 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAceGRPO: Adaptive Curriculum Enhanced Group Relative Policy Optimization for Autonomous Machine Learning Engineering
Feb 08, 2026Autonomous Machine Learning Engineering (MLE) requires agents to perform sustained, iterative optimization over long horizons. While recent LLM-based agents show promise, current prompt-based agents for MLE suffer from behavioral stagnation due to frozen parameters. Although Reinforcement Learning (RL) offers a remedy, applying it to MLE is hindered by prohibitive execution latency and inefficient data selection. Recognizing these challenges, we propose AceGRPO with two core components: (1) Evolving Data Buffer that continuously repurposes execution traces into reusable training tasks, and (2) Adaptive Sampling guided by a Learnability Potential function, which dynamically prioritizes tasks at the agent's learning frontier to maximize learning efficiency. Leveraging AceGRPO, our trained Ace-30B model achieves a 100% valid submission rate on MLE-Bench-Lite, approaches the performance of proprietary frontier models, and outperforms larger open-source baselines (e.g., DeepSeek-V3.2), demonstrating robust capability for sustained iterative optimization. Code is available at https://github.com/yuzhu-cai/AceGRPO.
From Self-Evolving Synthetic Data to Verifiable-Reward RL: Post-Training Multi-turn Interactive Tool-Using Agents
Jan 30, 2026Interactive tool-using agents must solve real-world tasks via multi-turn interaction with both humans and external environments, requiring dialogue state tracking, multi-step tool execution, while following complex instructions. Post-training such agents is challenging because synthesis for high-quality multi-turn tool-use data is difficult to scale, and reinforcement learning (RL) could face noisy signals caused by user simulation, leading to degraded training efficiency. We propose a unified framework that combines a self-evolving data agent with verifier-based RL. Our system, EigenData, is a hierarchical multi-agent engine that synthesizes tool-grounded dialogues together with executable per-instance checkers, and improves generation reliability via closed-loop self-evolving process that updates prompts and workflow. Building on the synthetic data, we develop an RL recipe that first fine-tunes the user model and then applies GRPO-style training with trajectory-level group-relative advantages and dynamic filtering, yielding consistent improvements beyond SFT. Evaluated on tau^2-bench, our best model reaches 73.0% pass^1 on Airline and 98.3% pass^1 on Telecom, matching or exceeding frontier models. Overall, our results suggest a scalable pathway for bootstrapping complex tool-using behaviors without expensive human annotation.
Toward Ultra-Long-Horizon Agentic Science: Cognitive Accumulation for Machine Learning Engineering
Jan 15, 2026The advancement of artificial intelligence toward agentic science is currently bottlenecked by the challenge of ultra-long-horizon autonomy, the ability to sustain strategic coherence and iterative correction over experimental cycles spanning days or weeks. While Large Language Models (LLMs) have demonstrated prowess in short-horizon reasoning, they are easily overwhelmed by execution details in the high-dimensional, delayed-feedback environments of real-world research, failing to consolidate sparse feedback into coherent long-term guidance. Here, we present ML-Master 2.0, an autonomous agent that masters ultra-long-horizon machine learning engineering (MLE) which is a representative microcosm of scientific discovery. By reframing context management as a process of cognitive accumulation, our approach introduces Hierarchical Cognitive Caching (HCC), a multi-tiered architecture inspired by computer systems that enables the structural differentiation of experience over time. By dynamically distilling transient execution traces into stable knowledge and cross-task wisdom, HCC allows agents to decouple immediate execution from long-term experimental strategy, effectively overcoming the scaling limits of static context windows. In evaluations on OpenAI's MLE-Bench under 24-hour budgets, ML-Master 2.0 achieves a state-of-the-art medal rate of 56.44%. Our findings demonstrate that ultra-long-horizon autonomy provides a scalable blueprint for AI capable of autonomous exploration beyond human-precedent complexities.
