 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Significance of Skeleton-based Features in Virtual Try-On
Aug 17, 2022
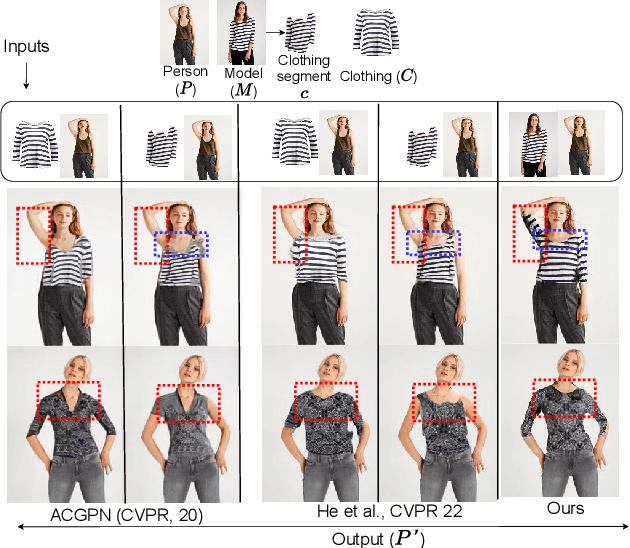
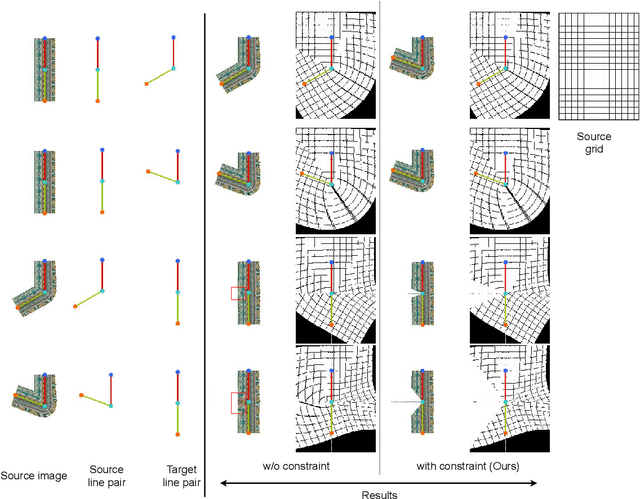


The idea of \textit{Virtual Try-ON} (VTON) benefits e-retailing by giving an user the convenience of trying a clothing at the comfort of their home. In general, most of the existing VTON methods produce inconsistent results when a person posing with his arms folded i.e., bent or crossed, wants to try an outfit. The problem becomes severe in the case of long-sleeved outfits. As then, for crossed arm postures, overlap among different clothing parts might happen. The existing approaches, especially the warping-based methods employing \textit{Thin Plate Spline (TPS)} transform can not tackle such cases. To this end, we attempt a solution approach where the clothing from the source person is segmented into semantically meaningful parts and each part is warped independently to the shape of the person. To address the bending issue, we employ hand-crafted geometric features consistent with human body geometry for warping the source outfit. In addition, we propose two learning-based modules: a synthesizer network and a mask prediction network. All these together attempt to produce a photo-realistic, pose-robust VTON solution without requiring any paired training data. Comparison with some of the benchmark methods clearly establishes the effectiveness of the approach.
