 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
MoFaNeRF: Morphable Facial Neural Radiance Field
Dec 04, 2021
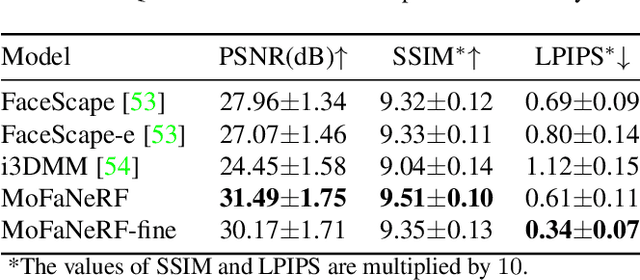
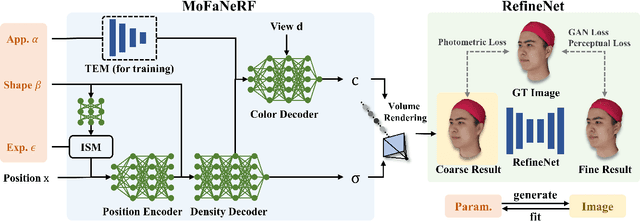
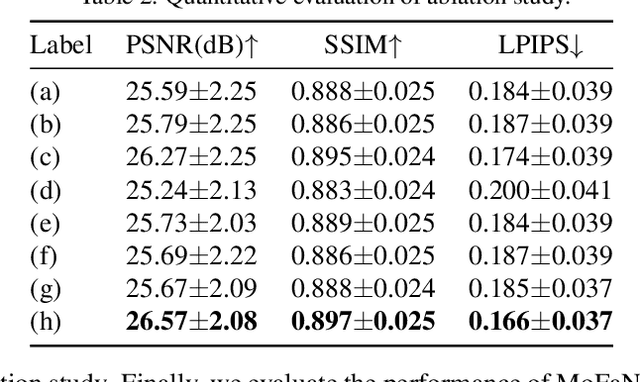

We propose a parametric model that maps free-view images into a vector space of coded facial shape, expression and appearance using a neural radiance field, namely Morphable Facial NeRF. Specifically, MoFaNeRF takes the coded facial shape, expression and appearance along with space coordinate and view direction as input to an MLP, and outputs the radiance of the space point for photo-realistic image synthesis. Compared with conventional 3D morphable models (3DMM), MoFaNeRF shows superiority in directly synthesizing photo-realistic facial details even for eyes, mouths, and beards. Also, continuous face morphing can be easily achieved by interpolating the input shape, expression and appearance codes. By introducing identity-specific modulation and texture encoder, our model synthesizes accurate photometric details and shows strong representation ability. Our model shows strong ability on multiple applications including image-based fitting, random generation, face rigging, face editing, and novel view synthesis. Experiments show that our method achieves higher representation ability than previous parametric models, and achieves competitive performance in several applications. To the best of our knowledge, our work is the first facial parametric model built upon a neural radiance field that can be used in fitting, generation and manipulation. Our code and model are released in https://github.com/zhuhao-nju/mofanerf.
