 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-Time Dynamic Data Driven Deformable Registration for Image-Guided Neurosurgery: Computational Aspects
Sep 06, 2023
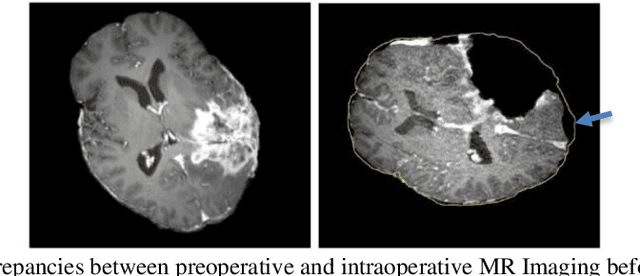
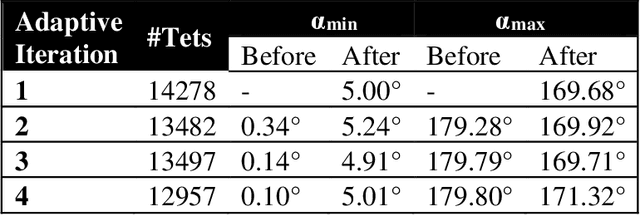
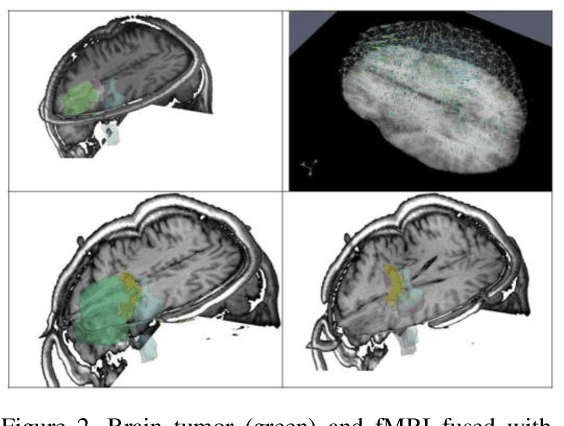
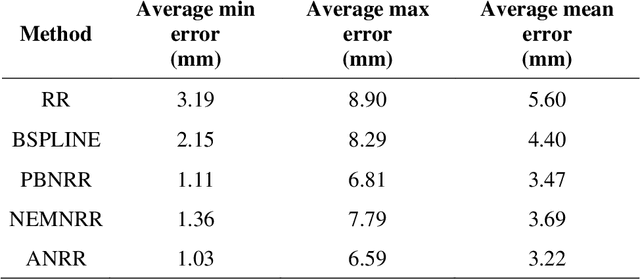
Current neurosurgical procedures utilize medical images of various modalities to enable the precise location of tumors and critical brain structures to plan accurate brain tumor resection. The difficulty of using preoperative images during the surgery is caused by the intra-operative deformation of the brain tissue (brain shift), which introduces discrepancies concerning the preoperative configuration. Intra-operative imaging allows tracking such deformations but cannot fully substitute for the quality of the pre-operative data. Dynamic Data Driven Deformable Non-Rigid Registration (D4NRR) is a complex and time-consuming image processing operation that allows the dynamic adjustment of the pre-operative image data to account for intra-operative brain shift during the surgery. This paper summarizes the computational aspects of a specific adaptive numerical approximation method and its variations for registering brain MRIs. It outlines its evolution over the last 15 years and identifies new directions for the computational aspects of the technique.
