 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Deep Portrait Lighting Enhancement with 3D Guidance
Aug 04, 2021
Despite recent breakthroughs in deep learning methods for image lighting enhancement, they are inferior when applied to portraits because 3D facial information is ignored in their models. To address this, we present a novel deep learning framework for portrait lighting enhancement based on 3D facial guidance. Our framework consists of two stages. In the first stage, corrected lighting parameters are predicted by a network from the input bad lighting image, with the assistance of a 3D morphable model and a differentiable renderer. Given the predicted lighting parameter, the differentiable renderer renders a face image with corrected shading and texture, which serves as the 3D guidance for learning image lighting enhancement in the second stage. To better exploit the long-range correlations between the input and the guidance, in the second stage, we design an image-to-image translation network with a novel transformer architecture, which automatically produces a lighting-enhanced result. Experimental results on the FFHQ dataset and in-the-wild images show that the proposed method outperforms state-of-the-art methods in terms of both quantitative metrics and visual quality. We will publish our dataset along with more results on https://cassiepython.github.io/egsr/index.html.
* {\dag} for equal conribution. Accepted to CGF. Project page: https://cassiepython.github.io/egsr/index.html
Controlled AutoEncoders to Generate Faces from Voices
Jul 16, 2021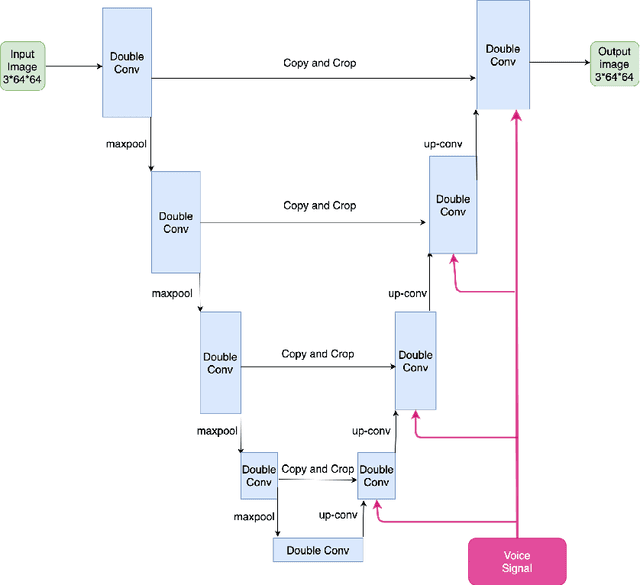
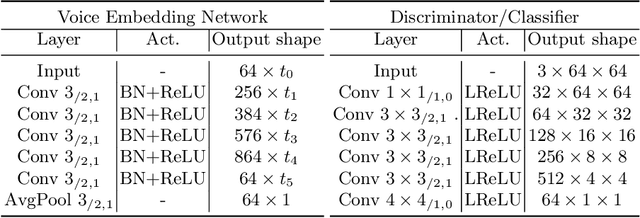
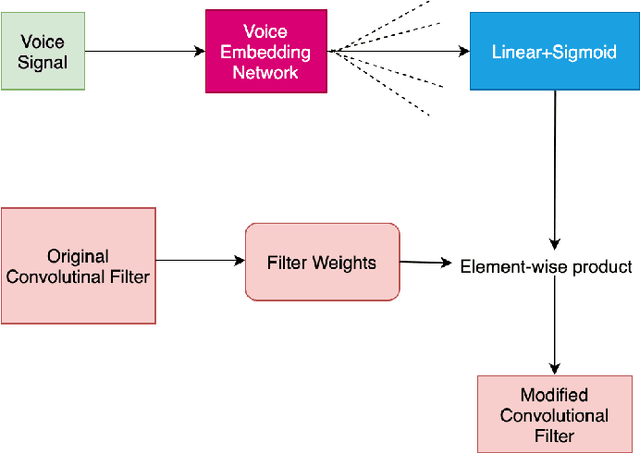

Multiple studies in the past have shown that there is a strong correlation between human vocal characteristics and facial features. However, existing approaches generate faces simply from voice, without exploring the set of features that contribute to these observed correlations. A computational methodology to explore this can be devised by rephrasing the question to: "how much would a target face have to change in order to be perceived as the originator of a source voice?" With this in perspective, we propose a framework to morph a target face in response to a given voice in a way that facial features are implicitly guided by learned voice-face correlation in this paper. Our framework includes a guided autoencoder that converts one face to another, controlled by a unique model-conditioning component called a gating controller which modifies the reconstructed face based on input voice recordings. We evaluate the framework on VoxCelab and VGGFace datasets through human subjects and face retrieval. Various experiments demonstrate the effectiveness of our proposed model.
