 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Multi-Modal Multi-Correlation Learning for Audio-Visual Speech Separation
Jul 04, 2022
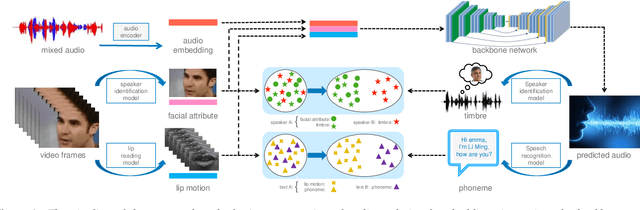
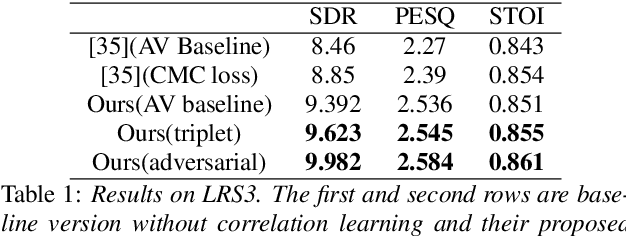
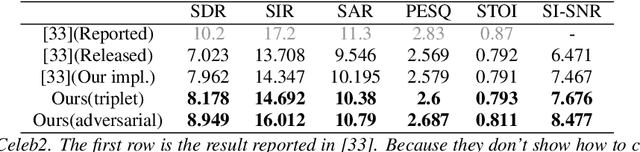
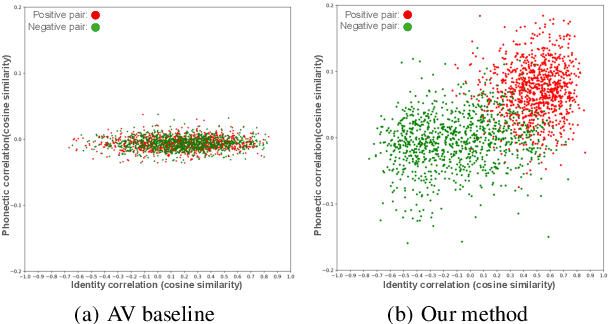
In this paper we propose a multi-modal multi-correlation learning framework targeting at the task of audio-visual speech separation. Although previous efforts have been extensively put on combining audio and visual modalities, most of them solely adopt a straightforward concatenation of audio and visual features. To exploit the real useful information behind these two modalities, we define two key correlations which are: (1) identity correlation (between timbre and facial attributes); (2) phonetic correlation (between phoneme and lip motion). These two correlations together comprise the complete information, which shows a certain superiority in separating target speaker's voice especially in some hard cases, such as the same gender or similar content. For implementation, contrastive learning or adversarial training approach is applied to maximize these two correlations. Both of them work well, while adversarial training shows its advantage by avoiding some limitations of contrastive learning. Compared with previous research, our solution demonstrates clear improvement on experimental metrics without additional complexity. Further analysis reveals the validity of the proposed architecture and its good potential for future extension.
Deepfake Video Detection with Spatiotemporal Dropout Transformer
Jul 14, 2022



While the abuse of deepfake technology has caused serious concerns recently, how to detect deepfake videos is still a challenge due to the high photo-realistic synthesis of each frame. Existing image-level approaches often focus on single frame and ignore the spatiotemporal cues hidden in deepfake videos, resulting in poor generalization and robustness. The key of a video-level detector is to fully exploit the spatiotemporal inconsistency distributed in local facial regions across different frames in deepfake videos. Inspired by that, this paper proposes a simple yet effective patch-level approach to facilitate deepfake video detection via spatiotemporal dropout transformer. The approach reorganizes each input video into bag of patches that is then fed into a vision transformer to achieve robust representation. Specifically, a spatiotemporal dropout operation is proposed to fully explore patch-level spatiotemporal cues and serve as effective data augmentation to further enhance model's robustness and generalization ability. The operation is flexible and can be easily plugged into existing vision transformers. Extensive experiments demonstrate the effectiveness of our approach against 25 state-of-the-arts with impressive robustness, generalizability, and representation ability.
