 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMD-Face: MoE-Enhanced Label-Free Disentangled Representation for Interactive Facial Attribute Editing
Apr 22, 2026GAN-based facial attribute editing is widely used in virtual avatars and social media but often suffers from attribute entanglement, where modifying one face attribute unintentionally alters others. While supervised disentangled representation learning can address this, it relies heavily on labeled data, incurring high annotation costs. To address these challenges, we propose MD-Face, a label-free disentangled representation learning framework based on Mixture of Experts (MoE). MD-Face utilizes a MoE backbone with a gating mechanism that dynamically allocates experts, enabling the model to learn semantic vectors with greater independence. To further enhance attribute entanglement, we introduce a geometry-aware loss, which aligns each semantic vector with its corresponding Semantic Boundary Vector (SBV) through a Jacobian-based pushforward method. Experiments with ProGAN and StyleGAN show that MD-Face outperforms unsupervised baselines and competes with supervised ones. Compared to diffusion-based methods, it offers better image quality and lower inference latency, making it ideal for interactive editing.
IGU-LoRA: Adaptive Rank Allocation via Integrated Gradients and Uncertainty-Aware Scoring
Mar 14, 2026As large language models (LLMs) scale to billions of parameters, full-parameter fine-tuning becomes compute- and memory-prohibitive. Parameter-efficient fine-tuning (PEFT) mitigates this issue by updating only a small set of task-specific parameters while keeping the base model frozen. Among PEFT approaches, low-rank adaptation (LoRA) is widely adopted; however, it enforces a uniform rank across layers despite substantial variation in layer importance, motivating {layerwise} rank allocation. Recent adaptive-rank variants (e.g., AdaLoRA) allocate ranks based on importance scores, yet typically rely on instantaneous gradients that capture only local sensitivity, overlooking non-local, pathwise effects within the same layer, which yields unstable and biased scores. To address this limitation, we introduce IGU-LoRA, an adaptive-rank LoRA that (i) computes within-layer Integrated Gradients (IG) sensitivities and aggregates them into a layer-level score for rank allocation, and (ii) applies an uncertainty-aware scheme using exponential moving averages with deviation tracking to suppress noisy updates and calibrate rank selection. Theoretically, we prove an upper bound on the composite trapezoidal rule approximation error for parameter-space IG under a pathwise Hessian-Lipschitz condition, which informs the quadrature budget. Across diverse tasks and architectures, IGU-LoRA consistently outperforms strong PEFT baselines at matched parameter budgets, improving downstream accuracy and robustness. Ablations confirm the contributions of pathwise within-layer sensitivity estimates and uncertainty-aware selection to effective rank allocation. Our code is publicly available at https://github.com/withyou12/igulora.git
U-Face: An Efficient and Generalizable Framework for Unsupervised Facial Attribute Editing via Subspace Learning
Mar 14, 2026Latent space-based facial attribute editing methods have gained popularity in applications such as digital entertainment, virtual avatar creation, and human-computer interaction systems due to their potential for efficient and flexible attribute manipulation, particularly for continuous edits. Among these, unsupervised latent space-based methods, which discover effective semantic vectors without relying on labeled data, have attracted considerable attention in the research community. However, existing methods still encounter difficulties in disentanglement, as manipulating a specific facial attribute may unintentionally affect other attributes, complicating fine-grained controllability. To address these challenges, we propose a novel framework designed to offer an effective and adaptable solution for unsupervised facial attribute editing, called Unsupervised Facial Attribute Controllable Editing (U-Face). The proposed method frames semantic vector learning as a subspace learning problem, where latent vectors are approximated within a lower-dimensional semantic subspace spanned by a semantic vector matrix. This formulation can also be equivalently interpreted from a projection-reconstruction perspective and further generalized into an autoencoder framework, providing a foundation that can support disentangled representation learning in a flexible manner. To improve disentanglement and controllability, we impose orthogonal non-negative constraints on the semantic vectors and incorporate attribute boundary vectors to reduce entanglement in the learned directions. Although these constraints make the optimization problem challenging, we design an alternating iterative algorithm, called Alternating Iterative Disentanglement and Controllability (AIDC), with closed-form updates and provable convergence under specific conditions.
Bandwidth-constrained Variational Message Encoding for Cooperative Multi-agent Reinforcement Learning
Dec 11, 2025Graph-based multi-agent reinforcement learning (MARL) enables coordinated behavior under partial observability by modeling agents as nodes and communication links as edges. While recent methods excel at learning sparse coordination graphs-determining who communicates with whom-they do not address what information should be transmitted under hard bandwidth constraints. We study this bandwidth-limited regime and show that naive dimensionality reduction consistently degrades coordination performance. Hard bandwidth constraints force selective encoding, but deterministic projections lack mechanisms to control how compression occurs. We introduce Bandwidth-constrained Variational Message Encoding (BVME), a lightweight module that treats messages as samples from learned Gaussian posteriors regularized via KL divergence to an uninformative prior. BVME's variational framework provides principled, tunable control over compression strength through interpretable hyperparameters, directly constraining the representations used for decision-making. Across SMACv1, SMACv2, and MPE benchmarks, BVME achieves comparable or superior performance while using 67--83% fewer message dimensions, with gains most pronounced on sparse graphs where message quality critically impacts coordination. Ablations reveal U-shaped sensitivity to bandwidth, with BVME excelling at extreme ratios while adding minimal overhead.
