 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNORA: A Harness-Engineered Autonomous Research Agent for End-to-End Spatial Data Science
May 03, 2026The automation of scientific research workflows has emerged as a transformative frontier in artificial intelligence, yet existing autonomous research agents remain largely domain-agnostic, lacking the specialized reasoning, method selection, and data acquisition capabilities required for rigorous spatial data science. This paper introduces NORA (Night Owl Research Agent), a harness-engineered, multi-agent autonomous research system purpose-built for GIScience and spatial data science. NORA orchestrates the complete research lifecycle through a skills-first architecture comprising 21 domain-specialized workflow skills, 9 specialist sub-agents, and custom Model Context Protocol (MCP) servers. Central to the system's design are two novel domain-specialized skills: a spatial analysis skill unit that encodes decision frameworks for exploratory spatial data analysis, spatial regression, and diagnostics; and a spatial data download skill that supports reproducible acquisition from authoritative geospatial data sources. We formalize the concept of harness engineering for scientific research agents, demonstrating how lifecycle hooks, safety gates, generator-evaluator separation, human-in-the-loop, and state persistence ensure reliable and reproducible autonomous research. We evaluate NORA through case studies by 6 domain specialists and 3 LLM reviewers across seven dimensions (novelty, quality, rigor, etc). Results demonstrate that domain-specialized harness engineering substantially improves the efficiency and quality of research output compared to general-purpose agent configurations.
Toward building next-generation Geocoding systems: a systematic review
Mar 24, 2025



Geocoding systems are widely used in both scientific research for spatial analysis and everyday life through location-based services. The quality of geocoded data significantly impacts subsequent processes and applications, underscoring the need for next-generation systems. In response to this demand, this review first examines the evolving requirements for geocoding inputs and outputs across various scenarios these systems must address. It then provides a detailed analysis of how to construct such systems by breaking them down into key functional components and reviewing a broad spectrum of existing approaches, from traditional rule-based methods to advanced techniques in information retrieval, natural language processing, and large language models. Finally, we identify opportunities to improve next-generation geocoding systems in light of recent technological advances.
Estimating Agreement by Chance for Sequence Annotation
Jul 16, 2024



In the field of natural language processing, correction of performance assessment for chance agreement plays a crucial role in evaluating the reliability of annotations. However, there is a notable dearth of research focusing on chance correction for assessing the reliability of sequence annotation tasks, despite their widespread prevalence in the field. To address this gap, this paper introduces a novel model for generating random annotations, which serves as the foundation for estimating chance agreement in sequence annotation tasks. Utilizing the proposed randomization model and a related comparison approach, we successfully derive the analytical form of the distribution, enabling the computation of the probable location of each annotated text segment and subsequent chance agreement estimation. Through a combination simulation and corpus-based evaluation, we successfully assess its applicability and validate its accuracy and efficacy.
Automated Clinical Data Extraction with Knowledge Conditioned LLMs
Jun 26, 2024



The extraction of lung lesion information from clinical and medical imaging reports is crucial for research on and clinical care of lung-related diseases. Large language models (LLMs) can be effective at interpreting unstructured text in reports, but they often hallucinate due to a lack of domain-specific knowledge, leading to reduced accuracy and posing challenges for use in clinical settings. To address this, we propose a novel framework that aligns generated internal knowledge with external knowledge through in-context learning (ICL). Our framework employs a retriever to identify relevant units of internal or external knowledge and a grader to evaluate the truthfulness and helpfulness of the retrieved internal-knowledge rules, to align and update the knowledge bases. Our knowledge-conditioned approach also improves the accuracy and reliability of LLM outputs by addressing the extraction task in two stages: (i) lung lesion finding detection and primary structured field parsing, followed by (ii) further parsing of lesion description text into additional structured fields. Experiments with expert-curated test datasets demonstrate that this ICL approach can increase the F1 score for key fields (lesion size, margin and solidity) by an average of 12.9% over existing ICL methods.
Is ChatGPT a game changer for geocoding -- a benchmark for geocoding address parsing techniques
Oct 22, 2023