Identity-Enhanced Network for Facial Expression Recognition
Dec 11, 2018
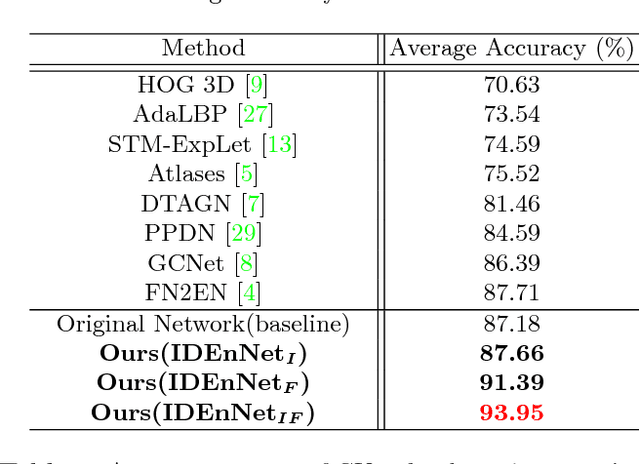
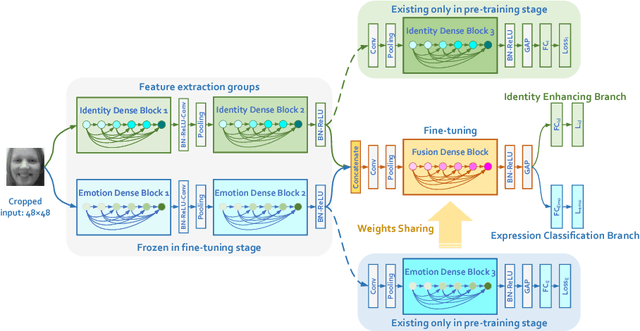
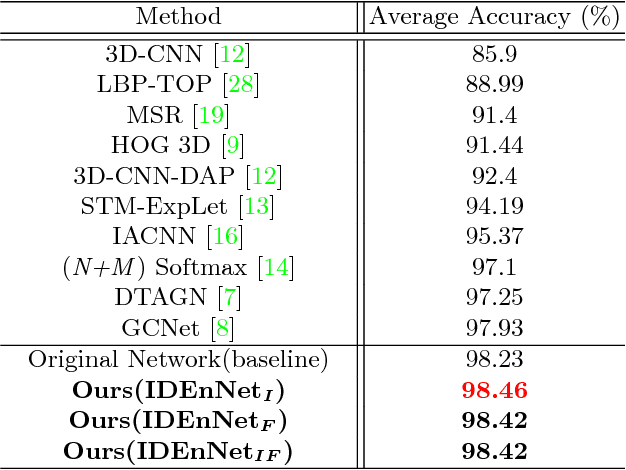
Facial expression recognition is a challenging task, arguably because of large intra-class variations and high inter-class similarities. The core drawback of the existing approaches is the lack of ability to discriminate the changes in appearance caused by emotions and identities. In this paper, we present a novel identity-enhanced network (IDEnNet) to eliminate the negative impact of identity factor and focus on recognizing facial expressions. Spatial fusion combined with self-constrained multi-task learning are adopted to jointly learn the expression representations and identity-related information. We evaluate our approach on three popular datasets, namely Oulu-CASIA, CK+ and MMI. IDEnNet improves the baseline consistently, and achieves the best or comparable state-of-the-art on all three datasets.
