 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Semantic Hierarchy Emerges in Deep Generative Representations for Scene Synthesis
Nov 21, 2019

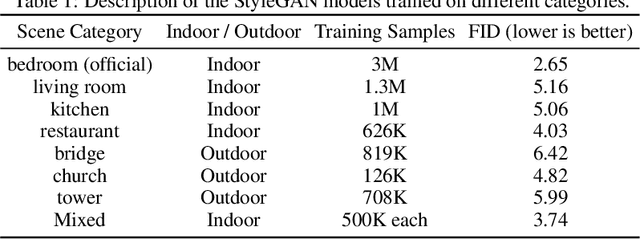

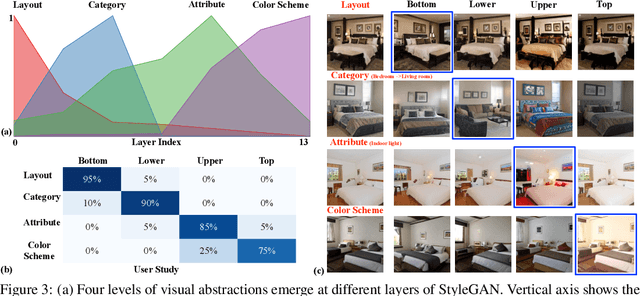
Despite the success of Generative Adversarial Networks (GANs) in image synthesis, there lacks enough understanding on what networks have learned inside the deep generative representations and how photo-realistic images are able to be composed from random noises. In this work, we show that highly-structured semantic hierarchy emerges as variation factors for synthesizing scenes from the generative representations in state-of-the-art GAN models, like StyleGAN and BigGAN. By probing the layer-wise representations with a broad set of semantics at different abstraction levels, we are able to quantify the causality between the activations and semantics occurring in the output image. Such a quantification identifies the human-understandable variation factors learned by GANs to compose scenes. The qualitative and quantitative results suggest that the generative representations learned by the GANs with layer-wise latent codes are specialized to synthesize different hierarchical semantics: the early layers tend to determine the spatial layout and configuration, the middle layers control the categorical objects, and the later layers finally render the scene attributes as well as color scheme. Identifying such a set of manipulatable latent variation factors facilitates semantic scene manipulation.
Lake Ice Monitoring with Webcams and Crowd-Sourced Images
Feb 18, 2020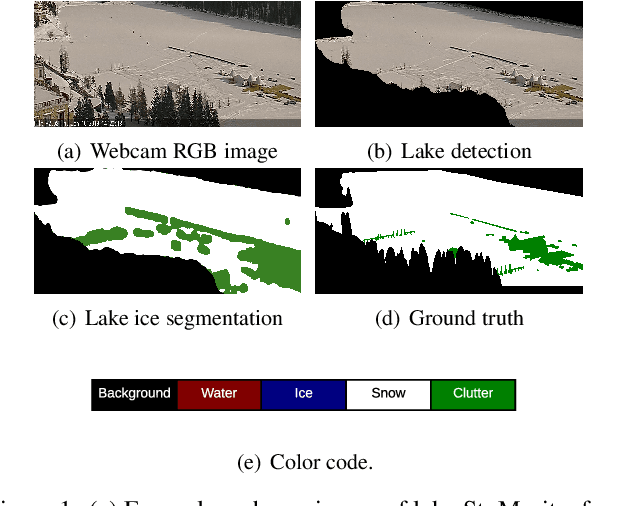
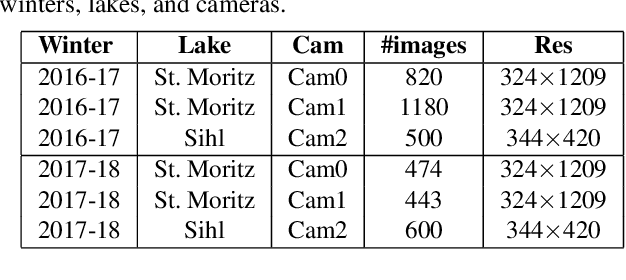

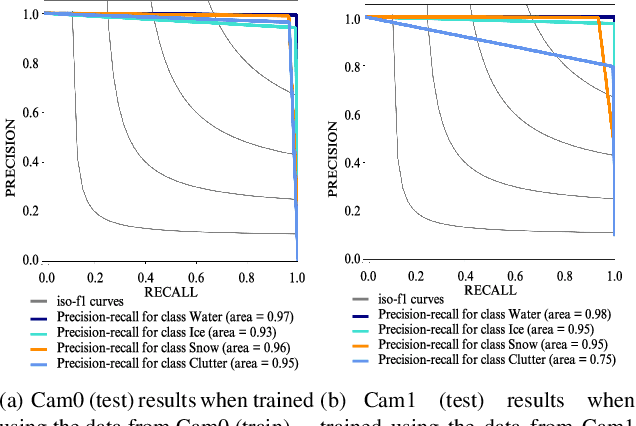
Lake ice is a strong climate indicator and has been recognised as part of the Essential Climate Variables (ECV) by the Global Climate Observing System (GCOS). The dynamics of freezing and thawing, and possible shifts of freezing patterns over time, can help in understanding the local and global climate systems. One way to acquire the spatio-temporal information about lake ice formation, independent of clouds, is to analyse webcam images. This paper intends to move towards a universal model for monitoring lake ice with freely available webcam data. We demonstrate good performance, including