 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Bridging Unpaired Facial Photos And Sketches By Line-drawings
Feb 25, 2021
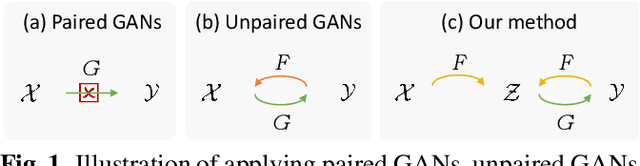
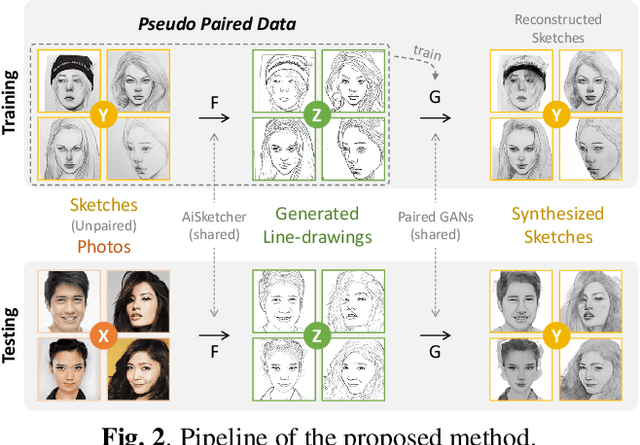
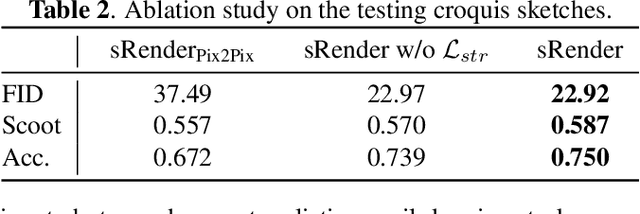
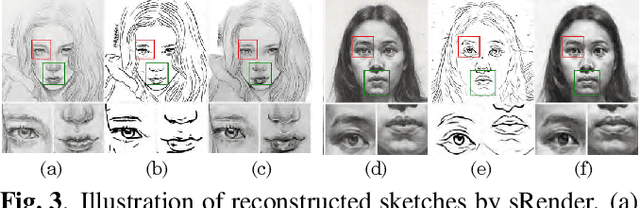
In this paper, we propose a novel method to learn face sketch synthesis models by using unpaired data. Our main idea is bridging the photo domain $\mathcal{X}$ and the sketch domain $Y$ by using the line-drawing domain $\mathcal{Z}$. Specially, we map both photos and sketches to line-drawings by using a neural style transfer method, i.e. $F: \mathcal{X}/\mathcal{Y} \mapsto \mathcal{Z}$. Consequently, we obtain \textit{pseudo paired data} $(\mathcal{Z}, \mathcal{Y})$, and can learn the mapping $G:\mathcal{Z} \mapsto \mathcal{Y}$ in a supervised learning manner. In the inference stage, given a facial photo, we can first transfer it to a line-drawing and then to a sketch by $G \circ F$. Additionally, we propose a novel stroke loss for generating different types of strokes. Our method, termed sRender, accords well with human artists' rendering process. Experimental results demonstrate that sRender can generate multi-style sketches, and significantly outperforms existing unpaired image-to-image translation methods.
Are GAN-based Morphs Threatening Face Recognition?
