 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
SPHEAR: Spherical Head Registration for Complete Statistical 3D Modeling
Nov 04, 2023



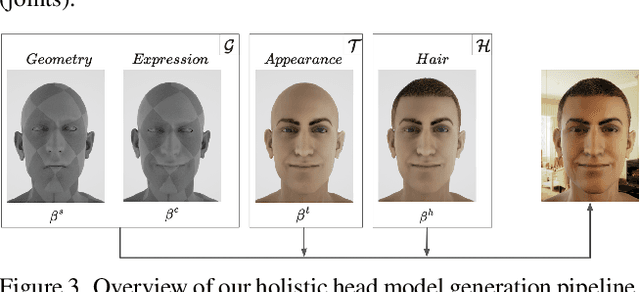
We present \emph{SPHEAR}, an accurate, differentiable parametric statistical 3D human head model, enabled by a novel 3D registration method based on spherical embeddings. We shift the paradigm away from the classical Non-Rigid Registration methods, which operate under various surface priors, increasing reconstruction fidelity and minimizing required human intervention. Additionally, SPHEAR is a \emph{complete} model that allows not only to sample diverse synthetic head shapes and facial expressions, but also gaze directions, high-resolution color textures, surface normal maps, and hair cuts represented in detail, as strands. SPHEAR can be used for automatic realistic visual data generation, semantic annotation, and general reconstruction tasks. Compared to state-of-the-art approaches, our components are fast and memory efficient, and experiments support the validity of our design choices and the accuracy of registration, reconstruction and generation techniques.
Conversation Understanding using Relational Temporal Graph Neural Networks with Auxiliary Cross-Modality Interaction
Nov 08, 2023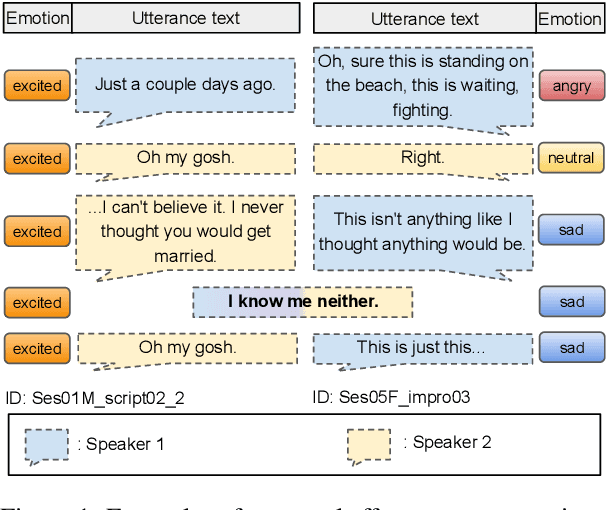
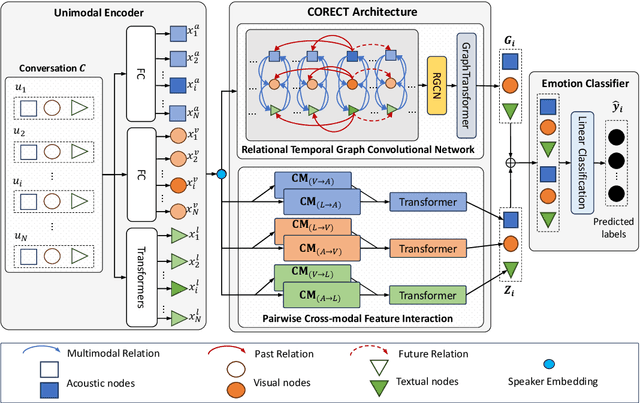
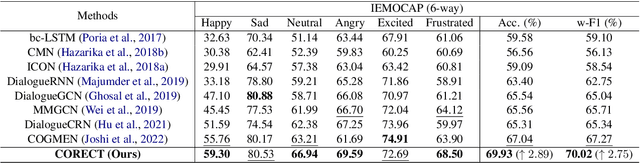
Emotion recognition is a crucial task for human conversation understanding. It becomes more challenging with the notion of multimodal data, e.g., language, voice, and facial expressions. As a typical solution, the global- and the local context information are exploited to predict the emotional label for every single sentence, i.e., utterance, in the dialogue. Specifically, the global representation could be captured via modeling of cross-modal interactions at the conversation level. The local one is often inferred using the temporal information of speakers or emotional shifts, which neglects vital factors at the utterance level. Additionally, most existing approaches take fused features of multiple modalities in an unified input without leveraging modality-specific representations. Motivating from these problems, we propose the Relational Temporal Graph Neural Network with Auxiliary Cross-Modality Interaction (CORECT), an novel neural network framework that effectively captures conversation-level cross-modality interactions and utterance-level temporal dependencies with the modality-specific manner for conversation understanding. Extensive experiments demonstrate the effectiveness of CORECT via its state-of-the-art results on the IEMOCAP and CMU-MOSEI datasets for the multimodal ERC task.