the ability to generalise across different winters and different lakes, with a state-of-the-art Convolutional Neural Network (CNN) model for semantic image segmentation, Deeplab v3+. Moreover, we design a variant of that model, termed Deep-U-Lab, which predicts sharper, more correct segmentation boundaries. We have tested the model's ability to generalise with data from multiple camera views and two different winters. On average, it achieves intersection-over-union (IoU) values of ~71% across different cameras and ~69% across different winters, greatly outperforming prior work. Going even further, we show that the model even achieves 60% IoU on arbitrary images scraped from photo-sharing web sites. As part of the work, we introduce a new benchmark dataset of webcam images, Photi-LakeIce, from multiple cameras and two different winters, along with pixel-wise ground truth annotations.
Sensory Optimization: Neural Networks as a Model for Understanding and Creating Art
Nov 16, 2019

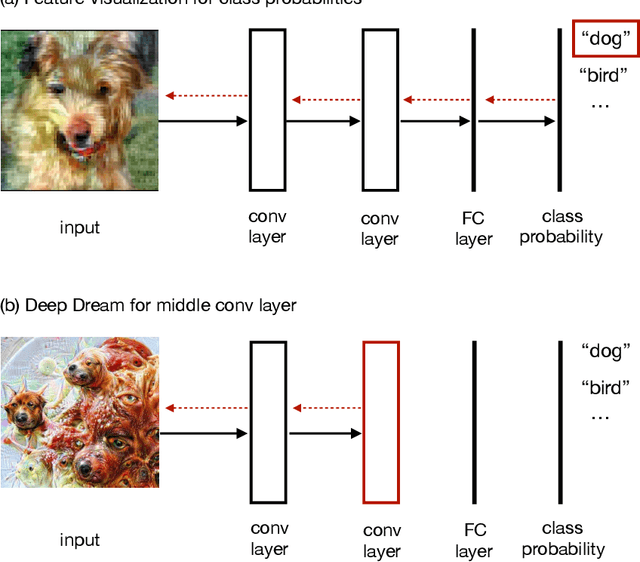
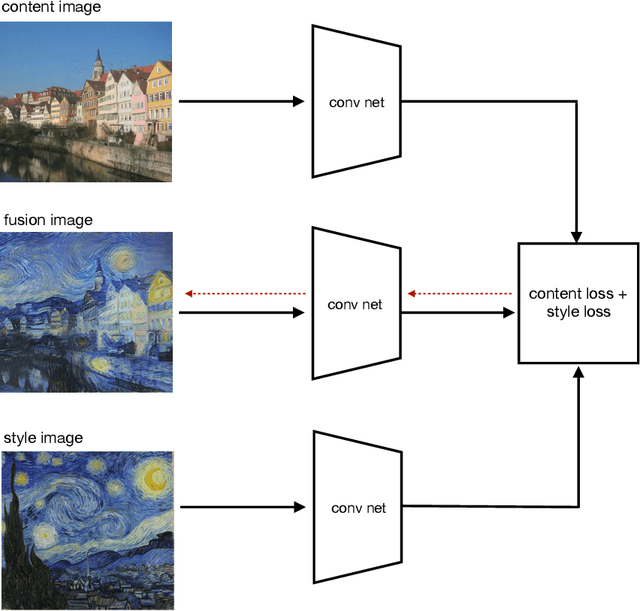
This article is about the cognitive science of visual art. Artists create physical artifacts (such as sculptures or paintings) which depict people, objects, and events. These depictions are usually stylized rather than photo-realistic. How is it that humans are able to understand and create stylized representations? Does this ability depend on general cognitive capacities or an evolutionary adaptation for art? What role is played by learning and culture? Machine Learning can shed light on these questions. It's possible to train convolutional neural networks (CNNs) to recognize objects without training them on any visual art. If such CNNs can generalize to visual art (by creating and understanding stylized representations), then CNNs provide a model for how humans could understand art without innate adaptations or cultural learning. I argue that Deep Dream and Style Transfer show that CNNs can create a basic form of visual art, and that humans could create art by similar processes. This suggests that artists make art by optimizing for effects on the human object-recognition system. Physical artifacts are optimized to evoke real-world objects for this system (e.g. to evoke people or landscapes) and to serve as superstimuli for this system.
