 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Low-latency Visual Previews of Large Synchrotron Micro-CT Datasets
Nov 25, 2023
The unprecedented rate at which synchrotron radiation facilities are producing micro-computed (micro-CT) datasets has resulted in an overwhelming amount of data that scientists struggle to browse and interact with in real-time. Thousands of arthropods are scanned into micro-CT within the NOVA project, producing a large collection of gigabyte-sized datasets. In this work, we present methods to reduce the size of this data, scaling it from gigabytes to megabytes, enabling the micro-CT dataset to be delivered in real-time. In addition, arthropods can be identified by scientists even after implementing data reduction methodologies. Our initial step is to devise three distinct visual previews that comply with the best practices of data exploration. Subsequently, each visual preview warrants its own design consideration, thereby necessitating an individual data processing pipeline for each. We aim to present data reduction algorithms applied across the data processing pipelines. Particularly, we reduce size by using the multi-resolution slicemaps, the server-side rendering, and the histogram filtering approaches. In the evaluation, we examine the disparities of each method to identify the most favorable arrangement for our operation, which can then be adjusted for other experiments that have comparable necessities. Our demonstration proved that reducing the dataset size to the megabyte range is achievable without compromising the arthropod's geometry information.
Revisiting Quantum Algorithms for Linear Regressions: Quadratic Speedups without Data-Dependent Parameters
Nov 24, 2023Linear regression is one of the most fundamental linear algebra problems. Given a dense matrix $A \in \mathbb{R}^{n \times d}$ and a vector $b$, the goal is to find $x'$ such that $ \| Ax' - b \|_2^2 \leq (1+\epsilon) \min_{x} \| A x - b \|_2^2 $. The best classical algorithm takes $O(nd) + \mathrm{poly}(d/\epsilon)$ time [Clarkson and Woodruff STOC 2013, Nelson and Nguyen FOCS 2013]. On the other hand, quantum linear regression algorithms can achieve exponential quantum speedups, as shown in [Wang Phys. Rev. A 96, 012335, Kerenidis and Prakash ITCS 2017, Chakraborty, Gily{\'e}n and Jeffery ICALP 2019]. However, the running times of these algorithms depend on some quantum linear algebra-related parameters, such as $\kappa(A)$, the condition number of $A$. In this work, we develop a quantum algorithm that runs in $\widetilde{O}(\epsilon^{-1}\sqrt{n}d^{1.5}) + \mathrm{poly}(d/\epsilon)$ time. It provides a quadratic quantum speedup in $n$ over the classical lower bound without any dependence on data-dependent parameters. In addition, we also show our result can be generalized to multiple regression and ridge linear regression.
AdaDiff: Adaptive Step Selection for Fast Diffusion
Nov 24, 2023Diffusion models, as a type of generative models, have achieved impressive results in generating images and videos conditioned on textual conditions. However, the generation process of diffusion models involves denoising for dozens of steps to produce photorealistic images/videos, which is computationally expensive. Unlike previous methods that design ``one-size-fits-all'' approaches for speed up, we argue denoising steps should be sample-specific conditioned on the richness of input texts. To this end, we introduce AdaDiff, a lightweight framework designed to learn instance-specific step usage policies, which are then used by the diffusion model for generation. AdaDiff is optimized using a policy gradient method to maximize a carefully designed reward function, balancing inference time and generation quality. We conduct experiments on three image generation and two video generation benchmarks and demonstrate that our approach achieves similar results in terms of visual quality compared to the baseline using a fixed 50 denoising steps while reducing inference time by at least 33%, going as high as 40%. Furthermore, our qualitative analysis shows that our method allocates more steps to more informative text conditions and fewer steps to simpler text conditions.