Automatic Photo Adjustment Using Deep Neural Networks
May 16, 2015
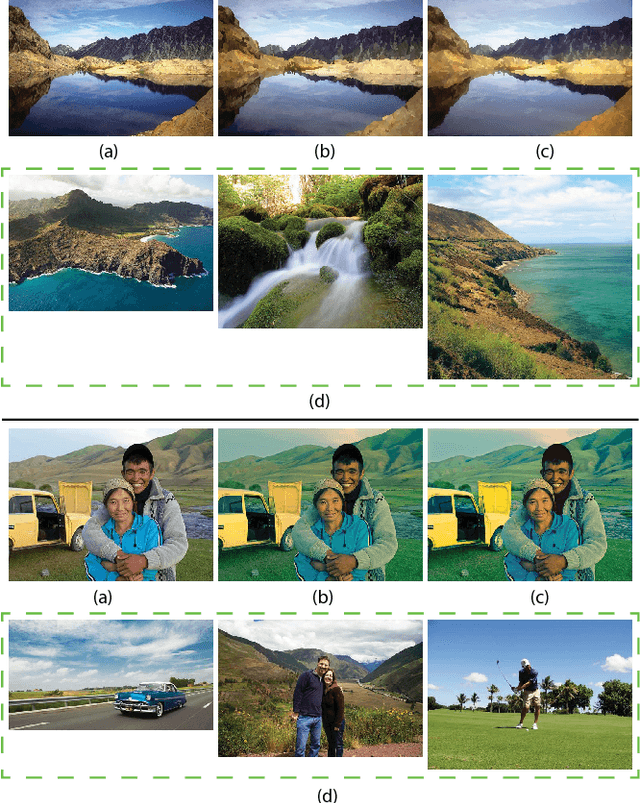

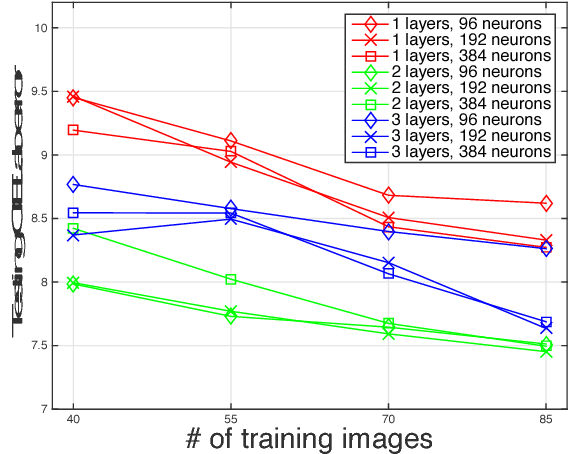
Photo retouching enables photographers to invoke dramatic visual impressions by artistically enhancing their photos through stylistic color and tone adjustments. However, it is also a time-consuming and challenging task that requires advanced skills beyond the abilities of casual photographers. Using an automated algorithm is an appealing alternative to manual work but such an algorithm faces many hurdles. Many photographic styles rely on subtle adjustments that depend on the image content and even its semantics. Further, these adjustments are often spatially varying. Because of these characteristics, existing automatic algorithms are still limited and cover only a subset of these challenges. Recently, deep machine learning has shown unique abilities to address hard problems that resisted machine algorithms for long. This motivated us to explore the use of deep learning in the context of photo editing. In this paper, we explain how to formulate the automatic photo adjustment problem in a way suitable for this approach. We also introduce an image descriptor that accounts for the local semantics of an image. Our experiments demonstrate that our deep learning formulation applied using these descriptors successfully capture sophisticated photographic styles. In particular and unlike previous techniques, it can model local adjustments that depend on the image semantics. We show on several examples that this yields results that are qualitatively and quantitatively better than previous work.
ObamaNet: Photo-realistic lip-sync from text
Dec 06, 2017
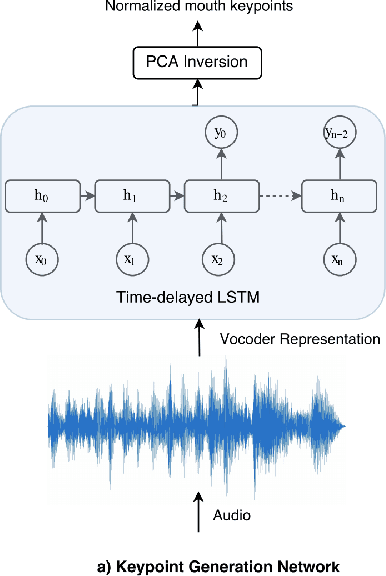
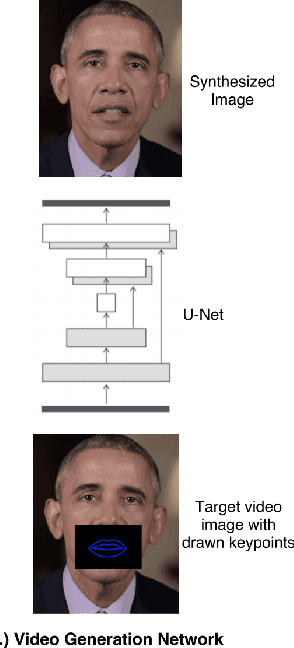

We present ObamaNet, the first architecture that generates both audio and synchronized photo-realistic lip-sync videos from any new text. Contrary to other published lip-sync approaches, ours is only composed of fully trainable neural modules and does not rely on any traditional computer graphics methods. More precisely, we use three main modules: a text-to-speech network based on Char2Wav, a time-delayed LSTM to generate mouth-keypoints synced to the audio, and a network based on Pix2Pix to generate the video frames conditioned on the keypoints.