E4S: Fine-grained Face Swapping via Editing With Regional GAN Inversion
Oct 23, 2023
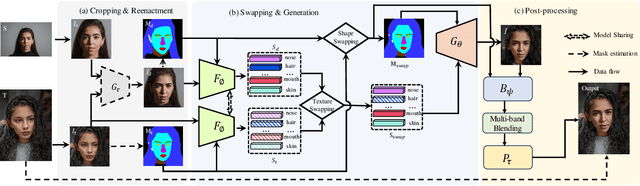
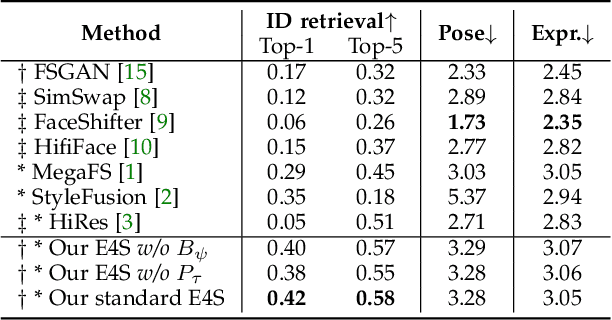
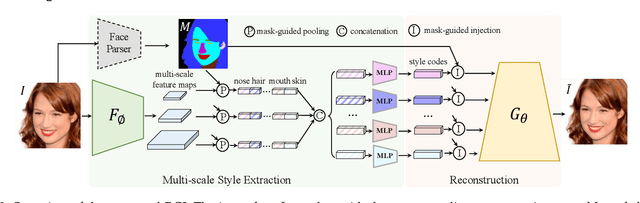
This paper proposes a novel approach to face swapping from the perspective of fine-grained facial editing, dubbed "editing for swapping" (E4S). The traditional face swapping methods rely on global feature extraction and often fail to preserve the source identity. In contrast, our framework proposes a Regional GAN Inversion (RGI) method, which allows the explicit disentanglement of shape and texture. Specifically, our E4S performs face swapping in the latent space of a pretrained StyleGAN, where a multi-scale mask-guided encoder is applied to project the texture of each facial component into regional style codes and a mask-guided injection module then manipulates feature maps with the style codes. Based on this disentanglement, face swapping can be simplified as style and mask swapping. Besides, since reconstructing the source face in the target image may lead to disharmony lighting, we propose to train a re-coloring network to make the swapped face maintain the lighting condition on the target face. Further, to deal with the potential mismatch area during mask exchange, we designed a face inpainting network as post-processing. The extensive comparisons with state-of-the-art methods demonstrate that our E4S outperforms existing methods in preserving texture, shape, and lighting. Our implementation is available at https://github.com/e4s2023/E4S2023.