May 05, 2022
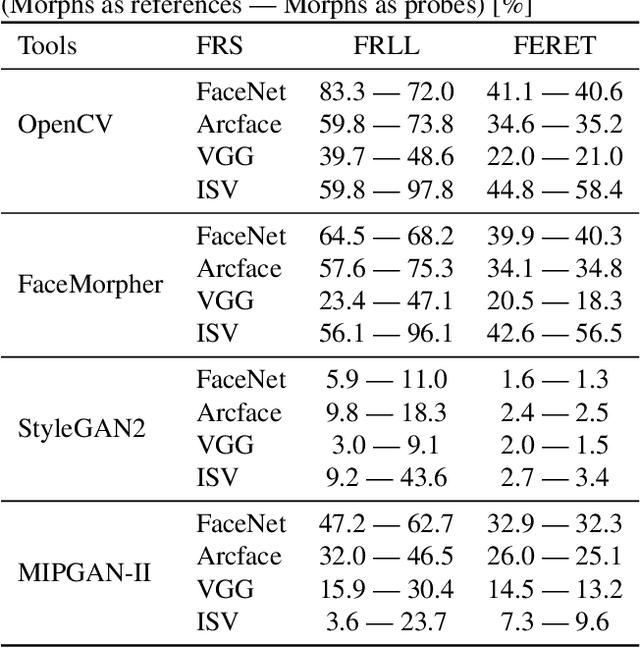
Morphing attacks are a threat to biometric systems where the biometric reference in an identity document can be altered. This form of attack presents an important issue in applications relying on identity documents such as border security or access control. Research in generation of face morphs and their detection is developing rapidly, however very few datasets with morphing attacks and open-source detection toolkits are publicly available. This paper bridges this gap by providing two datasets and the corresponding code for four types of morphing attacks: two that rely on facial landmarks based on OpenCV and FaceMorpher, and two that use StyleGAN 2 to generate synthetic morphs. We also conduct extensive experiments to assess the vulnerability of four state-of-the-art face recognition systems, including FaceNet, VGG-Face, ArcFace, and ISV. Surprisingly, the experiments demonstrate that, although visually more appealing, morphs based on StyleGAN 2 do not pose a significant threat to the state to face recognition systems, as these morphs were outmatched by the simple morphs that are based facial landmarks.
* arXiv admin note: substantial text overlap with arXiv:2012.05344
GeoConv: Geodesic Guided Convolution for Facial Action Unit Recognition
Mar 06, 2020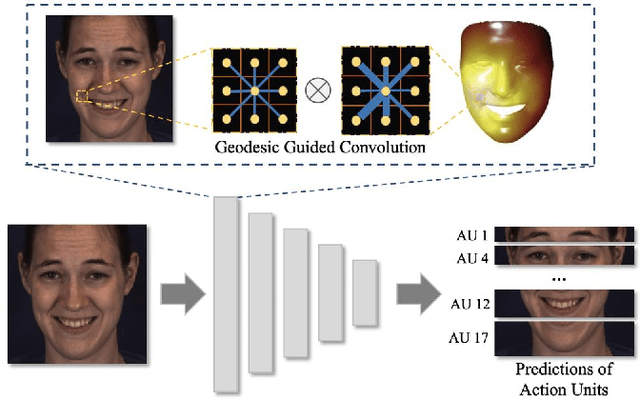
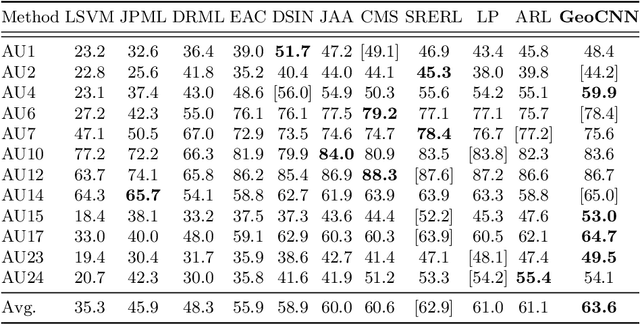
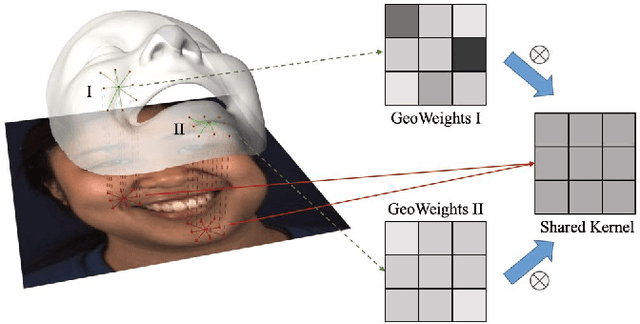
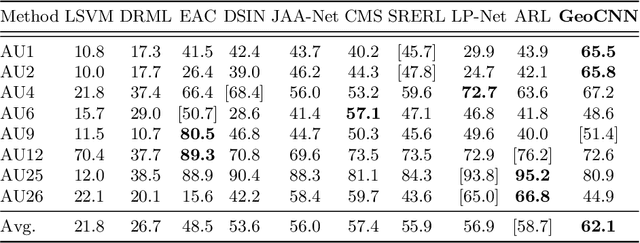
Automatic facial action unit (AU) recognition has attracted great attention but still remains a challenging task, as subtle changes of local facial muscles are difficult to thoroughly capture. Most existing AU recognition approaches leverage geometry information in a straightforward 2D or 3D manner, which either ignore 3D manifold information or suffer from high computational costs. In this paper, we propose a novel geodesic guided convolution (GeoConv) for AU recognition by embedding 3D manifold information into 2D convolutions. Specifically, the kernel of GeoConv is weighted by our introduced geodesic weights, which are negatively correlated to geodesic distances on a coarsely reconstructed 3D face model. Moreover, based on GeoConv, we further develop an end-to-end trainable framework named GeoCNN for AU recognition. Extensive experiments on BP4D and DISFA benchmarks show that our approach significantly outperforms the state-of-the-art AU recognition methods.
