 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
A Hybrid Framework for Matching Printing Design Files to Product Photos
Jun 09, 2020
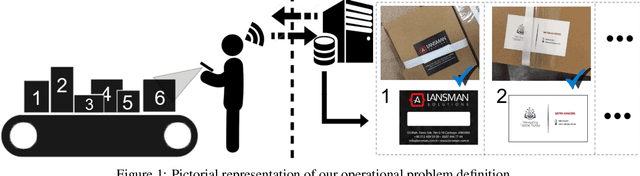


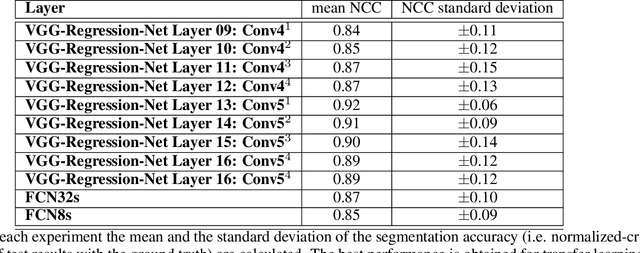
We propose a real-time image matching framework, which is hybrid in the sense that it uses both hand-crafted features and deep features obtained from a well-tuned deep convolutional network. The matching problem, which we concentrate on, is specific to a certain application, that is, printing design to product photo matching. Printing designs are any kind of template image files, created using a design tool, thus are perfect image signals. However, photographs of a printed product suffer many unwanted effects, such as uncontrolled shooting angle, uncontrolled illumination, occlusions, printing deficiencies in color, camera noise, optic blur, et cetera. For this purpose, we create an image set that includes printing design and corresponding product photo pairs with collaboration of an actual printing facility. Using this image set, we benchmark various hand-crafted and deep features for matching performance and propose a framework in which deep learning is utilized with highest contribution, but without disabling real-time operation using an ordinary desktop computer.
ComicGAN: Text-to-Comic Generative Adversarial Network
Sep 19, 2021

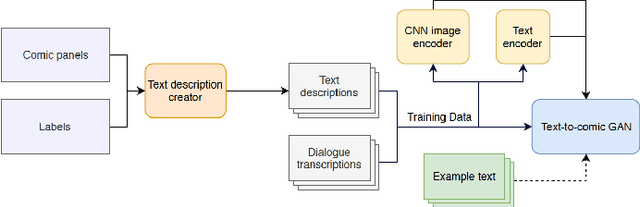
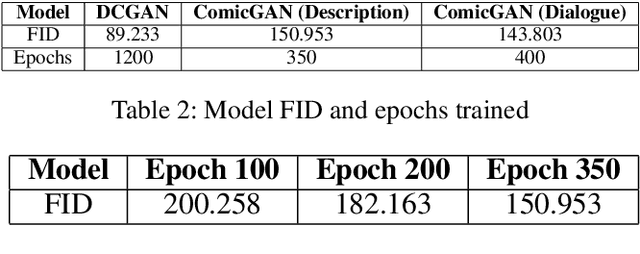
Drawing and annotating comic illustrations is a complex and difficult process. No existing machine learning algorithms have been developed to create comic illustrations based on descriptions of illustrations, or the dialogue in comics. Moreover, it is not known if a generative adversarial network (GAN) can generate original comics that correspond to the dialogue and/or descriptions. GANs are successful in producing photo-realistic images, but this technology does not necessarily translate to generation of flawless comics. What is more, comic evaluation is a prominent challenge as common metrics such as Inception Score will not perform comparably, as they are designed to work on photos. In this paper: 1. We implement ComicGAN, a novel text-to-comic pipeline based on a text-to-image GAN that synthesizes comics according to text descriptions. 2. We describe an in-depth empirical study of the technical difficulties of comic generation using GAN's. ComicGAN has two novel features: (i) text description creation from labels via permutation and augmentation, and (ii) custom image encoding with Convolutional Neural Networks. We extensively evaluate the proposed ComicGAN in two scenarios, namely image generation from descriptions, and image generation from dialogue. Our results on 1000 Dilbert comic panels and 6000 descriptions show synthetic comic panels from text inputs resemble original Dilbert panels. Novel methods for text description creation and custom image encoding brought improvements to Frechet Inception Distance, detail, and overall image quality over baseline algorithms. Generating illustrations from descriptions provided clear comics including characters and colours that were specified in the descriptions.