Thompson sampling for zero-inflated count outcomes with an application to the Drink Less mobile health study
Nov 24, 2023Mobile health (mHealth) technologies aim to improve distal outcomes, such as clinical conditions, by optimizing proximal outcomes through just-in-time adaptive interventions. Contextual bandits provide a suitable framework for customizing such interventions according to individual time-varying contexts, intending to maximize cumulative proximal outcomes. However, unique challenges such as modeling count outcomes within bandit frameworks have hindered the widespread application of contextual bandits to mHealth studies. The current work addresses this challenge by leveraging count data models into online decision-making approaches. Specifically, we combine four common offline count data models (Poisson, negative binomial, zero-inflated Poisson, and zero-inflated negative binomial regressions) with Thompson sampling, a popular contextual bandit algorithm. The proposed algorithms are motivated by and evaluated on a real dataset from the Drink Less trial, where they are shown to improve user engagement with the mHealth system. The proposed methods are further evaluated on simulated data, achieving improvement in maximizing cumulative proximal outcomes over existing algorithms. Theoretical results on regret bounds are also derived. A user-friendly R package countts that implements the proposed methods for assessing contextual bandit algorithms is made publicly available at https://cran.r-project.org/web/packages/countts.
Towards Running Time Analysis of Interactive Multi-objective Evolutionary Algorithms
Oct 15, 2023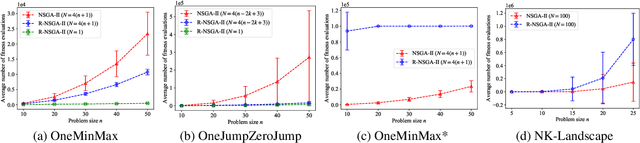
Evolutionary algorithms (EAs) are widely used for multi-objective optimization due to their population-based nature. Traditional multi-objective EAs (MOEAs) generate a large set of solutions to approximate the Pareto front, leaving a decision maker (DM) with the task of selecting a preferred solution. However, this process can be inefficient and time-consuming, especially when there are many objectives or the subjective preferences of DM is known. To address this issue, interactive MOEAs (iMOEAs) combine decision making into the optimization process, i.e., update the population with the help of the DM. In contrast to their wide applications, there has existed only two pieces of theoretical works on iMOEAs, which only considered interactive variants of the two simple single-objective algorithms, RLS and (1+1)-EA. This paper provides the first running time analysis (the essential theoretical aspect of EAs) for practical iMOEAs. Specifically, we prove that the expected running time of the well-developed interactive NSGA-II (called R-NSGA-II) for solving the OneMinMax and OneJumpZeroJump problems is $O(n \log n)$ and $O(n^k)$, respectively, which are all asymptotically faster than the traditional NSGA-II. Meanwhile, we present a variant of OneMinMax, and prove that R-NSGA-II can be exponentially slower than NSGA-II. These results provide theoretical justification for the effectiveness of iMOEAs while identifying situations where they may fail. Experiments are also conducted to validate the theoretical results.
Adaptive Image Registration: A Hybrid Approach Integrating Deep Learning and Optimization Functions for Enhanced Precision
Nov 27, 2023Image registration has traditionally been done using two distinct approaches: learning based methods, relying on robust deep neural networks, and optimization-based methods, applying complex mathematical transformations to warp images accordingly. Of course, both paradigms offer advantages and disadvantages, and, in this work, we seek to combine their respective strengths into a single streamlined framework, using the outputs of the learning based method as initial parameters for optimization while prioritizing computational power for the image pairs that offer the greatest loss. Our investigations showed that an improvement of 0.3\% in testing when utilizing the best performing state-of-the-art model as the backbone of the framework, while maintaining the same inference time and with only a 0.8\% loss in deformation field smoothness.
Evaluation of dynamic characteristics of power grid based on GNN and application on knowledge graph
Nov 28, 2023A novel method for detecting faults in power grids using a graph neural network (GNN) has been developed, aimed at enhancing intelligent fault diagnosis in network operation and maintenance. This GNN-based approach identifies faulty nodes within the power grid through a specialized electrical feature extraction model coupled with a knowledge graph. Incorporating temporal data, the method leverages the status of nodes from preceding and subsequent time periods to aid in current fault detection. To validate the effectiveness of this GNN in extracting node features, a correlation analysis of the output features from each node within the neural network layer was conducted. The results from experiments show that this method can accurately locate fault nodes in simulated scenarios with a remarkable 99.53% accuracy. Additionally, the graph neural network's feature modeling allows for a qualitative examination of how faults spread across nodes, providing valuable insights for analyzing fault nodes.