Robustness of Facial Recognition to GAN-based Face-morphing Attacks
Dec 18, 2020
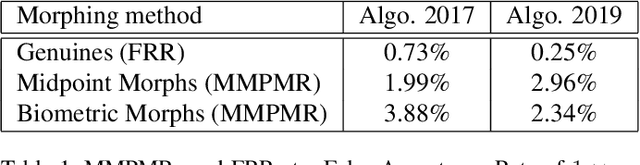

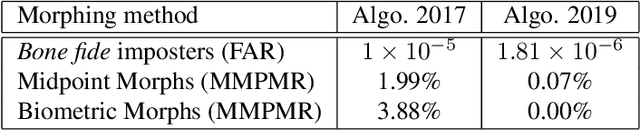
Face-morphing attacks have been a cause for concern for a number of years. Striving to remain one step ahead of attackers, researchers have proposed many methods of both creating and detecting morphed images. These detection methods, however, have generally proven to be inadequate. In this work we identify two new, GAN-based methods that an attacker may already have in his arsenal. Each method is evaluated against state-of-the-art facial recognition (FR) algorithms and we demonstrate that improvements to the fidelity of FR algorithms do lead to a reduction in the success rate of attacks provided morphed images are considered when setting operational acceptance thresholds.
AT-DDPM: Restoring Faces degraded by Atmospheric Turbulence using Denoising Diffusion Probabilistic Models
Aug 24, 2022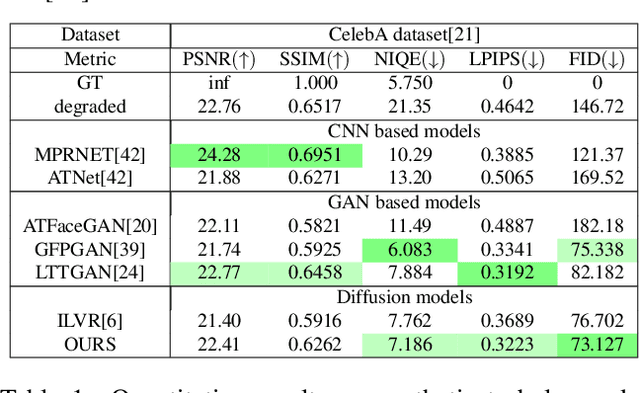
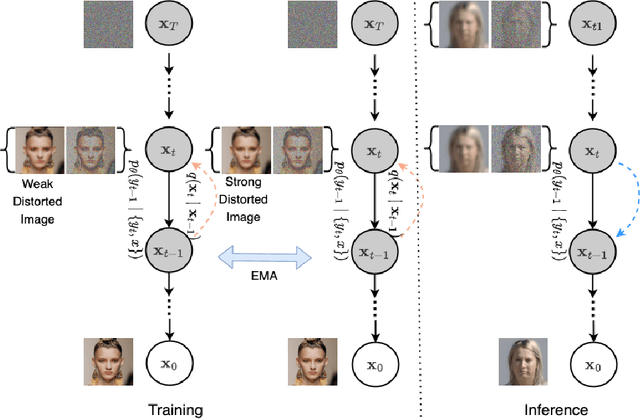
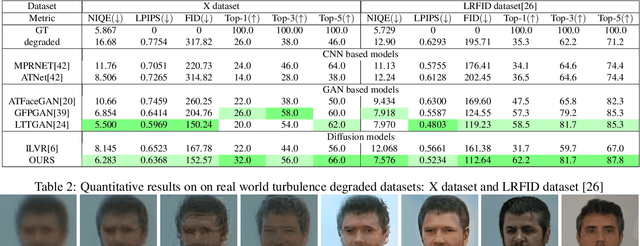

Although many long-range imaging systems are designed to support extended vision applications, a natural obstacle to their operation is degradation due to atmospheric turbulence. Atmospheric turbulence causes significant degradation to image quality by introducing blur and geometric distortion. In recent years, various deep learning-based single image atmospheric turbulence mitigation methods, including CNN-based and GAN inversion-based, have been proposed in the literature which attempt to remove the distortion in the image. However, some of these methods are difficult to train and often fail to reconstruct facial features and produce unrealistic results especially in the case of high turbulence. Denoising Diffusion Probabilistic Models (DDPMs) have recently gained some traction because of their stable training process and their ability to generate high quality images. In this paper, we propose the first DDPM-based solution for the problem of atmospheric turbulence mitigation. We also propose a fast sampling technique for reducing the inference times for conditional DDPMs. Extensive experiments are conducted on synthetic and real-world data to show the significance of our model. To facilitate further research, all codes and pretrained models will be made public after the review process.