TSTTC: A Large-Scale Dataset for Time-to-Contact Estimation in Driving Scenarios
Sep 06, 2023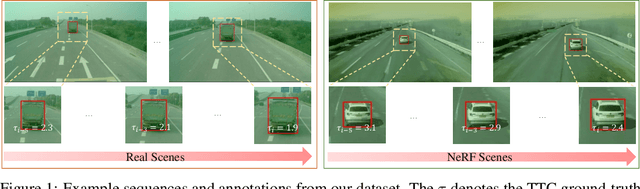
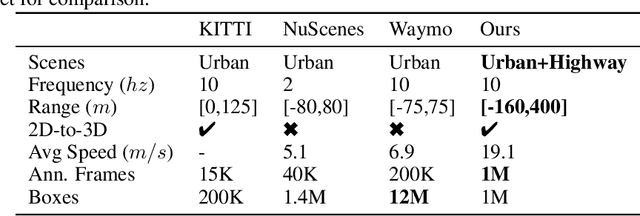
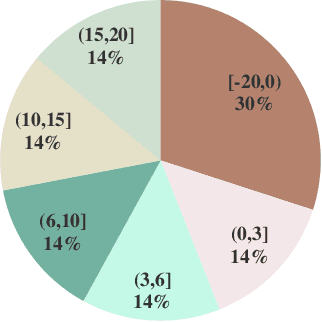

Time-to-Contact (TTC) estimation is a critical task for assessing collision risk and is widely used in various driver assistance and autonomous driving systems. The past few decades have witnessed development of related theories and algorithms. The prevalent learning-based methods call for a large-scale TTC dataset in real-world scenarios. In this work, we present a large-scale object oriented TTC dataset in the driving scene for promoting the TTC estimation by a monocular camera. To collect valuable samples and make data with different TTC values relatively balanced, we go through thousands of hours of driving data and select over 200K sequences with a preset data distribution. To augment the quantity of small TTC cases, we also generate clips using the latest Neural rendering methods. Additionally, we provide several simple yet effective TTC estimation baselines and evaluate them extensively on the proposed dataset to demonstrate their effectiveness. The proposed dataset is publicly available at https://open-dataset.tusen.ai/TSTTC.
A Geometrical Approach to Evaluate the Adversarial Robustness of Deep Neural Networks
Oct 10, 2023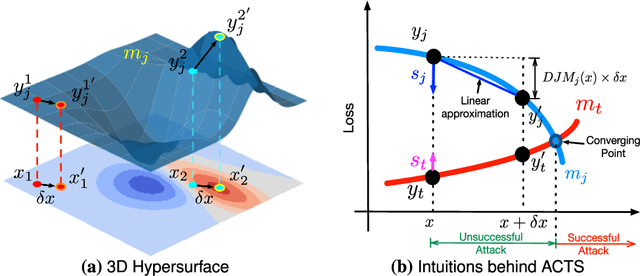
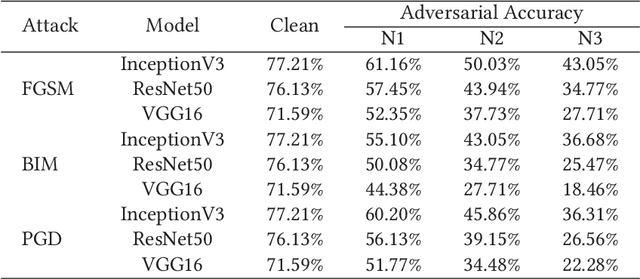
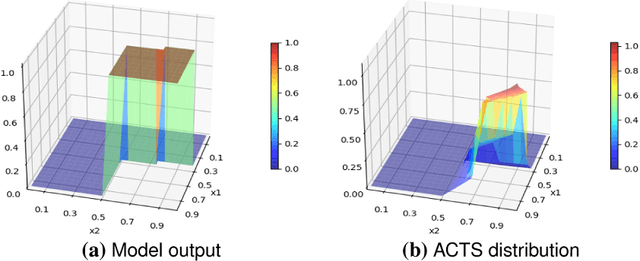
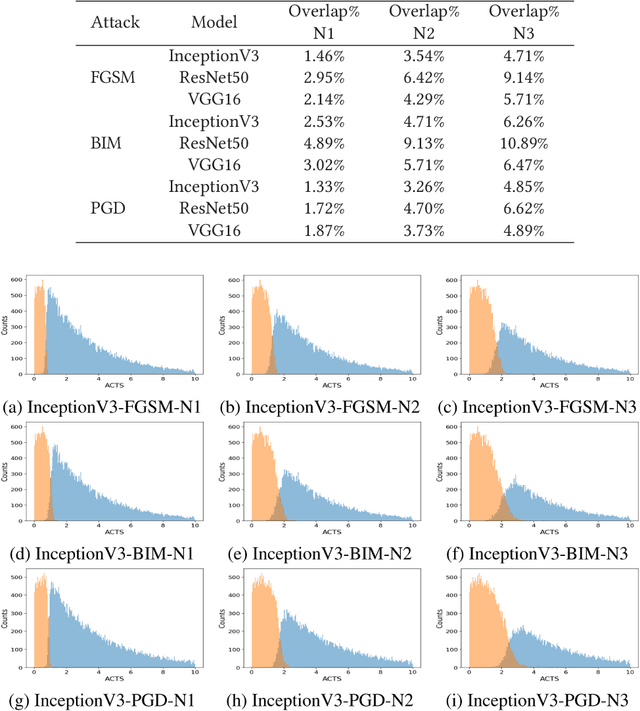
Deep Neural Networks (DNNs) are widely used for computer vision tasks. However, it has been shown that deep models are vulnerable to adversarial attacks, i.e., their performances drop when imperceptible perturbations are made to the original inputs, which may further degrade the following visual tasks or introduce new problems such as data and privacy security. Hence, metrics for evaluating the robustness of deep models against adversarial attacks are desired. However, previous metrics are mainly proposed for evaluating the adversarial robustness of shallow networks on the small-scale datasets. Although the Cross Lipschitz Extreme Value for nEtwork Robustness (CLEVER) metric has been proposed for large-scale datasets (e.g., the ImageNet dataset), it is computationally expensive and its performance relies on a tractable number of samples. In this paper, we propose the Adversarial Converging Time Score (ACTS), an attack-dependent metric that