 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoreferencing complex relative locality descriptions with large language models
Dec 16, 2025Georeferencing text documents has typically relied on either gazetteer-based methods to assign geographic coordinates to place names, or on language modelling approaches that associate textual terms with geographic locations. However, many location descriptions specify positions relatively with spatial relationships, making geocoding based solely on place names or geo-indicative words inaccurate. This issue frequently arises in biological specimen collection records, where locations are often described through narratives rather than coordinates if they pre-date GPS. Accurate georeferencing is vital for biodiversity studies, yet the process remains labour-intensive, leading to a demand for automated georeferencing solutions. This paper explores the potential of Large Language Models (LLMs) to georeference complex locality descriptions automatically, focusing on the biodiversity collections domain. We first identified effective prompting patterns, then fine-tuned an LLM using Quantized Low-Rank Adaptation (QLoRA) on biodiversity datasets from multiple regions and languages. Our approach outperforms existing baselines with an average, across datasets, of 65% of records within a 10 km radius, for a fixed amount of training data. The best results (New York state) were 85% within 10km and 67% within 1km. The selected LLM performs well for lengthy, complex descriptions, highlighting its potential for georeferencing intricate locality descriptions.
Embedding Geographic Locations for Modelling the Natural Environment using Flickr Tags and Structured Data
Oct 12, 2018
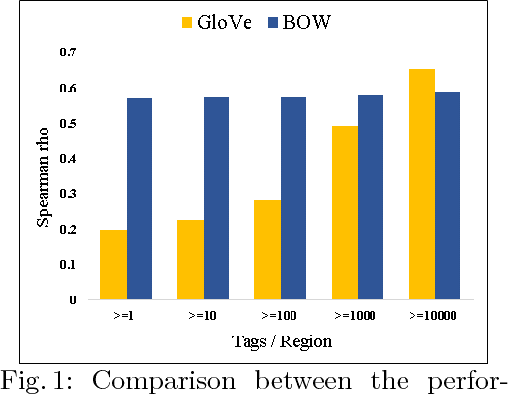
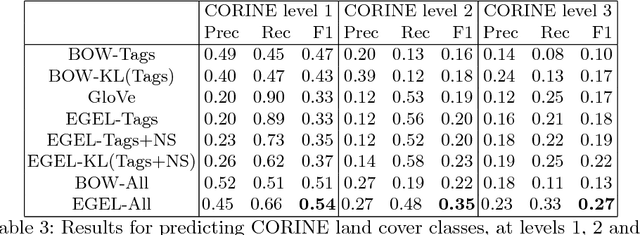
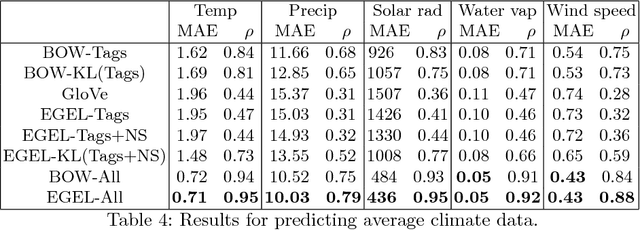
Meta-data from photo-sharing websites such as Flickr can be used to obtain rich bag-of-words descriptions of geographic locations, which have proven valuable, among others, for modelling and predicting ecological features. One important insight from previous work is that the descriptions obtained from Flickr tend to be complementary to the structured information that is available from traditional scientific resources. To better integrate these two diverse sources of information, in this paper we consider a method for learning vector space embeddings of geographic locations. We show experimentally that this method improves on existing approaches, especially in cases where structured information is available.