PluGeN: Multi-Label Conditional Generation From Pre-Trained Models
Sep 18, 2021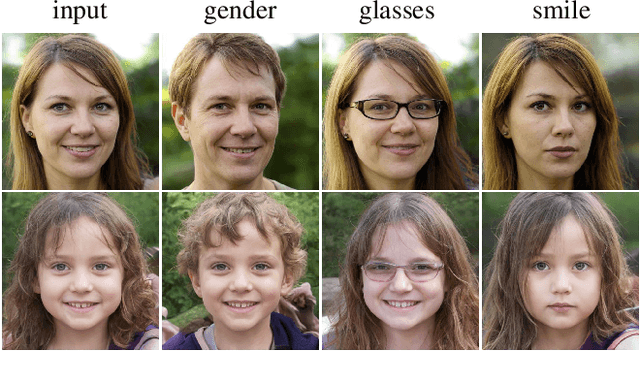
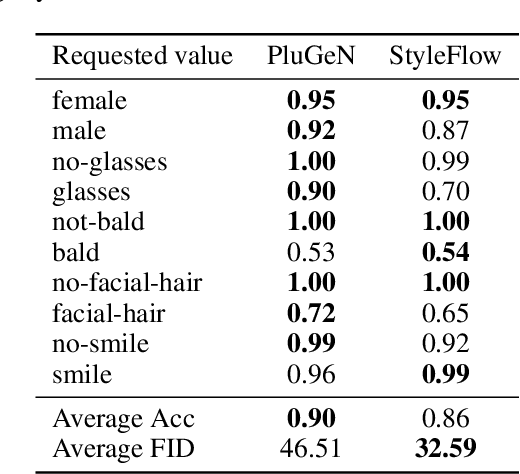
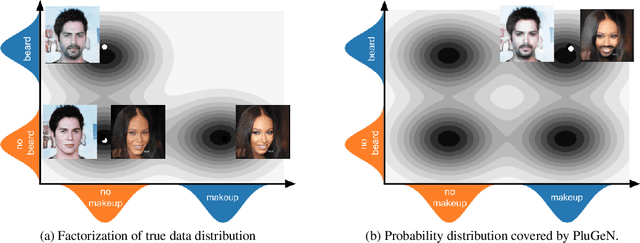
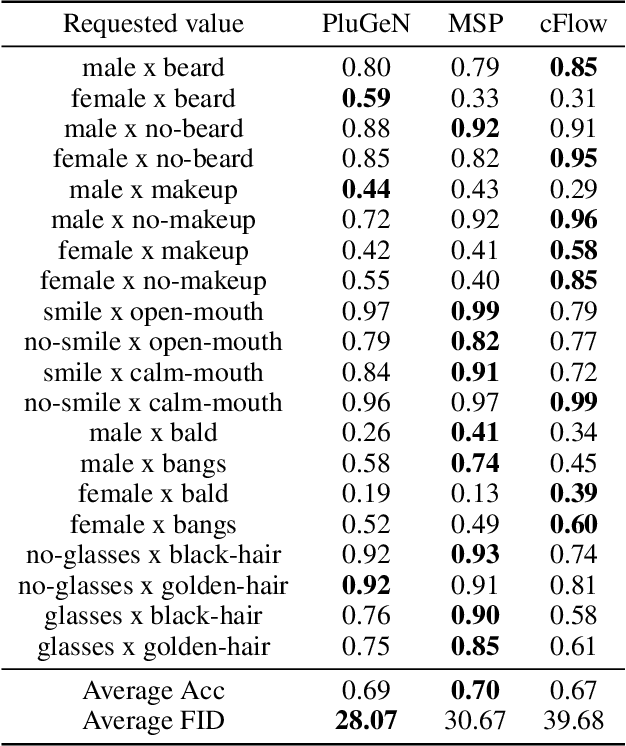
Modern generative models achieve excellent quality in a variety of tasks including image or text generation and chemical molecule modeling. However, existing methods often lack the essential ability to generate examples with requested properties, such as the age of the person in the photo or the weight of the generated molecule. Incorporating such additional conditioning factors would require rebuilding the entire architecture and optimizing the parameters from scratch. Moreover, it is difficult to disentangle selected attributes so that to perform edits of only one attribute while leaving the others unchanged. To overcome these limitations we propose PluGeN (Plugin Generative Network), a simple yet effective generative technique that can be used as a plugin to pre-trained generative models. The idea behind our approach is to transform the entangled latent representation using a flow-based module into a multi-dimensional space where the values of each attribute are modeled as an independent one-dimensional distribution. In consequence, PluGeN can generate new samples with desired attributes as well as manipulate labeled attributes of existing examples. Due to the disentangling of the latent representation, we are even able to generate samples with rare or unseen combinations of attributes in the dataset, such as a young person with gray hair, men with make-up, or women with beards. We combined PluGeN with GAN and VAE models and applied it to conditional generation and manipulation of images and chemical molecule modeling. Experiments demonstrate that PluGeN preserves the quality of backbone models while adding the ability to control the values of labeled attributes.