Group-Aware Coordination Graph for Multi-Agent Reinforcement Learning
Apr 17, 2024Cooperative Multi-Agent Reinforcement Learning (MARL) necessitates seamless collaboration among agents, often represented by an underlying relation graph. Existing methods for learning this graph primarily focus on agent-pair relations, neglecting higher-order relationships. While several approaches attempt to extend cooperation modelling to encompass behaviour similarities within groups, they commonly fall short in concurrently learning the latent graph, thereby constraining the information exchange among partially observed agents. To overcome these limitations, we present a novel approach to infer the Group-Aware Coordination Graph (GACG), which is designed to capture both the cooperation between agent pairs based on current observations and group-level dependencies from behaviour patterns observed across trajectories. This graph is further used in graph convolution for information exchange between agents during decision-making. To further ensure behavioural consistency among agents within the same group, we introduce a group distance loss, which promotes group cohesion and encourages specialization between groups. Our evaluations, conducted on StarCraft II micromanagement tasks, demonstrate GACG's superior performance. An ablation study further provides experimental evidence of the effectiveness of each component of our method.
Inferring Latent Temporal Sparse Coordination Graph for Multi-Agent Reinforcement Learning
Mar 28, 2024



Effective agent coordination is crucial in cooperative Multi-Agent Reinforcement Learning (MARL). While agent cooperation can be represented by graph structures, prevailing graph learning methods in MARL are limited. They rely solely on one-step observations, neglecting crucial historical experiences, leading to deficient graphs that foster redundant or detrimental information exchanges. Additionally, high computational demands for action-pair calculations in dense graphs impede scalability. To address these challenges, we propose inferring a Latent Temporal Sparse Coordination Graph (LTS-CG) for MARL. The LTS-CG leverages agents' historical observations to calculate an agent-pair probability matrix, where a sparse graph is sampled from and used for knowledge exchange between agents, thereby simultaneously capturing agent dependencies and relation uncertainty. The computational complexity of this procedure is only related to the number of agents. This graph learning process is further augmented by two innovative characteristics: Predict-Future, which enables agents to foresee upcoming observations, and Infer-Present, ensuring a thorough grasp of the environmental context from limited data. These features allow LTS-CG to construct temporal graphs from historical and real-time information, promoting knowledge exchange during policy learning and effective collaboration. Graph learning and agent training occur simultaneously in an end-to-end manner. Our demonstrated results on the StarCraft II benchmark underscore LTS-CG's superior performance.
Layer-diverse Negative Sampling for Graph Neural Networks
Mar 18, 2024



Graph neural networks (GNNs) are a powerful solution for various structure learning applications due to their strong representation capabilities for graph data. However, traditional GNNs, relying on message-passing mechanisms that gather information exclusively from first-order neighbours (known as positive samples), can lead to issues such as over-smoothing and over-squashing. To mitigate these issues, we propose a layer-diverse negative sampling method for message-passing propagation. This method employs a sampling matrix within a determinantal point process, which transforms the candidate set into a space and selectively samples from this space to generate negative samples. To further enhance the diversity of the negative samples during each forward pass, we develop a space-squeezing method to achieve layer-wise diversity in multi-layer GNNs. Experiments on various real-world graph datasets demonstrate the effectiveness of our approach in improving the diversity of negative samples and overall learning performance. Moreover, adding negative samples dynamically changes the graph's topology, thus with the strong potential to improve the expressiveness of GNNs and reduce the risk of over-squashing.
Predicting Single-cell Drug Sensitivity by Adaptive Weighted Feature for Adversarial Multi-source Domain Adaptation
Mar 08, 2024



The development of single-cell sequencing technology had promoted the generation of a large amount of single-cell transcriptional profiles, providing valuable opportunities to explore drug-resistant cell subpopulations in a tumor. However, the drug sensitivity data in single-cell level is still scarce to date, pressing an urgent and highly challenging task for computational prediction of the drug sensitivity to individual cells. This paper proposed scAdaDrug, a multi-source adaptive weighting model to predict single-cell drug sensitivity. We used an autoencoder to extract domain-invariant features related to drug sensitivity from multiple source domains by exploiting adversarial domain adaptation. Especially, we introduced an adaptive weight generator to produce importance-aware and mutual independent weights, which could adaptively modulate the embedding of each sample in dimension-level for both source and target domains. Extensive experimental results showed that our model achieved state-of-the-art performance in predicting drug sensitivity on sinle-cell datasets, as well as on cell line and patient datasets.
