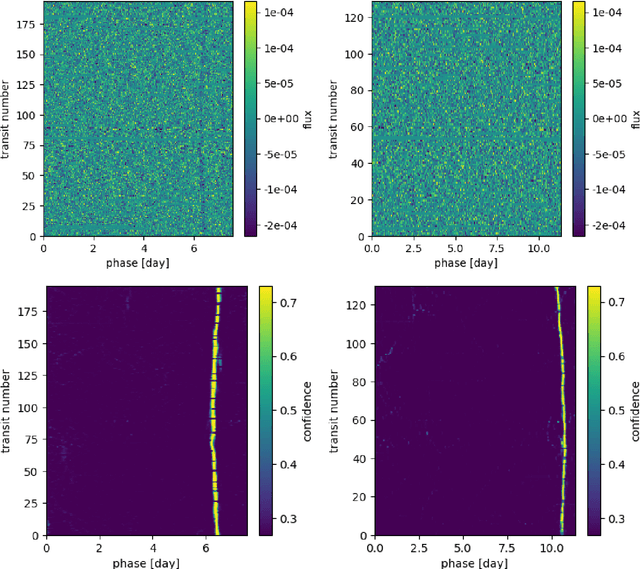
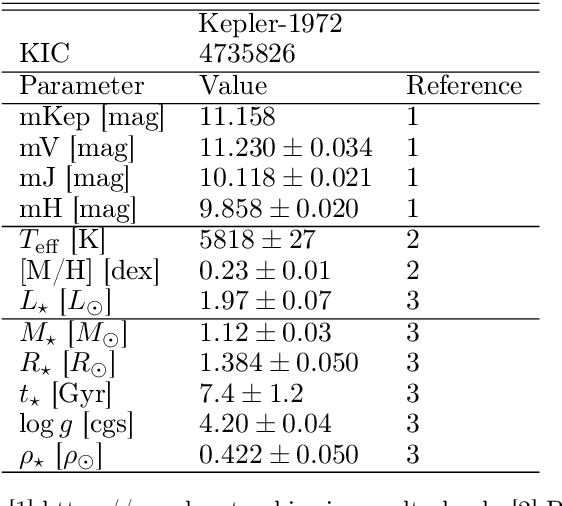
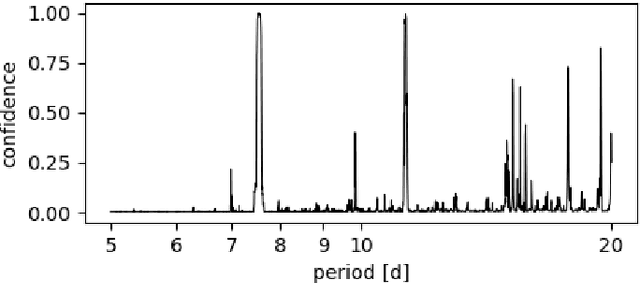
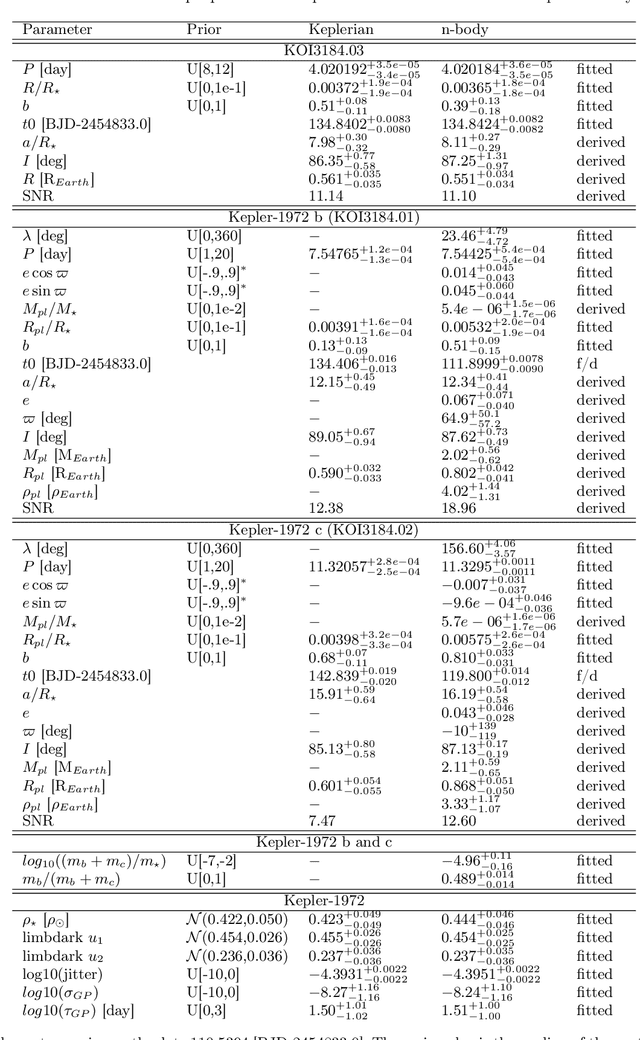
Transit Timing Variations (TTVs) can provide useful information for systems observed by transit, by putting constraints on the masses and eccentricities of the observed planets, or even constrain the existence of non-transiting companions. However, TTVs can also prevent the detection of small planets in transit surveys, or bias the recovered planetary and transit parameters. Here we show that Kepler-1972 c, initially the "not transit-like" false positive KOI-3184.02, is an Earth-sized planet whose orbit is perturbed by Kepler-1972 b (initially KOI-3184.01). The pair is locked in a 3:2 Mean-motion resonance, each planet displaying TTVs of more than 6h hours of amplitude over the duration of the Kepler mission. The two planets have similar masses $m_b/m_c =0.956_{-0.051}^{+0.056}$ and radii $R_b=0.802_{-0.041}^{+0.042}R_{Earth}$, $R_c=0.868_{-0.050}^{+0.051}R_{Earth}$, and the whole system, including the inner candidate KOI-3184.03, appear to be coplanar. Despite the faintness of the signals (SNR of 1.35 for each transit of Kepler-1972 b and 1.10 for Kepler-1972 c), we recovered the transits of the planets using the RIVERS method, based on the recognition of the tracks of planets in river diagrams using machine learning, and a photo-dynamic fit of the lightcurve. Recovering the correct ephemerides of the planets is essential to have a complete picture of the observed planetary systems. In particular, we show that