 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Music Gesture for Visual Sound Separation
Apr 20, 2020
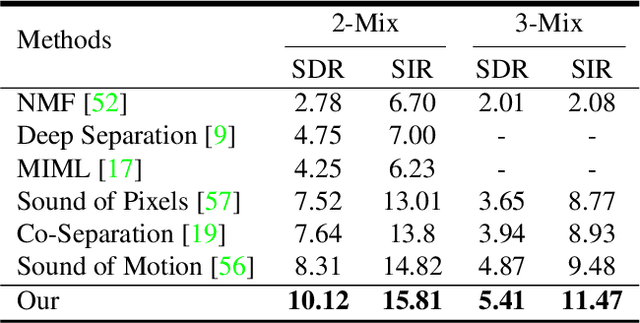
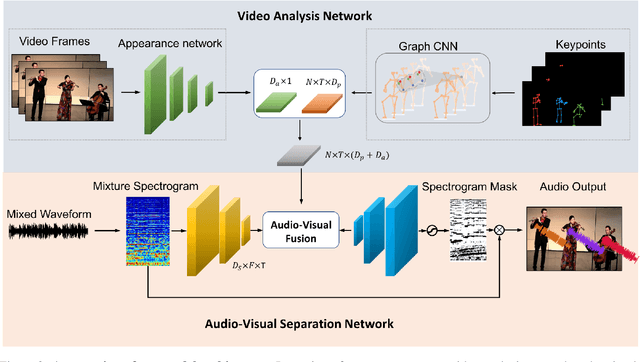

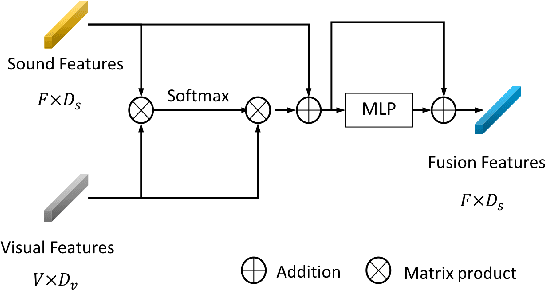
Recent deep learning approaches have achieved impressive performance on visual sound separation tasks. However, these approaches are mostly built on appearance and optical flow like motion feature representations, which exhibit limited abilities to find the correlations between audio signals and visual points, especially when separating multiple instruments of the same types, such as multiple violins in a scene. To address this, we propose "Music Gesture," a keypoint-based structured representation to explicitly model the body and finger movements of musicians when they perform music. We first adopt a context-aware graph network to integrate visual semantic context with body dynamics, and then apply an audio-visual fusion model to associate body movements with the corresponding audio signals. Experimental results on three music performance datasets show: 1) strong improvements upon benchmark metrics for hetero-musical separation tasks (i.e. different instruments); 2) new ability for effective homo-musical separation for piano, flute, and trumpet duets, which to our best knowledge has never been achieved with alternative methods. Project page: http://music-gesture.csail.mit.edu.
MeloForm: Generating Melody with Musical Form based on Expert Systems and Neural Networks
Aug 30, 2022
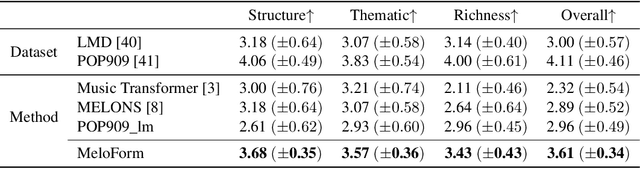
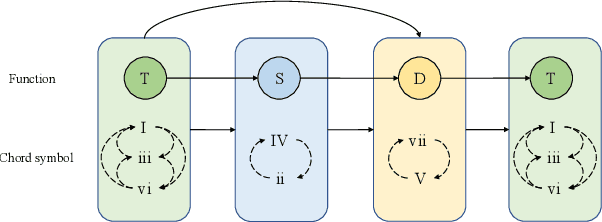
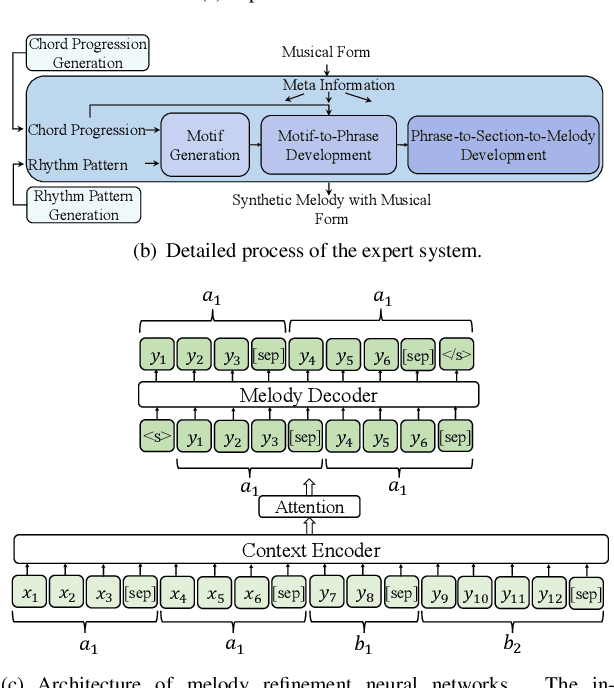
Human usually composes music by organizing elements according to the musical form to express music ideas. However, for neural network-based music generation, it is difficult to do so due to the lack of labelled data on musical form. In this paper, we develop MeloForm, a system that generates melody with musical form using expert systems and neural networks. Specifically, 1) we design an expert system to generate a melody by developing musical elements from motifs to phrases then