Automated Pain Detection from Facial Expressions using FACS: A Review
Nov 13, 2018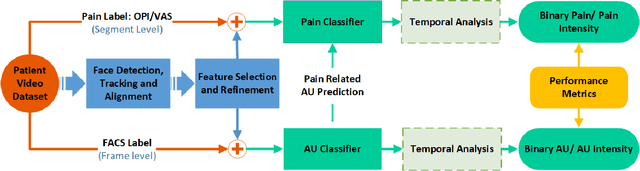
Facial pain expression is an important modality for assessing pain, especially when the patient's verbal ability to communicate is impaired. The facial muscle-based action units (AUs), which are defined by the Facial Action Coding System (FACS), have been widely studied and are highly reliable as a method for detecting facial expressions (FE) including valid detection of pain. Unfortunately, FACS coding by humans is a very time-consuming task that makes its clinical use prohibitive. Significant progress on automated facial expression recognition (AFER) has led to its numerous successful applications in FACS-based affective computing problems. However, only a handful of studies have been reported on automated pain detection (APD), and its application in clinical settings is still far from a reality. In this paper, we review the progress in research that has contributed to automated pain detection, with focus on 1) the framework-level similarity between spontaneous AFER and APD problems; 2) the evolution of system design including the recent development of deep learning methods; 3) the strategies and considerations in developing a FACS-based pain detection framework from existing research; and 4) introduction of the most relevant databases that are available for AFER and APD studies. We attempt to present key considerations in extending a general AFER framework to an APD framework in clinical settings. In addition, the performance metrics are also highlighted in evaluating an AFER or an APD system.
Realistic Speech-Driven Facial Animation with GANs
Jun 14, 2019
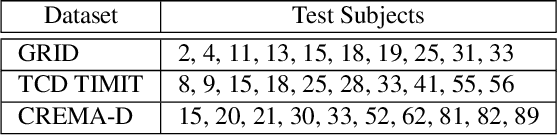
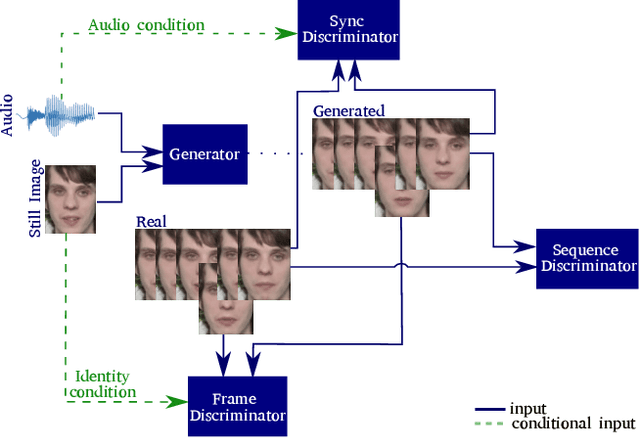
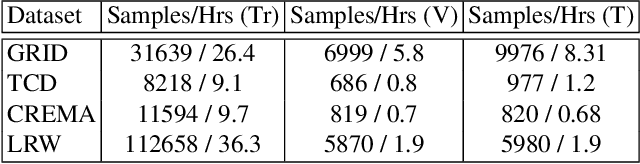
Speech-driven facial animation is the process that automatically synthesizes talking characters based on speech signals. The majority of work in this domain creates a mapping from audio features to visual features. This approach often requires post-processing using computer graphics techniques to produce realistic albeit subject dependent results. We present an end-to-end system that generates videos of a talking head, using only a still image of a person and an audio clip containing speech, without relying on handcrafted intermediate features. Our method generates videos which have (a) lip movements that are in sync with the audio and (b) natural facial expressions such as blinks and eyebrow movements. Our temporal GAN uses 3 discriminators focused on achieving detailed frames, audio-visual synchronization, and realistic expressions. We quantify the contribution of each component in our model using an ablation study and we provide insights into the latent representation of the model. The generated videos are evaluated based on sharpness, reconstruction quality, lip-reading accuracy, synchronization as well as their ability to generate natural blinks.