Multi Modal Adaptive Normalization for Audio to Video Generation
Dec 14, 2020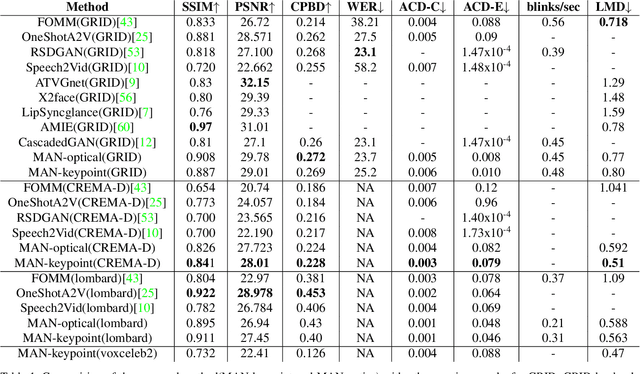

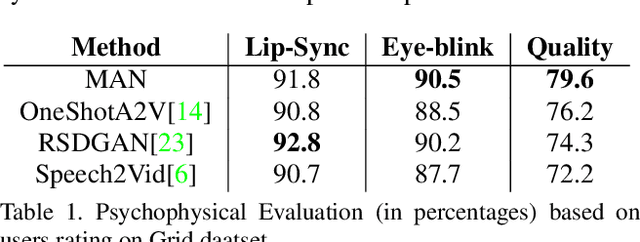
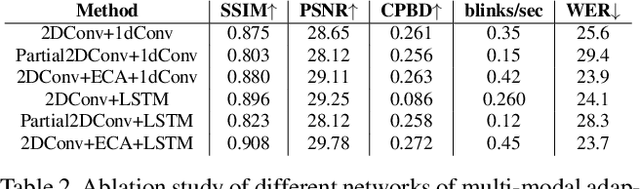
Speech-driven facial video generation has been a complex problem due to its multi-modal aspects namely audio and video domain. The audio comprises lots of underlying features such as expression, pitch, loudness, prosody(speaking style) and facial video has lots of variability in terms of head movement, eye blinks, lip synchronization and movements of various facial action units along with temporal smoothness. Synthesizing highly expressive facial videos from the audio input and static image is still a challenging task for generative adversarial networks. In this paper, we propose a multi-modal adaptive normalization(MAN) based architecture to synthesize a talking person video of arbitrary length using as input: an audio signal and a single image of a person. The architecture uses the multi-modal adaptive normalization, keypoint heatmap predictor, optical flow predictor and class activation map[58] based layers to learn movements of expressive facial components and hence generates a highly expressive talking-head video of the given person. The multi-modal adaptive normalization uses the various features of audio and video such as Mel spectrogram, pitch, energy from audio signals and predicted keypoint heatmap/optical flow and a single image to learn the respective affine parameters to generate highly expressive video. Experimental evaluation demonstrates superior performance of the proposed method as compared to Realistic Speech-Driven Facial Animation with GANs(RSDGAN) [53], Speech2Vid [10], and other approaches, on multiple quantitative metrics including: SSIM (structural similarity index), PSNR (peak signal to noise ratio), CPBD (image sharpness), WER(word error rate), blinks/sec and LMD(landmark distance). Further, qualitative evaluation and Online Turing tests demonstrate the efficacy of our approach.
