 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReading the Mood Behind Words: Integrating Prosody-Derived Emotional Context into Socially Responsive VR Agents
Mar 10, 2026In VR interactions with embodied conversational agents, users' emotional intent is often conveyed more by how something is said than by what is said. However, most VR agent pipelines rely on speech-to-text processing, discarding prosodic cues and often producing emotionally incongruent responses despite correct semantics. We propose an emotion-context-aware VR interaction pipeline that treats vocal emotion as explicit dialogue context in an LLM-based conversational agent. A real-time speech emotion recognition model infers users' emotional states from prosody, and the resulting emotion labels are injected into the agent's dialogue context to shape response tone and style. Results from a within-subjects VR study (N=30) show significant improvements in dialogue quality, naturalness, engagement, rapport, and human-likeness, with 93.3% of participants preferring the emotion-aware agent.
* 12 pages, 4 figures, Accepted to CHI EA 2026 (Extended Abstracts of the 2026 CHI Conference on Human Factors in Computing Systems)
Human Reaction Intensity Estimation with Ensemble of Multi-task Networks
Mar 16, 2023Facial expression in-the-wild is essential for various interactive computing domains. Especially, "Emotional Reaction Intensity" (ERI) is an important topic in the facial expression recognition task. In this paper, we propose a multi-emotional task learning-based approach and present preliminary results for the ERI challenge introduced in the 5th affective behavior analysis in-the-wild (ABAW) competition. Our method achieved the mean PCC score of 0.3254.
Learning from Synthetic Data: Facial Expression Classification based on Ensemble of Multi-task Networks
Jul 21, 2022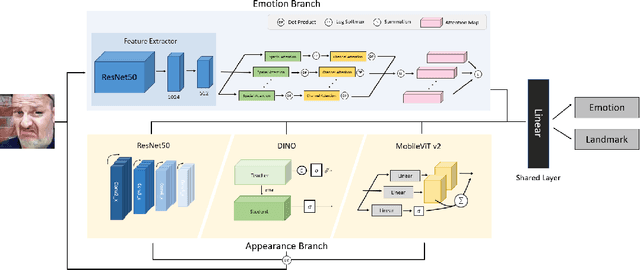


Facial expression in-the-wild is essential for various interactive computing domains. Especially, "Learning from Synthetic Data" (LSD) is an important topic in the facial expression recognition task. In this paper, we propose a multi-task learning-based facial expression recognition approach which consists of emotion and appearance learning branches that can share all face information, and present preliminary results for the LSD challenge introduced in the 4th affective behavior analysis in-the-wild (ABAW) competition. Our method achieved the mean F1 score of 0.71.
Facial Expression Recognition based on Multi-head Cross Attention Network
Mar 24, 2022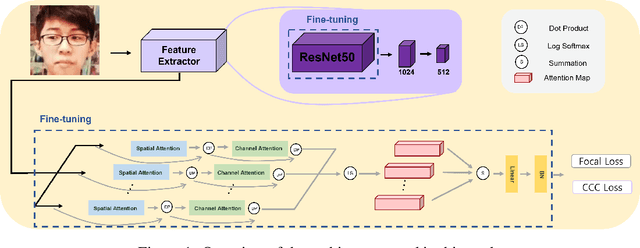


Facial expression in-the-wild is essential for various interactive computing domains. In this paper, we proposed an extended version of DAN model to address the VA estimation and facial expression challenges introduced in ABAW 2022. Our method produced preliminary results of 0.44 of mean CCC value for the VA estimation task, and 0.33 of the average F1 score for the expression classification task.