 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Generalizing to Unseen Domains in Diabetic Retinopathy Classification
Oct 27, 2023
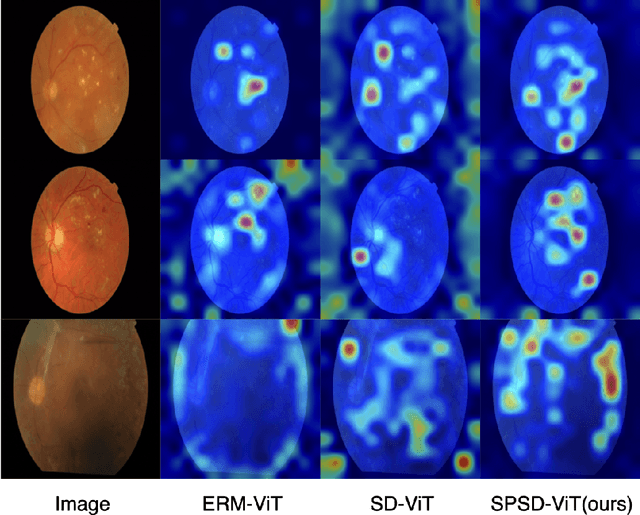
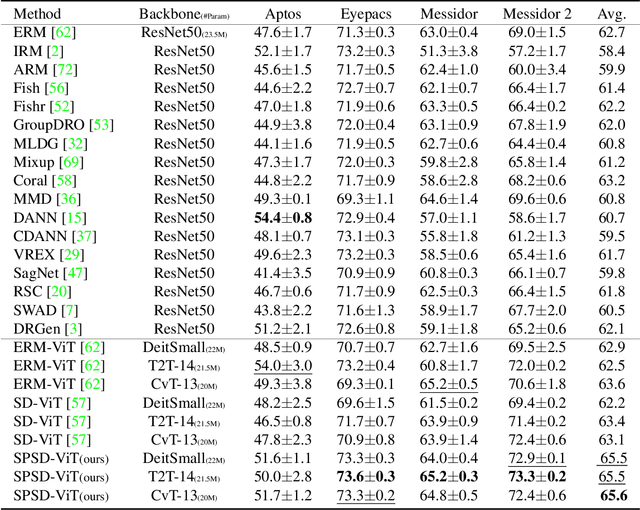
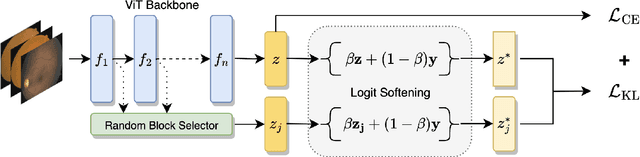
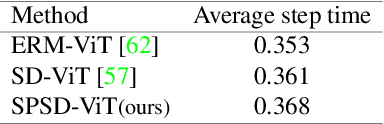
Diabetic retinopathy (DR) is caused by long-standing diabetes and is among the fifth leading cause for visual impairments. The process of early diagnosis and treatments could be helpful in curing the disease, however, the detection procedure is rather challenging and mostly tedious. Therefore, automated diabetic retinopathy classification using deep learning techniques has gained interest in the medical imaging community. Akin to several other real-world applications of deep learning, the typical assumption of i.i.d data is also violated in DR classification that relies on deep learning. Therefore, developing DR classification methods robust to unseen distributions is of great value. In this paper, we study the problem of generalizing a model to unseen distributions or domains (a.k.a domain generalization) in DR classification. To this end, we propose a simple and effective domain generalization (DG) approach that achieves self-distillation in vision transformers (ViT) via a novel prediction softening mechanism. This prediction softening is an adaptive convex combination one-hot labels with the model's own knowledge. We perform extensive experiments on challenging open-source DR classification datasets under both multi-source and single-source DG settings with three different ViT backbones to establish the efficacy and applicability of our approach against competing methods. For the first time, we report the performance of several state-of-the-art DG methods on open-source DR classification datasets after conducting thorough experiments. Finally, our method is also capable of delivering improved calibration performance than other methods, showing its suitability for safety-critical applications, including healthcare. We hope that our contributions would investigate more DG research across the medical imaging community.