Heart rate estimation in intense exercise videos
Aug 04, 2022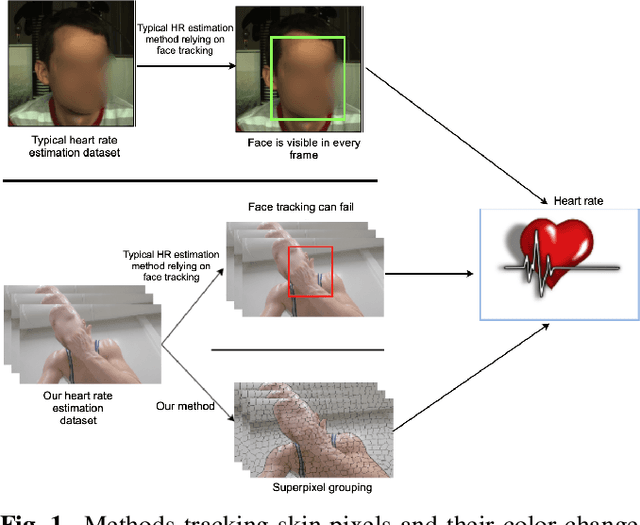

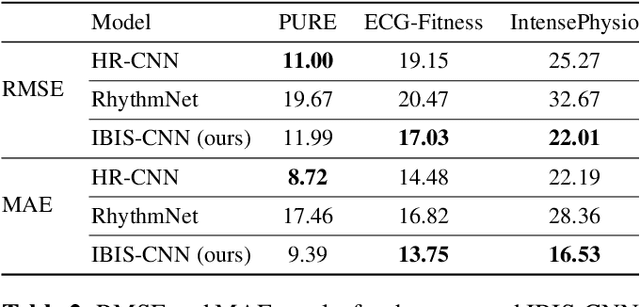
Estimating heart rate from video allows non-contact health monitoring with applications in patient care, human interaction, and sports. Existing work can robustly measure heart rate under some degree of motion by face tracking. However, this is not always possible in unconstrained settings, as the face might be occluded or even outside the camera. Here, we present IntensePhysio: a challenging video heart rate estimation dataset with realistic face occlusions, severe subject motion, and ample heart rate variation. To ensure heart rate variation in a realistic setting we record each subject for around 1-2 hours. The subject is exercising (at a moderate to high intensity) on a cycling ergometer with an attached video camera and is given no instructions regarding positioning or movement. We have 11 subjects, and approximately 20 total hours of video. We show that the existing remote photo-plethysmography methods have difficulty in estimating heart rate in this setting. In addition, we present IBIS-CNN, a new baseline using spatio-temporal superpixels, which improves on existing models by eliminating the need for a visible face/face tracking. We will make the code and data publically available soon.