Multispectral Imaging for Differential Face Morphing Attack Detection: A Preliminary Study
Apr 07, 2023
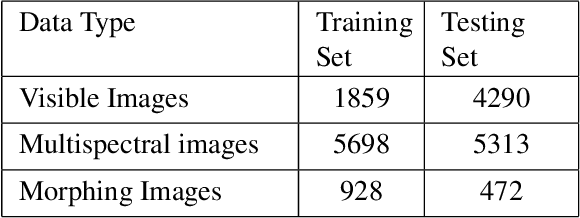
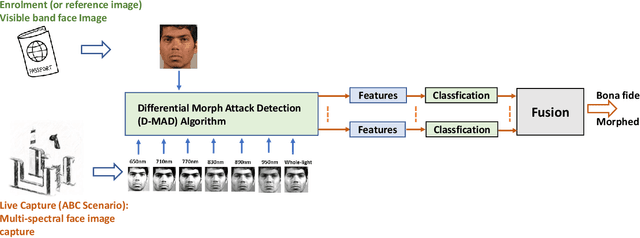
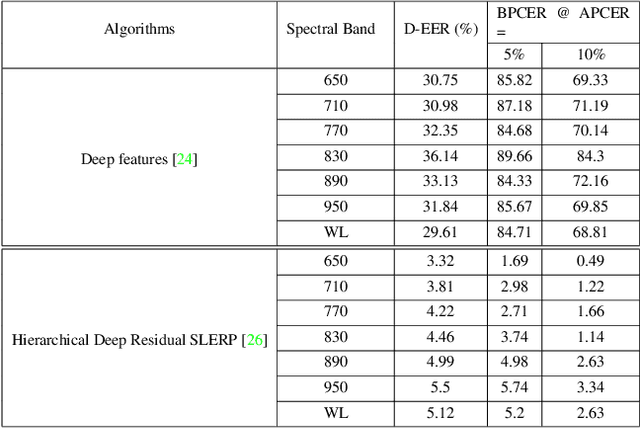
Face morphing attack detection is emerging as an increasingly challenging problem owing to advancements in high-quality and realistic morphing attack generation. Reliable detection of morphing attacks is essential because these attacks are targeted for border control applications. This paper presents a multispectral framework for differential morphing-attack detection (D-MAD). The D-MAD methods are based on using two facial images that are captured from the ePassport (also called the reference image) and the trusted device (for example, Automatic Border Control (ABC) gates) to detect whether the face image presented in ePassport is morphed. The proposed multispectral D-MAD framework introduce a multispectral image captured as a trusted capture to capture seven different spectral bands to detect morphing attacks. Extensive experiments were conducted on the newly created datasets with 143 unique data subjects that were captured using both visible and multispectral cameras in multiple sessions. The results indicate the superior performance of the proposed multispectral framework compared to visible images.
Recurrent Transformer Encoders for Vision-based Estimation of Fatigue and Engagement in Cognitive Training Sessions
Apr 24, 2023
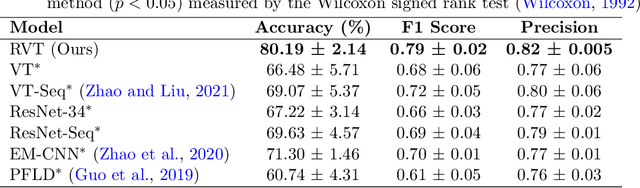
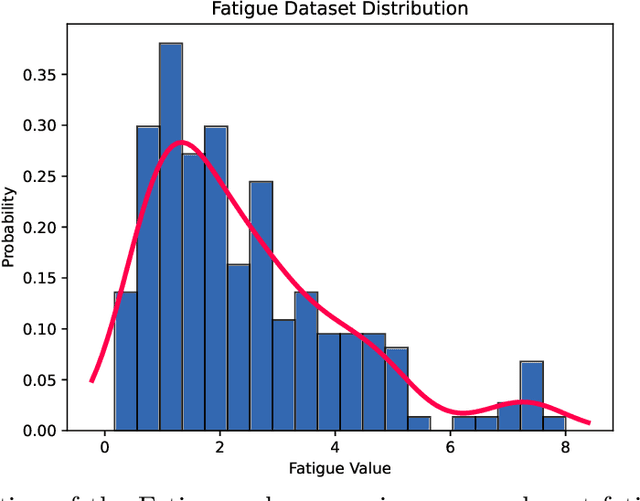

The effectiveness of computerized cognitive training in slowing cognitive decline and brain aging in dementia is often limited by the engagement of participants in the training. Monitoring older users' real-time engagement in domains of attention, motivation, and affect is crucial to understanding the overall effectiveness of such training. In this paper, we propose to predict engagement, quantified via an established mental fatigue measure assessing users' perceived attention, motivation, and affect throughout computerized cognitive training sessions, in older adults with mild cognitive impairment (MCI), by monitoring their real-time video-recorded facial gestures in training sessions. To achieve the goal, we used computer vision, analyzing video frames every 5 seconds to optimize the balance between information retention and data size, and developed a novel Recurrent Video Transformer (RVT). Our RVT model, which combines a clip-wise transformer encoder module and a session-wise Recurrent Neural Network (RNN) classifier, achieved the highest balanced accuracy, F1 score, and precision compared to other state-of-the-art models for both detecting mental fatigue/disengagement cases (binary classification) and rating the level of mental fatigue (multi-class classification). By leveraging dynamic temporal information, the RVT model demonstrates the potential to accurately predict engagement among computerized cognitive training users, which lays the foundation for future work to modulate the level of engagement in computerized cognitive training interventions. The code will be released.