Conditional Sequential Modulation for Efficient Global Image Retouching
Sep 22, 2020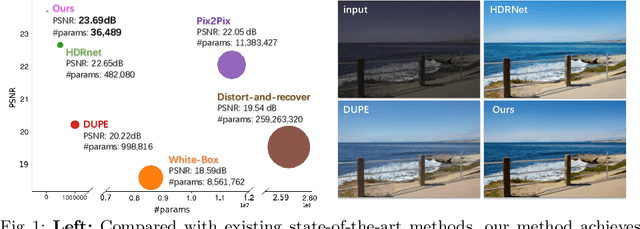
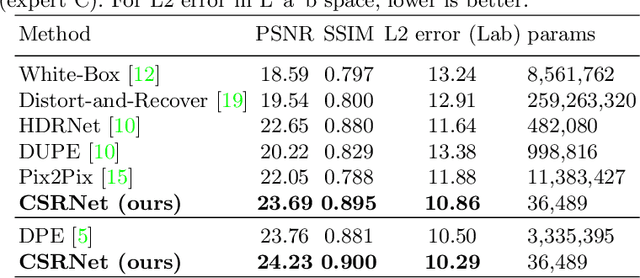
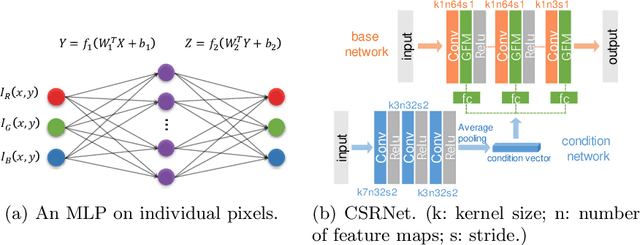
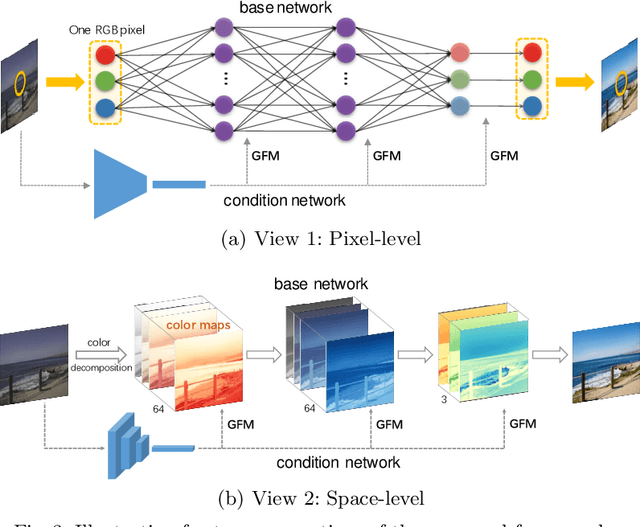
Photo retouching aims at enhancing the aesthetic visual quality of images that suffer from photographic defects such as over/under exposure, poor contrast, inharmonious saturation. Practically, photo retouching can be accomplished by a series of image processing operations. In this paper, we investigate some commonly-used retouching operations and mathematically find that these pixel-independent operations can be approximated or formulated by multi-layer perceptrons (MLPs). Based on this analysis, we propose an extremely light-weight framework - Conditional Sequential Retouching Network (CSRNet) - for efficient global image retouching. CSRNet consists of a base network and a condition network. The base network acts like an MLP that processes each pixel independently and the condition network extracts the global features of the input image to generate a condition vector. To realize retouching operations, we modulate the intermediate features using Global Feature Modulation (GFM), of which the parameters are transformed by condition vector. Benefiting from the utilization of $1\times1$ convolution, CSRNet only contains less than 37k trainable parameters, which is orders of magnitude smaller than existing learning-based methods. Extensive experiments show that our method achieves state-of-the-art performance on the benchmark MIT-Adobe FiveK dataset quantitively and qualitatively. Code is available at https://github.com/hejingwenhejingwen/CSRNet.