Latent-OFER: Detect, Mask, and Reconstruct with Latent Vectors for Occluded Facial Expression Recognition
Jul 21, 2023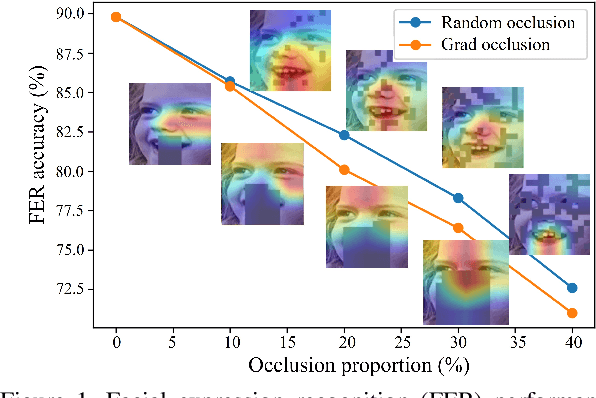

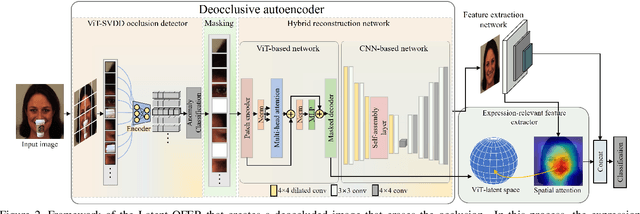
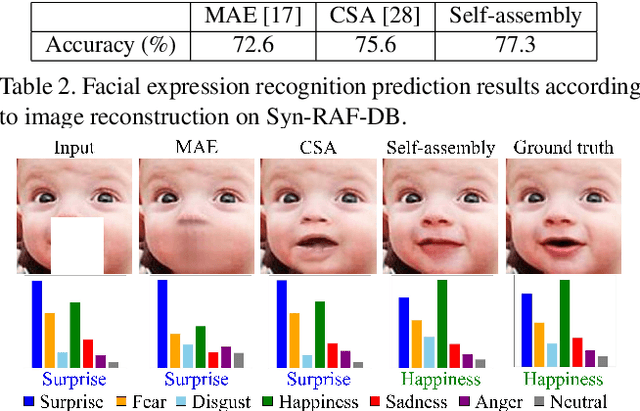
Most research on facial expression recognition (FER) is conducted in highly controlled environments, but its performance is often unacceptable when applied to real-world situations. This is because when unexpected objects occlude the face, the FER network faces difficulties extracting facial features and accurately predicting facial expressions. Therefore, occluded FER (OFER) is a challenging problem. Previous studies on occlusion-aware FER have typically required fully annotated facial images for training. However, collecting facial images with various occlusions and expression annotations is time-consuming and expensive. Latent-OFER, the proposed method, can detect occlusions, restore occluded parts of the face as if they were unoccluded, and recognize them, improving FER accuracy. This approach involves three steps: First, the vision transformer (ViT)-based occlusion patch detector masks the occluded position by training only latent vectors from the unoccluded patches using the support vector data description algorithm. Second, the hybrid reconstruction network generates the masking position as a complete image using the ViT and convolutional neural network (CNN). Last, the expression-relevant latent vector extractor retrieves and uses expression-related information from all latent vectors by applying a CNN-based class activation map. This mechanism has a significant advantage in preventing performance degradation from occlusion by unseen objects. The experimental results on several databases demonstrate the superiority of the proposed method over state-of-the-art methods.
High-Fidelity 3D Head Avatars Reconstruction through Spatially-Varying Expression Conditioned Neural Radiance Field
Oct 10, 2023One crucial aspect of 3D head avatar reconstruction lies in the details of facial expressions. Although recent NeRF-based photo-realistic 3D head avatar methods achieve high-quality avatar rendering, they still encounter challenges retaining intricate facial expression details because they overlook the potential of specific expression variations at different spatial positions when conditioning the radiance field. Motivated by this observation, we introduce a novel Spatially-Varying Expression (SVE) conditioning. The SVE can be obtained by a simple MLP-based generation network, encompassing both spatial positional features and global expression information. Benefiting from rich and diverse information of the SVE at different positions, the proposed SVE-conditioned neural radiance field can deal with intricate facial expressions and achieve realistic rendering and geometry details of high-fidelity 3D head avatars. Additionally, to further elevate the geometric and rendering quality, we introduce a new coarse-to-fine training strategy, including a geometry initialization strategy at the coarse stage and an adaptive importance sampling strategy at the fine stage. Extensive experiments indicate that our method outperforms other state-of-the-art (SOTA) methods in rendering and geometry quality on mobile phone-collected and public datasets.