Recapture as You Want
Jun 02, 2020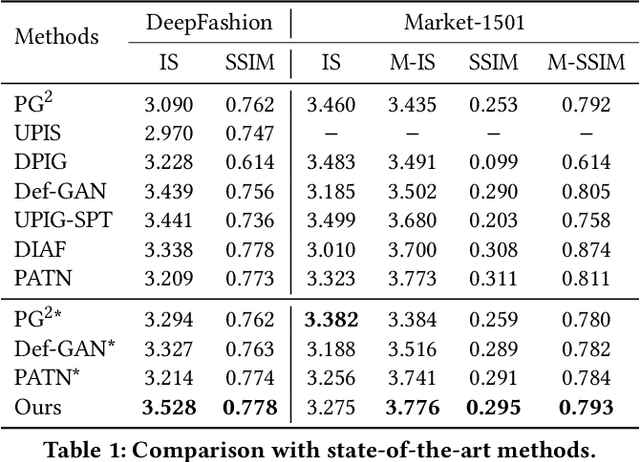
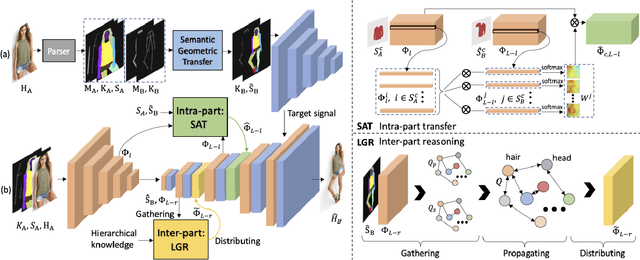

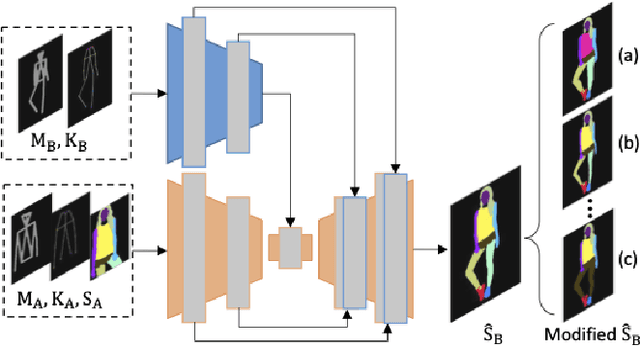
With the increasing prevalence and more powerful camera systems of mobile devices, people can conveniently take photos in their daily life, which naturally brings the demand for more intelligent photo post-processing techniques, especially on those portrait photos. In this paper, we present a portrait recapture method enabling users to easily edit their portrait to desired posture/view, body figure and clothing style, which are very challenging to achieve since it requires to simultaneously perform non-rigid deformation of human body, invisible body-parts reasoning and semantic-aware editing. We decompose the editing procedure into semantic-aware geometric and appearance transformation. In geometric transformation, a semantic layout map is generated that meets user demands to represent part-level spatial constraints and further guides the semantic-aware appearance transformation. In appearance transformation, we design two novel modules, Semantic-aware Attentive Transfer (SAT) and Layout Graph Reasoning (LGR), to conduct intra-part transfer and inter-part reasoning, respectively. SAT module produces each human part by paying attention to the semantically consistent regions in the source portrait. It effectively addresses the non-rigid deformation issue and well preserves the intrinsic structure/appearance with rich texture details. LGR module utilizes body skeleton knowledge to construct a layout graph that connects all relevant part features, where graph reasoning mechanism is used to propagate information among part nodes to mine their relations. In this way, LGR module infers invisible body parts and guarantees global coherence among all the parts. Extensive experiments on DeepFashion, Market-1501 and in-the-wild photos demonstrate the effectiveness and superiority of our approach. Video demo is at: \url{https://youtu.be/vTyq9HL6jgw}.
