 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Resonant Inductive Coupling Network for Human-Sized Magnetic Particle Imaging
Dec 23, 2023
In Magnetic Particle Imaging, a field-free region is maneuvered throughout the field of view using a time-varying magnetic field known as the drive-field. Human-sized systems operate the drive-field in the kHz range and generate it by utilizing strong currents that can rise to the kA range within a coil called the drive field generator. Matching and tuning between a power amplifier, a band-pass filter and the drive-field generator is required. Here, for reasons of safety in future human scanners, a symmetrical topology and a transformer, called inductive coupling network is used. Our primary objectives are to achieve floating potentials to ensure patient safety, attaining high linearity and high gain for the resonant transformer. We present a novel systematic approach to the design of a loss-optimized resonant toroid with a D-shaped cross section, employing segmentation to adjust the inductance-to-resistance ratio while maintaining a constant quality factor. Simultaneously, we derive a specific matching condition of a symmetric transmit-receive circuit for magnetic particle imaging. The chosen setup filters the fundamental frequency and allows simultaneous signal transmission and reception. In addition, the decoupling of multiple drive field channels is discussed and the primary side of the transformer is evaluated for maximum coupling and minimum stray field. Two prototypes were constructed, measured, decoupled, and compared to the derived theory and to method-of-moment based simulations.
Living Scenes: Multi-object Relocalization and Reconstruction in Changing 3D Environments
Dec 14, 2023Research into dynamic 3D scene understanding has primarily focused on short-term change tracking from dense observations, while little attention has been paid to long-term changes with sparse observations. We address this gap with MoRE, a novel approach for multi-object relocalization and reconstruction in evolving environments. We view these environments as "living scenes" and consider the problem of transforming scans taken at different points in time into a 3D reconstruction of the object instances, whose accuracy and completeness increase over time. At the core of our method lies an SE(3)-equivariant representation in a single encoder-decoder network, trained on synthetic data. This representation enables us to seamlessly tackle instance matching, registration, and reconstruction. We also introduce a joint optimization algorithm that facilitates the accumulation of point clouds originating from the same instance across multiple scans taken at different points in time. We validate our method on synthetic and real-world data and demonstrate state-of-the-art performance in both end-to-end performance and individual subtasks.
Machine Learning-Enhanced Prediction of Surface Smoothness for Inertial Confinement Fusion Target Polishing Using Limited Data
Dec 16, 2023In Inertial Confinement Fusion (ICF) process, roughly a 2mm spherical shell made of high density carbon is used as target for laser beams, which compress and heat it to energy levels needed for high fusion yield. These shells are polished meticulously to meet the standards for a fusion shot. However, the polishing of these shells involves multiple stages, with each stage taking several hours. To make sure that the polishing process is advancing in the right direction, we are able to measure the shell surface roughness. This measurement, however, is very labor-intensive, time-consuming, and requires a human operator. We propose to use machine learning models that can predict surface roughness based on the data collected from a vibration sensor that is connected to the polisher. Such models can generate surface roughness of the shells in real-time, allowing the operator to make any necessary changes to the polishing for optimal result.
Unraveling the "Anomaly" in Time Series Anomaly Detection: A Self-supervised Tri-domain Solution
Nov 27, 2023The ongoing challenges in time series anomaly detection (TSAD), notably the scarcity of anomaly labels and the variability in anomaly lengths and shapes, have led to the need for a more efficient solution. As limited anomaly labels hinder traditional supervised models in TSAD, various SOTA deep learning techniques, such as self-supervised learning, have been introduced to tackle this issue. However, they encounter difficulties handling variations in anomaly lengths and shapes, limiting their adaptability to diverse anomalies. Additionally, many benchmark datasets suffer from the problem of having explicit anomalies that even random functions can detect. This problem is exacerbated by ill-posed evaluation metrics, known as point adjustment (PA), which can result in inflated model performance. In this context, we propose a novel self-supervised learning based Tri-domain Anomaly Detector (TriAD), which addresses these challenges by modeling features across three data domains - temporal, frequency, and residual domains - without relying on anomaly labels. Unlike traditional contrastive learning methods, TriAD employs both inter-domain and intra-domain contrastive loss to learn common attributes among normal data and differentiate them from anomalies. Additionally, our approach can detect anomalies of varying lengths by integrating with a discord discovery algorithm. It is worth noting that this study is the first to reevaluate the deep learning potential in TSAD, utilizing both rigorously designed datasets (i.e., UCR Archive) and evaluation metrics (i.e., PA%K and affiliation). Through experimental results on the UCR dataset, TriAD achieves an impressive three-fold increase in PA%K based F1 scores over SOTA deep learning models, and 50% increase of accuracy as compared to SOTA discord discovery algorithms.