Robust Sequential DeepFake Detection
Sep 26, 2023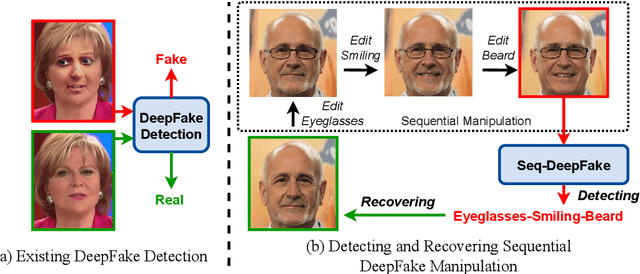
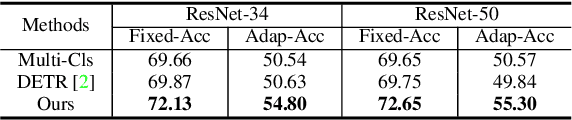
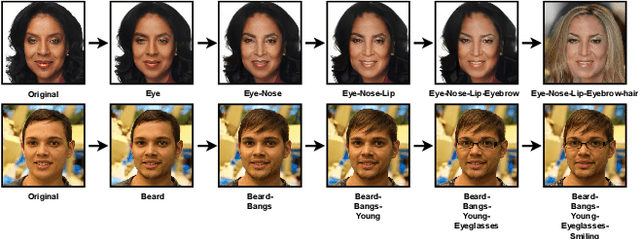
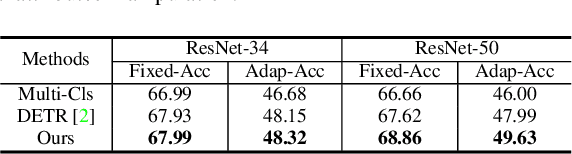
Since photorealistic faces can be readily generated by facial manipulation technologies nowadays, potential malicious abuse of these technologies has drawn great concerns. Numerous deepfake detection methods are thus proposed. However, existing methods only focus on detecting one-step facial manipulation. As the emergence of easy-accessible facial editing applications, people can easily manipulate facial components using multi-step operations in a sequential manner. This new threat requires us to detect a sequence of facial manipulations, which is vital for both detecting deepfake media and recovering original faces afterwards. Motivated by this observation, we emphasize the need and propose a novel research problem called Detecting Sequential DeepFake Manipulation (Seq-DeepFake). Unlike the existing deepfake detection task only demanding a binary label prediction, detecting Seq-DeepFake manipulation requires correctly predicting a sequential vector of facial manipulation operations. To support a large-scale investigation, we construct the first Seq-DeepFake dataset, where face images are manipulated sequentially with corresponding annotations of sequential facial manipulation vectors. Based on this new dataset, we cast detecting Seq-DeepFake manipulation as a specific image-to-sequence task and propose a concise yet effective Seq-DeepFake Transformer (SeqFakeFormer). To better reflect real-world deepfake data distributions, we further apply various perturbations on the original Seq-DeepFake dataset and construct the more challenging Sequential DeepFake dataset with perturbations (Seq-DeepFake-P). To exploit deeper correlation between images and sequences when facing Seq-DeepFake-P, a dedicated Seq-DeepFake Transformer with Image-Sequence Reasoning (SeqFakeFormer++) is devised, which builds stronger correspondence between image-sequence pairs for more robust Seq-DeepFake detection.