Semantic Palette: Guiding Scene Generation with Class Proportions
Jun 03, 2021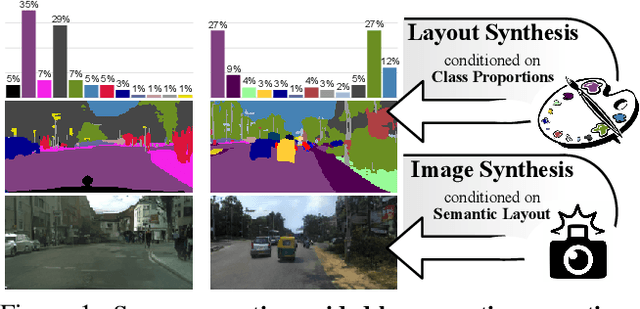
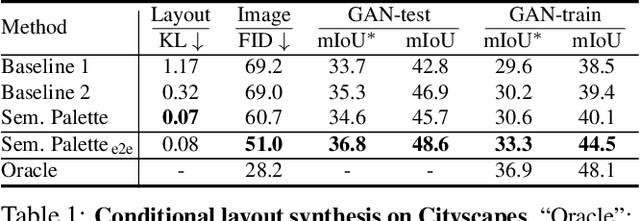
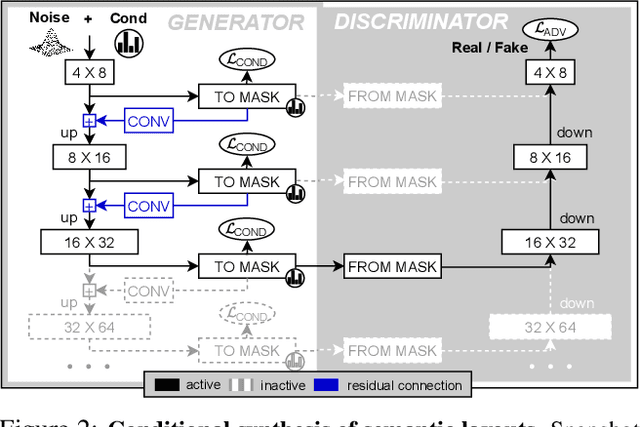
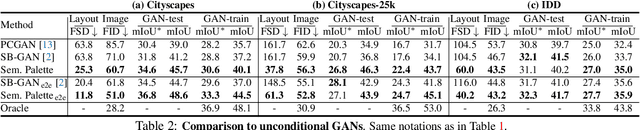
Despite the recent progress of generative adversarial networks (GANs) at synthesizing photo-realistic images, producing complex urban scenes remains a challenging problem. Previous works break down scene generation into two consecutive phases: unconditional semantic layout synthesis and image synthesis conditioned on layouts. In this work, we propose to condition layout generation as well for higher semantic control: given a vector of class proportions, we generate layouts with matching composition. To this end, we introduce a conditional framework with novel architecture designs and learning objectives, which effectively accommodates class proportions to guide the scene generation process. The proposed architecture also allows partial layout editing with interesting applications. Thanks to the semantic control, we can produce layouts close to the real distribution, helping enhance the whole scene generation process. On different metrics and urban scene benchmarks, our models outperform existing baselines. Moreover, we demonstrate the merit of our approach for data augmentation: semantic segmenters trained on real layout-image pairs along with additional ones generated by our approach outperform models only trained on real pairs.