Hybrid Optical Turbulence Models Using Machine Learning and Local Measurements
Oct 27, 2023Accurate prediction of atmospheric optical turbulence in localized environments is essential for estimating the performance of free-space optical systems. Macro-meteorological models developed to predict turbulent effects in one environment may fail when applied in new environments. However, existing macro-meteorological models are expected to offer some predictive power. Building a new model from locally-measured macro-meteorology and scintillometer readings can require significant time and resources, as well as a large number of observations. These challenges motivate the development of a machine-learning informed hybrid model framework. By combining some baseline macro-meteorological model with local observations, hybrid models were trained to improve upon the predictive power of each baseline model. Comparisons between the performance of the hybrid models, the selected baseline macro-meteorological models, and machine-learning models trained only on local observations highlight potential use cases for the hybrid model framework when local data is expensive to collect. Both the hybrid and data-only models were trained using the Gradient Boosted Decision Tree (GBDT) architecture with a variable number of in-situ meteorological observations. The hybrid and data-only models were found to outperform three baseline macro-meteorological models, even for low numbers of observations, in some cases as little as one day. For the first baseline macro-meteorological model investigated, the hybrid model achieves an estimated 29% reduction in mean absolute error (MAE) using only one days-equivalent of observation, growing to 41% after only two days, and 68% after 180 days-equivalent training data. The number of days-equivalent training data required is potentially indicative of the seasonal variation in the local microclimate and its propagation environment.
* 15 pages, 8 figures
DM-VTON: Distilled Mobile Real-time Virtual Try-On
Aug 26, 2023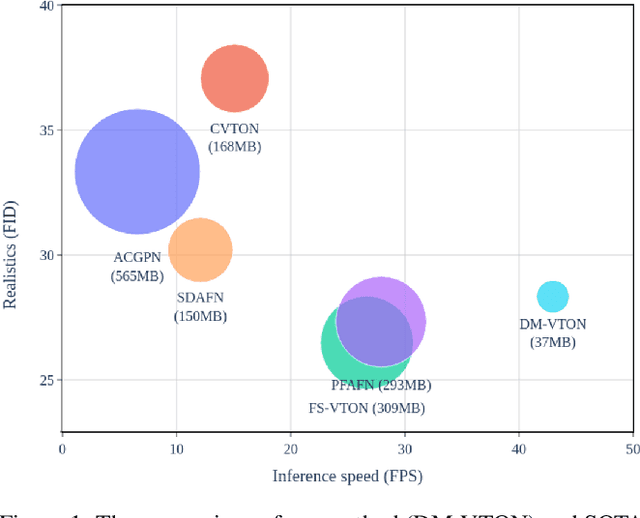

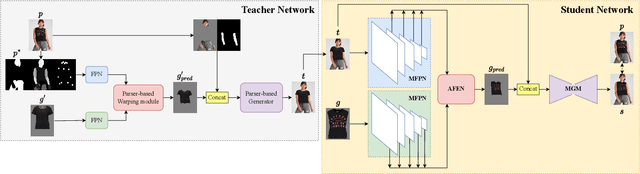
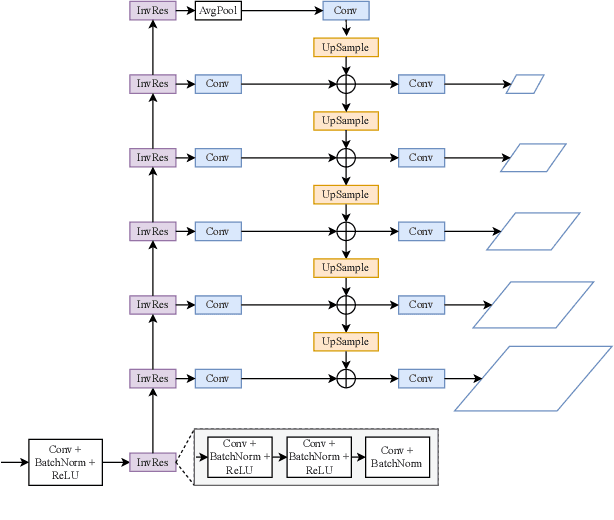