Automatic Calibration of a Six-Degrees-of-Freedom Pose Estimation System
Aug 23, 2022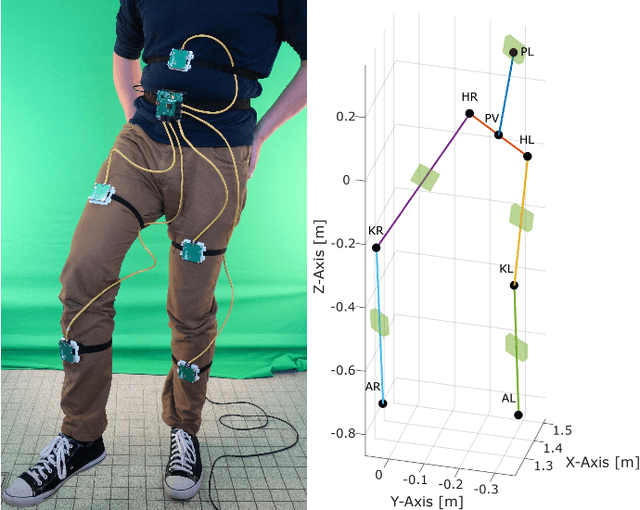
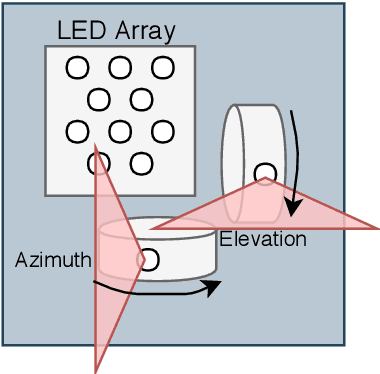
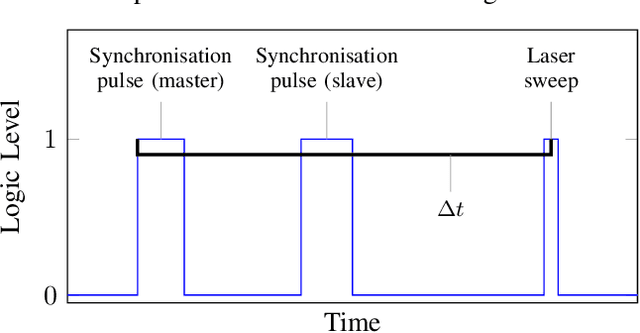

Systems for estimating the six-degrees-of-freedom human body pose have been improving for over two decades. Technologies such as motion capture cameras, advanced gaming peripherals and more recently both deep learning techniques and virtual reality systems have shown impressive results. However, most systems that provide high accuracy and high precision are expensive and not easy to operate. Recently, research has been carried out to estimate the human body pose using the HTC Vive virtual reality system. This system shows accurate results while keeping the cost under a 1000 USD. This system uses an optical approach. Two transmitter devices emit infrared pulses and laser planes are tracked by use of photo diodes on receiver hardware. A system using these transmitter devices combined with low-cost custom-made receiver hardware was developed previously but requires manual measurement of the position and orientation of the transmitter devices. These manual measurements can be time consuming, prone to error and not possible in particular setups. We propose an algorithm to automatically calibrate the poses of the transmitter devices in any chosen environment with custom receiver/calibration hardware. Results show that the calibration works in a variety of setups while being more accurate than what manual measurements would allow. Furthermore, the calibration movement and speed has no noticeable influence on the precision of the results.
Feasibility study of urban flood mapping using traffic signs for route optimization
Sep 24, 2021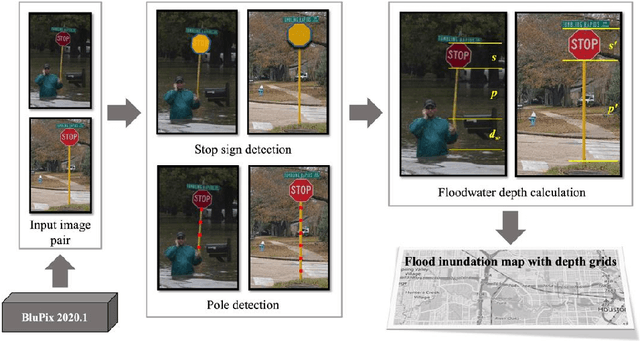
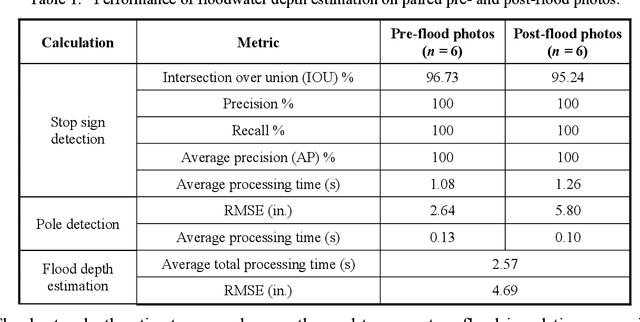
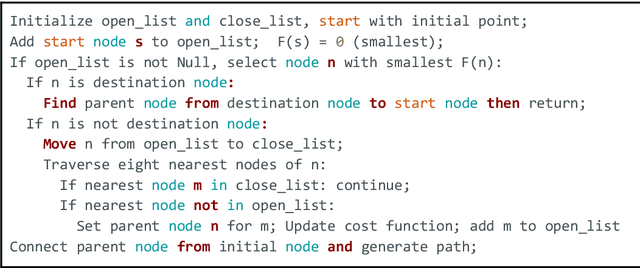
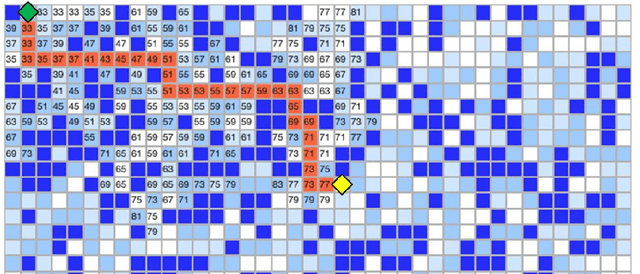