Study of detecting behavioral signatures within DeepFake videos
Aug 06, 2022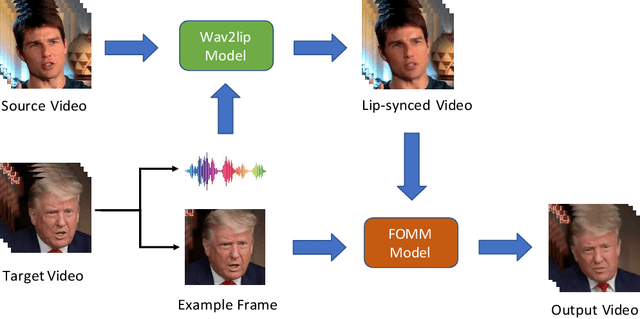
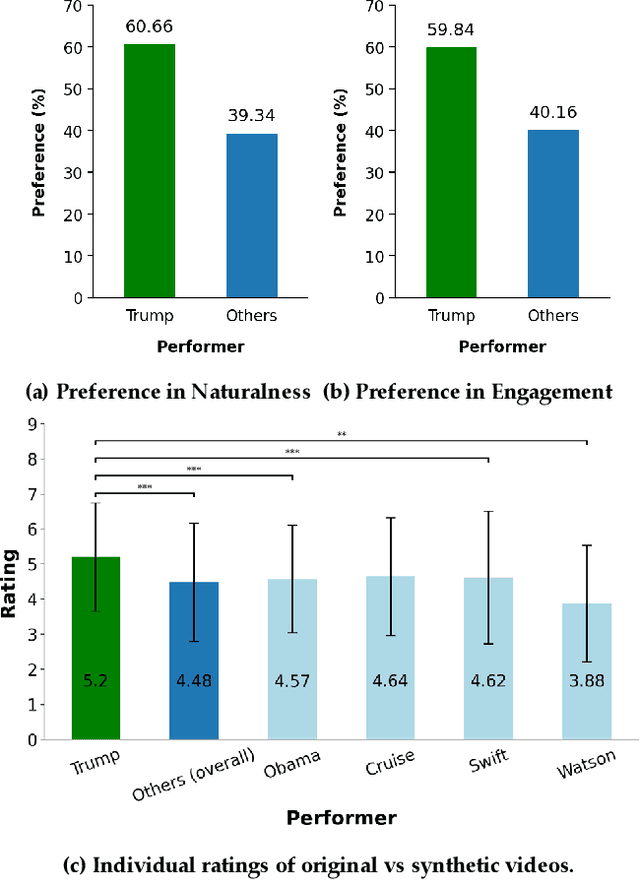
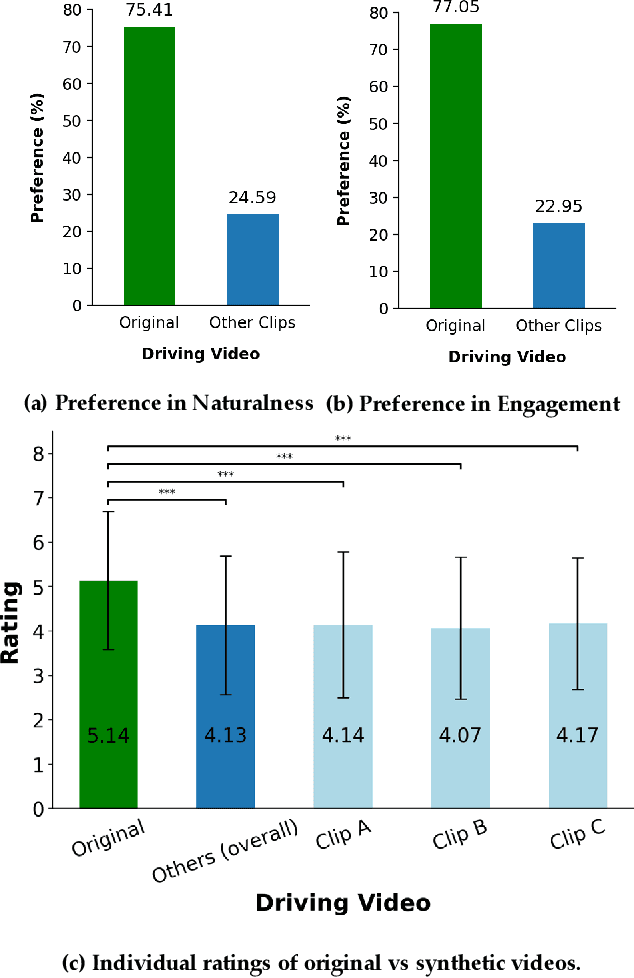

There is strong interest in the generation of synthetic video imagery of people talking for various purposes, including entertainment, communication, training, and advertisement. With the development of deep fake generation models, synthetic video imagery will soon be visually indistinguishable to the naked eye from a naturally capture video. In addition, many methods are continuing to improve to avoid more careful, forensic visual analysis. Some deep fake videos are produced through the use of facial puppetry, which directly controls the head and face of the synthetic image through the movements of the actor, allow the actor to 'puppet' the image of another. In this paper, we address the question of whether one person's movements can be distinguished from the original speaker by controlling the visual appearance of the speaker but transferring the behavior signals from another source. We conduct a study by comparing synthetic imagery that: 1) originates from a different person speaking a different utterance, 2) originates from the same person speaking a different utterance, and 3) originates from a different person speaking the same utterance. Our study shows that synthetic videos in all three cases are seen as less real and less engaging than the original source video. Our results indicate that there could be a behavioral signature that is detectable from a person's movements that is separate from their visual appearance, and that this behavioral signature could be used to distinguish a deep fake from a properly captured video.