Simultaneous regression and feature learning for facial landmarking
Apr 24, 2019
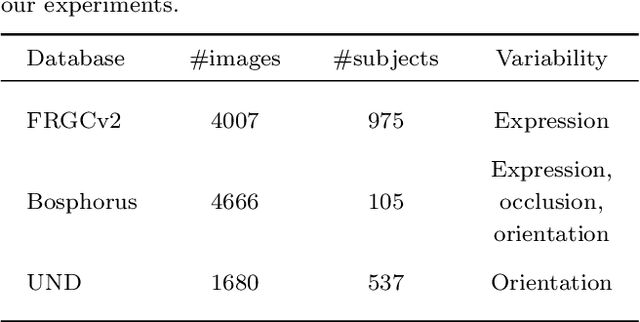
Face alignment (or facial landmarking) is an important task in many face-related applications, ranging from registration, tracking and animation to higher-level classification problems such as face, expression or attribute recognition. While several solutions have been presented in the literature for this task so far, reliably locating salient facial features across a wide range of posses still remains challenging. To address this issue, we propose in this paper a novel method for automatic facial landmark localization in 3D face data designed specifically to address appearance variability caused by significant pose variations. Our method builds on recent cascaded-regression-based methods to facial landmarking and uses a gating mechanism to incorporate multiple linear cascaded regression models each trained for a limited range of poses into a single powerful landmarking model capable of processing arbitrary posed input data. We develop two distinct approaches around the proposed gating mechanism: i) the first uses a gated multiple ridge descent (GRID) mechanism in conjunction with established (hand-crafted) HOG features for face alignment and achieves state-of-the-art landmarking performance across a wide range of facial poses, ii) the second simultaneously learns multiple-descent directions as well as binary features (SMUF) that are optimal for the alignment tasks and in addition to competitive landmarking results also ensures extremely rapid processing. We evaluate both approaches in rigorous experiments on several popular datasets of 3D face images, i.e., the FRGCv2 and Bosphorus 3D Face datasets and image collections F and G from the University of Notre Dame. The results of our evaluation show that both approaches are competitive in comparison to the state-of-the-art, while exhibiting considerable robustness to pose variations.
