 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
BAM: Box Abstraction Monitors for Real-time OoD Detection in Object Detection
Mar 27, 2024
Out-of-distribution (OoD) detection techniques for deep neural networks (DNNs) become crucial thanks to their filtering of abnormal inputs, especially when DNNs are used in safety-critical applications and interact with an open and dynamic environment. Nevertheless, integrating OoD detection into state-of-the-art (SOTA) object detection DNNs poses significant challenges, partly due to the complexity introduced by the SOTA OoD construction methods, which require the modification of DNN architecture and the introduction of complex loss functions. This paper proposes a simple, yet surprisingly effective, method that requires neither retraining nor architectural change in object detection DNN, called Box Abstraction-based Monitors (BAM). The novelty of BAM stems from using a finite union of convex box abstractions to capture the learned features of objects for in-distribution (ID) data, and an important observation that features from OoD data are more likely to fall outside of these boxes. The union of convex regions within the feature space allows the formation of non-convex and interpretable decision boundaries, overcoming the limitations of VOS-like detectors without sacrificing real-time performance. Experiments integrating BAM into Faster R-CNN-based object detection DNNs demonstrate a considerably improved performance against SOTA OoD detection techniques.
Predictive Modeling for Breast Cancer Classification in the Context of Bangladeshi Patients: A Supervised Machine Learning Approach with Explainable AI
Apr 06, 2024Breast cancer has rapidly increased in prevalence in recent years, making it one of the leading causes of mortality worldwide. Among all cancers, it is by far the most common. Diagnosing this illness manually requires significant time and expertise. Since detecting breast cancer is a time-consuming process, preventing its further spread can be aided by creating machine-based forecasts. Machine learning and Explainable AI are crucial in classification as they not only provide accurate predictions but also offer insights into how the model arrives at its decisions, aiding in the understanding and trustworthiness of the classification results. In this study, we evaluate and compare the classification accuracy, precision, recall, and F-1 scores of five different machine learning methods using a primary dataset (500 patients from Dhaka Medical College Hospital). Five different supervised machine learning techniques, including decision tree, random forest, logistic regression, naive bayes, and XGBoost, have been used to achieve optimal results on our dataset. Additionally, this study applied SHAP analysis to the XGBoost model to interpret the model's predictions and understand the impact of each feature on the model's output. We compared the accuracy with which several algorithms classified the data, as well as contrasted with other literature in this field. After final evaluation, this study found that XGBoost achieved the best model accuracy, which is 97%.
Study of the effect of Sharpness on Blind Video Quality Assessment
Apr 06, 2024Introduction: Video Quality Assessment (VQA) is one of the important areas of study in this modern era, where video is a crucial component of communication with applications in every field. Rapid technology developments in mobile technology enabled anyone to create videos resulting in a varied range of video quality scenarios. Objectives: Though VQA was present for some time with the classical metrices like SSIM and PSNR, the advent of machine learning has brought in new techniques of VQAs which are built upon Convolutional Neural Networks (CNNs) or Deep Neural Networks (DNNs). Methods: Over the past years various research studies such as the BVQA which performed video quality assessment of nature-based videos using DNNs exposed the powerful capabilities of machine learning algorithms. BVQA using DNNs explored human visual system effects such as content dependency and time-related factors normally known as temporal effects. Results: This study explores the sharpness effect on models like BVQA. Sharpness is the measure of the clarity and details of the video image. Sharpness typically involves analyzing the edges and contrast of the image to determine the overall level of detail and sharpness. Conclusion: This study uses the existing video quality databases such as CVD2014. A comparative study of the various machine learning parameters such as SRCC and PLCC during the training and testing are presented along with the conclusion.
Decision Transformer for Wireless Communications: A New Paradigm of Resource Management
Apr 08, 2024As the next generation of mobile systems evolves, artificial intelligence (AI) is expected to deeply integrate with wireless communications for resource management in variable environments. In particular, deep reinforcement learning (DRL) is an important tool for addressing stochastic optimization issues of resource allocation. However, DRL has to start each new training process from the beginning once the state and action spaces change, causing low sample efficiency and poor generalization ability. Moreover, each DRL training process may take a large number of epochs to converge, which is unacceptable for time-sensitive scenarios. In this paper, we adopt an alternative AI technology, namely, the Decision Transformer (DT), and propose a DT-based adaptive decision architecture for wireless resource management. This architecture innovates through constructing pre-trained models in the cloud and then fine-tuning personalized models at the edges. By leveraging the power of DT models learned over extensive datasets, the proposed architecture is expected to achieve rapid convergence with many fewer training epochs and higher performance in a new context, e.g., similar tasks with different state and action spaces, compared with DRL. We then design DT frameworks for two typical communication scenarios: Intelligent reflecting surfaces-aided communications and unmanned aerial vehicle-aided edge computing. Simulations demonstrate that the proposed DT frameworks achieve over $3$-$6$ times speedup in convergence and better performance relative to the classic DRL method, namely, proximal policy optimization.