quantifies the adversarial robustness of a DNN on a specific input. Our key observation is that local neighborhoods on a DNN's output surface would have different shapes given different inputs. Hence, given different inputs, it requires different time for converging to an adversarial sample. Based on this geometry meaning, ACTS measures the converging time as an adversarial robustness metric. We validate the effectiveness and generalization of the proposed ACTS metric against different adversarial attacks on the large-scale ImageNet dataset using state-of-the-art deep networks. Extensive experiments show that our ACTS metric is an efficient and effective adversarial metric over the previous CLEVER metric.
eDKM: An Efficient and Accurate Train-time Weight Clustering for Large Language Models
Sep 02, 2023

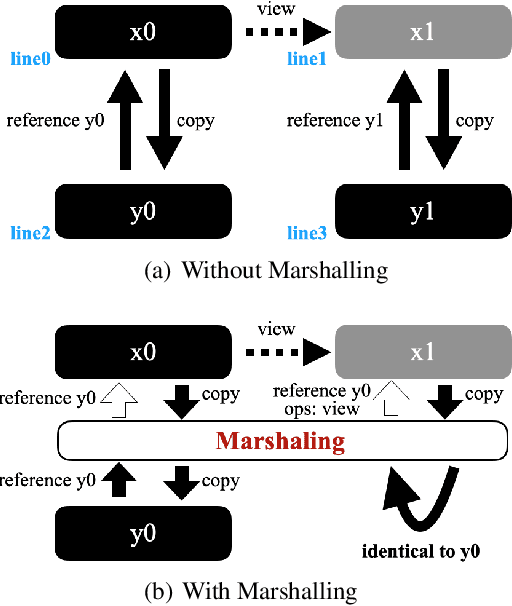
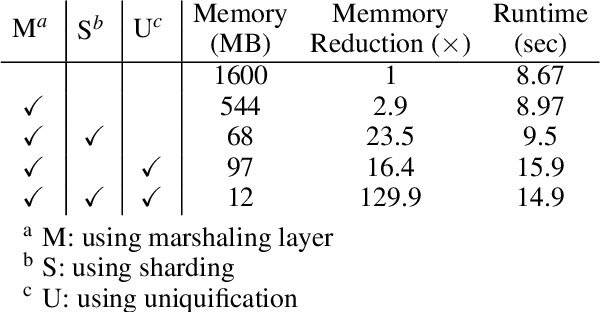
Since Large Language Models or LLMs have demonstrated high-quality performance on many complex language tasks, there is a great interest in bringing these LLMs to mobile devices for faster responses and better privacy protection. However, the size of LLMs (i.e., billions of parameters) requires highly effective compression to fit into storage-limited devices. Among many compression techniques, weight-clustering, a form of non-linear quantization, is one of the leading candidates for LLM compression, and supported by modern smartphones. Yet, its training overhead is prohibitively significant for LLM fine-tuning. Especially, Differentiable KMeans Clustering, or DKM, has shown the state-of-the-art trade-off between compression ratio and accuracy regression, but its large memory complexity makes it nearly impossible to apply to train-time LLM compression. In this paper, we propose a memory-efficient DKM implementation, eDKM powered by novel techniques to reduce the memory footprint of DKM by orders of magnitudes. For a given tensor to be saved on CPU for the backward pass of DKM, we compressed the tensor by applying uniquification and sharding after checking if there is no duplicated tensor previously copied to CPU. Our experimental results demonstrate that \prjname can fine-tune and compress a pretrained LLaMA 7B model from 12.6 GB to 2.5 GB (3bit/weight) with the Alpaca dataset by reducing the train-time memory footprint of a decoder layer by 130$\times$, while delivering good accuracy on broader LLM benchmarks (i.e., 77.7\% for PIQA, 66.1\% for Winograde, and so on).