Personalized Automatic Estimation of Self-reported Pain Intensity from Facial Expressions
Jun 24, 2017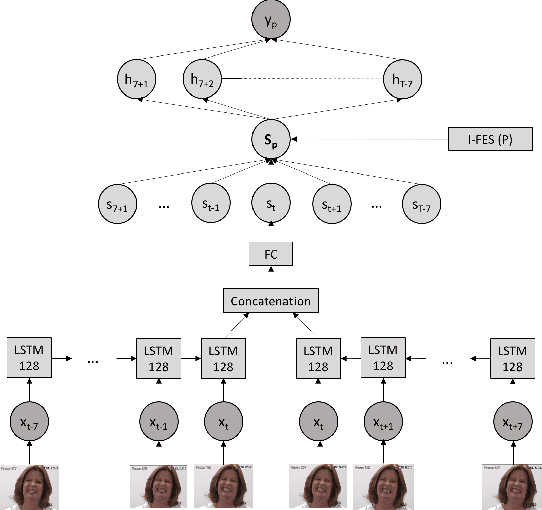

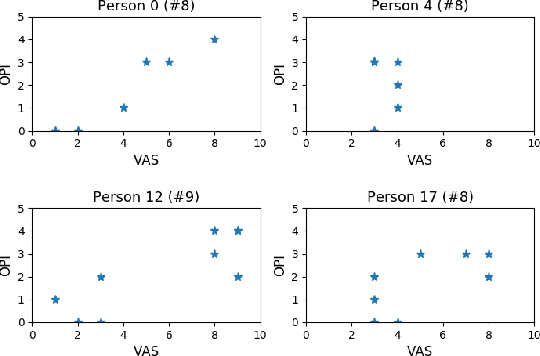
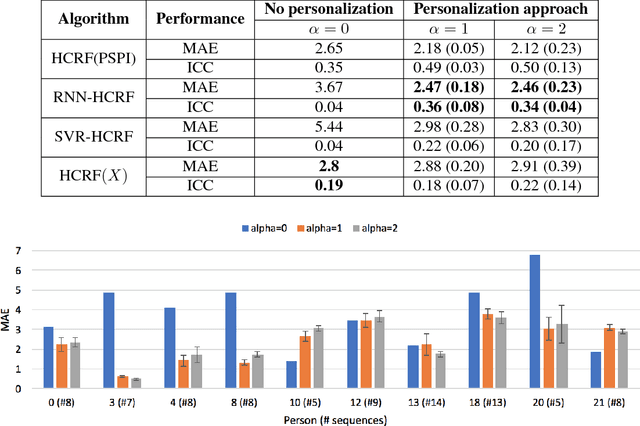
Pain is a personal, subjective experience that is commonly evaluated through visual analog scales (VAS). While this is often convenient and useful, automatic pain detection systems can reduce pain score acquisition efforts in large-scale studies by estimating it directly from the participants' facial expressions. In this paper, we propose a novel two-stage learning approach for VAS estimation: first, our algorithm employs Recurrent Neural Networks (RNNs) to automatically estimate Prkachin and Solomon Pain Intensity (PSPI) levels from face images. The estimated scores are then fed into the personalized Hidden Conditional Random Fields (HCRFs), used to estimate the VAS, provided by each person. Personalization of the model is performed using a newly introduced facial expressiveness score, unique for each person. To the best of our knowledge, this is the first approach to automatically estimate VAS from face images. We show the benefits of the proposed personalized over traditional non-personalized approach on a benchmark dataset for pain analysis from face images.