Facial Expression Re-targeting from a Single Character
Jun 21, 2023

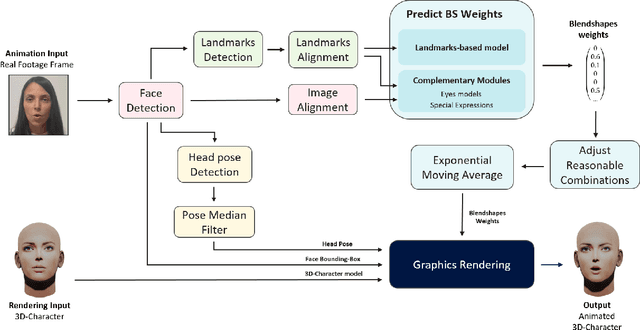

Video retargeting for digital face animation is used in virtual reality, social media, gaming, movies, and video conference, aiming to animate avatars' facial expressions based on videos of human faces. The standard method to represent facial expressions for 3D characters is by blendshapes, a vector of weights representing the avatar's neutral shape and its variations under facial expressions, e.g., smile, puff, blinking. Datasets of paired frames with blendshape vectors are rare, and labeling can be laborious, time-consuming, and subjective. In this work, we developed an approach that handles the lack of appropriate datasets. Instead, we used a synthetic dataset of only one character. To generalize various characters, we re-represented each frame to face landmarks. We developed a unique deep-learning architecture that groups landmarks for each facial organ and connects them to relevant blendshape weights. Additionally, we incorporated complementary methods for facial expressions that landmarks did not represent well and gave special attention to eye expressions. We have demonstrated the superiority of our approach to previous research in qualitative and quantitative metrics. Our approach achieved a higher MOS of 68% and a lower MSE of 44.2% when tested on videos with various users and expressions.
A survey and classification of face alignment methods based on face models
Nov 06, 2023A face model is a mathematical representation of the distinct features of a human face. Traditionally, face models were built using a set of fiducial points or landmarks, each point ideally located on a facial feature, i.e., corner of the eye, tip of the nose, etc. Face alignment is the process of fitting the landmarks in a face model to the respective ground truth positions in an input image containing a face. Despite significant research on face alignment in the past decades, no review analyses various face models used in the literature. Catering to three types of readers - beginners, practitioners and researchers in face alignment, we provide a comprehensive analysis of different face models used for face alignment. We include the interpretation and training of the face models along with the examples of fitting the face model to a new face image. We found that 3D-based face models are preferred in cases of extreme face pose, whereas deep learning-based methods often use heatmaps. Moreover, we discuss the possible future directions of face models in the field of face alignment.
Dual Defense: Adversarial, Traceable, and Invisible Robust Watermarking against Face Swapping
Oct 25, 2023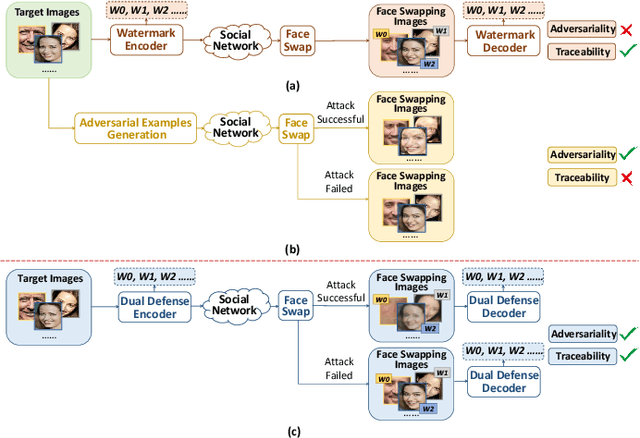
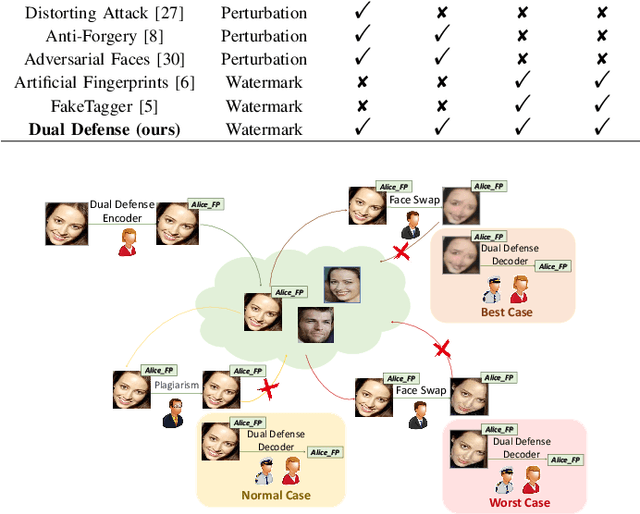
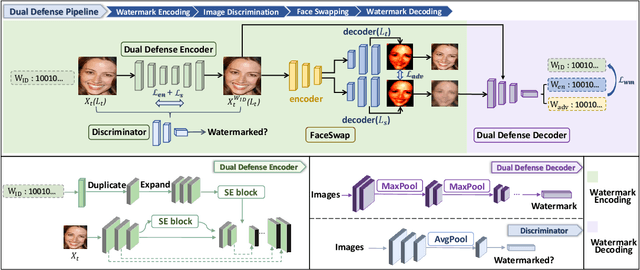
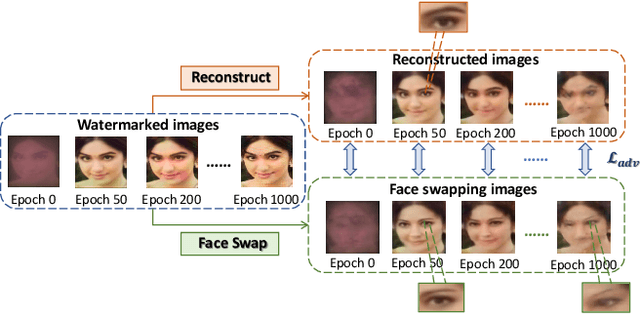