Exploring the Power of Graph Neural Networks in Solving Linear Optimization Problems
Oct 16, 2023Recently, machine learning, particularly message-passing graph neural networks (MPNNs), has gained traction in enhancing exact optimization algorithms. For example, MPNNs speed up solving mixed-integer optimization problems by imitating computational intensive heuristics like strong branching, which entails solving multiple linear optimization problems (LPs). Despite the empirical success, the reasons behind MPNNs' effectiveness in emulating linear optimization remain largely unclear. Here, we show that MPNNs can simulate standard interior-point methods for LPs, explaining their practical success. Furthermore, we highlight how MPNNs can serve as a lightweight proxy for solving LPs, adapting to a given problem instance distribution. Empirically, we show that MPNNs solve LP relaxations of standard combinatorial optimization problems close to optimality, often surpassing conventional solvers and competing approaches in solving time.
TimeGPT-1
Oct 05, 2023
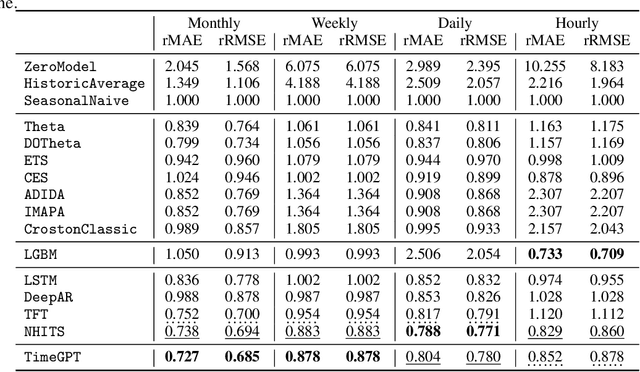
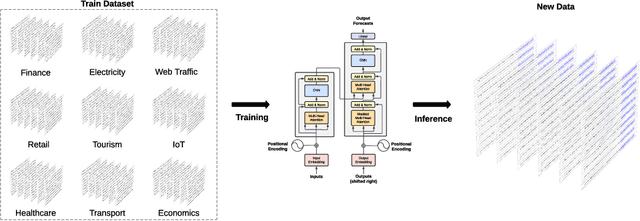
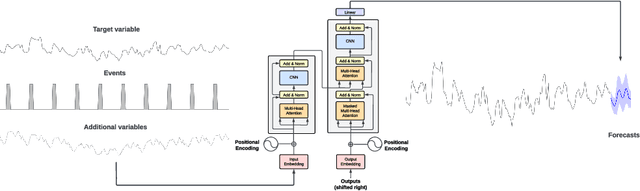
In this paper, we introduce TimeGPT, the first foundation model for time series, capable of generating accurate predictions for diverse datasets not seen during training. We evaluate our pre-trained model against established statistical, machine learning, and deep learning methods, demonstrating that TimeGPT zero-shot inference excels in performance, efficiency, and simplicity. Our study provides compelling evidence that insights from other domains of artificial intelligence can be effectively applied to time series analysis. We conclude that large-scale time series models offer an exciting opportunity to democratize access to precise predictions and reduce uncertainty by leveraging the capabilities of contemporary advancements in deep learning.