in Kepler-1972, not taking into account planet-planet interactions yields an error of $\sim 30\%$ on the radii of planets b and c, in addition to generating in-transit scatter, which leads to mistake KOI3184.02 for a false positive. Alleviating this bias is essential for an unbiased view of Kepler systems, some of the TESS stars, and the upcoming PLATO mission.
One-Shot Generative Domain Adaptation
Nov 18, 2021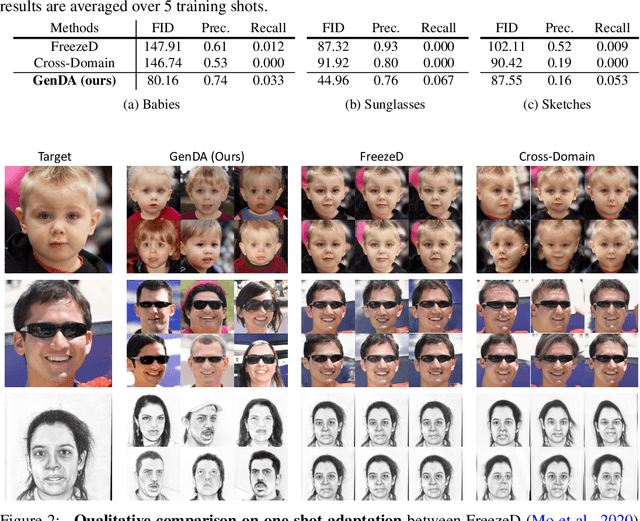
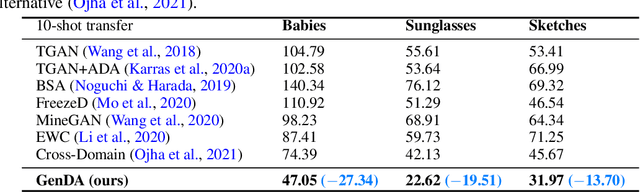


This work aims at transferring a Generative Adversarial Network (GAN) pre-trained on one image domain to a new domain referring to as few as just one target image. The main challenge is that, under limited supervision, it is extremely difficult to synthesize photo-realistic and highly diverse images, while acquiring representative characters of the target. Different from existing approaches that adopt the vanilla fine-tuning strategy, we import two lightweight modules to the generator and the discriminator respectively. Concretely, we introduce an attribute adaptor into the generator yet freeze its original parameters, through which it can reuse the prior knowledge to the most extent and hence maintain the synthesis quality and diversity. We then equip the well-learned discriminator backbone with an attribute classifier to ensure that the generator captures the appropriate characters from the reference. Furthermore, considering the poor diversity of the training data (i.e., as few as only one image), we propose to also constrain the diversity of the generative domain in the training