Scalable and hyper-parameter-free non-parametric covariate shift adaptation with conditional sampling
Dec 15, 2023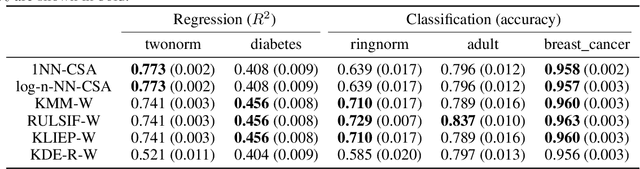
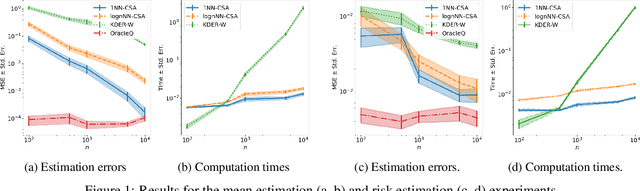
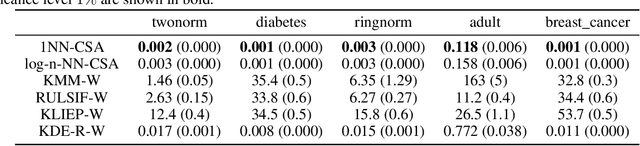
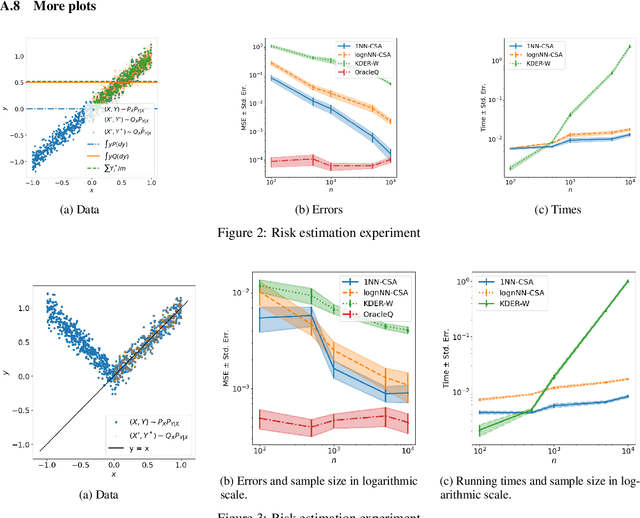
Many existing covariate shift adaptation methods estimate sample weights to be used in the risk estimation in order to mitigate the gap between the source and the target distribution. However, non-parametrically estimating the optimal weights typically involves computationally expensive hyper-parameter tuning that is crucial to the final performance. In this paper, we propose a new non-parametric approach to covariate shift adaptation which avoids estimating weights and has no hyper-parameter to be tuned. Our basic idea is to label unlabeled target data according to the $k$-nearest neighbors in the source dataset. Our analysis indicates that setting $k = 1$ is an optimal choice. Thanks to this property, there is no need to tune any hyper-parameters, unlike other non-parametric methods. Moreover, our method achieves a running time quasi-linear in the sample size with a theoretical guarantee, for the first time in the literature to the best of our knowledge. Our results include sharp rates of convergence for estimating the joint probability distribution of the target data. In particular, the variance of our estimators has the same rate of convergence as for standard parametric estimation despite their non-parametric nature. Our numerical experiments show that proposed method brings drastic reduction in the running time with accuracy comparable to that of the state-of-the-art methods.