PatchCURE: Improving Certifiable Robustness, Model Utility, and Computation Efficiency of Adversarial Patch Defenses
Oct 19, 2023State-of-the-art defenses against adversarial patch attacks can now achieve strong certifiable robustness with a marginal drop in model utility. However, this impressive performance typically comes at the cost of 10-100x more inference-time computation compared to undefended models -- the research community has witnessed an intense three-way trade-off between certifiable robustness, model utility, and computation efficiency. In this paper, we propose a defense framework named PatchCURE to approach this trade-off problem. PatchCURE provides sufficient "knobs" for tuning defense performance and allows us to build a family of defenses: the most robust PatchCURE instance can match the performance of any existing state-of-the-art defense (without efficiency considerations); the most efficient PatchCURE instance has similar inference efficiency as undefended models. Notably, PatchCURE achieves state-of-the-art robustness and utility performance across all different efficiency levels, e.g., 16-23% absolute clean accuracy and certified robust accuracy advantages over prior defenses when requiring computation efficiency to be close to undefended models. The family of PatchCURE defenses enables us to flexibly choose appropriate defenses to satisfy given computation and/or utility constraints in practice.
Network-Aware AutoML Framework for Software-Defined Sensor Networks
Oct 19, 2023As the current detection solutions of distributed denial of service attacks (DDoS) need additional infrastructures to handle high aggregate data rates, they are not suitable for sensor networks or the Internet of Things. Besides, the security architecture of software-defined sensor networks needs to pay attention to the vulnerabilities of both software-defined networks and sensor networks. In this paper, we propose a network-aware automated machine learning (AutoML) framework which detects DDoS attacks in software-defined sensor networks. Our framework selects an ideal machine learning algorithm to detect DDoS attacks in network-constrained environments, using metrics such as variable traffic load, heterogeneous traffic rate, and detection time while preventing over-fitting. Our contributions are two-fold: (i) we first investigate the trade-off between the efficiency of ML algorithms and network/traffic state in the scope of DDoS detection. (ii) we design and implement a software architecture containing open-source network tools, with the deployment of multiple ML algorithms. Lastly, we show that under the denial of service attacks, our framework ensures the traffic packets are still delivered within the network with additional delays.
Unit Commitment Predictor With a Performance Guarantee: A Support Vector Machine Classifier
Oct 07, 2023The system operators usually need to solve large-scale unit commitment problems within limited time frame for computation. This paper provides a pragmatic solution, showing how by learning and predicting the on/off commitment decisions of conventional units, there is a potential for system operators to warm start their solver and speed up their computation significantly. For the prediction, we train linear and kernelized support vector machine classifiers, providing an out-of-sample performance guarantee if properly regularized, converting to distributionally robust classifiers. For the unit commitment problem, we solve a mixed-integer second-order cone problem. Our results based on the IEEE 6-bus and 118-bus test systems show that the kernelized SVM with proper regularization outperforms other classifiers, reducing the computational time by a factor of 1.7. In addition, if there is a tight computational limit, while the unit commitment problem without warm start is far away from the optimal solution, its warmly started version can be solved to optimality within the time limit.