A Jointly Learned Deep Architecture for Facial Attribute Analysis and Face Detection in the Wild
Jul 27, 2017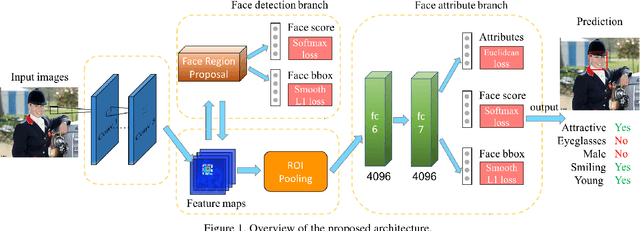
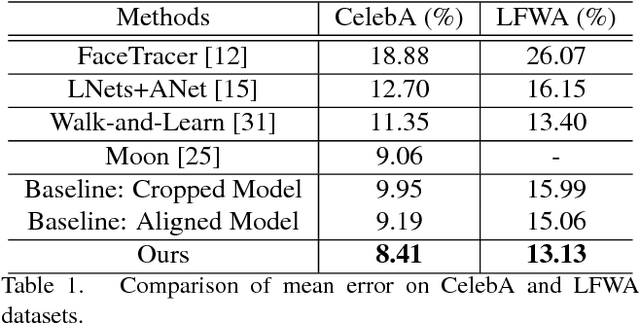
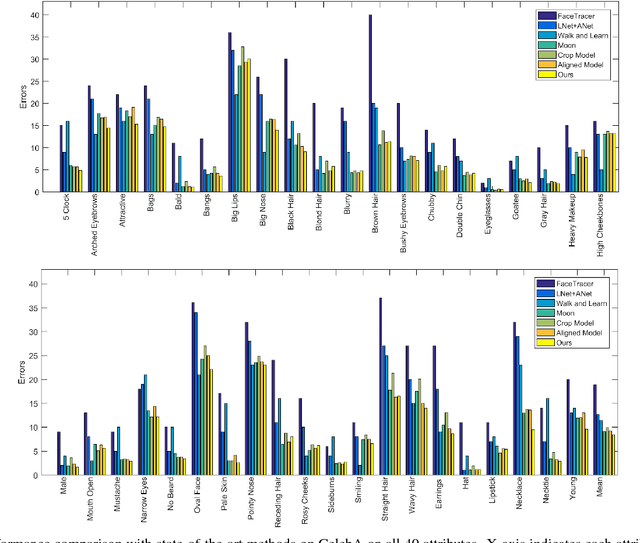
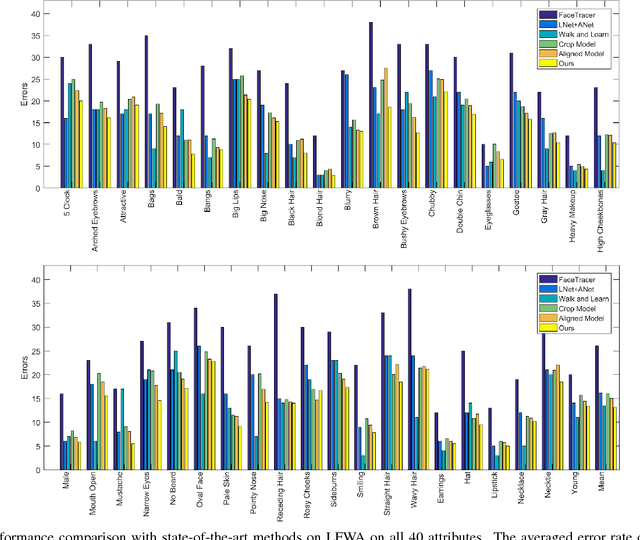
Facial attribute analysis in the real world scenario is very challenging mainly because of complex face variations. Existing works of analyzing face attributes are mostly based on the cropped and aligned face images. However, this result in the capability of attribute prediction heavily relies on the preprocessing of face detector. To address this problem, we present a novel jointly learned deep architecture for both facial attribute analysis and face detection. Our framework can process the natural images in the wild and our experiments on CelebA and LFWA datasets clearly show that the state-of-the-art performance is obtained.