process, alleviating the optimization difficulty. Our approach brings appealing results under various settings, substantially surpassing state-of-the-art alternatives, especially in terms of synthesis diversity. Noticeably, our method works well even with large domain gaps, and robustly converges within a few minutes for each experiment.
Learning Portrait Style Representations
Dec 08, 2020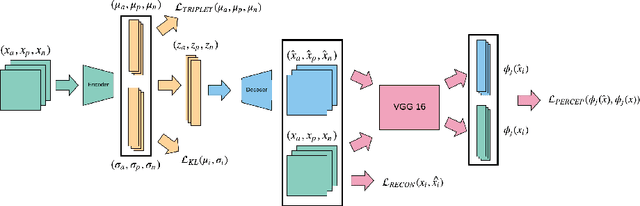

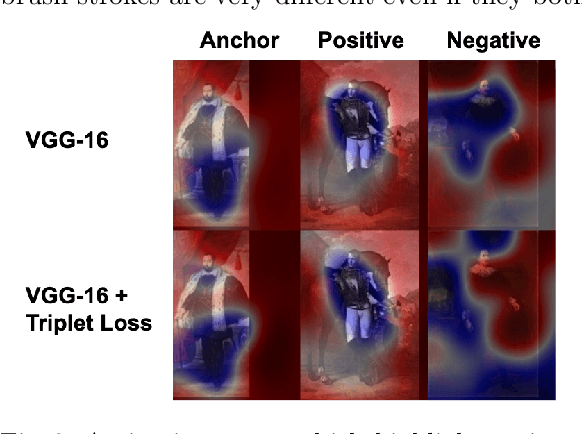

Style analysis of artwork in computer vision predominantly focuses on achieving results in target image generation through optimizing understanding of low level style characteristics such as brush strokes. However, fundamentally different techniques are required to computationally understand and control qualities of art which incorporate higher level style characteristics. We study style representations learned by neural network architectures incorporating these higher level characteristics. We find variation in learned style features from incorporating triplets annotated by art historians as supervision for style similarity. Networks leveraging statistical priors or pretrained on photo collections such as ImageNet can also derive useful visual representations of artwork. We align the impact of these expert human knowledge, statistical, and photo realism priors on style representations with art historical research and use these representations to perform zero-shot classification of artists. To facilitate this work, we also present the first large-scale dataset of portraits prepared for computational analysis.