The remarkable success of GPT models across various tasks, including toponymy recognition motivates us to assess the performance of the GPT-3 model in the geocoding address parsing task. To ensure that the evaluation more accurately mirrors performance in real-world scenarios with diverse user input qualities and resolve the pressing need for a 'gold standard' evaluation dataset for geocoding systems, we introduce a benchmark dataset of low-quality address descriptions synthesized based on human input patterns mining from actual input logs of a geocoding system in production. This dataset has 21 different input errors and variations; contains over 239,000 address records that are uniquely selected from streets across all U.S. 50 states and D.C.; and consists of three subsets to be used as training, validation, and testing sets. Building on this, we train and gauge the performance of the GPT-3 model in extracting address components, contrasting its performance with transformer-based and LSTM-based models. The evaluation results indicate that Bidirectional LSTM-CRF model has achieved the best performance over these transformer-based models and GPT-3 model. Transformer-based models demonstrate very comparable results compared to the Bidirectional LSTM-CRF model. The GPT-3 model, though trailing in performance, showcases potential in the address parsing task with few-shot examples, exhibiting room for improvement with additional fine-tuning. We open source the code and data of this presented benchmark so that researchers can utilize it for future model development or extend it to evaluate similar tasks, such as document geocoding.
Feasibility study of urban flood mapping using traffic signs for route optimization
Sep 24, 2021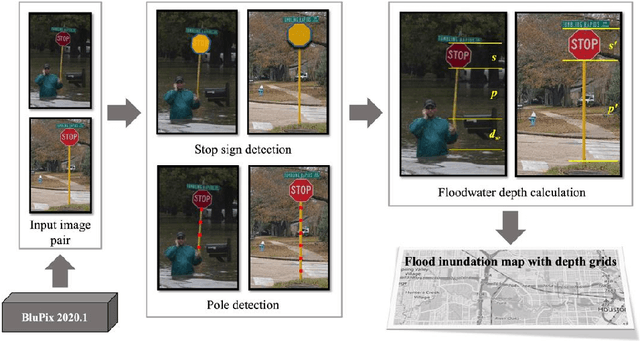
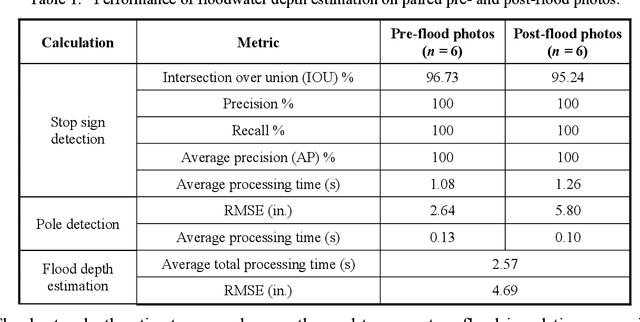
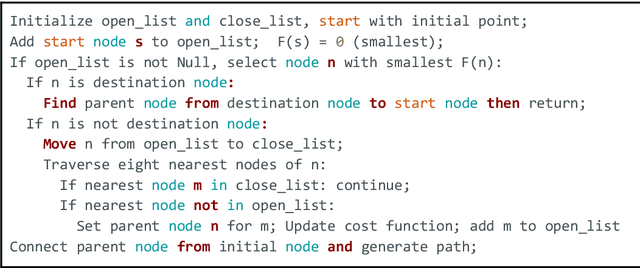
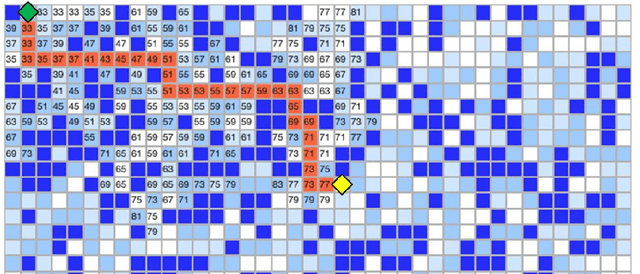
Water events are the most frequent and costliest climate disasters around the world. In the U.S., an estimated 127 million people who live in coastal areas are at risk of substantial home damage from hurricanes or flooding. In flood emergency management, timely and effective spatial decision-making and intelligent routing depend on flood depth information at a fine spatiotemporal scale. In this paper, crowdsourcing is utilized to collect photos of submerged stop signs, and pair each photo with a pre-flood photo taken at the same location. Each photo pair is then analyzed using deep neural network and image processing to estimate the depth of floodwater in the location of the photo. Generated point-by-point depth data is converted to a flood inundation map and used by an A* search algorithm to determine an optimal flood-free path connecting points of interest. Results provide crucial information to rescue teams and evacuees by enabling effective wayfinding during flooding events.