The fashion e-commerce industry has witnessed significant growth in recent years, prompting exploring image-based virtual try-on techniques to incorporate Augmented Reality (AR) experiences into online shopping platforms. However, existing research has primarily overlooked a crucial aspect - the runtime of the underlying machine-learning model. While existing methods prioritize enhancing output quality, they often disregard the execution time, which restricts their applications on a limited range of devices. To address this gap, we propose Distilled Mobile Real-time Virtual Try-On (DM-VTON), a novel virtual try-on framework designed to achieve simplicity and efficiency. Our approach is based on a knowledge distillation scheme that leverages a strong Teacher network as supervision to guide a Student network without relying on human parsing. Notably, we introduce an efficient Mobile Generative Module within the Student network, significantly reducing the runtime while ensuring high-quality output. Additionally, we propose Virtual Try-on-guided Pose for Data Synthesis to address the limited pose variation observed in training images. Experimental results show that the proposed method can achieve 40 frames per second on a single Nvidia Tesla T4 GPU and only take up 37 MB of memory while producing almost the same output quality as other state-of-the-art methods. DM-VTON stands poised to facilitate the advancement of real-time AR applications, in addition to the generation of lifelike attired human figures tailored for diverse specialized training tasks. https://sites.google.com/view/ltnghia/research/DMVTON
Single channel speech enhancement by colored spectrograms
Oct 26, 2023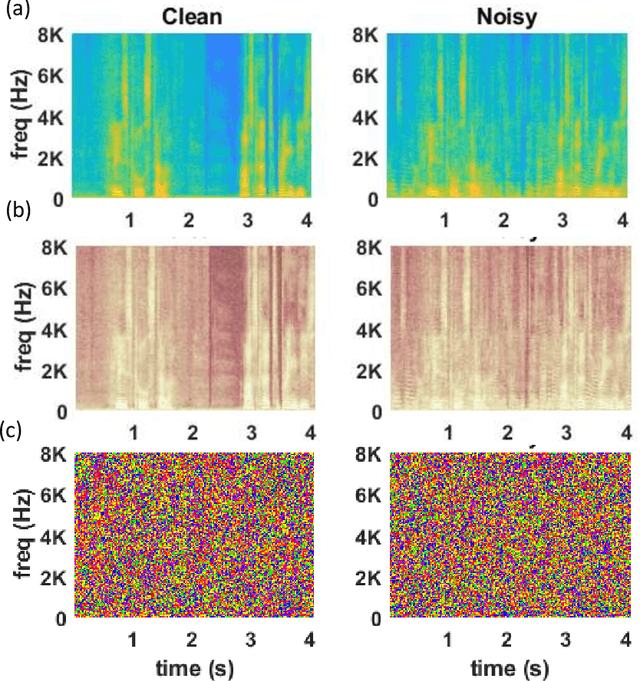
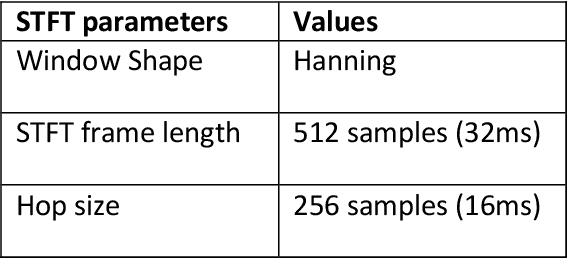
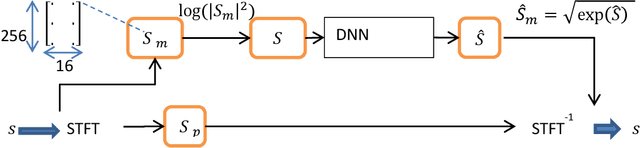
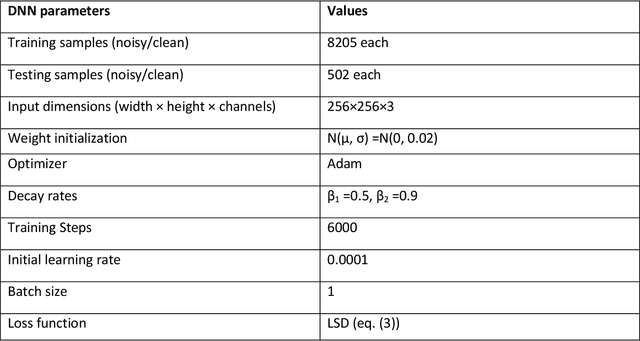
Speech enhancement concerns the processes required to remove unwanted background sounds from the target speech to improve its quality and intelligibility. In this paper, a novel approach for single-channel speech enhancement is presented, using colored spectrograms. We propose the use of a deep neural network (DNN) architecture adapted from the pix2pix generative adversarial network (GAN) and train it over colored spectrograms of speech to denoise them. After denoising, the colors of spectrograms are translated to magnitudes of short-time Fourier transform (STFT) using a shallow regression neural network. These estimated STFT magnitudes are later combined with the noisy phases to obtain an enhanced speech. The results show an improvement of almost 0.84 points in the perceptual evaluation of speech quality (PESQ) and 1% in the short-term objective intelligibility (STOI) over the unprocessed noisy