Graph Convolutional Neural Networks with Diverse Negative Samples via Decomposed Determinant Point Processes
Dec 05, 2022Graph convolutional networks (GCNs) have achieved great success in graph representation learning by extracting high-level features from nodes and their topology. Since GCNs generally follow a message-passing mechanism, each node aggregates information from its first-order neighbour to update its representation. As a result, the representations of nodes with edges between them should be positively correlated and thus can be considered positive samples. However, there are more non-neighbour nodes in the whole graph, which provide diverse and useful information for the representation update. Two non-adjacent nodes usually have different representations, which can be seen as negative samples. Besides the node representations, the structural information of the graph is also crucial for learning. In this paper, we used quality-diversity decomposition in determinant point processes (DPP) to obtain diverse negative samples. When defining a distribution on diverse subsets of all non-neighbouring nodes, we incorporate both graph structure information and node representations. Since the DPP sampling process requires matrix eigenvalue decomposition, we propose a new shortest-path-base method to improve computational efficiency. Finally, we incorporate the obtained negative samples into the graph convolution operation. The ideas are evaluated empirically in experiments on node classification tasks. These experiments show that the newly proposed methods not only improve the overall performance of standard representation learning but also significantly alleviate over-smoothing problems.
Learning from the Dark: Boosting Graph Convolutional Neural Networks with Diverse Negative Samples
Oct 03, 2022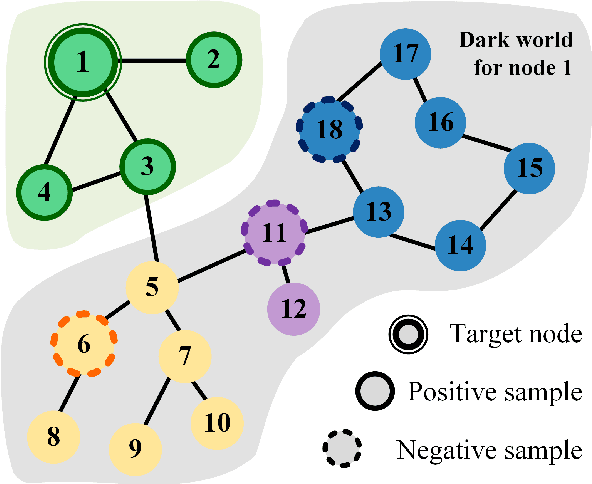

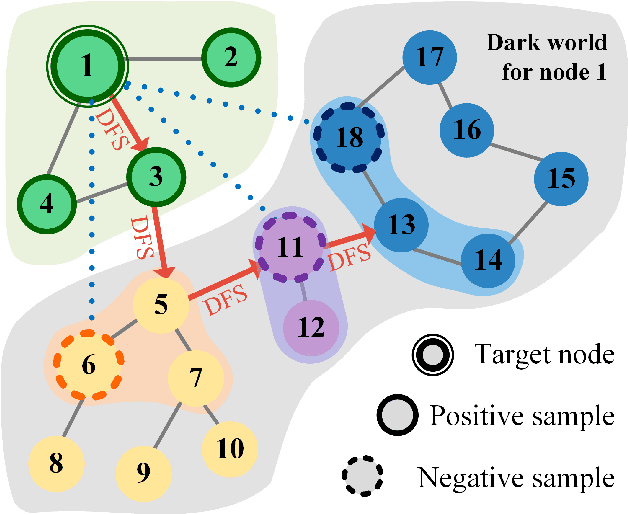
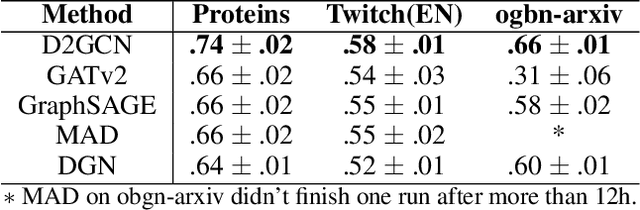
Graph Convolutional Neural Networks (GCNs) has been generally accepted to be an effective tool for node representations learning. An interesting way to understand GCNs is to think of them as a message passing mechanism where each node updates its representation by accepting information from its neighbours (also known as positive samples). However, beyond these neighbouring nodes, graphs have a large, dark, all-but forgotten world in which we find the non-neighbouring nodes (negative samples). In this paper, we show that this great dark world holds a substantial amount of information that might be useful for representation learning. Most specifically, it can provide negative information about the node representations. Our overall idea is to select appropriate negative samples for each node and incorporate the negative information contained in these samples into the representation updates. Moreover, we show that the process of selecting the negative samples is not trivial. Our theme therefore begins by describing the criteria for a good negative sample, followed by a determinantal point process algorithm for efficiently obtaining such samples. A GCN, boosted by diverse negative samples, then jointly considers the positive and negative information when passing messages. Experimental evaluations show that this idea not only improves the overall performance of standard representation learning but also significantly alleviates over-smoothing problems.