FCA: Learning a 3D Full-coverage Vehicle Camouflage for Multi-view Physical Adversarial Attack
Sep 15, 2021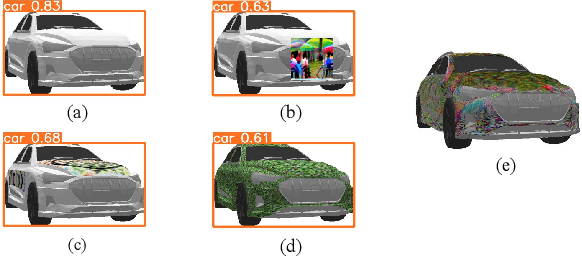

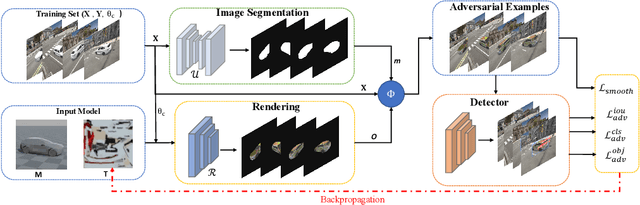
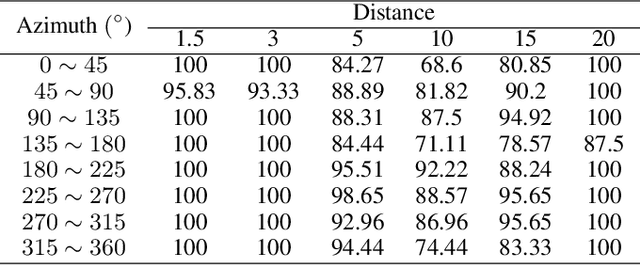
Physical adversarial attacks in object detection have attracted increasing attention. However, most previous works focus on hiding the objects from the detector by generating an individual adversarial patch, which only covers the planar part of the vehicle's surface and fails to attack the detector in physical scenarios for multi-view, long-distance and partially occluded objects. To bridge the gap between digital attacks and physical attacks, we exploit the full 3D vehicle surface to propose a robust Full-coverage Camouflage Attack (FCA) to fool detectors. Specifically, we first try rendering the non-planar camouflage texture over the full vehicle surface. To mimic the real-world environment conditions, we then introduce a transformation function to transfer the rendered camouflaged vehicle into a photo-realistic scenario. Finally, we design an efficient loss function to optimize the camouflage texture. Experiments show that the full-coverage camouflage attack can not only outperform state-of-the-art methods under various test cases but also generalize to different environments, vehicles, and object detectors.
StyleGAN-induced data-driven regularization for inverse problems
Oct 07, 2021
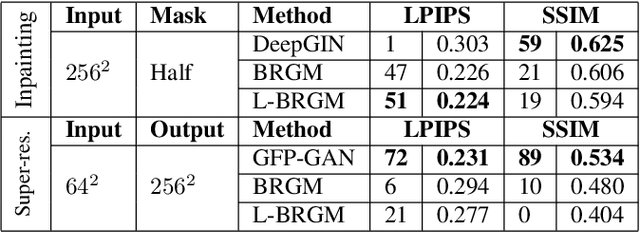

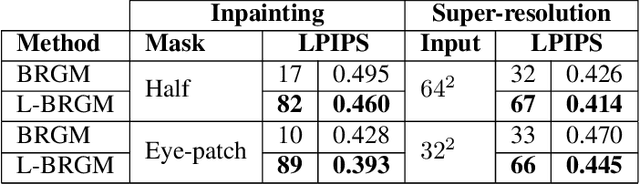
Recent advances in generative adversarial networks (GANs) have opened up the possibility of generating high-resolution photo-realistic images that were impossible to produce previously. The ability of GANs to sample from high-dimensional distributions has naturally motivated researchers to leverage their power for modeling the image prior in inverse problems. We extend this line of research by developing a Bayesian image reconstruction framework that utilizes the full potential of a pre-trained StyleGAN2 generator, which is the currently dominant GAN architecture, for constructing the prior distribution on the underlying image. Our proposed approach, which we refer to as learned Bayesian reconstruction with generative models (L-BRGM), entails joint optimization over the style-code and the input latent code, and enhances the expressive power of a pre-trained StyleGAN2 generator by allowing the style-codes to be different for different generator layers. Considering the inverse problems of image inpainting and super-resolution, we demonstrate that the proposed approach is competitive with, and sometimes superior to, state-of-the-art GAN-based image reconstruction methods.