data. The gain in quality and intelligibility over the unprocessed signal is almost equal to the gain achieved by the baseline methods used for comparison with the proposed model, but at a much reduced computational cost. The proposed solution offers a comparative PESQ score at almost 10 times reduced computational cost than a similar baseline model that has generated the highest PESQ score trained on grayscaled spectrograms, while it provides only a 1% deficit in STOI at 28 times reduced computational cost when compared to another baseline system based on convolutional neural network-GAN (CNN-GAN) that produces the most intelligible speech.
PockEngine: Sparse and Efficient Fine-tuning in a Pocket
Oct 26, 2023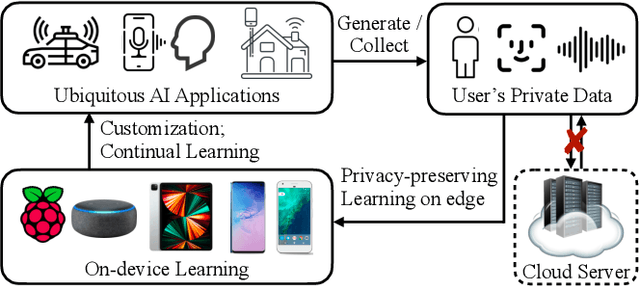

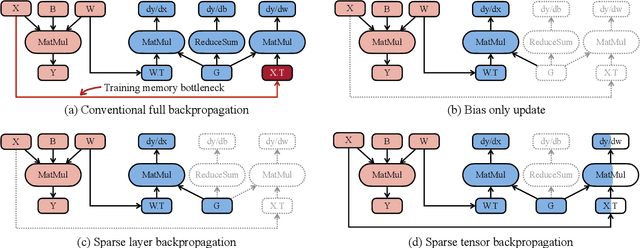
On-device learning and efficient fine-tuning enable continuous and privacy-preserving customization (e.g., locally fine-tuning large language models on personalized data). However, existing training frameworks are designed for cloud servers with powerful accelerators (e.g., GPUs, TPUs) and lack the optimizations for learning on the edge, which faces challenges of resource limitations and edge hardware diversity. We introduce PockEngine: a tiny, sparse and efficient engine to enable fine-tuning on various edge devices. PockEngine supports sparse backpropagation: it prunes the backward graph and sparsely updates the model with measured memory saving and latency reduction while maintaining the model quality. Secondly, PockEngine is compilation first: the entire training graph (including forward, backward and optimization steps) is derived at compile-time, which reduces the runtime overhead and brings opportunities for graph transformations. PockEngine also integrates a rich set of training graph optimizations, thus can further accelerate the training cost, including operator reordering and backend switching. PockEngine supports diverse applications, frontends and hardware backends: it flexibly compiles and tunes models defined in PyTorch/TensorFlow/Jax and deploys binaries to mobile CPU/GPU/DSPs. We evaluated PockEngine on both vision models and large language models. PockEngine achieves up to 15 $\times$ speedup over off-the-shelf TensorFlow (Raspberry Pi), 5.6 $\times$ memory saving back-propagation (Jetson AGX Orin). Remarkably, PockEngine enables fine-tuning LLaMav2-7B on NVIDIA Jetson AGX Orin at 550 tokens/s, 7.9$\times$ faster than the PyTorch.