Depression Recognition using Remote Photoplethysmography from Facial Videos
Jun 09, 2022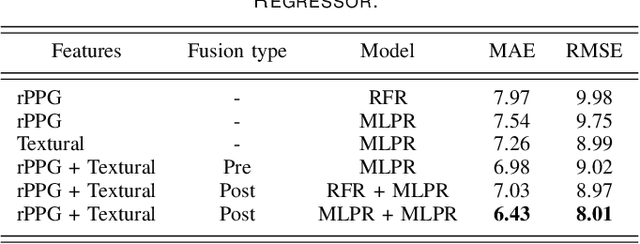
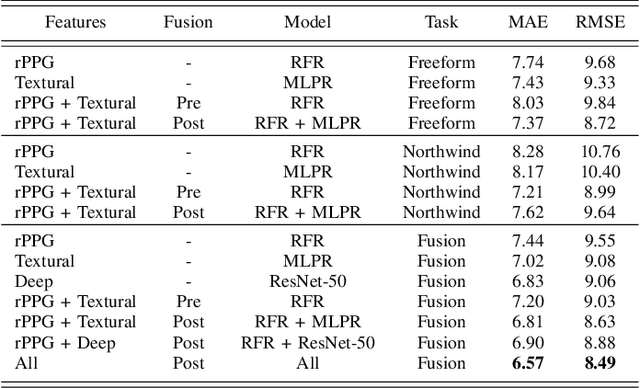
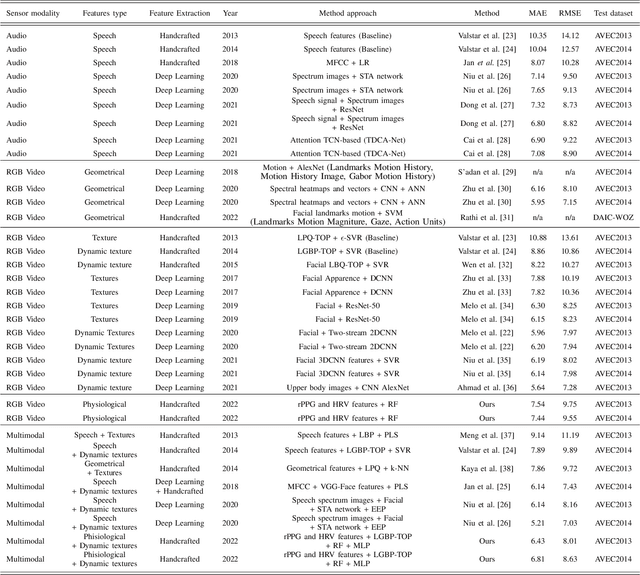
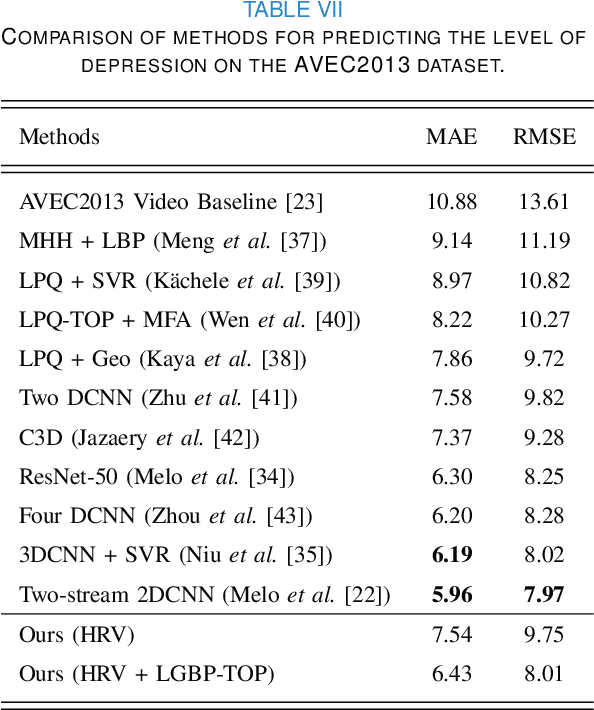
Depression is a mental illness that may be harmful to an individual's health. The detection of mental health disorders in the early stages and a precise diagnosis are critical to avoid social, physiological, or psychological side effects. This work analyzes physiological signals to observe if different depressive states have a noticeable impact on the blood volume pulse (BVP) and the heart rate variability (HRV) response. Although typically, HRV features are calculated from biosignals obtained with contact-based sensors such as wearables, we propose instead a novel scheme that directly extracts them from facial videos, just based on visual information, removing the need for any contact-based device. Our solution is based on a pipeline that is able to extract complete remote photoplethysmography signals (rPPG) in a fully unsupervised manner. We use these rPPG signals to calculate over 60 statistical, geometrical, and physiological features that are further used to train several machine learning regressors to recognize different levels of depression. Experiments on two benchmark datasets indicate that this approach offers comparable results to other audiovisual modalities based on voice or facial expression, potentially complementing them. In addition, the results achieved for the proposed method show promising and solid performance that outperforms hand-engineered methods and is comparable to deep learning-based approaches.