The malicious applications of deep forgery, represented by face swapping, have introduced security threats such as misinformation dissemination and identity fraud. While some research has proposed the use of robust watermarking methods to trace the copyright of facial images for post-event traceability, these methods cannot effectively prevent the generation of forgeries at the source and curb their dissemination. To address this problem, we propose a novel comprehensive active defense mechanism that combines traceability and adversariality, called Dual Defense. Dual Defense invisibly embeds a single robust watermark within the target face to actively respond to sudden cases of malicious face swapping. It disrupts the output of the face swapping model while maintaining the integrity of watermark information throughout the entire dissemination process. This allows for watermark extraction at any stage of image tracking for traceability. Specifically, we introduce a watermark embedding network based on original-domain feature impersonation attack. This network learns robust adversarial features of target facial images and embeds watermarks, seeking a well-balanced trade-off between watermark invisibility, adversariality, and traceability through perceptual adversarial encoding strategies. Extensive experiments demonstrate that Dual Defense achieves optimal overall defense success rates and exhibits promising universality in anti-face swapping tasks and dataset generalization ability. It maintains impressive adversariality and traceability in both original and robust settings, surpassing current forgery defense methods that possess only one of these capabilities, including CMUA-Watermark, Anti-Forgery, FakeTagger, or PGD methods.
P-Age: Pexels Dataset for Robust Spatio-Temporal Apparent Age Classification
Nov 04, 2023Age estimation is a challenging task that has numerous applications. In this paper, we propose a new direction for age classification that utilizes a video-based model to address challenges such as occlusions, low-resolution, and lighting conditions. To address these challenges, we propose AgeFormer which utilizes spatio-temporal information on the dynamics of the entire body dominating face-based methods for age classification. Our novel two-stream architecture uses TimeSformer and EfficientNet as backbones, to effectively capture both facial and body dynamics information for efficient and accurate age estimation in videos. Furthermore, to fill the gap in predicting age in real-world situations from videos, we construct a video dataset called Pexels Age (P-Age) for age classification. The proposed method achieves superior results compared to existing face-based age estimation methods and is evaluated in situations where the face is highly occluded, blurred, or masked. The method is also cross-tested on a variety of challenging video datasets such as Charades, Smarthome, and Thumos-14.