Deep machine learning for meteor monitoring: advances with transfer learning and gradient-weighted class activation mapping
Oct 26, 2023
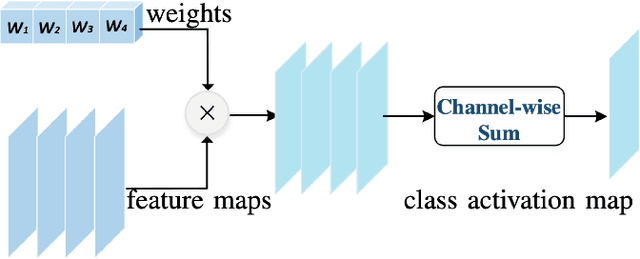
In recent decades, the use of optical detection systems for meteor studies has increased dramatically, resulting in huge amounts of data being analyzed. Automated meteor detection tools are essential for studying the continuous meteoroid incoming flux, recovering fresh meteorites, and achieving a better understanding of our Solar System. Concerning meteor detection, distinguishing false positives between meteor and non-meteor images has traditionally been performed by hand, which is significantly time-consuming. To address this issue, we developed a fully automated pipeline that uses Convolutional Neural Networks (CNNs) to classify candidate meteor detections. Our new method is able to detect meteors even in images that contain static elements such as clouds, the Moon, and buildings. To accurately locate the meteor within each frame, we employ the Gradient-weighted Class Activation Mapping (Grad-CAM) technique. This method facilitates the identification of the region of interest by multiplying the activations from the last convolutional layer with the average of the gradients across the feature map of that layer. By combining these findings with the activation map derived from the first convolutional layer, we effectively pinpoint the most probable pixel location of the meteor. We trained and evaluated our model on a large dataset collected by the Spanish Meteor Network (SPMN) and achieved a precision of 98\%. Our new methodology presented here has the potential to reduce the workload of meteor scientists and station operators and improve the accuracy of meteor tracking and classification.
Model-Based Runtime Monitoring with Interactive Imitation Learning
Oct 26, 2023
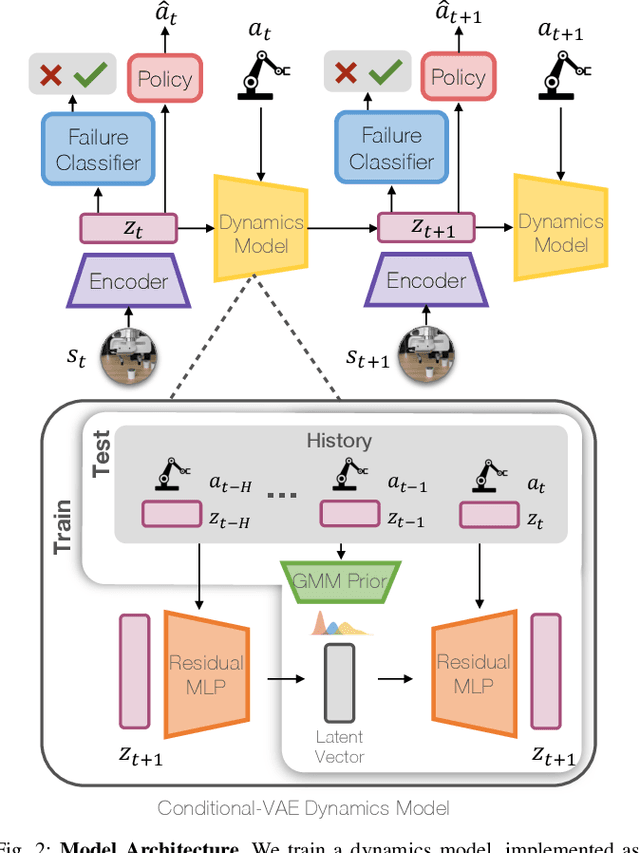
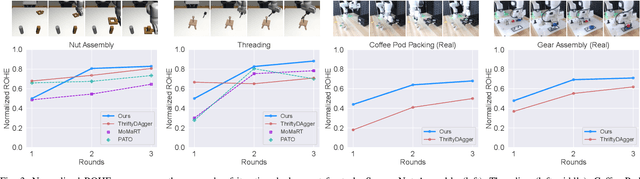
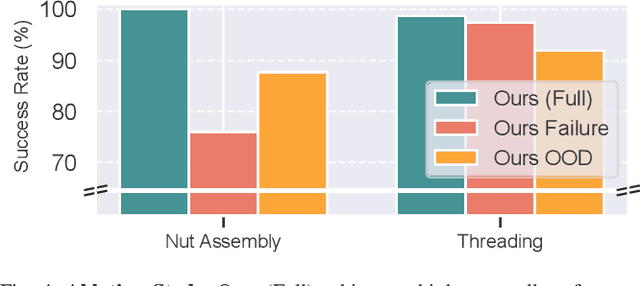
Robot learning methods have recently made great strides, but generalization and robustness challenges still hinder their widespread deployment. Failing to detect and address potential failures renders state-of-the-art learning systems not combat-ready for high-stakes tasks. Recent advances in interactive imitation learning have presented a promising framework for human-robot teaming, enabling the robots to operate safely and continually improve their performances over long-term deployments. Nonetheless, existing methods typically require constant human supervision and preemptive feedback, limiting their practicality in realistic domains. This work aims to endow a robot with the ability to monitor and detect errors during task execution. We introduce a model-based runtime monitoring algorithm that