Semantic-Aware Implicit Neural Audio-Driven Video Portrait Generation
Jan 19, 2022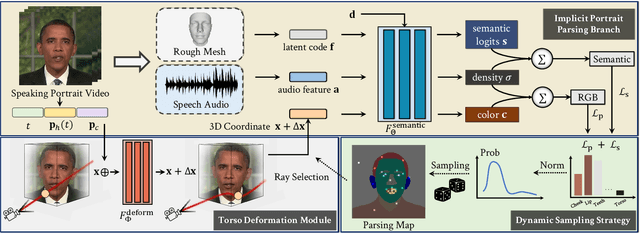
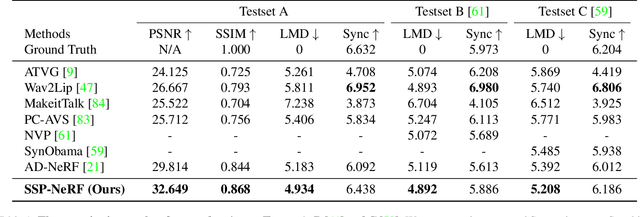
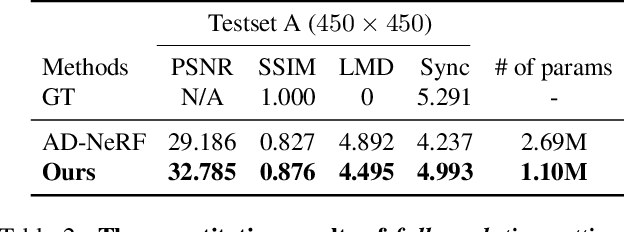

Animating high-fidelity video portrait with speech audio is crucial for virtual reality and digital entertainment. While most previous studies rely on accurate explicit structural information, recent works explore the implicit scene representation of Neural Radiance Fields (NeRF) for realistic generation. In order to capture the inconsistent motions as well as the semantic difference between human head and torso, some work models them via two individual sets of NeRF, leading to unnatural results. In this work, we propose Semantic-aware Speaking Portrait NeRF (SSP-NeRF), which creates delicate audio-driven portraits using one unified set of NeRF. The proposed model can handle the detailed local facial semantics and the global head-torso relationship through two semantic-aware modules. Specifically, we first propose a Semantic-Aware Dynamic Ray Sampling module with an additional parsing branch that facilitates audio-driven volume rendering. Moreover, to enable portrait rendering in one unified neural radiance field, a Torso Deformation module is designed to stabilize the large-scale non-rigid torso motions. Extensive evaluations demonstrate that our proposed approach renders more realistic video portraits compared to previous methods. Project page: https://alvinliu0.github.io/projects/SSP-NeRF
Multi-Order Networks for Action Unit Detection
Feb 01, 2022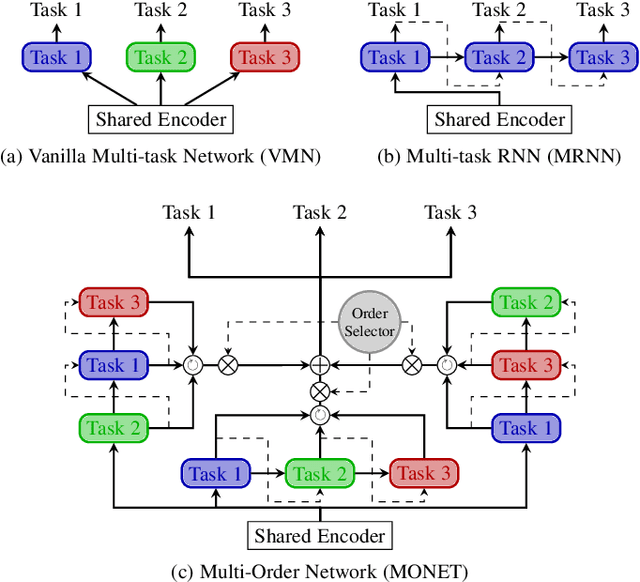
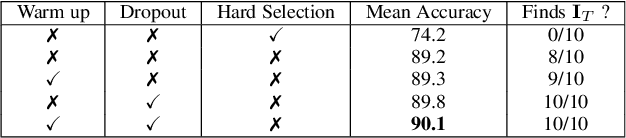
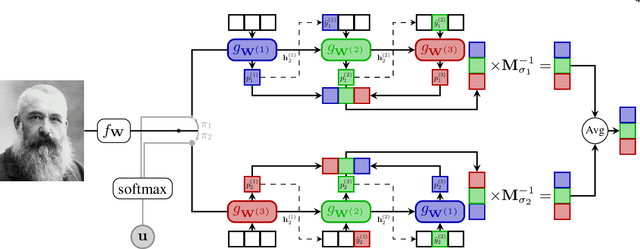
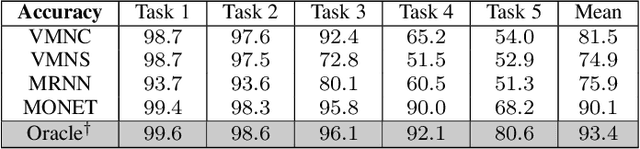
Deep multi-task methods, where several tasks are learned within a single network, have recently attracted increasing attention. Burning point of this attention is their capacity to capture inter-task relationships. Current approaches either only rely on weight sharing, or add explicit dependency modelling by decomposing the task joint distribution using Bayes chain rule. If the latter strategy yields comprehensive inter-task relationships modelling, it requires imposing an arbitrary order into an unordered task set. Most importantly, this sequence ordering choice has been identified as a critical source of performance variations. In this paper, we