Region Based Extensive Response Index Pattern for Facial Expression Recognition
Nov 26, 2018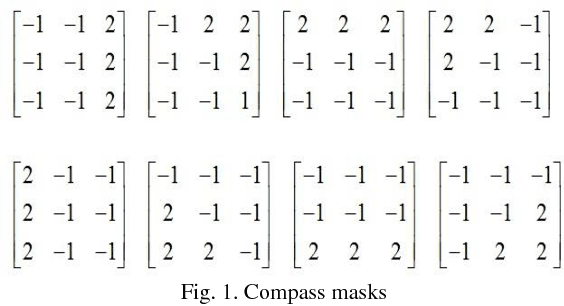

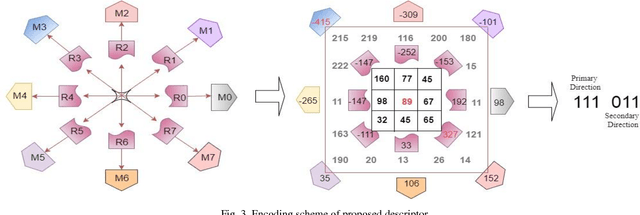
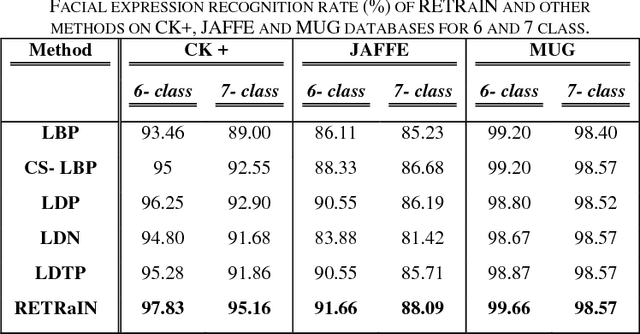
This paper presents a novel descriptor named Region based Extensive Response Index Pattern (RETRaIN) for facial expression recognition. The RETRaIN encodes the relation among the reference and neighboring pixels of facial active regions. These relations are computed by using directional compass mask on an input image and extract the high edge responses in foremost directions. Further extreme edge index positions are selected and encoded into six-bit compact code to reduce feature dimensionality and distinguish between the uniform and non-uniform patterns in the facial features. The performance of the proposed descriptor is tested and evaluated on three benchmark datasets Extended Cohn Kanade, JAFFE, and MUG. The RETRaIN achieves superior recognition accuracy in comparison to state-of-the-art techniques.