From Culture to Clothing: Discovering the World Events Behind A Century of Fashion Images
Feb 02, 2021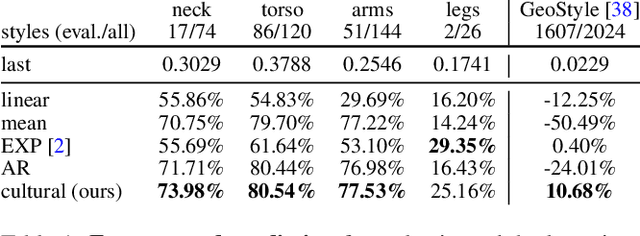
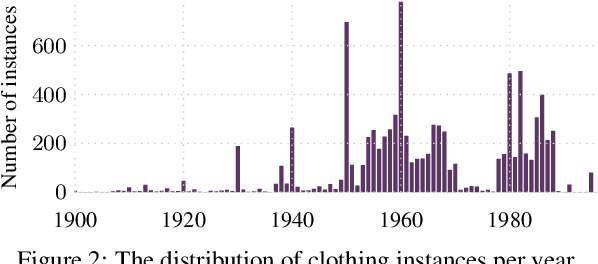


Fashion is intertwined with external cultural factors, but identifying these links remains a manual process limited to only the most salient phenomena. We propose a data-driven approach to identify specific cultural factors affecting the clothes people wear. Using large-scale datasets of news articles and vintage photos spanning a century, we introduce a multi-modal statistical model to detect influence relationships between happenings in the world and people's choice of clothing. Furthermore, we apply our model to improve the concrete vision tasks of visual style forecasting and photo timestamping on two datasets. Our work is a first step towards a computational, scalable, and easily refreshable approach to link culture to clothing.
SIMMC 2.0: A Task-oriented Dialog Dataset for Immersive Multimodal Conversations
Apr 18, 2021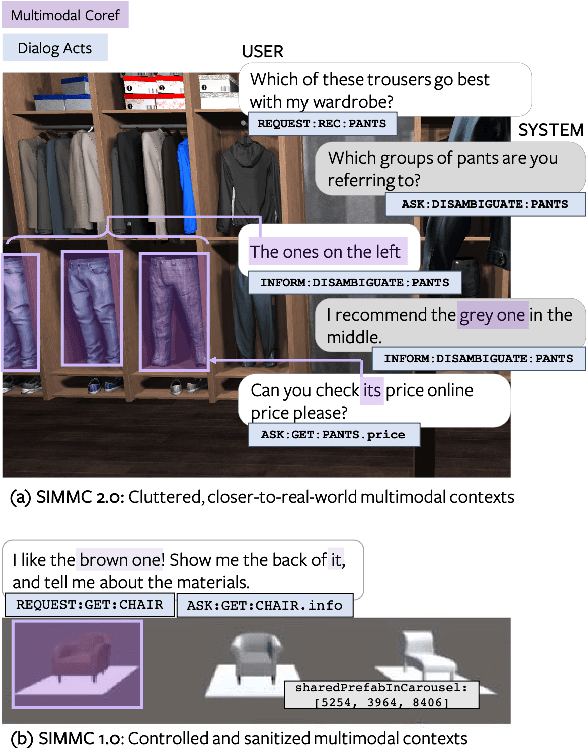


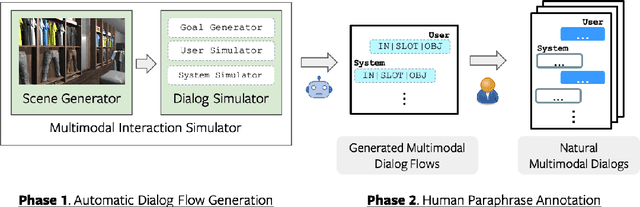
We present a new corpus for the Situated and Interactive Multimodal Conversations, SIMMC 2.0, aimed at building a successful multimodal assistant agent. Specifically, the dataset features 11K task-oriented dialogs (117K utterances) between a user and a virtual assistant on the shopping domain (fashion and furniture), grounded in situated and photo-realistic VR scenes. The dialogs are collected using a two-phase pipeline, which first generates simulated dialog flows via a novel multimodal dialog simulator