Face Animation with an Attribute-Guided Diffusion Model
Apr 06, 2023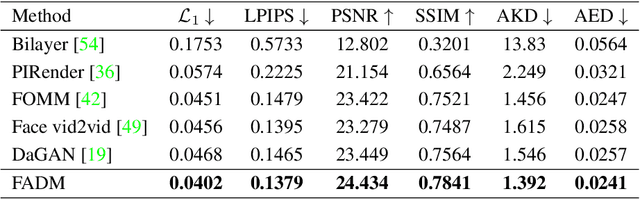
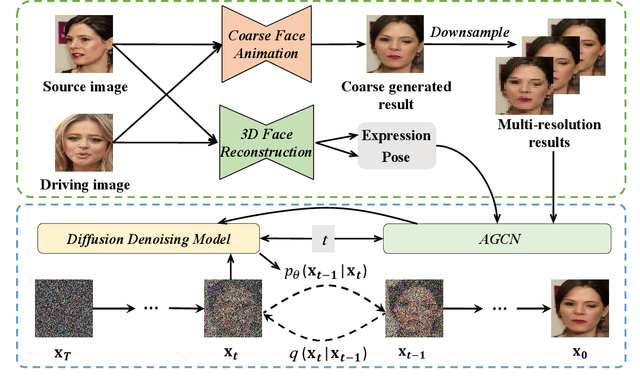
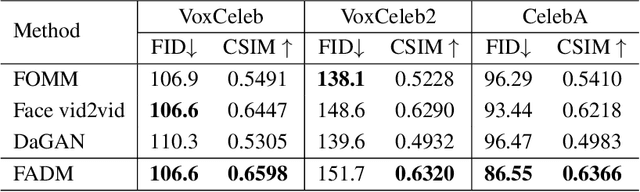
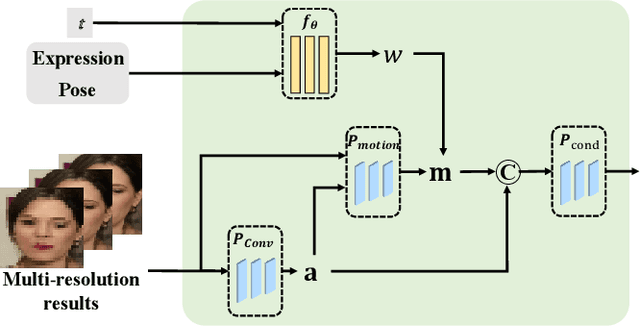
Face animation has achieved much progress in computer vision. However, prevailing GAN-based methods suffer from unnatural distortions and artifacts due to sophisticated motion deformation. In this paper, we propose a Face Animation framework with an attribute-guided Diffusion Model (FADM), which is the first work to exploit the superior modeling capacity of diffusion models for photo-realistic talking-head generation. To mitigate the uncontrollable synthesis effect of the diffusion model, we design an Attribute-Guided Conditioning Network (AGCN) to adaptively combine the coarse animation features and 3D face reconstruction results, which can incorporate appearance and motion conditions into the diffusion process. These specific designs help FADM rectify unnatural artifacts and distortions, and also enrich high-fidelity facial details through iterative diffusion refinements with accurate animation attributes. FADM can flexibly and effectively improve existing animation videos. Extensive experiments on widely used talking-head benchmarks validate the effectiveness of FADM over prior arts.