to sections with repetitions and variations according to pre-given musical form; 2) considering the generated melody is lack of musical richness, we design a Transformer based refinement model to improve the melody without changing its musical form. MeloForm enjoys the advantages of precise musical form control by expert systems and musical richness learning via neural models. Both subjective and objective experimental evaluations demonstrate that MeloForm generates melodies with precise musical form control with 97.79% accuracy, and outperforms baseline systems in terms of subjective evaluation score by 0.75, 0.50, 0.86 and 0.89 in structure, thematic, richness and overall quality, without any labelled musical form data. Besides, MeloForm can support various kinds of forms, such as verse and chorus form, rondo form, variational form, sonata form, etc.
Optical Music Recognition: State of the Art and Major Challenges
Jun 22, 2020

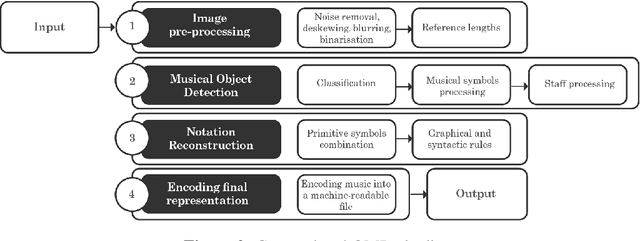
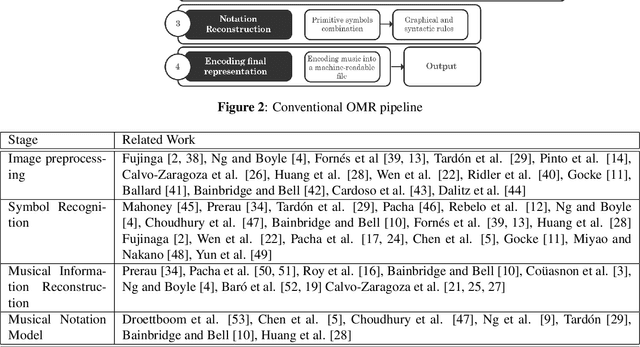
Optical Music Recognition (OMR) is concerned with transcribing sheet music into a machine-readable format. The transcribed copy should allow musicians to compose, play and edit music by taking a picture of a music sheet. Complete transcription of sheet music would also enable more efficient archival. OMR facilitates examining sheet music statistically or searching for patterns of notations, thus helping use cases in digital musicology too. Recently, there has been a shift in OMR from using conventional computer vision techniques towards a deep learning approach. In this paper, we review relevant works in OMR, including fundamental methods and significant outcomes, and highlight different stages of the OMR pipeline. These stages often lack standard input and output representation and standardised evaluation. Therefore, comparing different approaches and evaluating the impact of different processing methods can become rather complex. This paper provides recommendations for future work, addressing some of the highlighted issues and represents a position in furthering this important field of research.