Enhancing Clinical Efficiency through LLM: Discharge Note Generation for Cardiac Patients
Apr 08, 2024Medical documentation, including discharge notes, is crucial for ensuring patient care quality, continuity, and effective medical communication. However, the manual creation of these documents is not only time-consuming but also prone to inconsistencies and potential errors. The automation of this documentation process using artificial intelligence (AI) represents a promising area of innovation in healthcare. This study directly addresses the inefficiencies and inaccuracies in creating discharge notes manually, particularly for cardiac patients, by employing AI techniques, specifically large language model (LLM). Utilizing a substantial dataset from a cardiology center, encompassing wide-ranging medical records and physician assessments, our research evaluates the capability of LLM to enhance the documentation process. Among the various models assessed, Mistral-7B distinguished itself by accurately generating discharge notes that significantly improve both documentation efficiency and the continuity of care for patients. These notes underwent rigorous qualitative evaluation by medical expert, receiving high marks for their clinical relevance, completeness, readability, and contribution to informed decision-making and care planning. Coupled with quantitative analyses, these results confirm Mistral-7B's efficacy in distilling complex medical information into concise, coherent summaries. Overall, our findings illuminate the considerable promise of specialized LLM, such as Mistral-7B, in refining healthcare documentation workflows and advancing patient care. This study lays the groundwork for further integrating advanced AI technologies in healthcare, demonstrating their potential to revolutionize patient documentation and support better care outcomes.
Neural Network Modeling for Forecasting Tourism Demand in Stopića Cave: A Serbian Cave Tourism Study
Apr 07, 2024For modeling the number of visits in Stopi\'{c}a cave (Serbia) we consider the classical Auto-regressive Integrated Moving Average (ARIMA) model, Machine Learning (ML) method Support Vector Regression (SVR), and hybrid NeuralPropeth method which combines classical and ML concepts. The most accurate predictions were obtained with NeuralPropeth which includes the seasonal component and growing trend of time-series. In addition, non-linearity is modeled by shallow Neural Network (NN), and Google Trend is incorporated as an exogenous variable. Modeling tourist demand represents great importance for management structures and decision-makers due to its applicability in establishing sustainable tourism utilization strategies in environmentally vulnerable destinations such as caves. The data provided insights into the tourist demand in Stopi\'{c}a cave and preliminary data for addressing the issues of carrying capacity within the most visited cave in Serbia.
Advancing Time Series Classification with Multimodal Language Modeling
Mar 19, 2024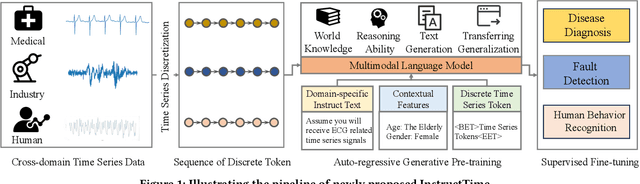
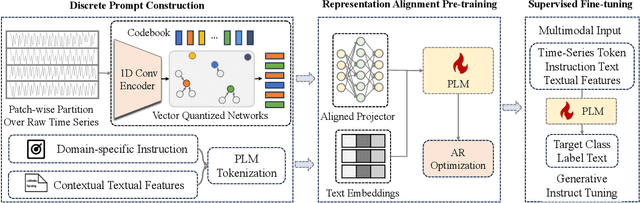
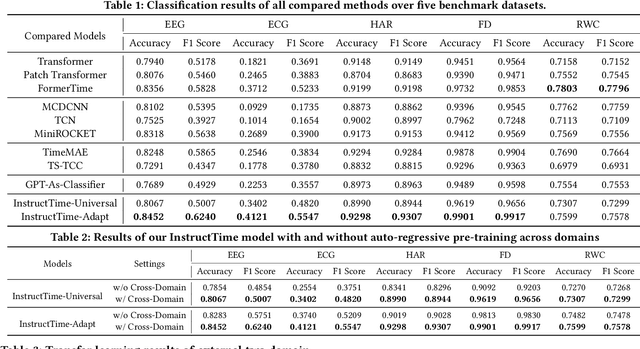

For the advancements of time series classification, scrutinizing previous studies, most existing methods adopt a common learning-to-classify paradigm - a time series classifier model tries to learn the relation between sequence inputs and target label encoded by one-hot distribution. Although effective, this paradigm conceals two inherent limitations: (1) encoding target categories with one-hot distribution fails to reflect the comparability and similarity between labels, and (2) it is very difficult to learn transferable model across domains, which greatly hinder the development of universal serving paradigm. In this work, we propose InstructTime, a novel attempt to reshape time series classification as a learning-to-generate paradigm. Relying on the powerful generative capacity of the pre-trained language model, the core idea is to formulate the classification of time series as a multimodal understanding task, in which both task-specific instructions and raw time series are treated as multimodal inputs while the label information is represented by texts. To accomplish this goal, three distinct designs are developed in the InstructTime. Firstly, a time series discretization module is designed to convert continuous time series into a sequence of hard tokens to solve the inconsistency issue across modal inputs. To solve the modality representation gap issue, for one thing, we introduce an alignment projected layer before feeding the transformed token of time series into language models. For another, we highlight the necessity of auto-regressive pre-training across domains, which can facilitate the transferability of the language model and boost the generalization performance. Extensive experiments are conducted over benchmark datasets, whose results uncover the superior performance of InstructTime and the potential for a universal foundation model in time series classification.