present Multi-Order Network (MONET), a multi-task learning method with joint task order optimization. MONET uses a differentiable order selection based on soft order modelling inside Birkhoff's polytope to jointly learn task-wise recurrent modules with their optimal chaining order. Furthermore, we introduce warm up and order dropout to enhance order selection by encouraging order exploration. Experimentally, we first validate MONET capacity to retrieve the optimal order in a toy environment. Second, we use an attribute detection scenario to show that MONET outperforms existing multi-task baselines on a wide range of dependency settings. Finally, we demonstrate that MONET significantly extends state-of-the-art performance in Facial Action Unit detection.
Controlling Memorability of Face Images
Feb 24, 2022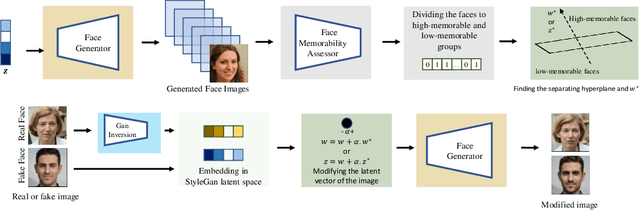


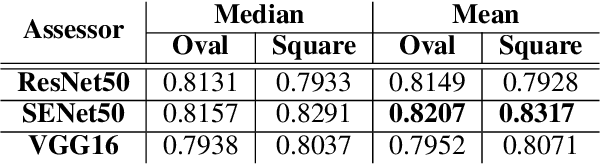
Everyday, we are bombarded with many photographs of faces, whether on social media, television, or smartphones. From an evolutionary perspective, faces are intended to be remembered, mainly due to survival and personal relevance. However, all these faces do not have the equal opportunity to stick in our minds. It has been shown that memorability is an intrinsic feature of an image but yet, it is largely unknown what attributes make an image more memorable. In this work, we aimed to address this question by proposing a fast approach to modify and control the memorability of face images. In our proposed method, we first found a hyperplane in the latent space of StyleGAN to separate high and low memorable images. We then modified the image memorability (while maintaining the identity and other facial features such as age, emotion, etc.) by moving in the positive or negative direction of this hyperplane normal vector. We further analyzed how different layers of the StyleGAN augmented latent space contribute to face memorability. These analyses showed how each individual face attribute makes an image more or less memorable. Most importantly, we evaluated our proposed method for both real and synthesized face images. The proposed method successfully modifies and controls the memorability of real human faces as well as unreal synthesized faces. Our proposed method can be employed in photograph editing applications for social media, learning aids, or advertisement purposes.