1-Lipschitz Layers Compared: Memory, Speed, and Certifiable Robustness
Nov 28, 2023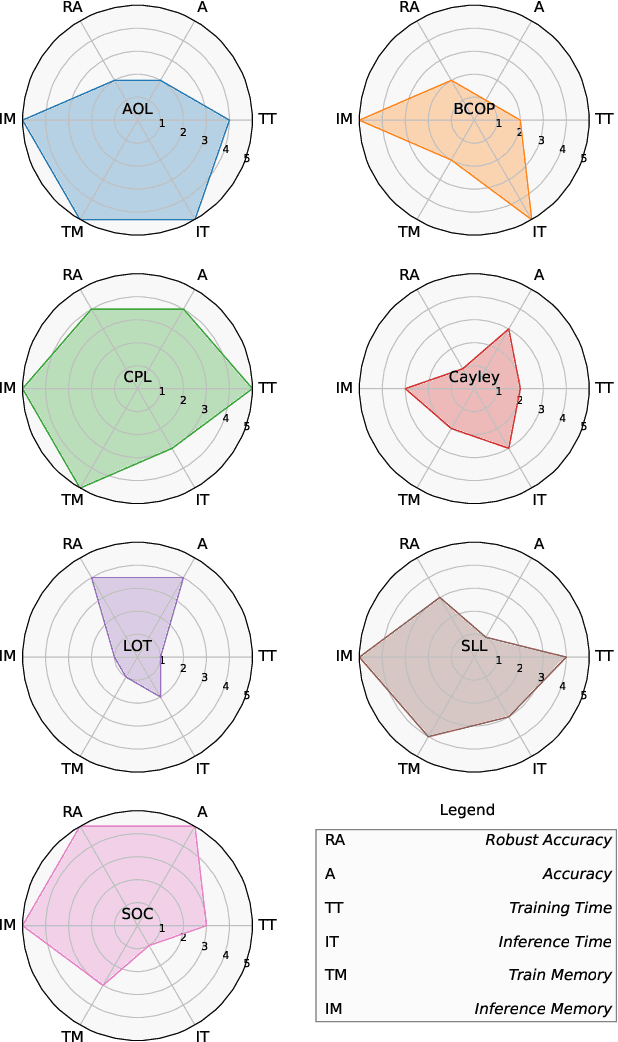
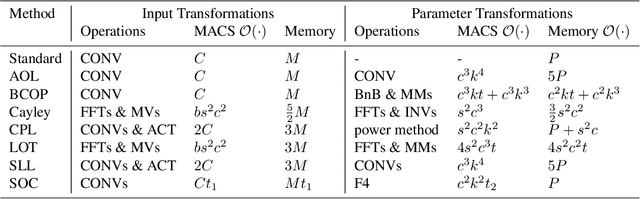
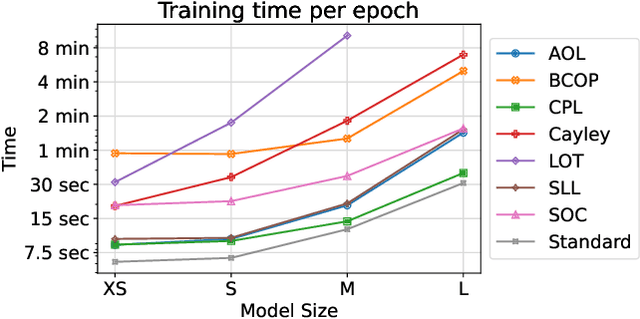
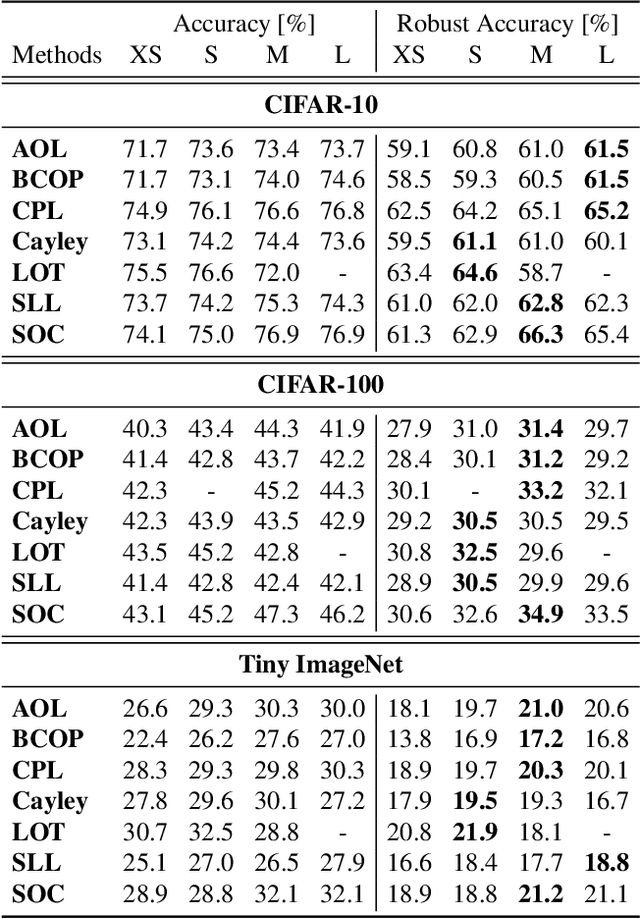
The robustness of neural networks against input perturbations with bounded magnitude represents a serious concern in the deployment of deep learning models in safety-critical systems. Recently, the scientific community has focused on enhancing certifiable robustness guarantees by crafting 1-Lipschitz neural networks that leverage Lipschitz bounded dense and convolutional layers. Although different methods have been proposed in the literature to achieve this goal, understanding the performance of such methods is not straightforward, since different metrics