MMNet: Muscle motion-guided network for micro-expression recognition
Jan 14, 2022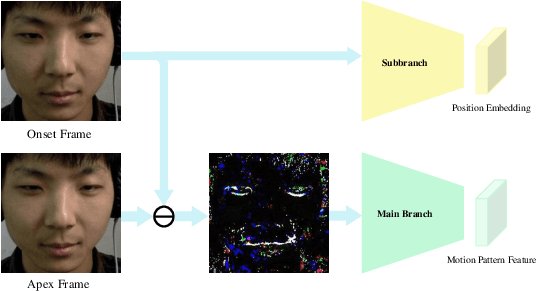
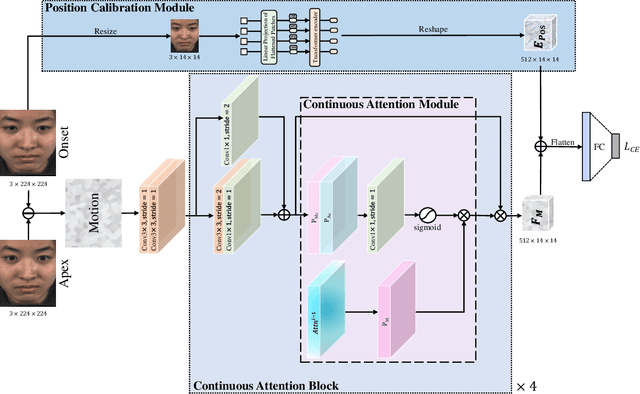
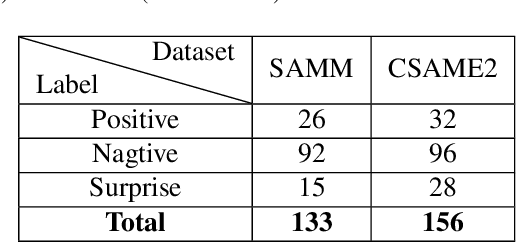
Facial micro-expressions (MEs) are involuntary facial motions revealing peoples real feelings and play an important role in the early intervention of mental illness, the national security, and many human-computer interaction systems. However, existing micro-expression datasets are limited and usually pose some challenges for training good classifiers. To model the subtle facial muscle motions, we propose a robust micro-expression recognition (MER) framework, namely muscle motion-guided network (MMNet). Specifically, a continuous attention (CA) block is introduced to focus on modeling local subtle muscle motion patterns with little identity information, which is different from most previous methods that directly extract features from complete video frames with much identity information. Besides, we design a position calibration (PC) module based on the vision transformer. By adding the position embeddings of the face generated by PC module at the end of the two branches, the PC module can help to add position information to facial muscle motion pattern features for the MER. Extensive experiments on three public micro-expression datasets demonstrate that our approach outperforms state-of-the-art methods by a large margin.
TANet: A new Paradigm for Global Face Super-resolution via Transformer-CNN Aggregation Network
Sep 16, 2021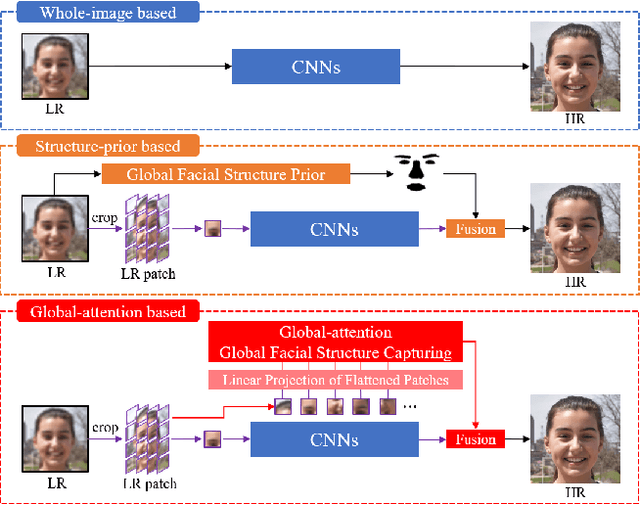
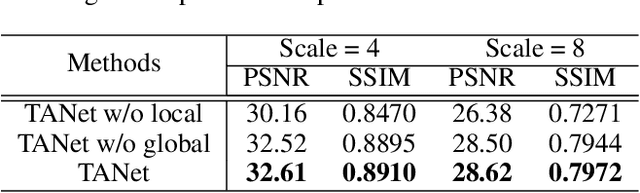
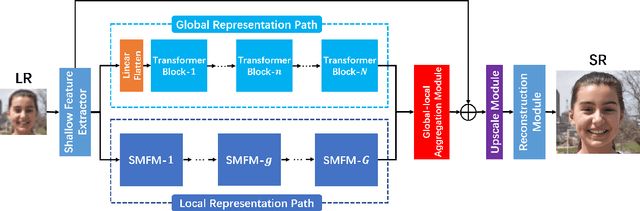
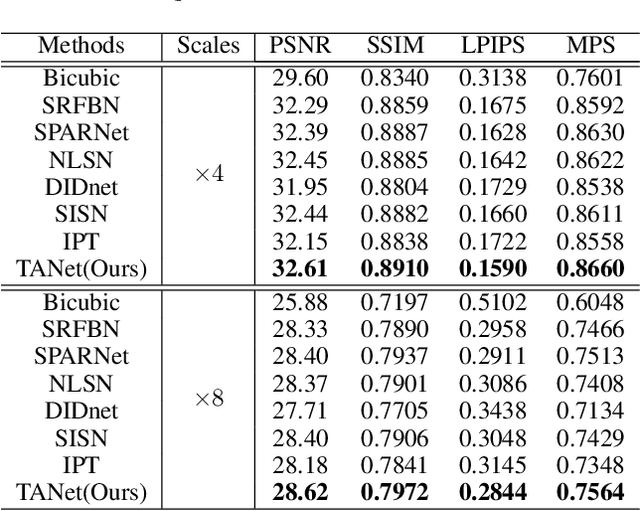
Recently, face super-resolution (FSR) methods either feed whole face image into convolutional neural networks (CNNs) or utilize extra facial priors (e.g., facial parsing maps, facial landmarks) to focus on facial structure, thereby maintaining the consistency of the facial structure while restoring facial details. However, the limited receptive fields of CNNs and inaccurate facial priors will reduce the naturalness and fidelity of the reconstructed face. In this paper, we propose a novel paradigm based on the self-attention mechanism (i.e., the core of Transformer) to fully explore the representation capacity of the facial structure feature. Specifically, we design a Transformer-CNN aggregation network (TANet) consisting of two paths, in which one