PointSAGE: Mesh-independent superresolution approach to fluid flow predictions
Apr 06, 2024Computational Fluid Dynamics (CFD) serves as a powerful tool for simulating fluid flow across diverse industries. High-resolution CFD simulations offer valuable insights into fluid behavior and flow patterns, aiding in optimizing design features or enhancing system performance. However, as resolution increases, computational data requirements and time increase proportionately. This presents a persistent challenge in CFD. Recently, efforts have been directed towards accurately predicting fine-mesh simulations using coarse-mesh simulations, with geometry and boundary conditions as input. Drawing inspiration from models designed for super-resolution, deep learning techniques like UNets have been applied to address this challenge. However, these existing methods are limited to structured data and fail if the mesh is unstructured due to its inability to convolute. Additionally, incorporating geometry/mesh information in the training process introduces drawbacks such as increased data requirements, challenges in generalizing to unseen geometries for the same physical phenomena, and issues with robustness to mesh distortions. To address these concerns, we propose a novel framework, PointSAGE a mesh-independent network that leverages the unordered, mesh-less nature of Pointcloud to learn the complex fluid flow and directly predict fine simulations, completely neglecting mesh information. Utilizing an adaptable framework, the model accurately predicts the fine data across diverse point cloud sizes, regardless of the training dataset's dimension. We have evaluated the effectiveness of PointSAGE on diverse datasets in different scenarios, demonstrating notable results and a significant acceleration in computational time in generating fine simulations compared to standard CFD techniques.
Optimal Batch Allocation for Wireless Federated Learning
Apr 03, 2024Federated learning aims to construct a global model that fits the dataset distributed across local devices without direct access to private data, leveraging communication between a server and the local devices. In the context of a practical communication scheme, we study the completion time required to achieve a target performance. Specifically, we analyze the number of iterations required for federated learning to reach a specific optimality gap from a minimum global loss. Subsequently, we characterize the time required for each iteration under two fundamental multiple access schemes: time-division multiple access (TDMA) and random access (RA). We propose a step-wise batch allocation, demonstrated to be optimal for TDMA-based federated learning systems. Additionally, we show that the non-zero batch gap between devices provided by the proposed step-wise batch allocation significantly reduces the completion time for RA-based learning systems. Numerical evaluations validate these analytical results through real-data experiments, highlighting the remarkable potential for substantial completion time reduction.
Gyro-based Neural Single Image Deblurring
Apr 08, 2024In this paper, we present GyroDeblurNet, a novel single image deblurring method that utilizes a gyro sensor to effectively resolve the ill-posedness of image deblurring. The gyro sensor provides valuable information about camera motion during exposure time that can significantly improve deblurring quality. However, effectively exploiting real-world gyro data is challenging due to significant errors from various sources including sensor noise, the disparity between the positions of a camera module and a gyro sensor, the absence of translational motion information, and moving objects whose motions cannot be captured by a gyro sensor. To handle gyro error, GyroDeblurNet is equipped with two novel neural network blocks: a gyro refinement block and a gyro deblurring block. The gyro refinement block refines the error-ridden gyro data using the blur information from the input image. On the other hand, the gyro deblurring block removes blur from the input image using the refined gyro data and further compensates for gyro error by leveraging the blur information from the input image. For training a neural network with erroneous gyro data, we propose a training strategy based on the curriculum learning. We also introduce a novel gyro data embedding scheme to represent real-world intricate camera shakes. Finally, we present a synthetic dataset and a real dataset for the training and evaluation of gyro-based single image deblurring. Our experiments demonstrate that our approach achieves state-of-the-art deblurring quality by effectively utilizing erroneous gyro data.