Pose with Style: Detail-Preserving Pose-Guided Image Synthesis with Conditional StyleGAN
Sep 13, 2021
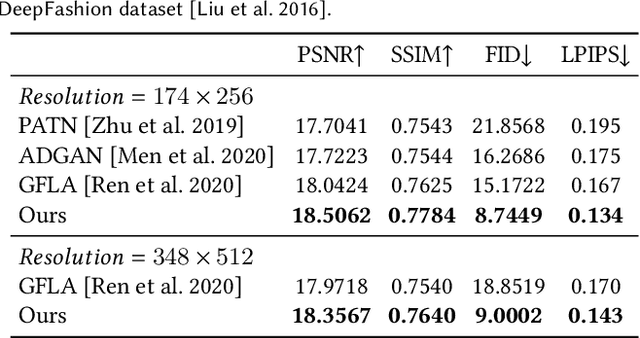


We present an algorithm for re-rendering a person from a single image under arbitrary poses. Existing methods often have difficulties in hallucinating occluded contents photo-realistically while preserving the identity and fine details in the source image. We first learn to inpaint the correspondence field between the body surface texture and the source image with a human body symmetry prior. The inpainted correspondence field allows us to transfer/warp local features extracted from the source to the target view even under large pose changes. Directly mapping the warped local features to an RGB image using a simple CNN decoder often leads to visible artifacts. Thus, we extend the StyleGAN generator so that it takes pose as input (for controlling poses) and introduces a spatially varying modulation for the latent space using the warped local features (for controlling appearances). We show that our method compares favorably against the state-of-the-art algorithms in both quantitative evaluation and visual comparison.
Modality-Aware Triplet Hard Mining for Zero-shot Sketch-Based Image Retrieval
Dec 16, 2021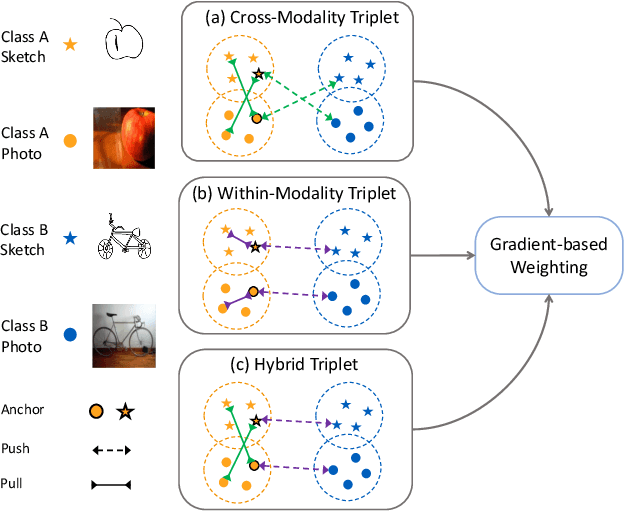
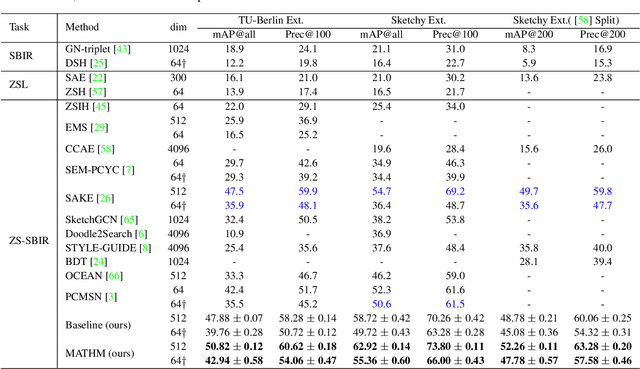
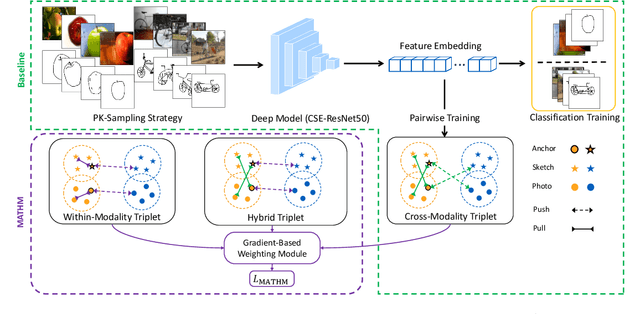

This paper tackles the Zero-Shot Sketch-Based Image Retrieval (ZS-SBIR) problem from the viewpoint of cross-modality metric learning. This task has two characteristics: 1) the zero-shot setting requires a metric space with good within-class compactness and the between-class discrepancy for recognizing the novel classes and 2) the sketch query and the photo gallery are in different modalities. The metric learning viewpoint benefits ZS-SBIR from two aspects. First, it facilitates improvement through recent good practices in deep metric learning (DML). By combining two fundamental learning approaches in DML, e.g., classification training and pairwise training, we set up a strong baseline for ZS-SBIR. Without bells and whistles, this baseline achieves competitive retrieval accuracy. Second, it provides an insight that properly suppressing the modality gap is critical. To this end, we design a novel method named Modality-Aware Triplet Hard Mining (MATHM). MATHM enhances the baseline with three types of pairwise learning, e.g., a cross-modality sample pair, a within-modality sample pair, and their combination.