path uses CNNs responsible for restoring fine-grained facial details while the other utilizes a resource-friendly Transformer to capture global information by exploiting the long-distance visual relation modeling. By aggregating the features from the above two paths, the consistency of global facial structure and fidelity of local facial detail restoration are strengthened simultaneously. Experimental results of face reconstruction and recognition verify that the proposed method can significantly outperform the state-of-the-art methods.
FV2ES: A Fully End2End Multimodal System for Fast Yet Effective Video Emotion Recognition Inference
Sep 21, 2022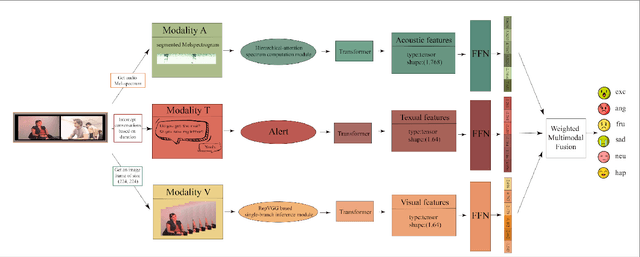
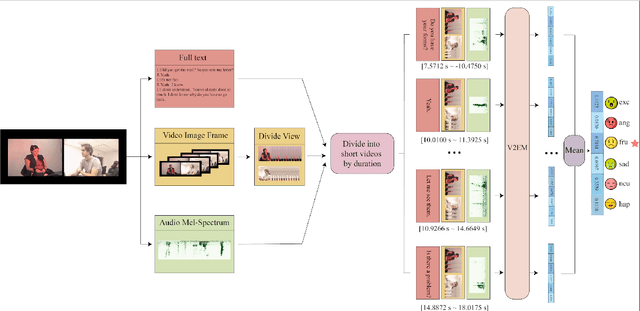
In the latest social networks, more and more people prefer to express their emotions in videos through text, speech, and rich facial expressions. Multimodal video emotion analysis techniques can help understand users' inner world automatically based on human expressions and gestures in images, tones in voices, and recognized natural language. However, in the existing research, the acoustic modality has long been in a marginal position as compared to visual and textual modalities. That is, it tends to be more difficult to improve the contribution of the acoustic modality for the whole multimodal emotion recognition task. Besides, although better performance can be obtained by introducing common deep learning methods, the complex structures of these training models always result in low inference efficiency, especially when exposed to high-resolution and long-length videos. Moreover, the lack of a fully end-to-end multimodal video emotion recognition system hinders its application. In this paper, we designed a fully multimodal video-to-emotion system (named FV2ES) for fast yet effective recognition inference, whose benefits are threefold: (1) The adoption of the hierarchical attention method upon the sound spectra breaks through the limited contribution of the acoustic modality and outperforms the existing models' performance on both IEMOCAP and CMU-MOSEI datasets; (2) the introduction of the idea of multi-scale for visual extraction while single-branch for inference brings higher efficiency and maintains the prediction accuracy at the same time; (3) the further integration of data pre-processing into the aligned multimodal learning model allows the significant reduction of computational costs and storage space.