Water events are the most frequent and costliest climate disasters around the world. In the U.S., an estimated 127 million people who live in coastal areas are at risk of substantial home damage from hurricanes or flooding. In flood emergency management, timely and effective spatial decision-making and intelligent routing depend on flood depth information at a fine spatiotemporal scale. In this paper, crowdsourcing is utilized to collect photos of submerged stop signs, and pair each photo with a pre-flood photo taken at the same location. Each photo pair is then analyzed using deep neural network and image processing to estimate the depth of floodwater in the location of the photo. Generated point-by-point depth data is converted to a flood inundation map and used by an A* search algorithm to determine an optimal flood-free path connecting points of interest. Results provide crucial information to rescue teams and evacuees by enabling effective wayfinding during flooding events.
Robotics Meets Cosmetic Dermatology: Development of a Novel Vision-Guided System for Skin Photo-Rejuvenation
May 22, 2020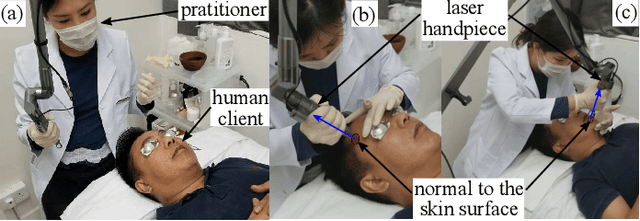
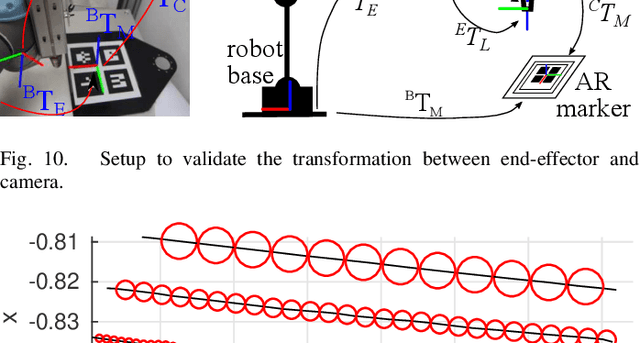
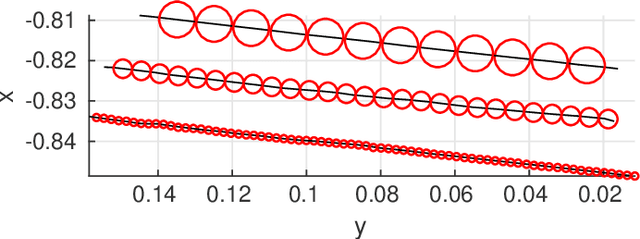

In this paper, we present a novel robotic system for skin photo-rejuvenation procedures, which can uniformly deliver the laser's energy over the skin of the face. The robotised procedure is performed by a manipulator whose end-effector is instrumented with a depth sensor, a thermal camera, and a cosmetic laser generator. To plan the heat stimulating trajectories for the laser, the system computes the surface model of the face and segments it into seven regions that are automatically filled with laser shots. We report experimental results with human subjects to validate the performance of the system. To the best of the author's knowledge, this is the first time that facial skin rejuvenation has been automated by robot manipulators.