Metrics for popularity bias in dynamic recommender systems
Oct 12, 2023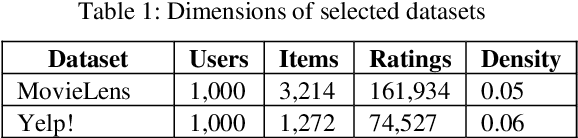
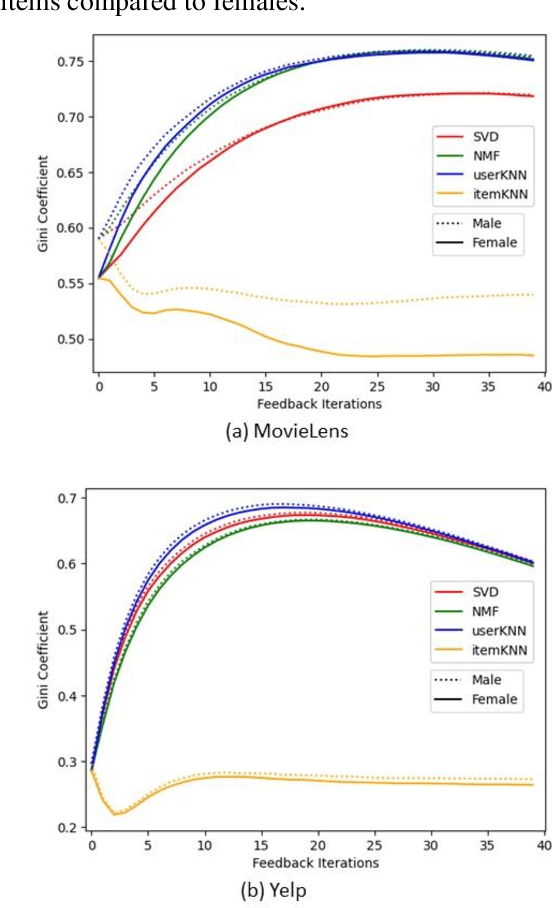
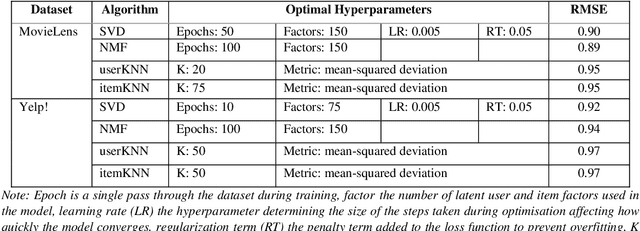
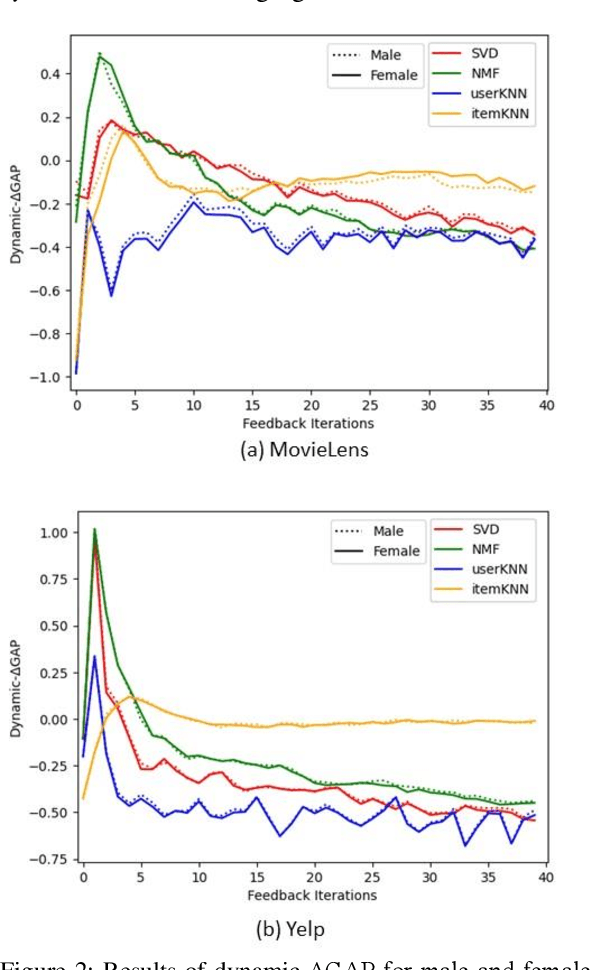
Albeit the widespread application of recommender systems (RecSys) in our daily lives, rather limited research has been done on quantifying unfairness and biases present in such systems. Prior work largely focuses on determining whether a RecSys is discriminating or not but does not compute the amount of bias present in these systems. Biased recommendations may lead to decisions that can potentially have adverse effects on individuals, sensitive user groups, and society. Hence, it is important to quantify these biases for fair and safe commercial applications of these systems. This paper focuses on quantifying popularity bias that stems directly from the output of RecSys models, leading to over recommendation of popular items that are likely to be misaligned with user preferences. Four metrics to quantify popularity bias in RescSys over time in dynamic setting across different sensitive user groups have been proposed. These metrics have been demonstrated for four collaborative filtering based RecSys algorithms trained on two commonly used benchmark datasets in the literature. Results obtained show that the metrics proposed provide a comprehensive understanding of growing disparities in treatment between sensitive groups over time when used conjointly.