Fast and Effective Adaptation of Facial Action Unit Detection Deep Model
Sep 26, 2019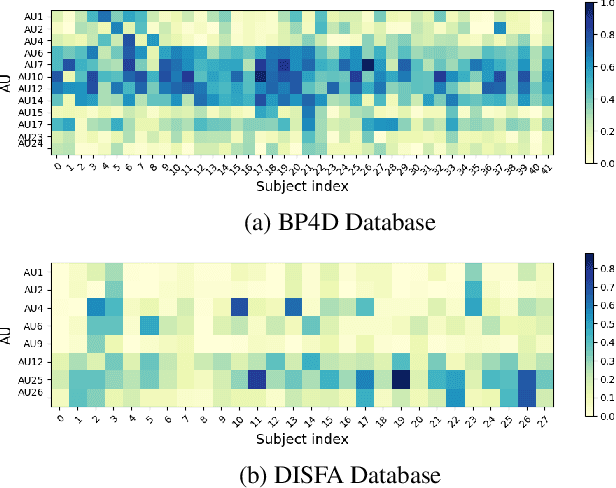
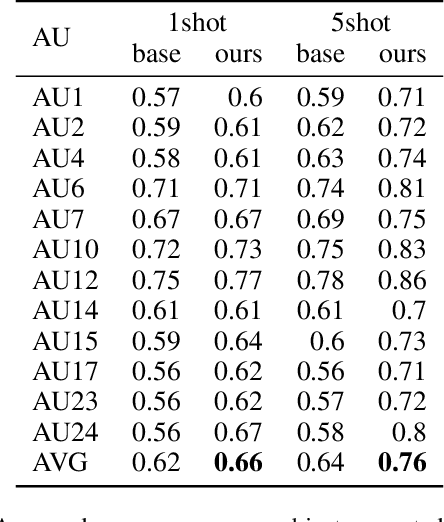
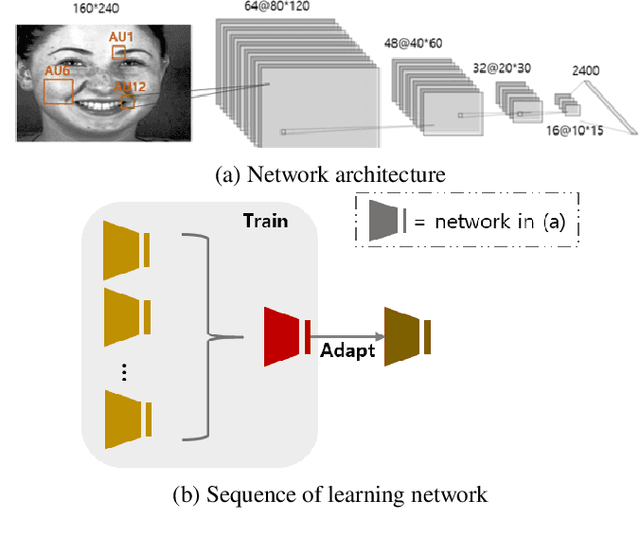
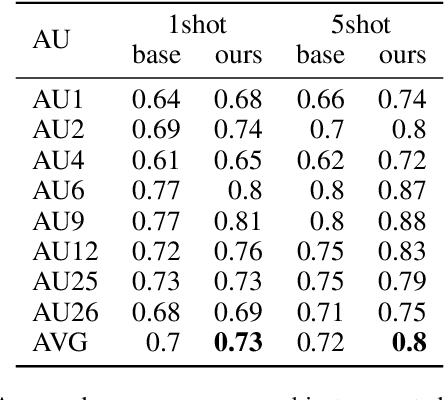
Detecting facial action units (AU) is one of the fundamental steps in automatic recognition of facial expression of emotions and cognitive states. Though there have been a variety of approaches proposed for this task, most of these models are trained only for the specific target AUs, and as such they fail to easily adapt to the task of recognition of new AUs (i.e., those not initially used to train the target models). In this paper, we propose a deep learning approach for facial AU detection that can easily and in a fast manner adapt to a new AU or target subject by leveraging only a few labeled samples from the new task (either an AU or subject). To this end, we propose a modeling approach based on the notion of the model-agnostic meta-learning [C. Finn and Levine, 2017], originally proposed for the general image recognition/detection tasks (e.g., the character recognition from the Omniglot dataset). Specifically, each subject and/or AU is treated as a new learning task and the model learns to adapt based on the knowledge of the previous tasks (the AUs and subjects used to pre-train the target models). Thus, given a new subject or AU, this meta-knowledge (that is shared among training and test tasks) is used to adapt the model to the new task using the notion of deep learning and model-agnostic meta-learning. We show on two benchmark datasets (BP4D and DISFA) for facial AU detection that the proposed approach can be easily adapted to new tasks (AUs/subjects). Using only a few labeled examples from these tasks, the model achieves large improvements over the baselines (i.e., non-adapted models).