Nonlinear action prediction models reveal multi-timescale locomotor control
Mar 20, 2025



Modeling movement in real-world tasks is a fundamental scientific goal. However, it is unclear whether existing models and their assumptions, overwhelmingly tested in laboratory-constrained settings, generalize to the real world. For example, data-driven models of foot placement control -- a crucial action for stable locomotion -- assume linear and single timescale mappings. We develop nonlinear foot placement prediction models, finding that neural network architectures with flexible input history-dependence like GRU and Transformer perform best across multiple contexts (walking and running, treadmill and overground, varying terrains) and input modalities (multiple body states, gaze), outperforming traditional models. These models reveal context- and modality-dependent timescales: there is more reliance on fast-timescale predictions in complex terrain, gaze predictions precede body state predictions, and full-body state predictions precede center-of-mass-relevant predictions. Thus, nonlinear action prediction models provide quantifiable insights into real-world motor control and can be extended to other actions, contexts, and populations.
Tiny Machine Learning: Progress and Futures
Mar 29, 2024



Tiny Machine Learning (TinyML) is a new frontier of machine learning. By squeezing deep learning models into billions of IoT devices and microcontrollers (MCUs), we expand the scope of AI applications and enable ubiquitous intelligence. However, TinyML is challenging due to hardware constraints: the tiny memory resource makes it difficult to hold deep learning models designed for cloud and mobile platforms. There is also limited compiler and inference engine support for bare-metal devices. Therefore, we need to co-design the algorithm and system stack to enable TinyML. In this review, we will first discuss the definition, challenges, and applications of TinyML. We then survey the recent progress in TinyML and deep learning on MCUs. Next, we will introduce MCUNet, showing how we can achieve ImageNet-scale AI applications on IoT devices with system-algorithm co-design. We will further extend the solution from inference to training and introduce tiny on-device training techniques. Finally, we present future directions in this area. Today's large model might be tomorrow's tiny model. The scope of TinyML should evolve and adapt over time.
* arXiv admin note: text overlap with arXiv:2206.15472
PockEngine: Sparse and Efficient Fine-tuning in a Pocket
Oct 26, 2023



On-device learning and efficient fine-tuning enable continuous and privacy-preserving customization (e.g., locally fine-tuning large language models on personalized data). However, existing training frameworks are designed for cloud servers with powerful accelerators (e.g., GPUs, TPUs) and lack the optimizations for learning on the edge, which faces challenges of resource limitations and edge hardware diversity. We introduce PockEngine: a tiny, sparse and efficient engine to enable fine-tuning on various edge devices. PockEngine supports sparse backpropagation: it prunes the backward graph and sparsely updates the model with measured memory saving and latency reduction while maintaining the model quality. Secondly, PockEngine is compilation first: the entire training graph (including forward, backward and optimization steps) is derived at compile-time, which reduces the runtime overhead and brings opportunities for graph transformations. PockEngine also integrates a rich set of training graph optimizations, thus can further accelerate the training cost, including operator reordering and backend switching. PockEngine supports diverse applications, frontends and hardware backends: it flexibly compiles and tunes models defined in PyTorch/TensorFlow/Jax and deploys binaries to mobile CPU/GPU/DSPs. We evaluated PockEngine on both vision models and large language models. PockEngine achieves up to 15 $\times$ speedup over off-the-shelf TensorFlow (Raspberry Pi), 5.6 $\times$ memory saving back-propagation (Jetson AGX Orin). Remarkably, PockEngine enables fine-tuning LLaMav2-7B on NVIDIA Jetson AGX Orin at 550 tokens/s, 7.9$\times$ faster than the PyTorch.