we propose, followed by manual paraphrasing of the generated utterances. In this paper, we provide an in-depth analysis of the collected dataset, and describe in detail the four main benchmark tasks we propose for SIMMC 2.0. The preliminary analysis with a baseline model highlights the new challenges that the SIMMC 2.0 dataset brings, suggesting new directions for future research. Our dataset and code will be made publicly available.
DeepBlur: A Simple and Effective Method for Natural Image Obfuscation
Mar 31, 2021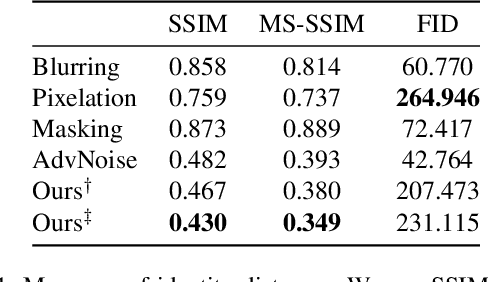
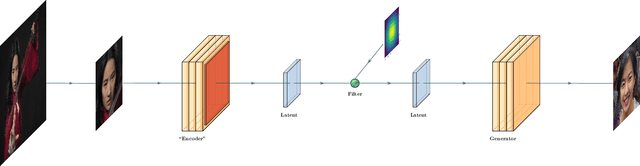
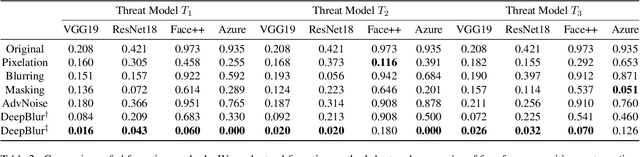
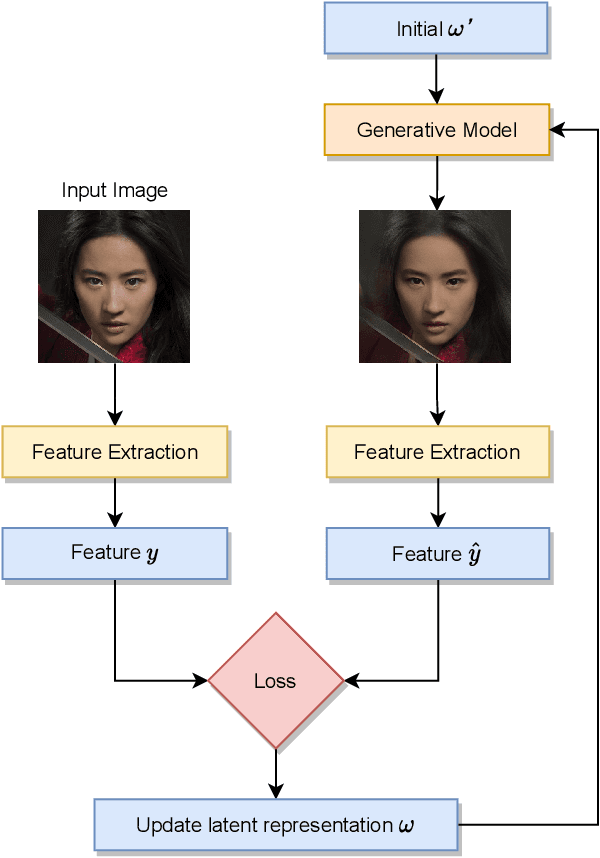
There is a growing privacy concern due to the popularity of social media and surveillance systems, along with advances in face recognition software. However, established image obfuscation techniques are either vulnerable to re-identification attacks by human or deep learning models, insufficient in preserving image fidelity, or too computationally intensive to be practical. To tackle these issues, we present DeepBlur, a simple yet effective method for image obfuscation by blurring in the latent space of an unconditionally pre-trained generative model that is able to synthesize photo-realistic facial images. We compare it with existing methods by efficiency and image quality, and evaluate against both state-of-the-art deep learning models and industrial products (e.g., Face++, Microsoft face service). Experiments show that our method produces high quality outputs and is the strongest defense for most test cases.