A Deep Learning Framework to Reconstruct Face under Mask
Mar 23, 2022
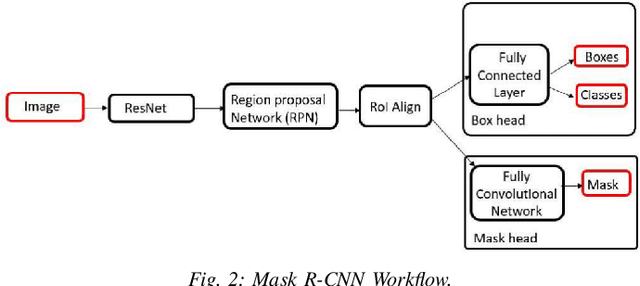
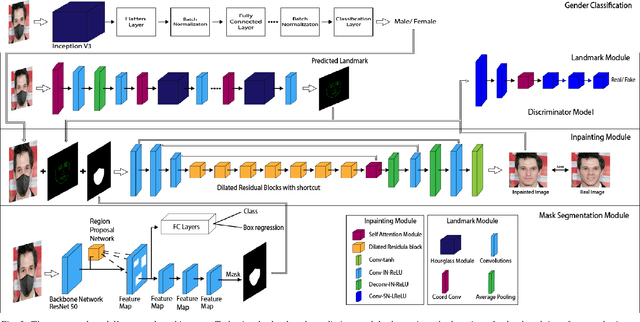
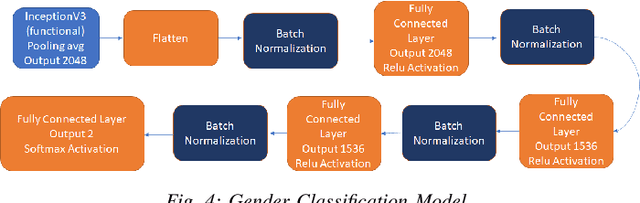
While deep learning-based image reconstruction methods have shown significant success in removing objects from pictures, they have yet to achieve acceptable results for attributing consistency to gender, ethnicity, expression, and other characteristics like the topological structure of the face. The purpose of this work is to extract the mask region from a masked image and rebuild the area that has been detected. This problem is complex because (i) it is difficult to determine the gender of an image hidden behind a mask, which causes the network to become confused and reconstruct the male face as a female or vice versa; (ii) we may receive images from multiple angles, making it extremely difficult to maintain the actual shape, topological structure of the face and a natural image; and (iii) there are problems with various mask forms because, in some cases, the area of the mask cannot be anticipated precisely; certain parts of the mask remain on the face after completion. To solve this complex task, we split the problem into three phases: landmark detection, object detection for the targeted mask area, and inpainting the addressed mask region. To begin, to solve the first problem, we have used gender classification, which detects the actual gender behind a mask, then we detect the landmark of the masked facial image. Second, we identified the non-face item, i.e., the mask, and used the Mask R-CNN network to create the binary mask of the observed mask area. Thirdly, we developed an inpainting network that uses anticipated landmarks to create realistic images. To segment the mask, this article uses a mask R-CNN and offers a binary segmentation map for identifying the mask area. Additionally, we generated the image utilizing landmarks as structural guidance through a GAN-based network. The studies presented in this paper use the FFHQ and CelebA datasets.
Controllable Image-to-Video Translation: A Case Study on Facial Expression Generation
Aug 09, 2018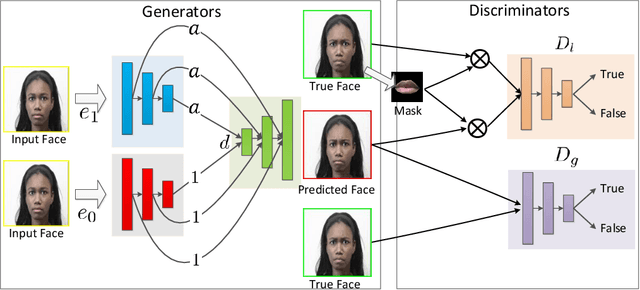


The recent advances in deep learning have made it possible to generate photo-realistic images by using neural networks and even to extrapolate video frames from an input video clip. In this paper, for the sake of both furthering this exploration and our own interest in a realistic application, we study image-to-video translation and particularly focus on the videos of facial expressions. This problem challenges the deep neural networks by another temporal dimension comparing to the image-to-image translation. Moreover, its single input image fails most existing video generation methods that rely on recurrent models. We propose a user-controllable approach so as to generate video clips of various lengths from a single face image. The lengths and types of the expressions are controlled by users. To this end, we design a novel neural network architecture that can incorporate the user input into its skip connections and propose several improvements to the adversarial training method for the neural network. Experiments and user studies verify the effectiveness of our approach. Especially, we would like to highlight that even for the face images in the wild (downloaded from the Web and the authors' own photos), our model can generate high-quality facial expression videos of which about 50\% are labeled as real by Amazon Mechanical Turk workers.