cMelGAN: An Efficient Conditional Generative Model Based on Mel Spectrograms
May 15, 2022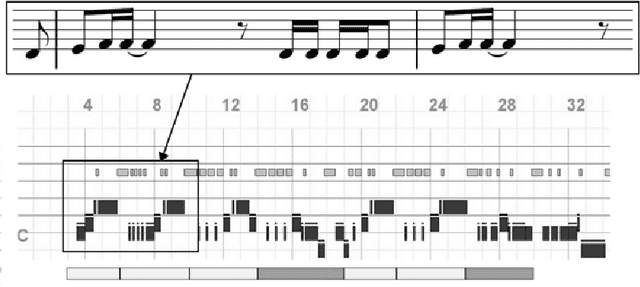
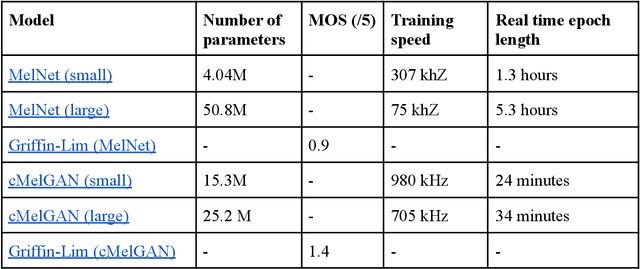

Analysing music in the field of machine learning is a very difficult problem with numerous constraints to consider. The nature of audio data, with its very high dimensionality and widely varying scales of structure, is one of the primary reasons why it is so difficult to model. There are many applications of machine learning in music, like the classifying the mood of a piece of music, conditional music generation, or popularity prediction. The goal for this project was to develop a genre-conditional generative model of music based on Mel spectrograms and evaluate its performance by comparing it to existing generative music models that use note-based representations. We initially implemented an autoregressive, RNN-based generative model called MelNet . However, due to its slow speed and low fidelity output, we decided to create a new, fully convolutional architecture that is based on the MelGAN [4] and conditional GAN architectures, called cMelGAN.
MidiBERT-Piano: Large-scale Pre-training for Symbolic Music Understanding
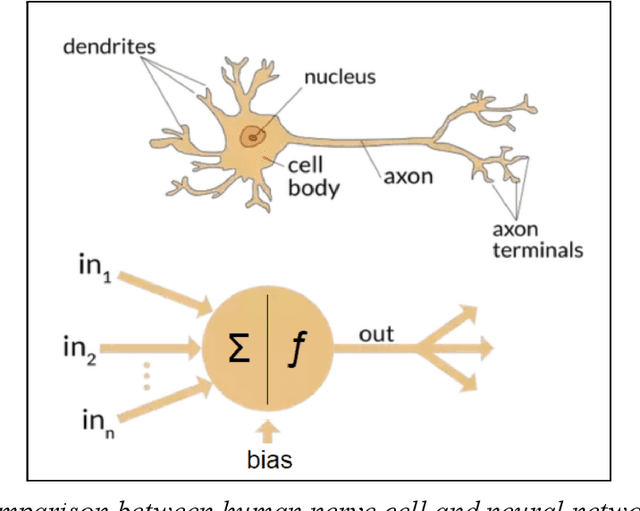
Jul 12, 2021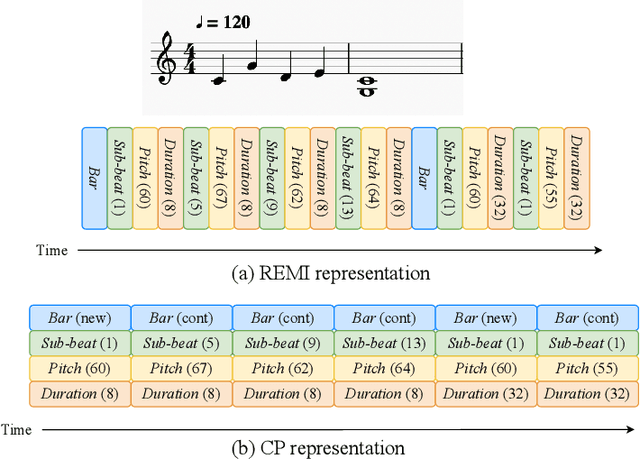
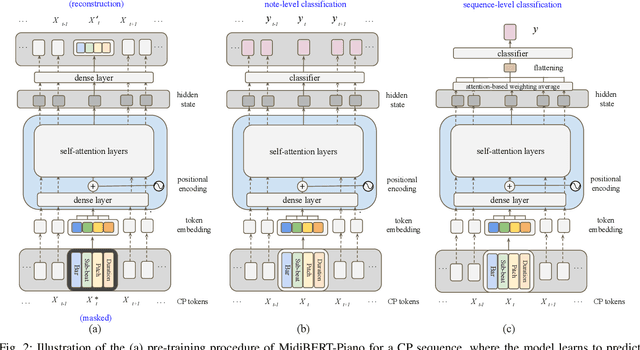
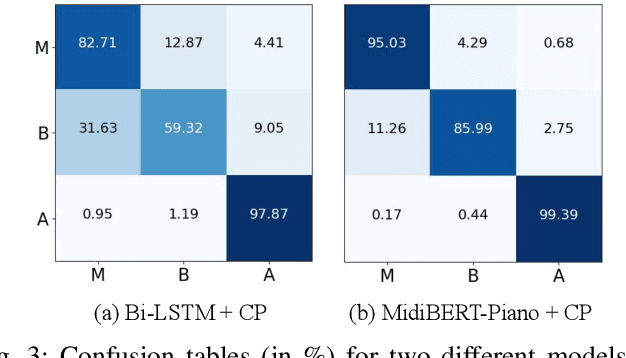
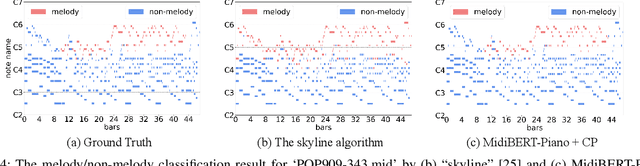
This paper presents an attempt to employ the mask language modeling approach of BERT to pre-train a 12-layer Transformer model over 4,166 pieces of polyphonic piano MIDI files for tackling a number of symbolic-domain discriminative music understanding tasks. These include two note-level classification tasks, i.e., melody extraction and velocity prediction, as well as two sequence-level classification tasks, i.e., composer classification and emotion classification. We