DAE-GAN: Dynamic Aspect-aware GAN for Text-to-Image Synthesis
Aug 27, 2021
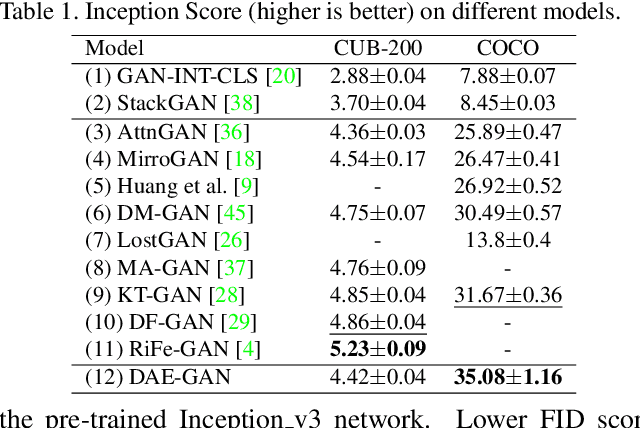
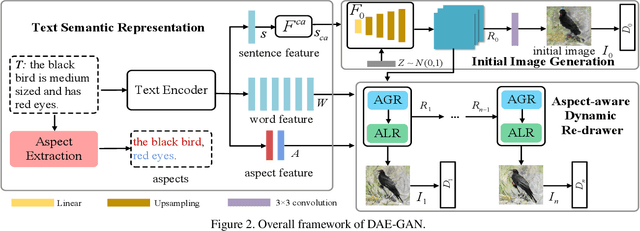
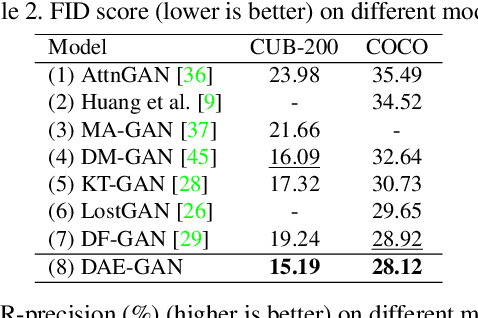
Text-to-image synthesis refers to generating an image from a given text description, the key goal of which lies in photo realism and semantic consistency. Previous methods usually generate an initial image with sentence embedding and then refine it with fine-grained word embedding. Despite the significant progress, the 'aspect' information (e.g., red eyes) contained in the text, referring to several words rather than a word that depicts 'a particular part or feature of something', is often ignored, which is highly helpful for synthesizing image details. How to make better utilization of aspect information in text-to-image synthesis still remains an unresolved challenge. To address this problem, in this paper, we propose a Dynamic Aspect-awarE GAN (DAE-GAN) that represents text information comprehensively from multiple granularities, including sentence-level, word-level, and aspect-level. Moreover, inspired by human learning behaviors, we develop a novel Aspect-aware Dynamic Re-drawer (ADR) for image refinement, in which an Attended Global Refinement (AGR) module and an Aspect-aware Local Refinement (ALR) module are alternately employed. AGR utilizes word-level embedding to globally enhance the previously generated image, while ALR dynamically employs aspect-level embedding to refine image details from a local perspective. Finally, a corresponding matching loss function is designed to ensure the text-image semantic consistency at different levels. Extensive experiments on two well-studied and publicly available datasets (i.e., CUB-200 and COCO) demonstrate the superiority and rationality of our method.