Dual-Attention GAN for Large-Pose Face Frontalization
Feb 17, 2020
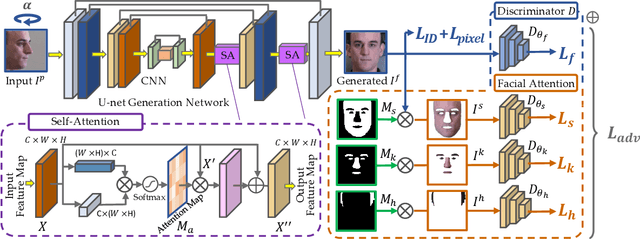


Face frontalization provides an effective and efficient way for face data augmentation and further improves the face recognition performance in extreme pose scenario. Despite recent advances in deep learning-based face synthesis approaches, this problem is still challenging due to significant pose and illumination discrepancy. In this paper, we present a novel Dual-Attention Generative Adversarial Network (DA-GAN) for photo-realistic face frontalization by capturing both contextual dependencies and local consistency during GAN training. Specifically, a self-attention-based generator is introduced to integrate local features with their long-range dependencies yielding better feature representations, and hence generate faces that preserve identities better, especially for larger pose angles. Moreover, a novel face-attention-based discriminator is applied to emphasize local features of face regions, and hence reinforce the realism of synthetic frontal faces. Guided by semantic segmentation, four independent discriminators are used to distinguish between different aspects of a face (\ie skin, keypoints, hairline, and frontalized face). By introducing these two complementary attention mechanisms in generator and discriminator separately, we can learn a richer feature representation and generate identity preserving inference of frontal views with much finer details (i.e., more accurate facial appearance and textures) comparing to the state-of-the-art. Quantitative and qualitative experimental results demonstrate the effectiveness and efficiency of our DA-GAN approach.
Single Image Reflection Removal through Cascaded Refinement
Nov 15, 2019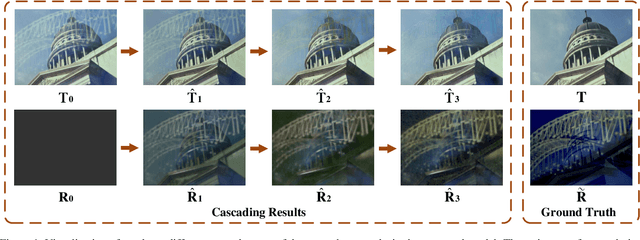
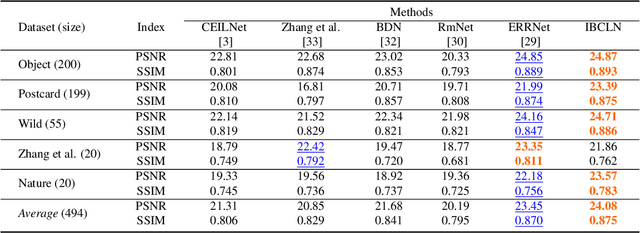
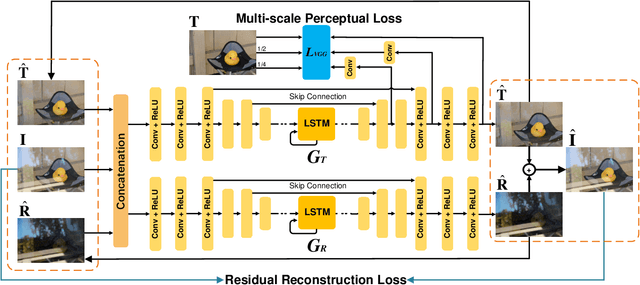
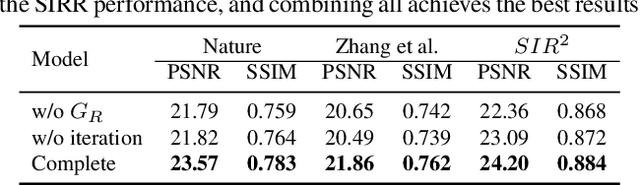
We address the problem of removing undesirable reflections from a single image captured through a glass surface, which is an ill-posed, challenging but practically important problem for photo enhancement. Inspired by iterative structure reduction for hidden community detection in social networks, we propose an Iterative Boost Convolutional LSTM Network (IBCLN) that enables cascaded prediction for reflection removal. IBCLN iteratively refines estimates of the transmission and reflection layers at each step in a manner that they can boost the prediction quality for each other. The intuition is that progressive refinement of the transmission or reflection layer is aided by increasingly better estimates of these quantities as input, and that transmission and reflection are complementary to each other in a single image and thus provide helpful auxiliary information for each other's prediction. To facilitate training over multiple cascade steps, we employ LSTM to address the vanishing gradient problem, and incorporate a reconstruction loss as further training guidance at each step. In addition, we create a dataset of real-world images with reflection and ground-truth transmission layers to mitigate the problem of insufficient data. Through comprehensive experiments, IBCLN demonstrates performance that surpasses state-of-the-art reflection removal methods.