\We also design an adaptive weighting method to balance these three components during training dynamically. Experimental results confirm that MATHM brings another round of significant improvement based on the strong baseline and sets up new state-of-the-art performance. For example, on the TU-Berlin dataset, we achieve 47.88+2.94% mAP@all and 58.28+2.34% Prec@100. Code will be publicly available at: https://github.com/huangzongheng/MATHM.
Centimeter-Wave Free-Space Time-of-Flight Imaging
May 25, 2021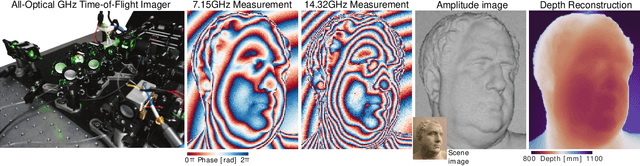
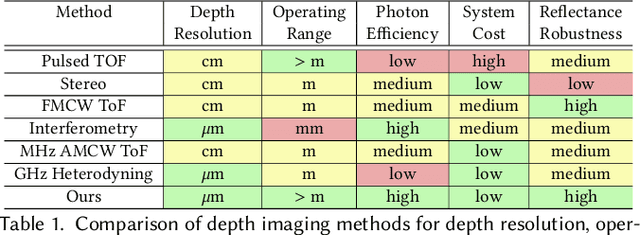
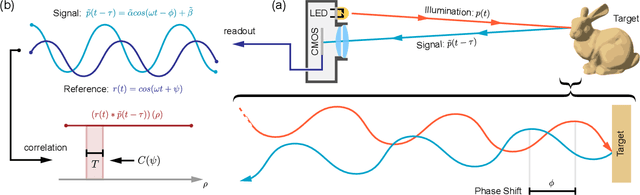
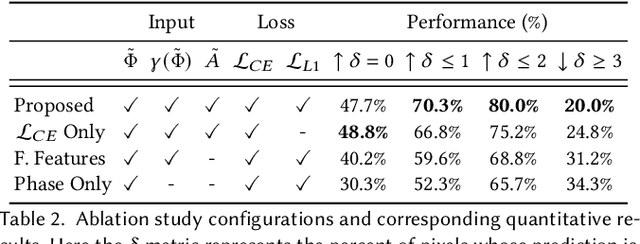
Depth cameras are emerging as a cornerstone modality with diverse applications that directly or indirectly rely on measured depth, including personal devices, robotics, and self-driving vehicles. Although time-of-flight (ToF) methods have fueled these applications, the precision and robustness of ToF methods is limited by relying on photon time-tagging or modulation after photo-conversion. Successful optical modulation approaches have been restricted fiber-coupled modulation with large coupling losses or interferometric modulation with sub-cm range, and the precision gap between interferometric methods and ToF methods is more than three orders of magnitudes. In this work, we close this gap and propose a computational imaging method for all-optical free-space correlation before photo-conversion that achieves micron-scale depth resolution with robustness to surface reflectance and ambient light with conventional silicon intensity sensors. To this end, we solve two technical challenges: modulating at GHz rates and computational phase unwrapping. We propose an imaging approach with resonant polarization modulators and devise a novel optical dual-pass frequency-doubling which achieves high modulation contrast at more than 10GHz. At the same time, centimeter-wave modulation together with a small modulation bandwidth render existing phase unwrapping methods ineffective. We tackle this problem with a neural phase unwrapping method that exploits that adjacent wraps are often highly correlated. We validate the proposed method in simulation and experimentally, where it achieves micron-scale depth precision. We demonstrate precise depth sensing independently of surface texture and ambient light and compare against existing analog demodulation methods, which we outperform across all tested scenarios.