HeadGAN: Video-and-Audio-Driven Talking Head Synthesis
Dec 15, 2020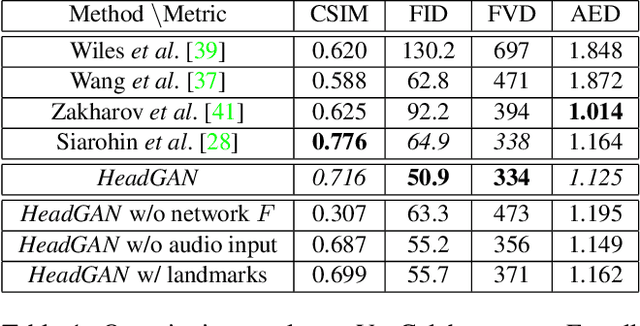
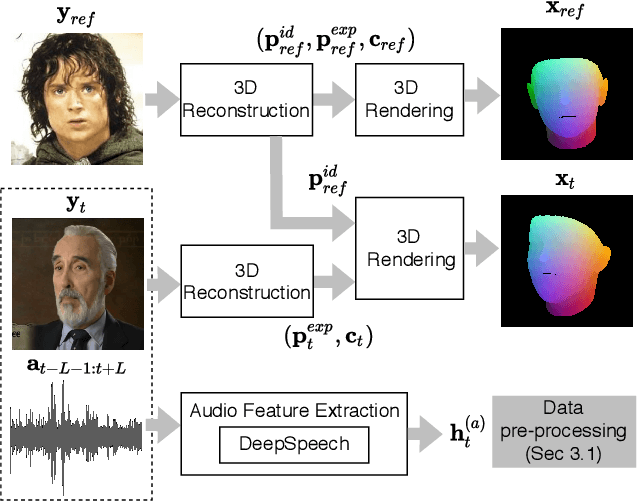
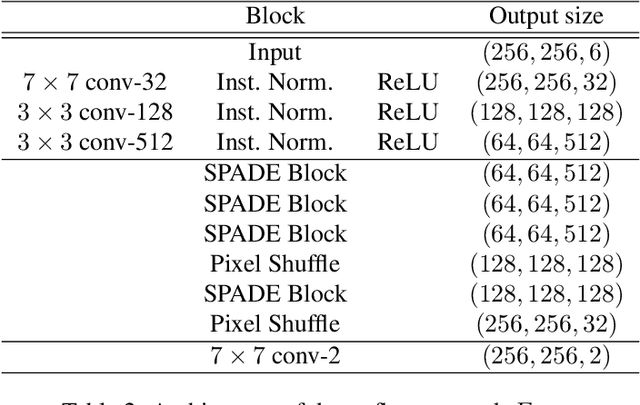
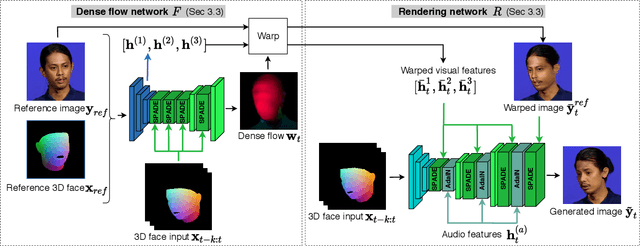
Recent attempts to solve the problem of talking head synthesis using a single reference image have shown promising results. However, most of them fail to meet the identity preservation problem, or perform poorly in terms of photo-realism, especially in extreme head poses. We propose HeadGAN, a novel reenactment approach that conditions synthesis on 3D face representations, which can be extracted from any driving video and adapted to the facial geometry of any source. We improve the plausibility of mouth movements, by utilising audio features as a complementary input to the Generator. Quantitative and qualitative experiments demonstrate the merits of our approach.