Facial Expression Recognition based on Multi-head Cross Attention Network
Mar 24, 2022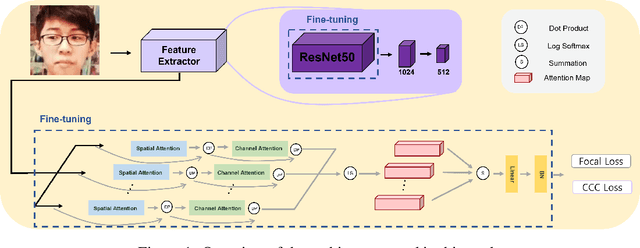


Facial expression in-the-wild is essential for various interactive computing domains. In this paper, we proposed an extended version of DAN model to address the VA estimation and facial expression challenges introduced in ABAW 2022. Our method produced preliminary results of 0.44 of mean CCC value for the VA estimation task, and 0.33 of the average F1 score for the expression classification task.
MGRR-Net: Multi-level Graph Relational Reasoning Network for Facial Action Units Detection
Apr 08, 2022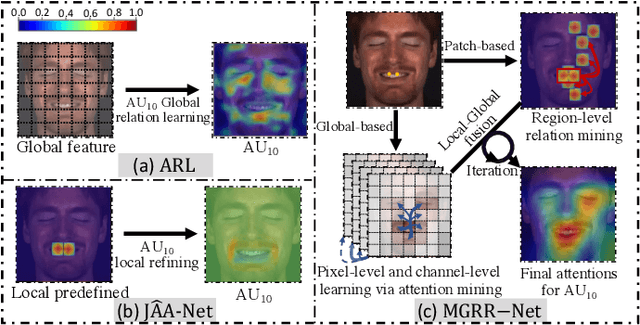
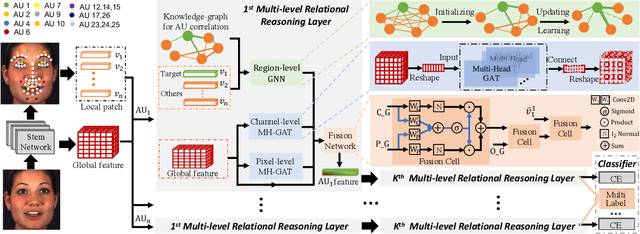
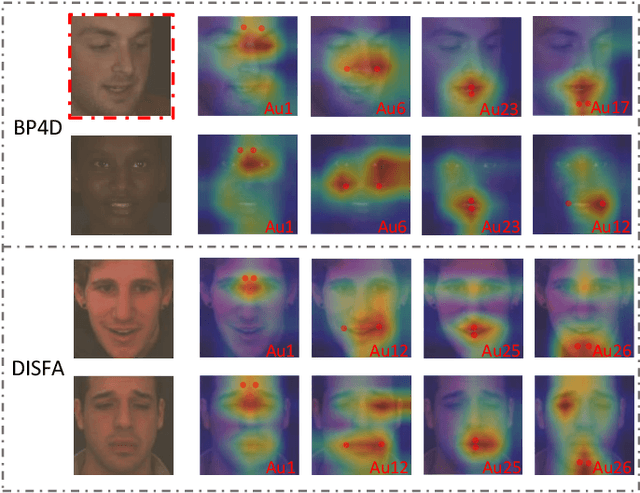
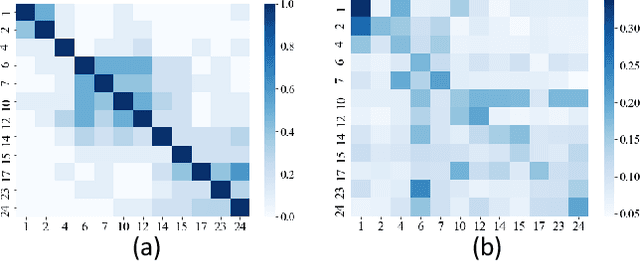
The Facial Action Coding System (FACS) encodes the action units (AUs) in facial images, which has attracted extensive research attention due to its wide use in facial expression analysis. Many methods that perform well on automatic facial action unit (AU) detection primarily focus on modeling various types of AU relations between corresponding local muscle areas, or simply mining global attention-aware facial features, however, neglect the dynamic interactions among local-global features. We argue that encoding AU features just from one perspective may not capture the rich contextual information between regional and global face features, as well as the detailed variability across AUs, because of the diversity in expression and individual characteristics. In this paper, we propose a novel Multi-level Graph Relational Reasoning Network (termed MGRR-Net) for facial AU detection. Each layer of MGRR-Net performs a