Identity-Free Facial Expression Recognition using conditional Generative Adversarial Network
Mar 19, 2019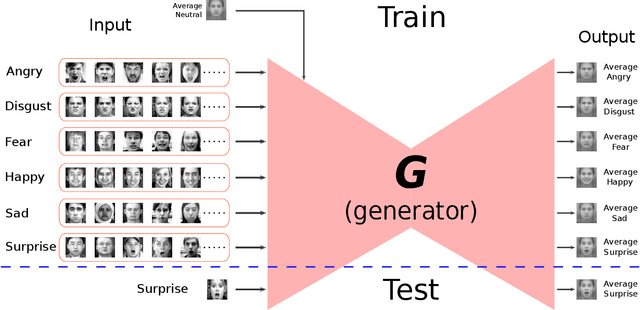
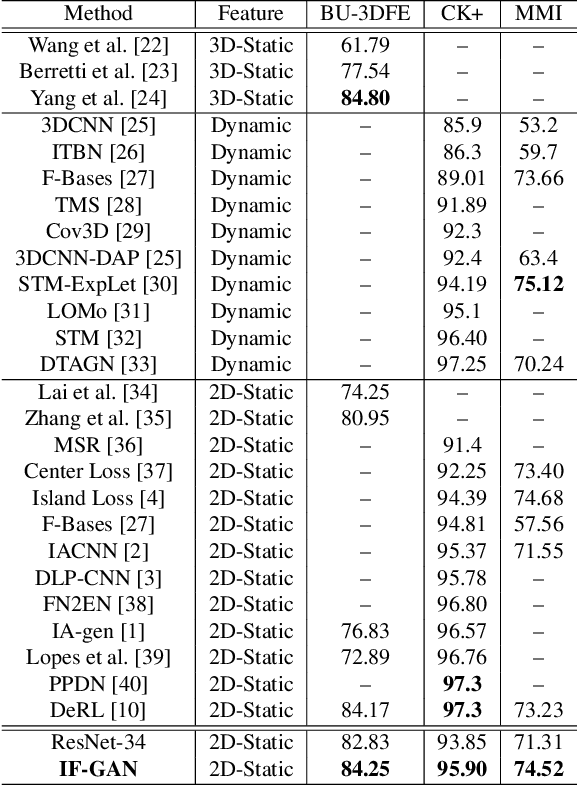
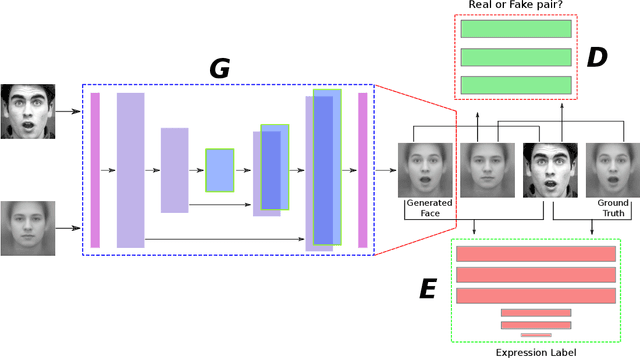

In this paper, we proposed a novel Identity-free conditional Generative Adversarial Network (IF-GAN) to explicitly reduce inter-subject variations for facial expression recognition. Specifically, for any given input face image, a conditional generative model was developed to transform an average neutral face, which is calculated from various subjects showing neutral expressions, to an average expressive face with the same expression as the input image. Since the transformed images have the same synthetic "average" identity, they differ from each other by only their expressions and thus, can be used for identity-free expression classification. In this work, an end-to-end system was developed to perform expression transformation and expression recognition in the IF-GAN framework. Experimental results on three facial expression datasets have demonstrated that the proposed IF-GAN outperforms the baseline CNN model and achieves comparable or better performance compared with the state-of-the-art methods for facial expression recognition.