Emotion-Controllable Generalized Talking Face Generation
May 02, 2022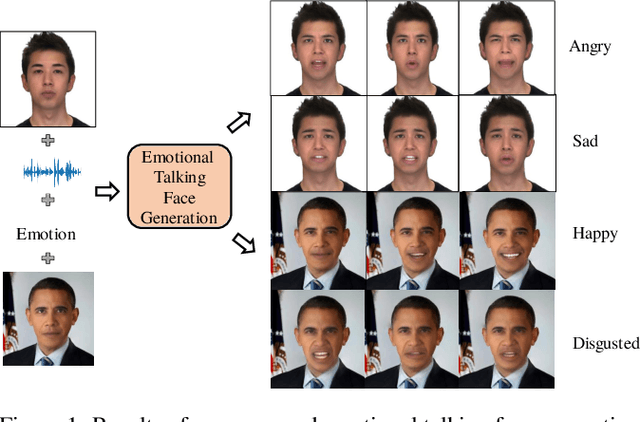
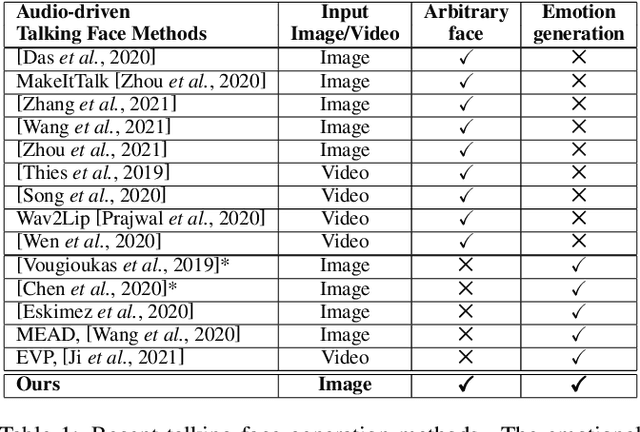
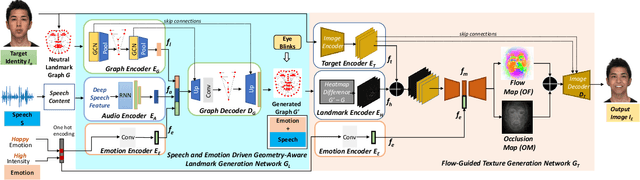

Despite the significant progress in recent years, very few of the AI-based talking face generation methods attempt to render natural emotions. Moreover, the scope of the methods is majorly limited to the characteristics of the training dataset, hence they fail to generalize to arbitrary unseen faces. In this paper, we propose a one-shot facial geometry-aware emotional talking face generation method that can generalize to arbitrary faces. We propose a graph convolutional neural network that uses speech content feature, along with an independent emotion input to generate emotion and speech-induced motion on facial geometry-aware landmark representation. This representation is further used in our optical flow-guided texture generation network for producing the texture. We propose a two-branch texture generation network, with motion and texture branches designed to consider the motion and texture content independently. Compared to the previous emotion talking face methods, our method can adapt to arbitrary faces captured in-the-wild by fine-tuning with only a single image of the target identity in neutral emotion.