How Does It Function? Characterizing Long-term Trends in Production Serverless Workloads
Dec 15, 2023This paper releases and analyzes two new Huawei cloud serverless traces. The traces span a period of over 7 months with over 1.4 trillion function invocations combined. The first trace is derived from Huawei's internal workloads and contains detailed per-second statistics for 200 functions running across multiple Huawei cloud data centers. The second trace is a representative workload from Huawei's public FaaS platform. This trace contains per-minute arrival rates for over 5000 functions running in a single Huawei data center. We present the internals of a production FaaS platform by characterizing resource consumption, cold-start times, programming languages used, periodicity, per-second versus per-minute burstiness, correlations, and popularity. Our findings show that there is considerable diversity in how serverless functions behave: requests vary by up to 9 orders of magnitude across functions, with some functions executed over 1 billion times per day; scheduling time, execution time and cold-start distributions vary across 2 to 4 orders of magnitude and have very long tails; and function invocation counts demonstrate strong periodicity for many individual functions and on an aggregate level. Our analysis also highlights the need for further research in estimating resource reservations and time-series prediction to account for the huge diversity in how serverless functions behave. Datasets and code available at https://github.com/sir-lab/data-release
A Multi-Stage Adaptive Feature Fusion Neural Network for Multimodal Gait Recognition
Dec 22, 2023Gait recognition is a biometric technology that has received extensive attention. Most existing gait recognition algorithms are unimodal, and a few multimodal gait recognition algorithms perform multimodal fusion only once. None of these algorithms may fully exploit the complementary advantages of the multiple modalities. In this paper, by considering the temporal and spatial characteristics of gait data, we propose a multi-stage feature fusion strategy (MSFFS), which performs multimodal fusions at different stages in the feature extraction process. Also, we propose an adaptive feature fusion module (AFFM) that considers the semantic association between silhouettes and skeletons. The fusion process fuses different silhouette areas with their more related skeleton joints. Since visual appearance changes and time passage co-occur in a gait period, we propose a multiscale spatial-temporal feature extractor (MSSTFE) to learn the spatial-temporal linkage features thoroughly. Specifically, MSSTFE extracts and aggregates spatial-temporal linkages information at different spatial scales. Combining the strategy and modules mentioned above, we propose a multi-stage adaptive feature fusion (MSAFF) neural network, which shows state-of-the-art performance in many experiments on three datasets. Besides, MSAFF is equipped with feature dimensional pooling (FD Pooling), which can significantly reduce the dimension of the gait representations without hindering the accuracy. https://github.com/ShinanZou/MSAFF
* This paper has been accepted by IJCB2023
Attacking Byzantine Robust Aggregation in High Dimensions
Dec 22, 2023Training modern neural networks or models typically requires averaging over a sample of high-dimensional vectors. Poisoning attacks can skew or bias the average vectors used to train the model, forcing the model to learn specific patterns or avoid learning anything useful. Byzantine robust aggregation is a principled algorithmic defense against such biasing. Robust aggregators can bound the maximum bias in computing centrality statistics, such as mean, even when some fraction of inputs are arbitrarily corrupted. Designing such aggregators is challenging when dealing with high dimensions. However, the first polynomial-time algorithms with strong theoretical bounds on the bias have recently been proposed. Their bounds are independent of the number of dimensions, promising a conceptual limit on the power of poisoning attacks in their ongoing arms race against defenses. In this paper, we show a new attack called HIDRA on practical realization of strong defenses which subverts their claim of dimension-independent bias. HIDRA highlights a novel computational bottleneck that has not been a concern of prior information-theoretic analysis. Our experimental evaluation shows that our attacks almost completely destroy the model performance, whereas existing attacks with the same goal fail to have much effect. Our findings leave the arms race between poisoning attacks and provable defenses wide open.
UAS-based Automated Structural Inspection Path Planning via Visual Data Analytics and Optimization
Dec 22, 2023Unmanned Aerial Systems (UAS) have gained significant traction for their application in infrastructure inspections. However, considering the enormous scale and complex nature of infrastructure, automation is essential for improving the efficiency and quality of inspection operations. One of the core problems in this regard is electing an optimal automated flight path that can achieve the mission objectives while minimizing flight time. This paper presents an effective formulation for the path planning problem in the context of structural inspections. Coverage is guaranteed as a constraint to ensure damage detectability and path length is minimized as an objective, thus maximizing efficiency while ensuring inspection quality. A two-stage algorithm is then devised to solve the path planning problem, composed of a genetic algorithm for determining the positions of viewpoints and a greedy algorithm for calculating the poses. A comprehensive sensitivity analysis is conducted to demonstrate the proposed algorithm's effectiveness and range of applicability. Applied examples of the algorithm, including partial space inspection with no-fly zones and focused inspection, are also presented, demonstrating the flexibility of the proposed method to meet real-world structural inspection requirements. In conclusion, the results of this study highlight the feasibility of the proposed approach and establish the groundwork for incorporating automation into UAS-based structural inspection mission planning.
GroundVLP: Harnessing Zero-shot Visual Grounding from Vision-Language Pre-training and Open-Vocabulary Object Detection
Dec 22, 2023Visual grounding, a crucial vision-language task involving the understanding of the visual context based on the query expression, necessitates the model to capture the interactions between objects, as well as various spatial and attribute information. However, the annotation data of visual grounding task is limited due to its time-consuming and labor-intensive annotation process, resulting in the trained models being constrained from generalizing its capability to a broader domain. To address this challenge, we propose GroundVLP, a simple yet effective zero-shot method that harnesses visual grounding ability from the existing models trained from image-text pairs and pure object detection data, both of which are more conveniently obtainable and offer a broader domain compared to visual grounding annotation data. GroundVLP proposes a fusion mechanism that combines the heatmap from GradCAM and the object proposals of open-vocabulary detectors. We demonstrate that the proposed method significantly outperforms other zero-shot methods on RefCOCO/+/g datasets, surpassing prior zero-shot state-of-the-art by approximately 28\% on the test split of RefCOCO and RefCOCO+. Furthermore, GroundVLP performs comparably to or even better than some non-VLP-based supervised models on the Flickr30k entities dataset. Our code is available at https://github.com/om-ai-lab/GroundVLP.