Multimodal Engagement Analysis from Facial Videos in the Classroom
Jan 11, 2021
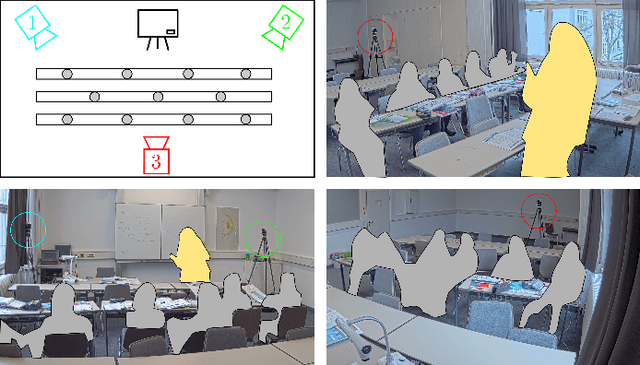
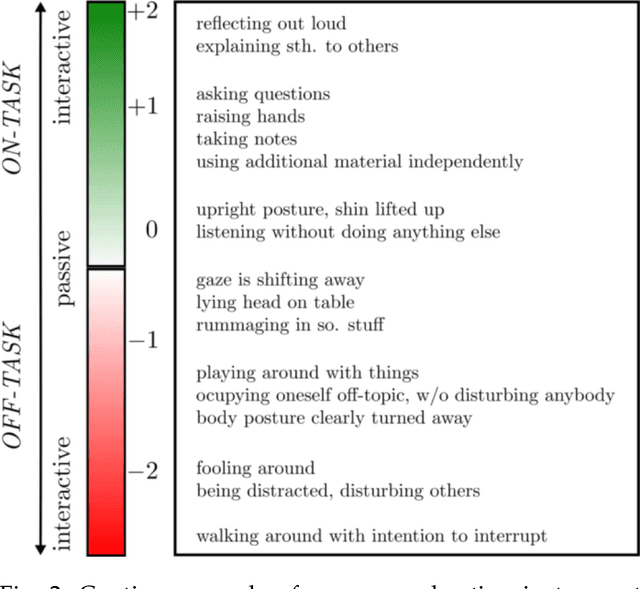
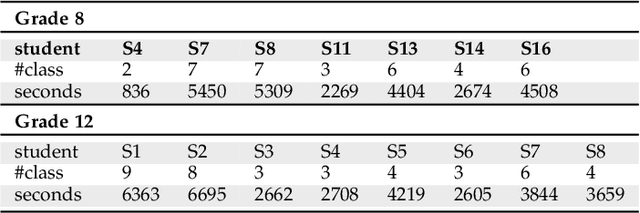
Student engagement is a key construct for learning and teaching. While most of the literature explored the student engagement analysis on computer-based settings, this paper extends that focus to classroom instruction. To best examine student visual engagement in the classroom, we conducted a study utilizing the audiovisual recordings of classes at a secondary school over one and a half month's time, acquired continuous engagement labeling per student (N=15) in repeated sessions, and explored computer vision methods to classify engagement levels from faces in the classroom. We trained deep embeddings for attentional and emotional features, training Attention-Net for head pose estimation and Affect-Net for facial expression recognition. We additionally trained different engagement classifiers, consisting of Support Vector Machines, Random Forest, Multilayer Perceptron, and Long Short-Term Memory, for both features. The best performing engagement classifiers achieved AUCs of .620 and .720 in Grades 8 and 12, respectively. We further investigated fusion strategies and found score-level fusion either improves the engagement classifiers or is on par with the best performing modality. We also investigated the effect of personalization and found that using only 60-seconds of person-specific data selected by margin uncertainty of the base classifier yielded an average AUC improvement of .084.