can be relevant (e.g., training time, memory usage, accuracy, certifiable robustness) for different applications. For this reason, this work provides a thorough theoretical and empirical comparison between methods by evaluating them in terms of memory usage, speed, and certifiable robust accuracy. The paper also provides some guidelines and recommendations to support the user in selecting the methods that work best depending on the available resources. We provide code at https://github.com/berndprach/1LipschitzLayersCompared.
Time-Variant Overlap-Add in Partitions
Sep 30, 2023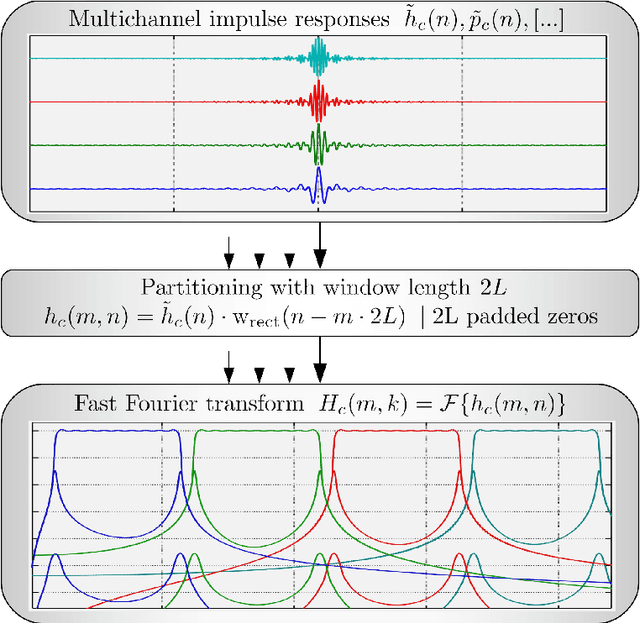
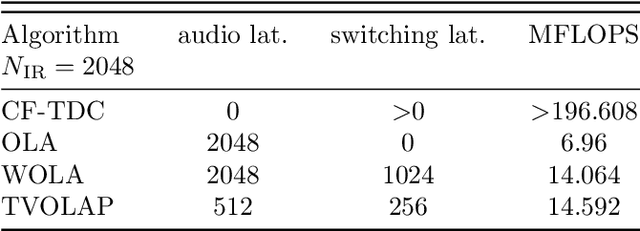
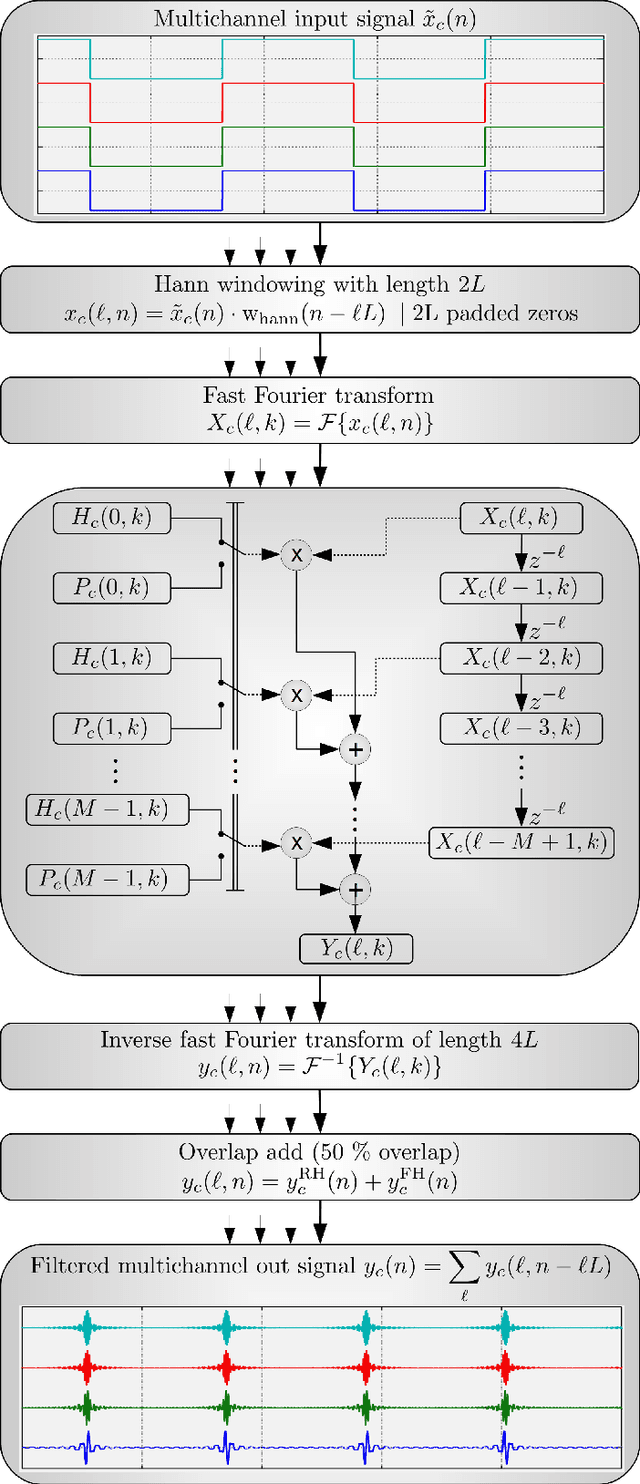

Virtual and augmented realities are increasingly popular tools in many domains such as architecture, production, training and education, (psycho)therapy, gaming, and others. For a convincing rendering of sound in virtual and augmented environments, audio signals must be convolved in real-time with impulse responses that change from one moment in time to another. Key requirements for the implementation of such time-variant real-time convolution algorithms are short latencies, moderate computational cost and memory footprint, and no perceptible switching artifacts. In this engineering report, we introduce a partitioned convolution algorithm that is able to quickly switch between impulse responses without introducing perceptible artifacts, while maintaining a constant computational load and low memory usage. Implementations in several popular programming languages are freely available via GitHub.
