 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining RhythmFormer: A Systematic XAI Analysis of Periodic Sparse Attention for Remote Photoplethysmography
Jun 11, 2026Remote photoplethysmography (rPPG) transformers achieve low heart-rate error on benchmarks, yet their decisions remain opaque--a growing concern as rPPG moves toward clinical heart rate estimation. Existing rPPG XAI is dominated by qualitative heatmap inspection without quantitative faithfulness metrics or physiology-grounded validation, leaving a gap between visual plausibility and auditable evidence. We address this gap. First, we adapt four attribution methods (raw attention, rollout, flow, Beyond Intuition) to RhythmFormer's bi-level routing attention with top-$k$ selection. Second, we introduce a skin coverage metric quantifying how much attribution mass falls on skin regions. Third, we adapt the SaCo faithfulness coefficient from its original classification setting to rPPG regression by using the MAE between original and perturbed predicted rPPG waveforms as the perturbation impact. Applying these tools, we quantify a multi-hop leakage effect under sparse top-$k$ routing: attention rollout and flow almost completely restores the connections that individual refined-attention layers explicitly set to zero. Beyond Intuition mitigates this via its value-projection-weighted rollout and gradient-supported mask, attaining the highest median refined skin coverage ($0.83$ vs. $0.57$ for vanilla rollout) and faithfulness ($F=0.92$) among the evaluated methods on UBFC-rPPG. Validation across diverse datasets and model variants is needed. A case study on a low-SaCo outlier further shows all four methods recovering consistently once an artefactual region is replaced, suggesting consistent SaCo behavior across attribution families in this illustrative case. Together, these metrics move XAI for rPPG toward auditable numerical evidence about spatial alignment and perturbation faithfulness, i.e. trustworthy rPPG XAI.
Illumination-Robust Camera-Based Heart-Rate Estimation for Physiological Sensing in Robots
Jun 10, 2026Physiological awareness is important for service, social, and assistive robots that interact with humans in everyday environments. Remote photoplethysmography (rPPG) enables non-contact heart-rate (HR) estimation from an RGB camera, making it a promising sensing modality for robot-mounted vision systems. However, illumination variation remains a major barrier to robust deployment. This paper presents an end-to-end spatial-temporal transformer framework for remote HR estimation on a new dataset with varied illumination. Our estimator integrates PRNet-based 3D face alignment, clip-level illumination augmentation, the Residual Temporal Standardization Module, and controlled hybrid temporal-frequency supervision. The training objective combines a Soft-Shifted Pearson waveform loss with a spectral Kullback-Leibler divergence loss, where a tuned weight ($\mathbfβ$) controls the contribution of frequency-domain heart-rate guidance. Experiments on a static all-level mix protocol covering three illumination levels show that $\mathbfβ=5$ provides the strongest result among the tested beta settings, achieving a best-run HR mean absolute error (MAE) of 0.79 bpm and an HR correlation of 0.982. Compared with the PhysFormer baseline evaluated on our dataset, our estimator reduces HR MAE by 93.6 %, while increasing HR correlation from 0.088 to 0.982, making it usable when illumination varies.
3C-FBI: A Combinatorial method using Convolutions for Circle Fitting in Blurry Images
Jul 15, 2025This paper addresses the fundamental computer vision challenge of robust circle detection and fitting in degraded imaging conditions. We present Combinatorial Convolution-based Circle Fitting for Blurry Images (3C-FBI), an algorithm that bridges the gap between circle detection and precise parametric fitting by combining (1) efficient combinatorial edge pixel (edgel) sampling and (2) convolution-based density estimation in parameter space. We evaluate 3C-FBI across three experimental frameworks: (1) real-world medical data from Parkinson's disease assessments (144 frames from 36 videos), (2) controlled synthetic data following established circle-fitting benchmarks, and (3) systematic analysis across varying spatial resolutions and outlier contamination levels. Results show that 3C-FBI achieves state-of-the-art accuracy (Jaccard index 0.896) while maintaining real-time performance (40.3 fps), significantly outperforming classical methods like RCD (6.8 fps) on a standard CPU (i7-10875H). It maintains near-perfect accuracy (Jaccard almost 1.0) at high resolutions (480x480) and reliable performance (Jaccard higher than 0.95) down to 160x160 with up to 20% outliers. In extensive synthetic testing, 3C-FBI achieves a mean Jaccard Index of 0.989 across contamination levels, comparable to modern methods like Qi et al. (2024, 0.991), and surpassing RHT (0.964). This combination of accuracy, speed, and robustness makes 3C-FBI ideal for medical imaging, robotics, and industrial inspection under challenging conditions.