learns from deployment data to detect system anomalies and anticipate failures. Unlike prior work that cannot foresee future failures or requires failure experiences for training, our method learns a latent-space dynamics model and a failure classifier, enabling our method to simulate future action outcomes and detect out-of-distribution and high-risk states preemptively. We train our method within an interactive imitation learning framework, where it continually updates the model from the experiences of the human-robot team collected using trustworthy deployments. Consequently, our method reduces the human workload needed over time while ensuring reliable task execution. Our method outperforms the baselines across system-level and unit-test metrics, with 23% and 40% higher success rates in simulation and on physical hardware, respectively. More information at https://ut-austin-rpl.github.io/sirius-runtime-monitor/
An Automated Machine Learning Approach for Detecting Anomalous Peak Patterns in Time Series Data from a Research Watershed in the Northeastern United States Critical Zone
Sep 14, 2023This paper presents an automated machine learning framework designed to assist hydrologists in detecting anomalies in time series data generated by sensors in a research watershed in the northeastern United States critical zone. The framework specifically focuses on identifying peak-pattern anomalies, which may arise from sensor malfunctions or natural phenomena. However, the use of classification methods for anomaly detection poses challenges, such as the requirement for labeled data as ground truth and the selection of the most suitable deep learning model for the given task and dataset. To address these challenges, our framework generates labeled datasets by injecting synthetic peak patterns into synthetically generated time series data and incorporates an automated hyperparameter optimization mechanism. This mechanism generates an optimized model instance with the best architectural and training parameters from a pool of five selected models, namely Temporal Convolutional Network (TCN), InceptionTime, MiniRocket, Residual Networks (ResNet), and Long Short-Term Memory (LSTM). The selection is based on the user's preferences regarding anomaly detection accuracy and computational cost. The framework employs Time-series Generative Adversarial Networks (TimeGAN) as the synthetic dataset generator. The generated model instances are evaluated using a combination of accuracy and computational cost metrics, including training time and memory, during the anomaly detection process. Performance evaluation of the framework was conducted using a dataset from a watershed, demonstrating consistent selection of the most fitting model instance that satisfies the user's preferences.
