 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Towards Geometric-Photometric Joint Alignment for Facial Mesh Registration
Mar 05, 2024
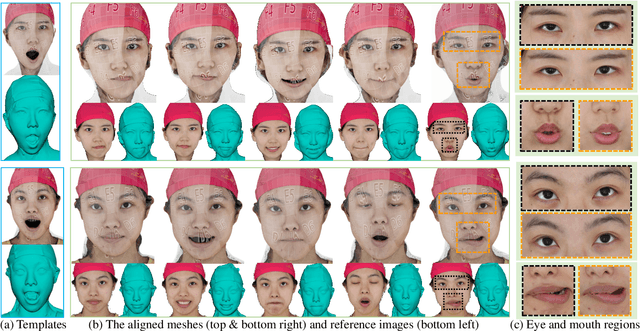
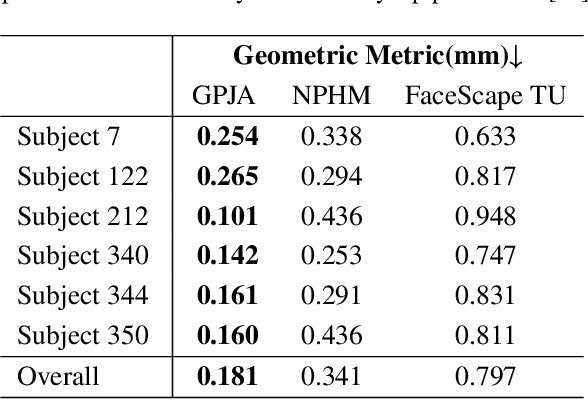
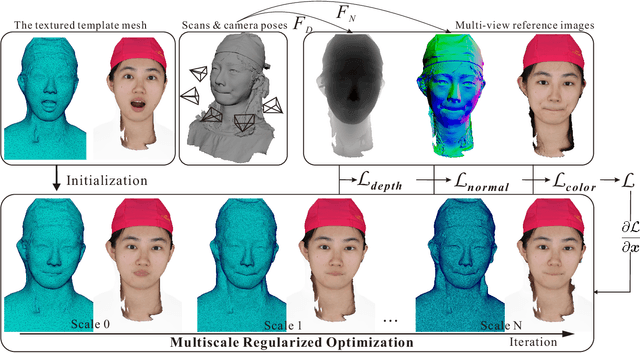

This paper presents a Geometric-Photometric Joint Alignment(GPJA) method, for accurately aligning human expressions by combining geometry and photometric information. Common practices for registering human heads typically involve aligning landmarks with facial template meshes using geometry processing approaches, but often overlook photometric consistency. GPJA overcomes this limitation by leveraging differentiable rendering to align vertices with target expressions, achieving joint alignment in geometry and photometric appearances automatically, without the need for semantic annotation or aligned meshes for training. It features a holistic rendering alignment strategy and a multiscale regularized optimization for robust and fast convergence. The method utilizes derivatives at vertex positions for supervision and employs a gradient-based algorithm which guarantees smoothness and avoids topological defects during the geometry evolution. Experimental results demonstrate faithful alignment under various expressions, surpassing the conventional ICP-based methods and the state-of-the-art deep learning based method. In practical, our method enhances the efficiency of obtaining topology-consistent face models from multi-view stereo facial scanning.
Rethinking Self-training for Semi-supervised Landmark Detection: A Selection-free Approach
Apr 06, 2024Self-training is a simple yet effective method for semi-supervised learning, during which pseudo-label selection plays an important role for handling confirmation bias. Despite its popularity, applying self-training to landmark detection faces three problems: 1) The selected confident pseudo-labels often contain data bias, which may hurt model performance; 2) It is not easy to decide a proper threshold for sample selection as the localization task can be sensitive to noisy pseudo-labels; 3) coordinate regression does not output confidence, making selection-based self-training infeasible. To address the above issues, we propose Self-Training for Landmark Detection (STLD), a method that does not require explicit pseudo-label selection. Instead, STLD constructs a task curriculum to deal with confirmation bias, which progressively transitions from more confident to less confident tasks over the rounds of self-training. Pseudo pretraining and shrink regression are two essential components for such a curriculum, where the former is the first task of the curriculum for providing a better model initialization and the latter is further added in the later rounds to directly leverage the pseudo-labels in a coarse-to-fine manner. Experiments on three facial and one medical landmark detection benchmark show that STLD outperforms the existing methods consistently in both semi- and omni-supervised settings.