Model compression using knowledge distillation with integrated gradients
Jun 17, 2025



Model compression is critical for deploying deep learning models on resource-constrained devices. We introduce a novel method enhancing knowledge distillation with integrated gradients (IG) as a data augmentation strategy. Our approach overlays IG maps onto input images during training, providing student models with deeper insights into teacher models' decision-making processes. Extensive evaluation on CIFAR-10 demonstrates that our IG-augmented knowledge distillation achieves 92.6% testing accuracy with a 4.1x compression factor-a significant 1.1 percentage point improvement ($p<0.001$) over non-distilled models (91.5%). This compression reduces inference time from 140 ms to 13 ms. Our method precomputes IG maps before training, transforming substantial runtime costs into a one-time preprocessing step. Our comprehensive experiments include: (1) comparisons with attention transfer, revealing complementary benefits when combined with our approach; (2) Monte Carlo simulations confirming statistical robustness; (3) systematic evaluation of compression factor versus accuracy trade-offs across a wide range (2.2x-1122x); and (4) validation on an ImageNet subset aligned with CIFAR-10 classes, demonstrating generalisability beyond the initial dataset. These extensive ablation studies confirm that IG-based knowledge distillation consistently outperforms conventional approaches across varied architectures and compression ratios. Our results establish this framework as a viable compression technique for real-world deployment on edge devices while maintaining competitive accuracy.
Knowledge Distillation: Enhancing Neural Network Compression with Integrated Gradients
Mar 17, 2025Efficient deployment of deep neural networks on resource-constrained devices demands advanced compression techniques that preserve accuracy and interoperability. This paper proposes a machine learning framework that augments Knowledge Distillation (KD) with Integrated Gradients (IG), an attribution method, to optimise the compression of convolutional neural networks. We introduce a novel data augmentation strategy where IG maps, precomputed from a teacher model, are overlaid onto training images to guide a compact student model toward critical feature representations. This approach leverages the teacher's decision-making insights, enhancing the student's ability to replicate complex patterns with reduced parameters. Experiments on CIFAR-10 demonstrate the efficacy of our method: a student model, compressed 4.1-fold from the MobileNet-V2 teacher, achieves 92.5% classification accuracy, surpassing the baseline student's 91.4% and traditional KD approaches, while reducing inference latency from 140 ms to 13 ms--a tenfold speedup. We perform hyperparameter optimisation for efficient learning. Comprehensive ablation studies dissect the contributions of KD and IG, revealing synergistic effects that boost both performance and model explainability. Our method's emphasis on feature-level guidance via IG distinguishes it from conventional KD, offering a data-driven solution for mining transferable knowledge in neural architectures. This work contributes to machine learning by providing a scalable, interpretable compression technique, ideal for edge computing applications where efficiency and transparency are paramount.
Unsupervised Skin Feature Tracking with Deep Neural Networks
May 08, 2024Facial feature tracking is essential in imaging ballistocardiography for accurate heart rate estimation and enables motor degradation quantification in Parkinson's disease through skin feature tracking. While deep convolutional neural networks have shown remarkable accuracy in tracking tasks, they typically require extensive labeled data for supervised training. Our proposed pipeline employs a convolutional stacked autoencoder to match image crops with a reference crop containing the target feature, learning deep feature encodings specific to the object category in an unsupervised manner, thus reducing data requirements. To overcome edge effects making the performance dependent on crop size, we introduced a Gaussian weight on the residual errors of the pixels when calculating the loss function. Training the autoencoder on facial images and validating its performance on manually labeled face and hand videos, our Deep Feature Encodings (DFE) method demonstrated superior tracking accuracy with a mean error ranging from 0.6 to 3.3 pixels, outperforming traditional methods like SIFT, SURF, Lucas Kanade, and the latest transformers like PIPs++ and CoTracker. Overall, our unsupervised learning approach excels in tracking various skin features under significant motion conditions, providing superior feature descriptors for tracking, matching, and image registration compared to both traditional and state-of-the-art supervised learning methods.
A survey and classification of face alignment methods based on face models
Nov 06, 2023A face model is a mathematical representation of the distinct features of a human face. Traditionally, face models were built using a set of fiducial points or landmarks, each point ideally located on a facial feature, i.e., corner of the eye, tip of the nose, etc. Face alignment is the process of fitting the landmarks in a face model to the respective ground truth positions in an input image containing a face. Despite significant research on face alignment in the past decades, no review analyses various face models used in the literature. Catering to three types of readers - beginners, practitioners and researchers in face alignment, we provide a comprehensive analysis of different face models used for face alignment. We include the interpretation and training of the face models along with the examples of fitting the face model to a new face image. We found that 3D-based face models are preferred in cases of extreme face pose, whereas deep learning-based methods often use heatmaps. Moreover, we discuss the possible future directions of face models in the field of face alignment.