4D LUT: Learnable Context-Aware 4D Lookup Table for Image Enhancement
Sep 05, 2022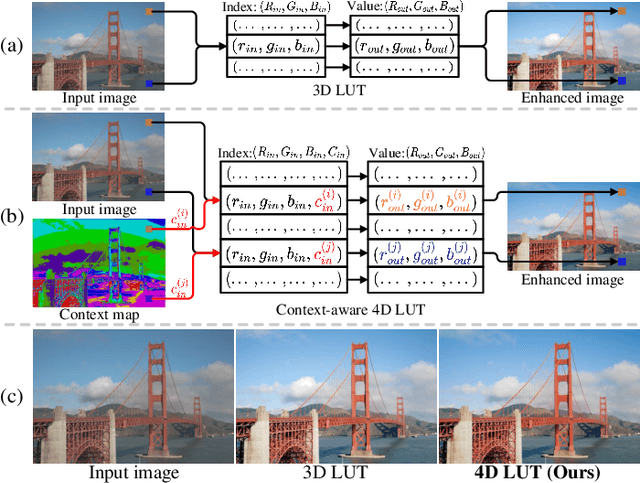
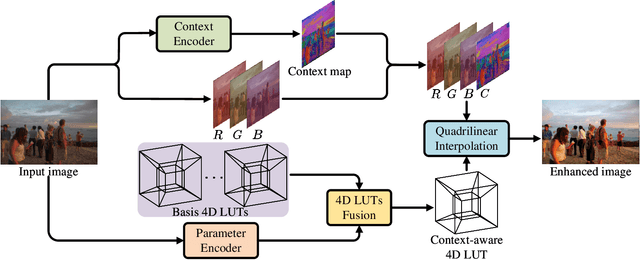


Image enhancement aims at improving the aesthetic visual quality of photos by retouching the color and tone, and is an essential technology for professional digital photography. Recent years deep learning-based image enhancement algorithms have achieved promising performance and attracted increasing popularity. However, typical efforts attempt to construct a uniform enhancer for all pixels' color transformation. It ignores the pixel differences between different content (e.g., sky, ocean, etc.) that are significant for photographs, causing unsatisfactory results. In this paper, we propose a novel learnable context-aware 4-dimensional lookup table (4D LUT), which achieves content-dependent enhancement of different contents in each image via adaptively learning of photo context. In particular, we first introduce a lightweight context encoder and a parameter encoder to learn a context map for the pixel-level category and a group of image-adaptive coefficients, respectively. Then, the context-aware 4D LUT is generated by integrating multiple basis 4D LUTs via the coefficients. Finally, the enhanced image can be obtained by feeding the source image and context map into fused context-aware 4D~LUT via quadrilinear interpolation. Compared with traditional 3D LUT, i.e., RGB mapping to RGB, which is usually used in camera imaging pipeline systems or tools, 4D LUT, i.e., RGBC(RGB+Context) mapping to RGB, enables finer control of color transformations for pixels with different content in each image, even though they have the same RGB values. Experimental results demonstrate that our method outperforms other state-of-the-art methods in widely-used benchmarks.