GiMeFive: Towards Interpretable Facial Emotion Classification
Feb 24, 2024Deep convolutional neural networks have been shown to successfully recognize facial emotions for the past years in the realm of computer vision. However, the existing detection approaches are not always reliable or explainable, we here propose our model GiMeFive with interpretations, i.e., via layer activations and gradient-weighted class activation mapping. We compare against the state-of-the-art methods to classify the six facial emotions. Empirical results show that our model outperforms the previous methods in terms of accuracy on two Facial Emotion Recognition (FER) benchmarks and our aggregated FER GiMeFive. Furthermore, we explain our work in real-world image and video examples, as well as real-time live camera streams. Our code and supplementary material are available at https: //github.com/werywjw/SEP-CVDL.
LCM-Lookahead for Encoder-based Text-to-Image Personalization
Apr 04, 2024Recent advancements in diffusion models have introduced fast sampling methods that can effectively produce high-quality images in just one or a few denoising steps. Interestingly, when these are distilled from existing diffusion models, they often maintain alignment with the original model, retaining similar outputs for similar prompts and seeds. These properties present opportunities to leverage fast sampling methods as a shortcut-mechanism, using them to create a preview of denoised outputs through which we can backpropagate image-space losses. In this work, we explore the potential of using such shortcut-mechanisms to guide the personalization of text-to-image models to specific facial identities. We focus on encoder-based personalization approaches, and demonstrate that by tuning them with a lookahead identity loss, we can achieve higher identity fidelity, without sacrificing layout diversity or prompt alignment. We further explore the use of attention sharing mechanisms and consistent data generation for the task of personalization, and find that encoder training can benefit from both.
Towards Variable and Coordinated Holistic Co-Speech Motion Generation
Mar 30, 2024This paper addresses the problem of generating lifelike holistic co-speech motions for 3D avatars, focusing on two key aspects: variability and coordination. Variability allows the avatar to exhibit a wide range of motions even with similar speech content, while coordination ensures a harmonious alignment among facial expressions, hand gestures, and body poses. We aim to achieve both with ProbTalk, a unified probabilistic framework designed to jointly model facial, hand, and body movements in speech. ProbTalk builds on the variational autoencoder (VAE) architecture and incorporates three core designs. First, we introduce product quantization (PQ) to the VAE, which enriches the representation of complex holistic motion. Second, we devise a novel non-autoregressive model that embeds 2D positional encoding into the product-quantized representation, thereby preserving essential structure information of the PQ codes. Last, we employ a secondary stage to refine the preliminary prediction, further sharpening the high-frequency details. Coupling these three designs enables ProbTalk to generate natural and diverse holistic co-speech motions, outperforming several state-of-the-art methods in qualitative and quantitative evaluations, particularly in terms of realism. Our code and model will be released for research purposes at https://feifeifeiliu.github.io/probtalk/.
X-Portrait: Expressive Portrait Animation with Hierarchical Motion Attention
Mar 27, 2024We propose X-Portrait, an innovative conditional diffusion model tailored for generating expressive and temporally coherent portrait animation. Specifically, given a single portrait as appearance reference, we aim to animate it with motion derived from a driving video, capturing both highly dynamic and subtle facial expressions along with wide-range head movements. As its core, we leverage the generative prior of a pre-trained diffusion model as the rendering backbone, while achieve fine-grained head pose and expression control with novel controlling signals within the framework of ControlNet. In contrast to conventional coarse explicit controls such as facial landmarks, our motion control module is learned to interpret the dynamics directly from the original driving RGB inputs. The motion accuracy is further enhanced with a patch-based local control module that effectively enhance the motion attention to small-scale nuances like eyeball positions. Notably, to mitigate the identity leakage from the driving signals, we train our motion control modules with scaling-augmented cross-identity images, ensuring maximized disentanglement from the appearance reference modules. Experimental results demonstrate the universal effectiveness of X-Portrait across a diverse range of facial portraits and expressive driving sequences, and showcase its proficiency in generating captivating portrait animations with consistently maintained identity characteristics.