Toward a Foundation Model for Time Series Data
Oct 05, 2023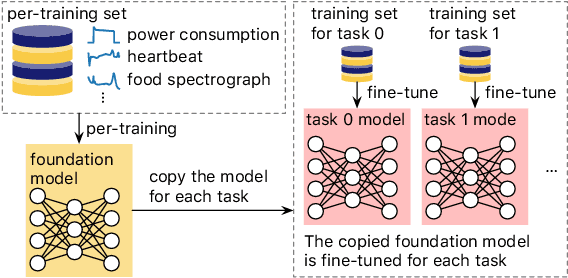
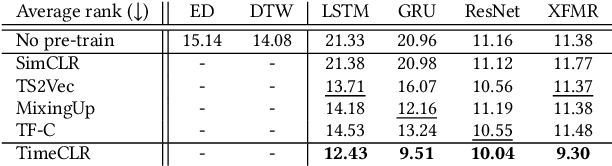
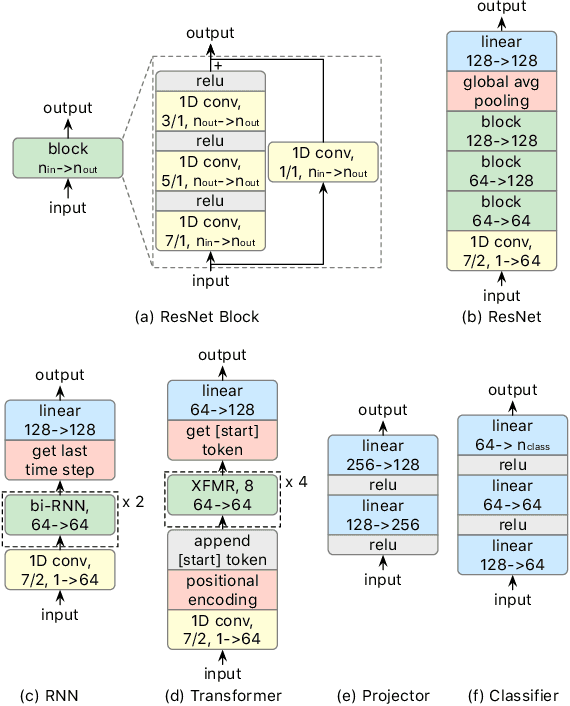
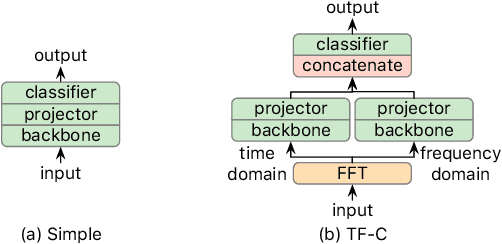
A foundation model is a machine learning model trained on a large and diverse set of data, typically using self-supervised learning-based pre-training techniques, that can be adapted to various downstream tasks. However, current research on time series pre-training has mostly focused on models pre-trained solely on data from a single domain, resulting in a lack of knowledge about other types of time series. However, current research on time series pre-training has predominantly focused on models trained exclusively on data from a single domain. As a result, these models possess domain-specific knowledge that may not be easily transferable to time series from other domains. In this paper, we aim to develop an effective time series foundation model by leveraging unlabeled samples from multiple domains. To achieve this, we repurposed the publicly available UCR Archive and evaluated four existing self-supervised learning-based pre-training methods, along with a novel method, on the datasets. We tested these methods using four popular neural network architectures for time series to understand how the pre-training methods interact with different network designs. Our experimental results show that pre-training improves downstream classification tasks by enhancing the convergence of the fine-tuning process. Furthermore, we found that the proposed pre-training method, when combined with the Transformer model, outperforms the alternatives.