Embedding Geographic Locations for Modelling the Natural Environment using Flickr Tags and Structured Data
Oct 12, 2018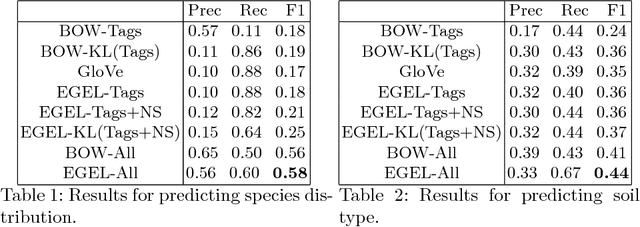
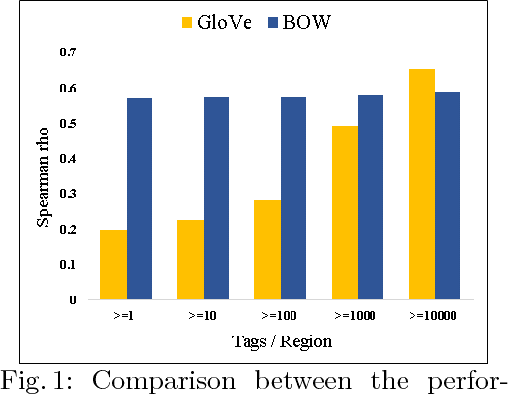
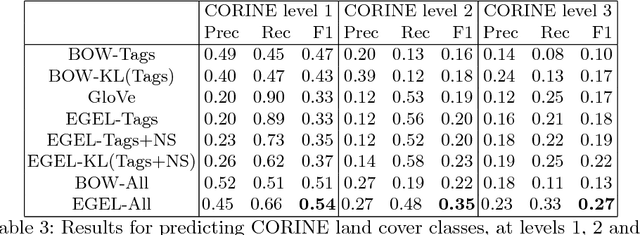
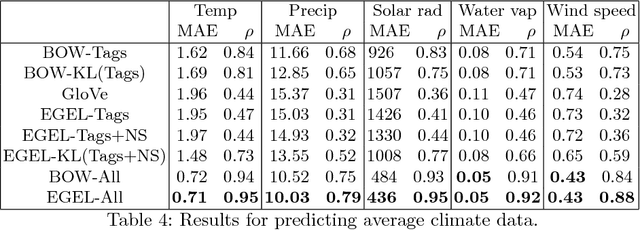
Meta-data from photo-sharing websites such as Flickr can be used to obtain rich bag-of-words descriptions of geographic locations, which have proven valuable, among others, for modelling and predicting ecological features. One important insight from previous work is that the descriptions obtained from Flickr tend to be complementary to the structured information that is available from traditional scientific resources. To better integrate these two diverse sources of information, in this paper we consider a method for learning vector space embeddings of geographic locations. We show experimentally that this method improves on existing approaches, especially in cases where structured information is available.