find that, given a pre-trained Transformer, our models outperform recurrent neural network based baselines with less than 10 epochs of fine-tuning. Ablation studies show that the pre-training remains effective even if none of the MIDI data of the downstream tasks are seen at the pre-training stage, and that freezing the self-attention layers of the Transformer at the fine-tuning stage slightly degrades performance. All the five datasets employed in this work are publicly available, as well as checkpoints of our pre-trained and fine-tuned models. As such, our research can be taken as a benchmark for symbolic-domain music understanding.
Interpretable Melody Generation from Lyrics with Discrete-Valued Adversarial Training
Jun 30, 2022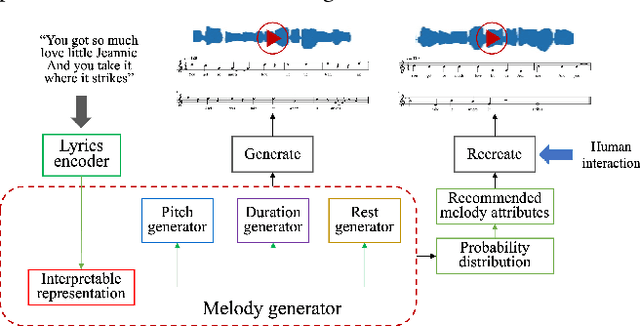
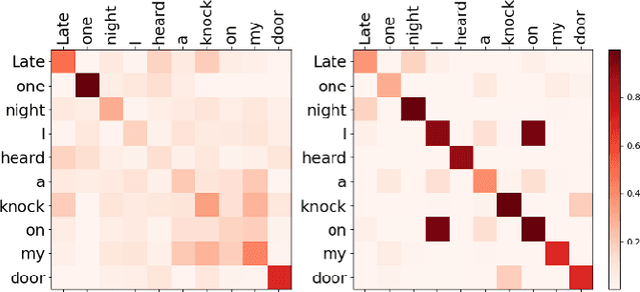

Generating melody from lyrics is an interesting yet challenging task in the area of artificial intelligence and music. However, the difficulty of keeping the consistency between input lyrics and generated melody limits the generation quality of previous works. In our proposal, we demonstrate our proposed interpretable lyrics-to-melody generation system which can interact with users to understand the generation process and recreate the desired songs. To improve the reliability of melody generation that matches lyrics, mutual information is exploited to strengthen the consistency between lyrics and generated melodies. Gumbel-Softmax is exploited to solve the non-differentiability problem of generating discrete music attributes by Generative Adversarial Networks (GANs). Moreover, the predicted probabilities output by the generator is utilized to recommend music attributes. Interacting with our lyrics-to-melody generation system, users can listen to the generated AI song as well as recreate a new song by selecting from recommended music attributes.