Skin feature point tracking using deep feature encodings
Dec 28, 2021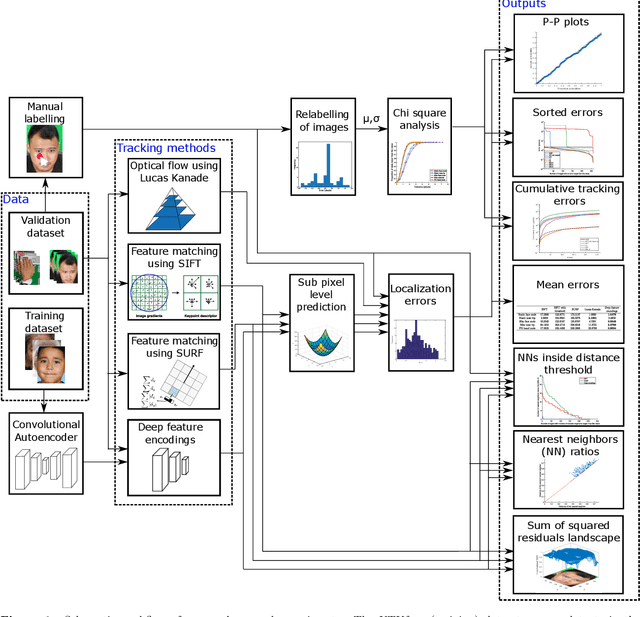
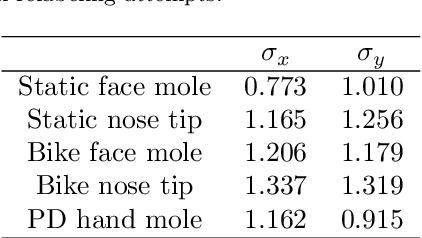
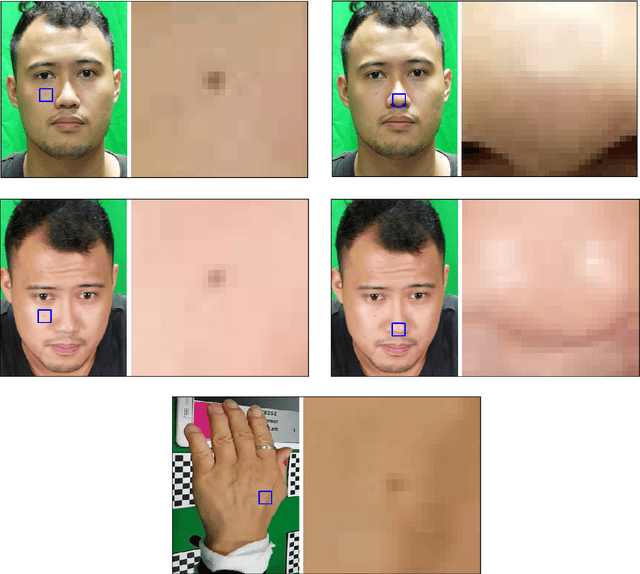
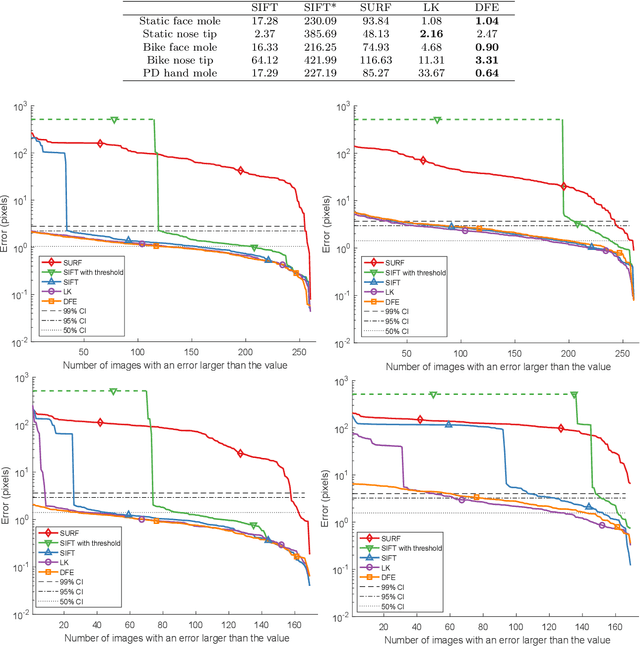
Facial feature tracking is a key component of imaging ballistocardiography (BCG) where accurate quantification of the displacement of facial keypoints is needed for good heart rate estimation. Skin feature tracking enables video-based quantification of motor degradation in Parkinson's disease. Traditional computer vision algorithms include Scale Invariant Feature Transform (SIFT), Speeded-Up Robust Features (SURF), and Lucas-Kanade method (LK). These have long represented the state-of-the-art in efficiency and accuracy but fail when common deformations, like affine local transformations or illumination changes, are present. Over the past five years, deep convolutional neural networks have outperformed traditional methods for most computer vision tasks. We propose a pipeline for feature tracking, that applies a convolutional stacked autoencoder to identify the most similar crop in an image to a reference crop containing the feature of interest. The autoencoder learns to represent image crops into deep feature encodings specific to the object category it is trained on. We train the autoencoder on facial images and validate its ability to track skin features in general using manually labeled face and hand videos. The tracking errors of distinctive skin features (moles) are so small that we cannot exclude that they stem from the manual labelling based on a $\chi^2$-test. With a mean error of 0.6-4.2 pixels, our method outperformed the other methods in all but one scenario. More importantly, our method was the only one to not diverge. We conclude that our method creates better feature descriptors for feature tracking, feature matching, and image registration than the traditional algorithms.