multi-level (i.e., region-level, pixel-wise and channel-wise level) feature learning. While the region-level feature learning from local face patches features via graph neural network can encode the correlation across different AUs, the pixel-wise and channel-wise feature learning via graph attention network can enhance the discrimination ability of AU features from global face features. The fused features from the three levels lead to improved AU discriminative ability. Extensive experiments on DISFA and BP4D AU datasets show that the proposed approach achieves superior performance than the state-of-the-art methods.
SoK: Anti-Facial Recognition Technology
Dec 08, 2021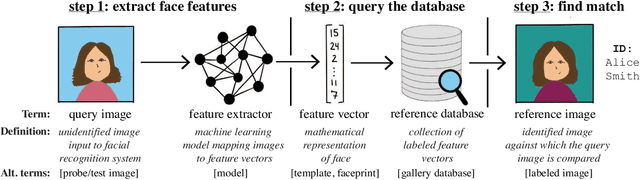
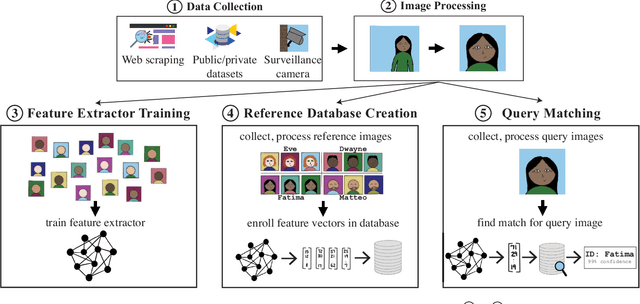

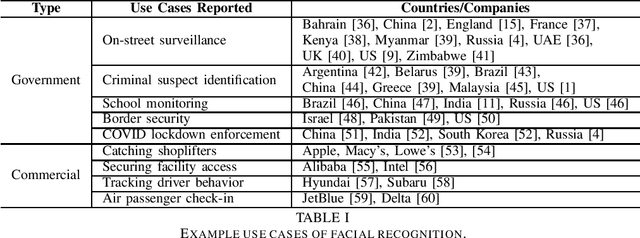
The rapid adoption of facial recognition (FR) technology by both government and commercial entities in recent years has raised concerns about civil liberties and privacy. In response, a broad suite of so-called "anti-facial recognition" (AFR) tools has been developed to help users avoid unwanted facial recognition. The set of AFR tools proposed in the last few years is wide-ranging and rapidly evolving, necessitating a step back to consider the broader design space of AFR systems and long-term challenges. This paper aims to fill that gap and provides the first comprehensive analysis of the AFR research landscape. Using the operational stages of FR systems as a starting point, we create a systematic framework for analyzing the benefits and tradeoffs of different AFR approaches. We then consider both technical and social challenges facing AFR tools and propose directions for future research in this field.