Learn to Dance with AIST++: Music Conditioned 3D Dance Generation
Feb 02, 2021

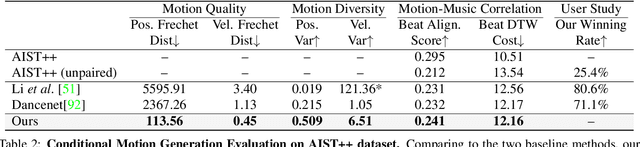

In this paper, we present a transformer-based learning framework for 3D dance generation conditioned on music. We carefully design our network architecture and empirically study the keys for obtaining qualitatively pleasing results. The critical components include a deep cross-modal transformer, which well learns the correlation between the music and dance motion; and the full-attention with future-N supervision mechanism which is essential in producing long-range non-freezing motion. In addition, we propose a new dataset of paired 3D motion and music called AIST++, which we reconstruct from the AIST multi-view dance videos. This dataset contains 1.1M frames of 3D dance motion in 1408 sequences, covering 10 genres of dance choreographies and accompanied with multi-view camera parameters. To our knowledge it is the largest dataset of this kind. Rich experiments on AIST++ demonstrate our method produces much better results than the state-of-the-art methods both qualitatively and quantitatively.
jaCappella Corpus: A Japanese a Cappella Vocal Ensemble Corpus
Dec 09, 2022


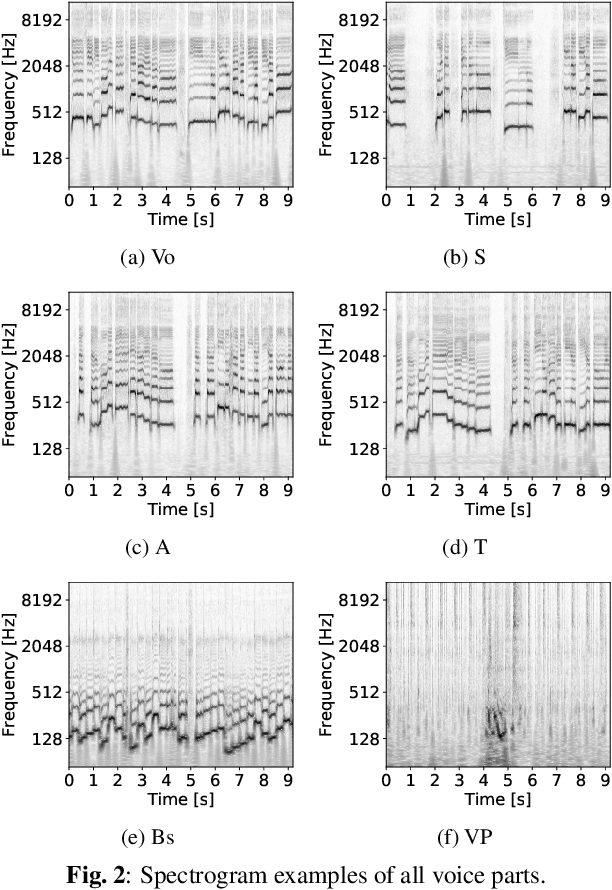
We construct a corpus of Japanese a cappella vocal ensembles (jaCappella corpus) for vocal ensemble separation and synthesis. It consists of 35 copyright-cleared vocal ensemble songs and their audio recordings of individual voice parts. These songs were arranged from out-of-copyright Japanese children's songs and have six voice parts (lead vocal, soprano, alto, tenor, bass, and vocal percussion). They are divided into seven subsets, each of which features typical characteristics of a music genre such as jazz and enka. The variety in genre and voice part match vocal ensembles recently widespread in social media services such as YouTube, although the main targets of conventional vocal ensemble datasets are choral singing made up of soprano, alto, tenor, and bass. Experimental evaluation demonstrates that our corpus is a challenging resource for vocal ensemble separation. Our corpus is available on our project page (https://tomohikonakamura.github.io/jaCappella_corpus/).