Experimental Results of Underwater Sound Speed Profile Inversion by Few-shot Multi-task Learning
Oct 18, 2023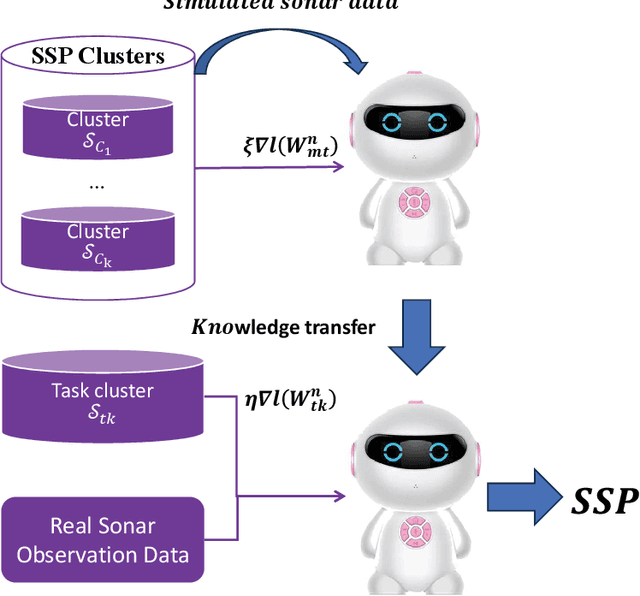
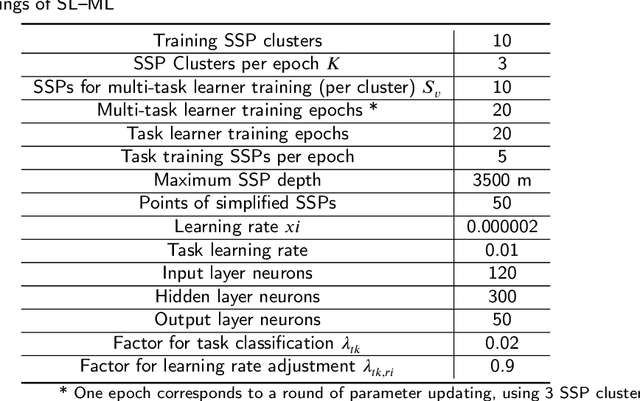
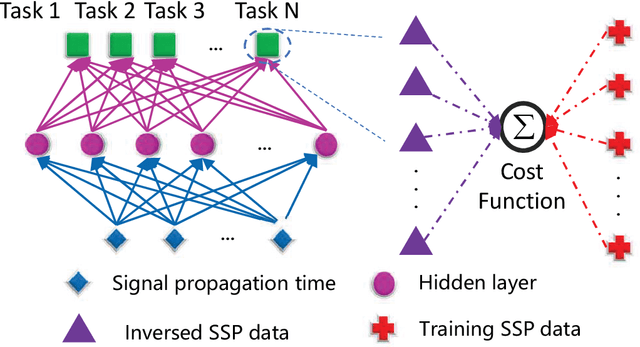
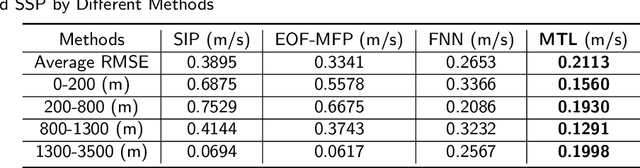
Underwater Sound Speed Profile (SSP) distribution has great influence on the propagation mode of acoustic signal, thus the fast and accurate estimation of SSP is of great importance in building underwater observation systems. The state-of-the-art SSP inversion methods include frameworks of matched field processing (MFP), compressive sensing (CS), and feedforeward neural networks (FNN), among which the FNN shows better real-time performance while maintain the same level of accuracy. However, the training of FNN needs quite a lot historical SSP samples, which is diffcult to be satisfied in many ocean areas. This situation is called few-shot learning. To tackle this issue, we propose a multi-task learning (MTL) model with partial parameter sharing among different traning tasks. By MTL, common features could be extracted, thus accelerating the learning process on given tasks, and reducing the demand for reference samples, so as to enhance the generalization ability in few-shot learning. To verify the feasibility and effectiveness of MTL, a deep-ocean experiment was held in April 2023 at the South China Sea. Results shows that MTL outperforms the state-of-the-art methods in terms of accuracy for SSP inversion, while inherits the real-time advantage of FNN during the inversion stage.
4 and 7-bit Labeling for Projective and Non-Projective Dependency Trees
Oct 22, 2023We introduce an encoding for parsing as sequence labeling that can represent any projective dependency tree as a sequence of 4-bit labels, one per word. The bits in each word's label represent (1) whether it is a right or left dependent, (2) whether it is the outermost (left/right) dependent of its parent, (3) whether it has any left children and (4) whether it has any right children. We show that this provides an injective mapping from trees to labels that can be encoded and decoded in linear time. We then define a 7-bit extension that represents an extra plane of arcs, extending the coverage to almost full non-projectivity (over 99.9% empirical arc coverage). Results on a set of diverse treebanks show that our 7-bit encoding obtains substantial accuracy gains over the previously best-performing sequence labeling encodings.