Multi-attribute Pizza Generator: Cross-domain Attribute Control with Conditional StyleGAN
Oct 22, 2021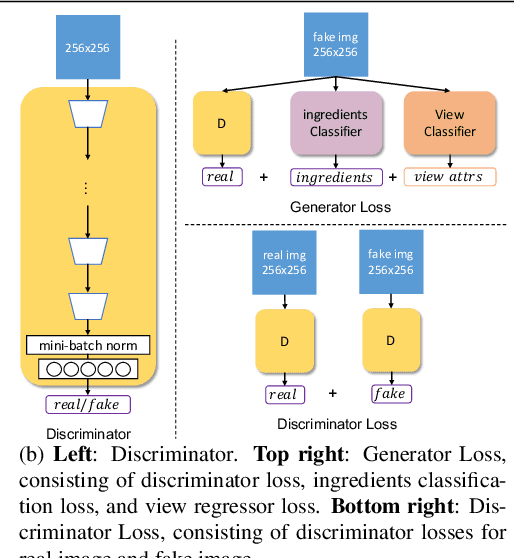
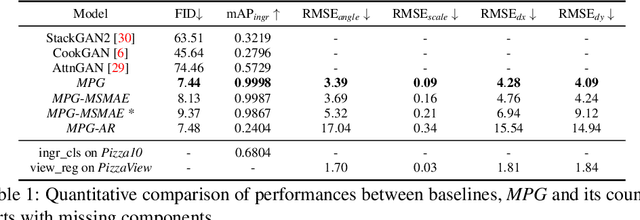
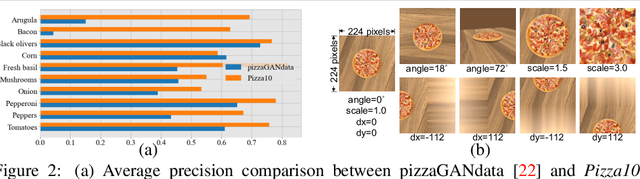
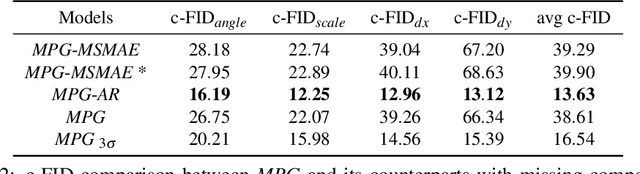
Multi-attribute conditional image generation is a challenging problem in computervision. We propose Multi-attribute Pizza Generator (MPG), a conditional Generative Neural Network (GAN) framework for synthesizing images from a trichotomy of attributes: content, view-geometry, and implicit visual style. We design MPG by extending the state-of-the-art StyleGAN2, using a new conditioning technique that guides the intermediate feature maps to learn multi-scale multi-attribute entangled representationsof controlling attributes. Because of the complex nature of the multi-attribute image generation problem, we regularize the image generation by predicting the explicit conditioning attributes (ingredients and view). To synthesize a pizza image with view attributesoutside the range of natural training images, we design a CGI pizza dataset PizzaView using 3D pizza models and employ it to train a view attribute regressor to regularize the generation process, bridging the real and CGI training datasets. To verify the efficacy of MPG, we test it on Pizza10, a carefully annotated multi-ingredient pizza image dataset. MPG can successfully generate photo-realistic pizza images with desired ingredients and view attributes, beyond the range of those observed in real-world training data.