Detecting Label Errors in Token Classification Data
Oct 08, 2022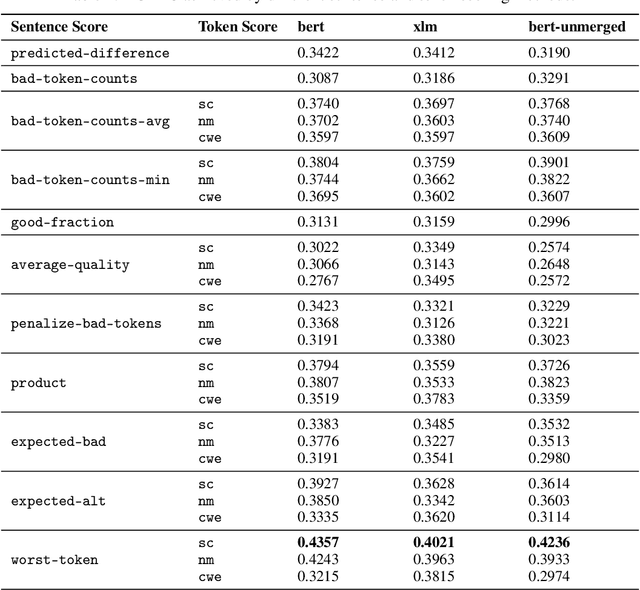
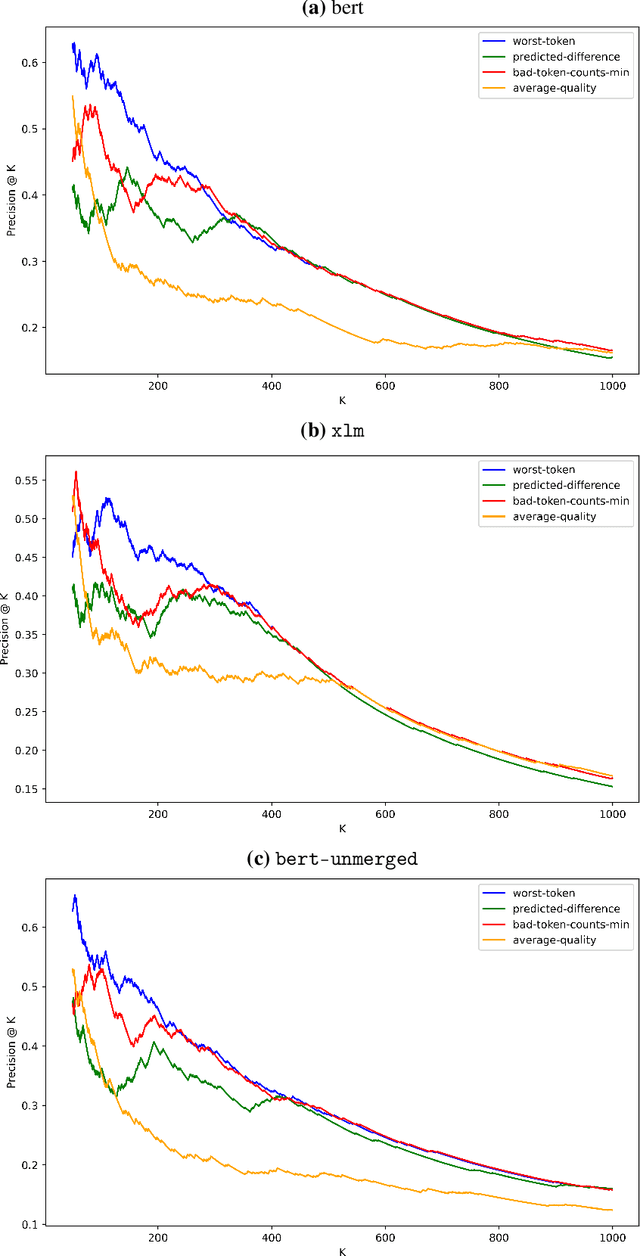
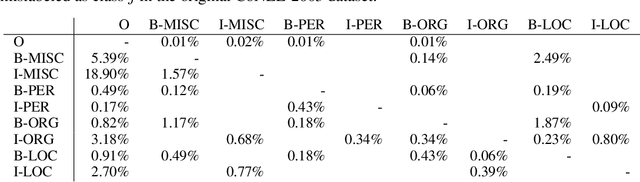
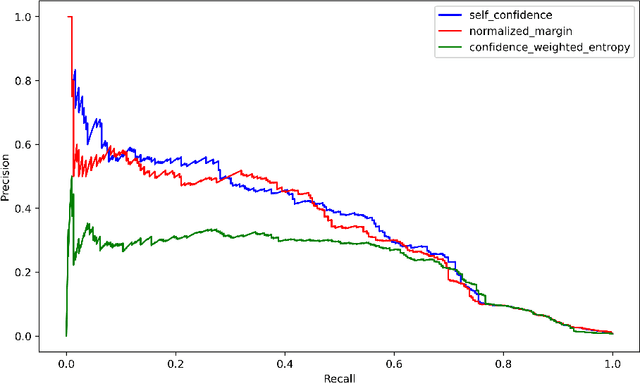
Mislabeled examples are a common issue in real-world data, particularly for tasks like token classification where many labels must be chosen on a fine-grained basis. Here we consider the task of finding sentences that contain label errors in token classification datasets. We study 11 different straightforward methods that score tokens/sentences based on the predicted class probabilities output by a (any) token classification model (trained via any procedure). In precision-recall evaluations based on real-world label errors in entity recognition data from CoNLL-2003, we identify a simple and effective method that consistently detects those sentences containing label errors when applied with different token classification models.
On-Device Training Under 256KB Memory
Jul 14, 2022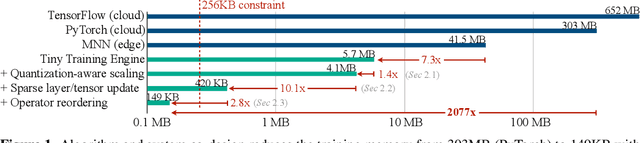
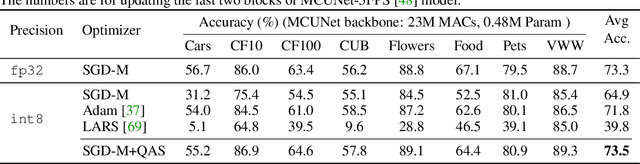
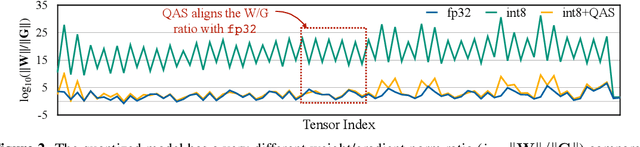
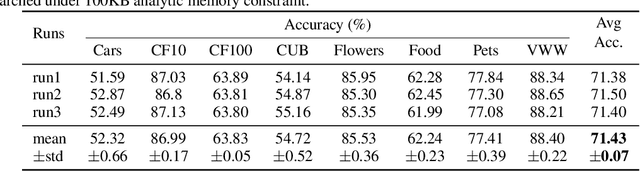
On-device training enables the model to adapt to new data collected from the sensors by fine-tuning a pre-trained model. However, the training memory consumption is prohibitive for IoT devices that have tiny memory resources. We propose an algorithm-system co-design framework to make on-device training possible with only 256KB of memory. On-device training faces two unique challenges: (1) the quantized graphs of neural networks are hard to optimize due to mixed bit-precision and the lack of normalization; (2) the limited hardware resource (memory and computation) does not allow full backward computation. To cope with the optimization difficulty, we propose Quantization-Aware Scaling to calibrate the gradient scales and stabilize quantized training. To reduce the memory footprint, we propose Sparse Update to skip the gradient computation of less important layers and sub-tensors. The algorithm innovation is implemented by a lightweight training system, Tiny Training Engine, which prunes the backward computation graph to support sparse updates and offloads the runtime auto-differentiation to compile time. Our framework is the first practical solution for on-device transfer learning of visual recognition on tiny IoT devices (e.g., a microcontroller with only 256KB SRAM), using less than 1/100 of the memory of existing frameworks while matching the accuracy of cloud training+edge deployment for the tinyML application VWW. Our study enables IoT devices to not only perform inference but also continuously adapt to new data for on-device lifelong learning.