CCPL: Contrastive Coherence Preserving Loss for Versatile Style Transfer
Jul 19, 2022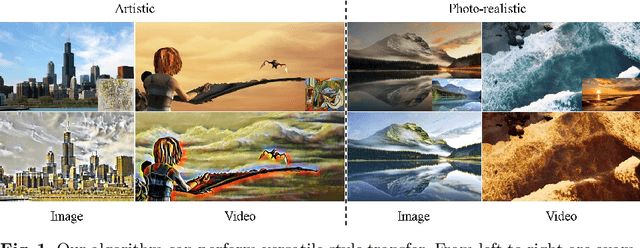
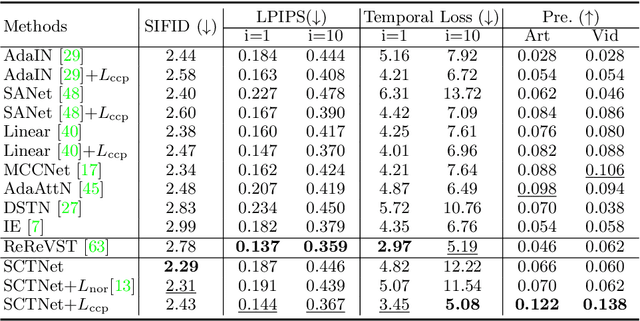
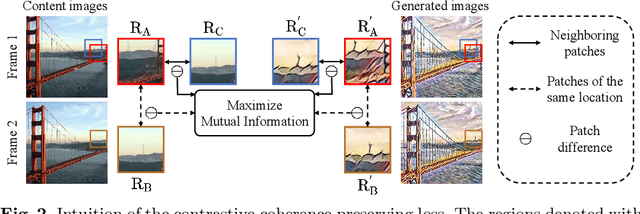

In this paper, we aim to devise a universally versatile style transfer method capable of performing artistic, photo-realistic, and video style transfer jointly, without seeing videos during training. Previous single-frame methods assume a strong constraint on the whole image to maintain temporal consistency, which could be violated in many cases. Instead, we make a mild and reasonable assumption that global inconsistency is dominated by local inconsistencies and devise a generic Contrastive Coherence Preserving Loss (CCPL) applied to local patches. CCPL can preserve the coherence of the content source during style transfer without degrading stylization. Moreover, it owns a neighbor-regulating mechanism, resulting in a vast reduction of local distortions and considerable visual quality improvement. Aside from its superior performance on versatile style transfer, it can be easily extended to other tasks, such as image-to-image translation. Besides, to better fuse content and style features, we propose Simple Covariance Transformation (SCT) to effectively align second-order statistics of the content feature with the style feature. Experiments demonstrate the effectiveness of the resulting model for versatile style transfer, when armed with CCPL.
LaTeRF: Label and Text Driven Object Radiance Fields
Jul 18, 2022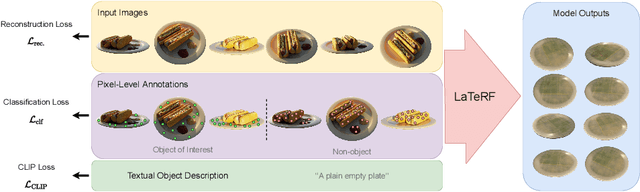
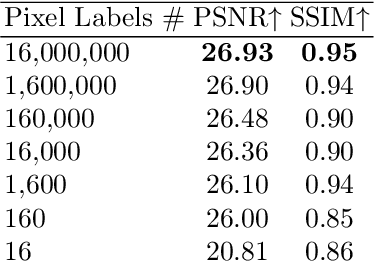

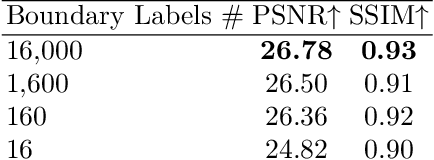
Obtaining 3D object representations is important for creating photo-realistic simulations and for collecting AR and VR assets. Neural fields have shown their effectiveness in learning a continuous volumetric representation of a scene from 2D images, but acquiring object representations from these models with weak supervision remains an open challenge. In this paper we introduce LaTeRF, a method for extracting an object of interest from a scene given 2D images of the entire scene, known camera poses, a natural language description of the object, and a set of point-labels of object and non-object points in the input images. To faithfully extract the object from the scene, LaTeRF extends the NeRF formulation with an additional `objectness' probability at each 3D point. Additionally, we leverage the rich latent space of a pre-trained CLIP model combined with our differentiable object renderer, to inpaint the occluded parts of the object. We demonstrate high-fidelity object extraction on both synthetic and real-world datasets and justify our design choices through an extensive ablation study.