 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Dance with AIST++: Music Conditioned 3D Dance Generation
Paper and Code


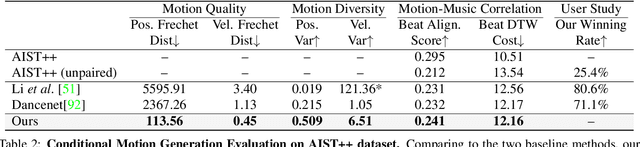

In this paper, we present a transformer-based learning framework for 3D dance generation conditioned on music. We carefully design our network architecture and empirically study the keys for obtaining qualitatively pleasing results. The critical components include a deep cross-modal transformer, which well learns the correlation between the music and dance motion; and the full-attention with future-N supervision mechanism which is essential in producing long-range non-freezing motion. In addition, we propose a new dataset of paired 3D motion and music called AIST++, which we reconstruct from the AIST multi-view dance videos. This dataset contains 1.1M frames of 3D dance motion in 1408 sequences, covering 10 genres of dance choreographies and accompanied with multi-view camera parameters. To our knowledge it is the largest dataset of this kind. Rich experiments on AIST++ demonstrate our method produces much better results than the state-of-the-art methods both qualitatively and quantitatively.