Feature Extraction Matters More: Universal Deepfake Disruption through Attacking Ensemble Feature Extractors
Mar 01, 2023
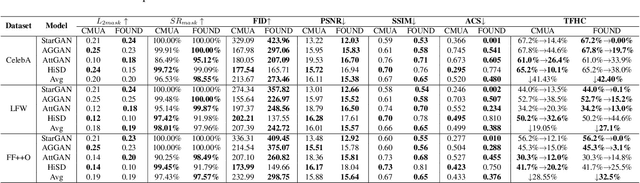
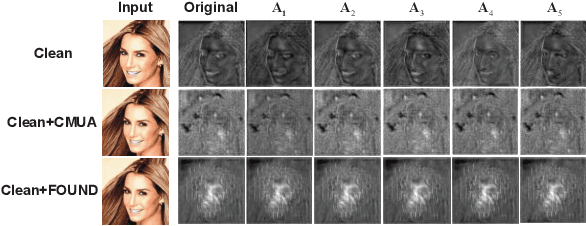

Adversarial example is a rising way of protecting facial privacy security from deepfake modification. To prevent massive facial images from being illegally modified by various deepfake models, it is essential to design a universal deepfake disruptor. However, existing works treat deepfake disruption as an End-to-End process, ignoring the functional difference between feature extraction and image reconstruction, which makes it difficult to generate a cross-model universal disruptor. In this work, we propose a novel Feature-Output ensemble UNiversal Disruptor (FOUND) against deepfake networks, which explores a new opinion that considers attacking feature extractors as the more critical and general task in deepfake disruption. We conduct an effective two-stage disruption process. We first disrupt multi-model feature extractors through multi-feature aggregation and individual-feature maintenance, and then develop a gradient-ensemble algorithm to enhance the disruption effect by simplifying the complex optimization problem of disrupting multiple End-to-End models. Extensive experiments demonstrate that FOUND can significantly boost the disruption effect against ensemble deepfake benchmark models. Besides, our method can fast obtain a cross-attribute, cross-image, and cross-model universal deepfake disruptor with only a few training images, surpassing state-of-the-art universal disruptors in both success rate and efficiency.
Learn From All: Erasing Attention Consistency for Noisy Label Facial Expression Recognition
Jul 21, 2022
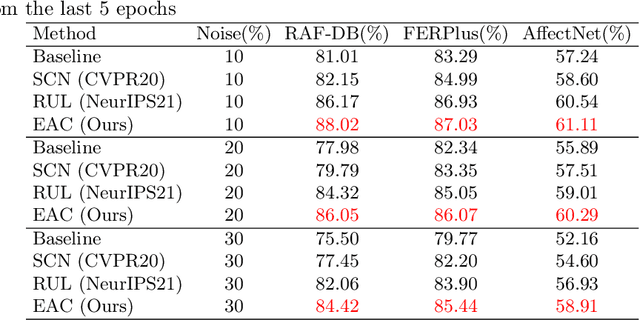
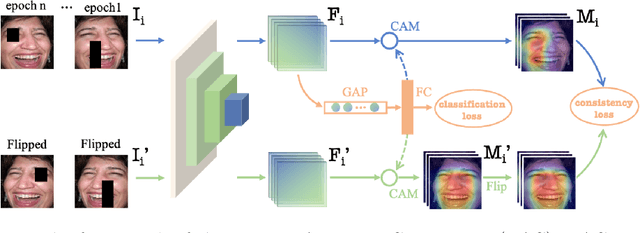

Noisy label Facial Expression Recognition (FER) is more challenging than traditional noisy label classification tasks due to the inter-class similarity and the annotation ambiguity. Recent works mainly tackle this problem by filtering out large-loss samples. In this paper, we explore dealing with noisy labels from a new feature-learning perspective. We find that FER models remember noisy samples by focusing on a part of the features that can be considered related to the noisy labels instead of learning from the whole features that lead to the latent truth. Inspired by that, we propose a novel Erasing Attention Consistency (EAC) method to suppress the noisy samples during the training process automatically. Specifically, we first utilize the flip semantic consistency of facial images to design an imbalanced framework. We then randomly erase input images and use flip attention consistency to prevent the model from focusing on a part of the features. EAC significantly outperforms state-of-the-art noisy label FER methods and generalizes well to other tasks with a large number of classes like CIFAR100 and Tiny-ImageNet. The code is available at https://github.com/zyh-uaiaaaa/Erasing-Attention-Consistency.