Recognizing Instagram Filtered Images with Feature De-stylization
Dec 30, 2019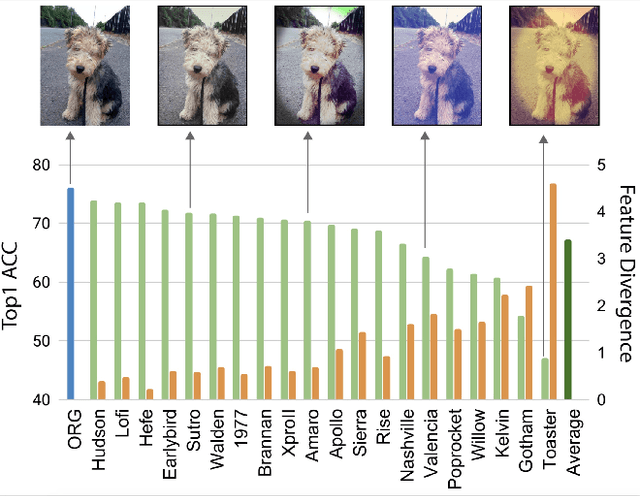


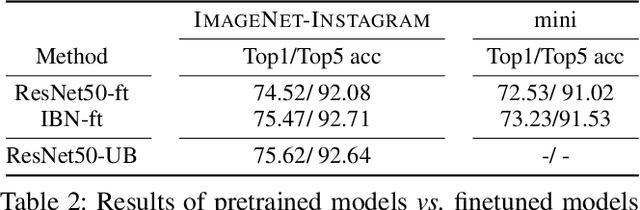
Deep neural networks have been shown to suffer from poor generalization when small perturbations are added (like Gaussian noise), yet little work has been done to evaluate their robustness to more natural image transformations like photo filters. This paper presents a study on how popular pretrained models are affected by commonly used Instagram filters. To this end, we introduce ImageNet-Instagram, a filtered version of ImageNet, where 20 popular Instagram filters are applied to each image in ImageNet. Our analysis suggests that simple structure preserving filters which only alter the global appearance of an image can lead to large differences in the convolutional feature space. To improve generalization, we introduce a lightweight de-stylization module that predicts parameters used for scaling and shifting feature maps to "undo" the changes incurred by filters, inverting the process of style transfer tasks. We further demonstrate the module can be readily plugged into modern CNN architectures together with skip connections. We conduct extensive studies on ImageNet-Instagram, and show quantitatively and qualitatively, that the proposed module, among other things, can effectively improve generalization by simply learning normalization parameters without retraining the entire network, thus recovering the alterations in the feature space caused by the filters.
Style Transfer With Adaptation to the Central Objects of the Scene
Jun 04, 2019
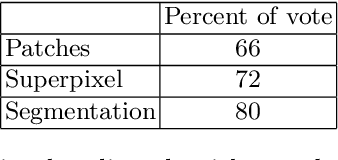


Style transfer is a problem of rendering image with some content in the style of another image, for example a family photo in the style of a painting of some famous artist. The drawback of classical style transfer algorithm is that it imposes style uniformly on all parts of the content image, which perturbs central objects on the content image, such as faces or text, and makes them unrecognizable. This work proposes a novel style transfer algorithm which automatically detects central objects on the content image, generates spatial importance mask and imposes style non-uniformly: central objects are stylized less to preserve their recognizability and other parts of the image are stylized as usual to preserve the style. Three methods of automatic central object detection are proposed and evaluated qualitatively and via a user evaluation study. Both comparisons demonstrate higher quality of stylization compared to the classical style transfer method.
Synthetic Video Generation for Robust Hand Gesture Recognition in Augmented Reality Applications
Nov 04, 2019
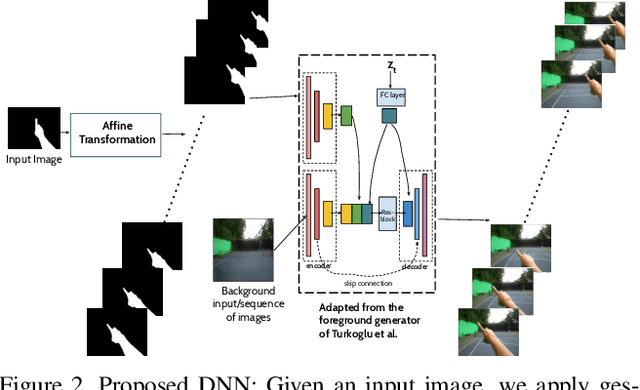


Hand gestures are a natural means of interaction in Augmented Reality and Virtual Reality (AR/VR) applications. Recently, there has been an increased focus on removing the dependence of accurate hand gesture recognition on complex sensor setup found in expensive proprietary devices such as the Microsoft HoloLens, Daqri and Meta Glasses. Most such solutions either rely on multi-modal sensor data or deep neural networks that can benefit greatly from abundance of labelled data. Datasets are an integral part of any deep learning based research. They have been the principal reason for the substantial progress in this field, both, in terms of providing enough data for the training of these models, and, for benchmarking competing algorithms. However, it is becoming increasingly difficult to generate enough labelled data for complex tasks such as hand gesture recognition. The goal of this work is to introduce a framework capable of generating photo-realistic videos that have labelled hand bounding box and fingertip that can help in designing, training, and benchmarking models for hand-gesture recognition in AR/VR applications. We demonstrate the efficacy of our framework in generating videos with diverse backgrounds.