Talk3D: High-Fidelity Talking Portrait Synthesis via Personalized 3D Generative Prior
Mar 29, 2024
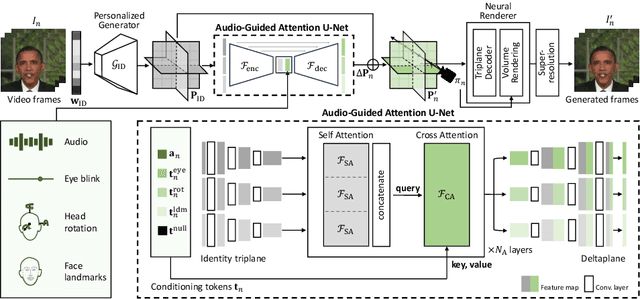

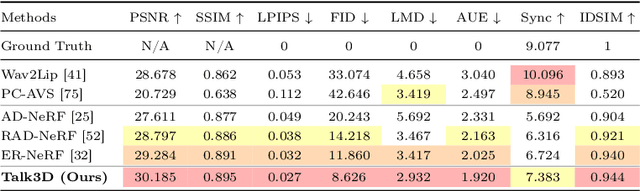
Recent methods for audio-driven talking head synthesis often optimize neural radiance fields (NeRF) on a monocular talking portrait video, leveraging its capability to render high-fidelity and 3D-consistent novel-view frames. However, they often struggle to reconstruct complete face geometry due to the absence of comprehensive 3D information in the input monocular videos. In this paper, we introduce a novel audio-driven talking head synthesis framework, called Talk3D, that can faithfully reconstruct its plausible facial geometries by effectively adopting the pre-trained 3D-aware generative prior. Given the personalized 3D generative model, we present a novel audio-guided attention U-Net architecture that predicts the dynamic face variations in the NeRF space driven by audio. Furthermore, our model is further modulated by audio-unrelated conditioning tokens which effectively disentangle variations unrelated to audio features. Compared to existing methods, our method excels in generating realistic facial geometries even under extreme head poses. We also conduct extensive experiments showing our approach surpasses state-of-the-art benchmarks in terms of both quantitative and qualitative evaluations.
MI-NeRF: Learning a Single Face NeRF from Multiple Identities
Mar 29, 2024
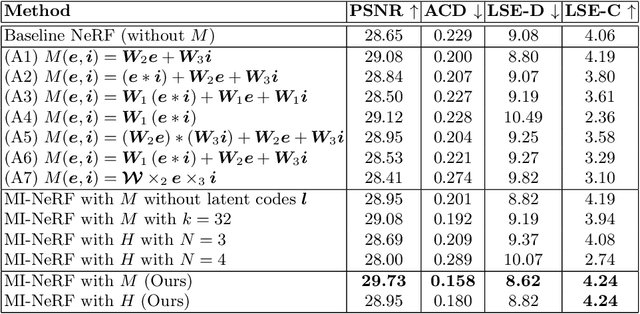
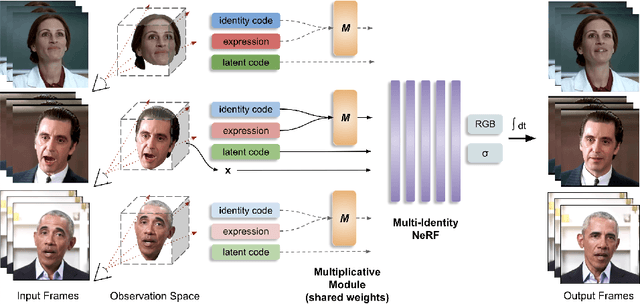
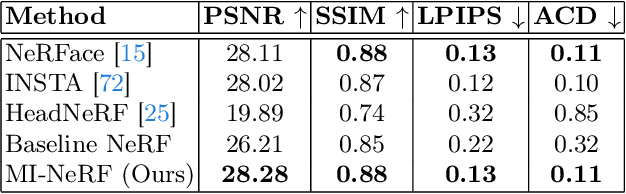
In this work, we introduce a method that learns a single dynamic neural radiance field (NeRF) from monocular talking face videos of multiple identities. NeRFs have shown remarkable results in modeling the 4D dynamics and appearance of human faces. However, they require per-identity optimization. Although recent approaches have proposed techniques to reduce the training and rendering time, increasing the number of identities can be expensive. We introduce MI-NeRF (multi-identity NeRF), a single unified network that models complex non-rigid facial motion for multiple identities, using only monocular videos of arbitrary length. The core premise in our method is to learn the non-linear interactions between identity and non-identity specific information with a multiplicative module. By training on multiple videos simultaneously, MI-NeRF not only reduces the total training time compared to standard single-identity NeRFs, but also demonstrates robustness in synthesizing novel expressions for any input identity. We present results for both facial expression transfer and talking face video synthesis. Our method can be further personalized for a target identity given only a short video.
