 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLAgeBench: Benchmarking Large Vision-Language Models for Zero-Shot Human Age Estimation
Mar 27, 2026Human age estimation from facial images represents a challenging computer vision task with significant applications in biometrics, healthcare, and human-computer interaction. While traditional deep learning approaches require extensive labeled datasets and domain-specific training, recent advances in large vision-language models (LVLMs) offer the potential for zero-shot age estimation. This study presents a comprehensive zero-shot evaluation of state-of-the-art Large Vision-Language Models (LVLMs) for facial age estimation, a task traditionally dominated by domain-specific convolutional networks and supervised learning. We assess the performance of GPT-4o, Claude 3.5 Sonnet, and LLaMA 3.2 Vision on two benchmark datasets, UTKFace and FG-NET, without any fine-tuning or task-specific adaptation. Using eight evaluation metrics, including MAE, MSE, RMSE, MAPE, MBE, $R^2$, CCC, and $\pm$5-year accuracy, we demonstrate that general-purpose LVLMs can deliver competitive performance in zero-shot settings. Our findings highlight the emergent capabilities of LVLMs for accurate biometric age estimation and position these models as promising tools for real-world applications. Additionally, we highlight performance disparities linked to image quality and demographic subgroups, underscoring the need for fairness-aware multimodal inference. This work introduces a reproducible benchmark and positions LVLMs as promising tools for real-world applications in forensic science, healthcare monitoring, and human-computer interaction. The benchmark focuses on strict zero-shot inference without fine-tuning and highlights remaining challenges related to prompt sensitivity, interpretability, computational cost, and demographic fairness.
ConvoWaste: An Automatic Waste Segregation Machine Using Deep Learning
Feb 06, 2023Nowadays, proper urban waste management is one of the biggest concerns for maintaining a green and clean environment. An automatic waste segregation system can be a viable solution to improve the sustainability of the country and boost the circular economy. This paper proposes a machine to segregate waste into different parts with the help of a smart object detection algorithm using ConvoWaste in the field of deep convolutional neural networks (DCNN) and image processing techniques. In this paper, deep learning and image processing techniques are applied to precisely classify the waste, and the detected waste is placed inside the corresponding bins with the help of a servo motor-based system. This machine has the provision to notify the responsible authority regarding the waste level of the bins and the time to trash out the bins filled with garbage by using the ultrasonic sensors placed in each bin and the dual-band GSM-based communication technology. The entire system is controlled remotely through an Android app in order to dump the separated waste in the desired place thanks to its automation properties. The use of this system can aid in the process of recycling resources that were initially destined to become waste, utilizing natural resources, and turning these resources back into usable products. Thus, the system helps fulfill the criteria of a circular economy through resource optimization and extraction. Finally, the system is designed to provide services at a low cost while maintaining a high level of accuracy in terms of technological advancement in the field of artificial intelligence (AI). We have gotten 98% accuracy for our ConvoWaste deep learning model.
A Deep Learning Framework to Reconstruct Face under Mask
Mar 23, 2022
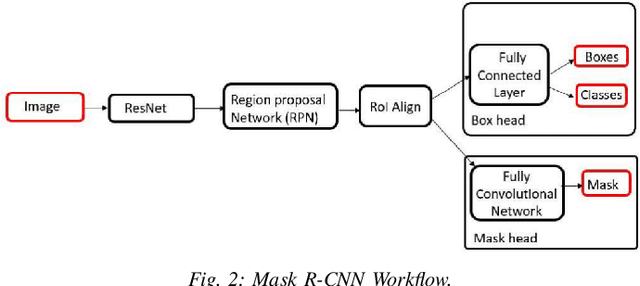
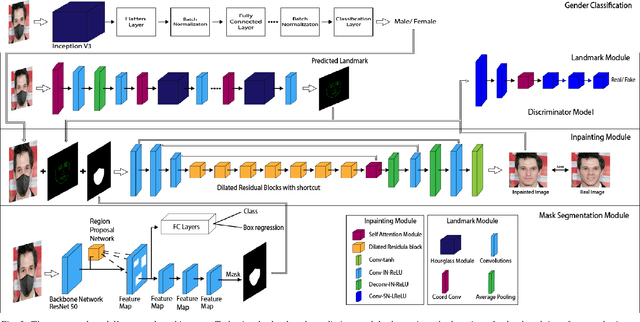
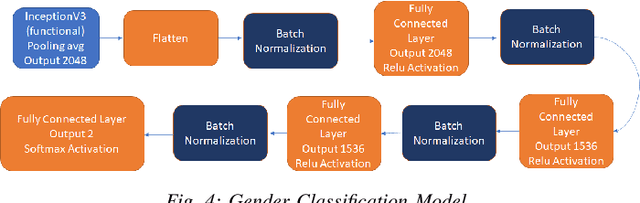
While deep learning-based image reconstruction methods have shown significant success in removing objects from pictures, they have yet to achieve acceptable results for attributing consistency to gender, ethnicity, expression, and other characteristics like the topological structure of the face. The purpose of this work is to extract the mask region from a masked image and rebuild the area that has been detected. This problem is complex because (i) it is difficult to determine the gender of an image hidden behind a mask, which causes the network to become confused and reconstruct the male face as a female or vice versa; (ii) we may receive images from multiple angles, making it extremely difficult to maintain the actual shape, topological structure of the face and a natural image; and (iii) there are problems with various mask forms because, in some cases, the area of the mask cannot be anticipated precisely; certain parts of the mask remain on the face after completion. To solve this complex task, we split the problem into three phases: landmark detection, object detection for the targeted mask area, and inpainting the addressed mask region. To begin, to solve the first problem, we have used gender classification, which detects the actual gender behind a mask, then we detect the landmark of the masked facial image. Second, we identified the non-face item, i.e., the mask, and used the Mask R-CNN network to create the binary mask of the observed mask area. Thirdly, we developed an inpainting network that uses anticipated landmarks to create realistic images. To segment the mask, this article uses a mask R-CNN and offers a binary segmentation map for identifying the mask area. Additionally, we generated the image utilizing landmarks as structural guidance through a GAN-based network. The studies presented in this paper use the FFHQ and CelebA datasets.