Distributionally Generative Augmentation for Fair Facial Attribute Classification
Mar 11, 2024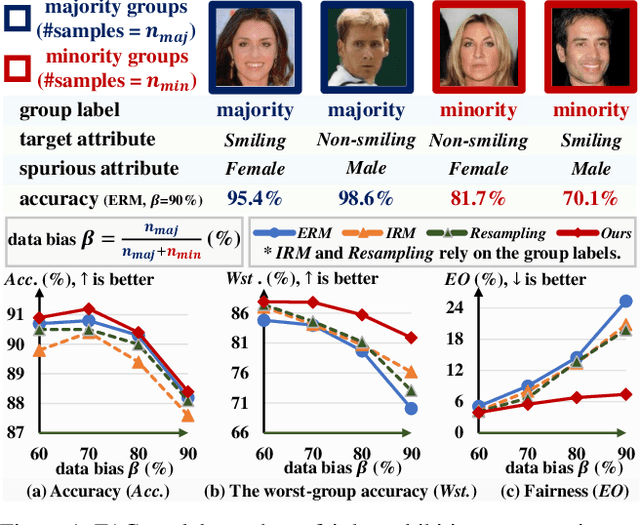
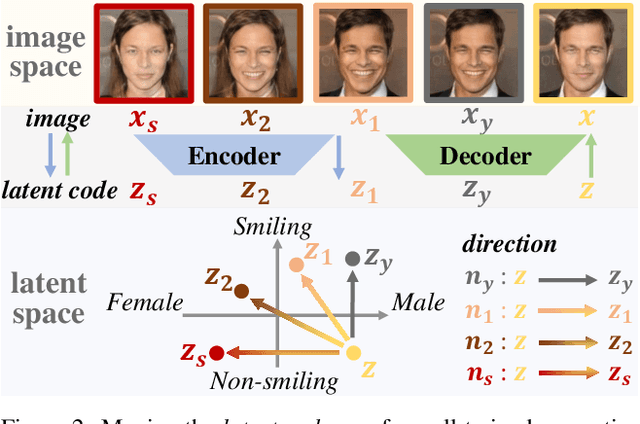

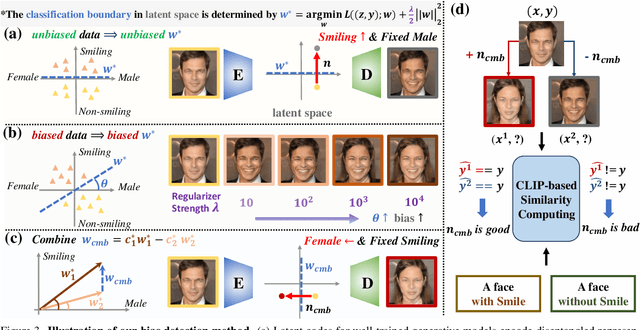
Facial Attribute Classification (FAC) holds substantial promise in widespread applications. However, FAC models trained by traditional methodologies can be unfair by exhibiting accuracy inconsistencies across varied data subpopulations. This unfairness is largely attributed to bias in data, where some spurious attributes (e.g., Male) statistically correlate with the target attribute (e.g., Smiling). Most of existing fairness-aware methods rely on the labels of spurious attributes, which may be unavailable in practice. This work proposes a novel, generation-based two-stage framework to train a fair FAC model on biased data without additional annotation. Initially, we identify the potential spurious attributes based on generative models. Notably, it enhances interpretability by explicitly showing the spurious attributes in image space. Following this, for each image, we first edit the spurious attributes with a random degree sampled from a uniform distribution, while keeping target attribute unchanged. Then we train a fair FAC model by fostering model invariance to these augmentation. Extensive experiments on three common datasets demonstrate the effectiveness of our method in promoting fairness in FAC without compromising accuracy. Codes are in https://github.com/heqianpei/DiGA.
Analyzing Participants' Engagement during Online Meetings Using Unsupervised Remote Photoplethysmography with Behavioral Features
Apr 05, 2024Engagement measurement finds application in healthcare, education, advertisement, and services. The use of physiological and behavioral features is viable, but the impracticality of traditional physiological measurement arises due to the need for contact sensors. We demonstrate the feasibility of unsupervised remote photoplethysmography (rPPG) as an alternative for contact sensors in deriving heart rate variability (HRV) features, then fusing these with behavioral features to measure engagement in online group meetings. Firstly, a unique Engagement Dataset of online interactions among social workers is collected with granular engagement labels, offering insight into virtual meeting dynamics. Secondly, a pre-trained rPPG model is customized to reconstruct accurate rPPG signals from video meetings in an unsupervised manner, enabling the calculation of HRV features. Thirdly, the feasibility of estimating engagement from HRV features using short observation windows, with a notable enhancement when using longer observation windows of two to four minutes, is demonstrated. Fourthly, the effectiveness of behavioral cues is evaluated and fused with physiological data, which further enhances engagement estimation performance. An accuracy of 94% is achieved when only HRV features are used, eliminating the need for contact sensors or ground truth signals. The incorporation of behavioral cues raises the accuracy to 96%. Facial video analysis offers precise engagement measurement, beneficial for future applications.