 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Good Can Linear Models Be for Time-Series Forecasting?
Jun 25, 2026Time-series forecasting research has been moving steadily toward larger architectures, from specialized transformers to general-purpose foundation models, on the assumption that capacity is what unlocks accuracy. We take the opposite position: most of the gap can be closed at far lower cost by tuning preprocessing rather than scaling models. We use Ridge regression as the testbed, since it has a closed-form solution and interpretable weights, which let the optimal hyperparameters be read off the search directly. We search over context length, local normalization, regularization, and augmentation on eight standard benchmarks and find three patterns. (1) Optimal lookback is strongly series-specific and often non-monotonic in forecast horizon, with fitted power-law exponents ranging from $+0.46$ on ETTm2 to $-0.19$ on Exchange and Traffic, challenging the convention that longer horizons need longer history. (2) Normalizing over a learned trailing fraction of the context, rather than its entirety, is almost universally preferred. (3) Series within the same dataset often disagree on hyperparameters; the optimal degree of cross-series sharing varies from fully shared to fully per-series. The resulting models beat prior linear forecasters on most dataset-horizon entries and exceed Transformer, MLP, and CNN baselines on six of eight benchmarks. The optimized hyperparameters also serve as a diagnostic on the data itself, revealing structures that larger models absorb silently into their learned parameters.
Continuous Thought Machines
May 08, 2025



Biological brains demonstrate complex neural activity, where the timing and interplay between neurons is critical to how brains process information. Most deep learning architectures simplify neural activity by abstracting away temporal dynamics. In this paper we challenge that paradigm. By incorporating neuron-level processing and synchronization, we can effectively reintroduce neural timing as a foundational element. We present the Continuous Thought Machine (CTM), a model designed to leverage neural dynamics as its core representation. The CTM has two core innovations: (1) neuron-level temporal processing, where each neuron uses unique weight parameters to process a history of incoming signals; and (2) neural synchronization employed as a latent representation. The CTM aims to strike a balance between oversimplified neuron abstractions that improve computational efficiency, and biological realism. It operates at a level of abstraction that effectively captures essential temporal dynamics while remaining computationally tractable for deep learning. We demonstrate the CTM's strong performance and versatility across a range of challenging tasks, including ImageNet-1K classification, solving 2D mazes, sorting, parity computation, question-answering, and RL tasks. Beyond displaying rich internal representations and offering a natural avenue for interpretation owing to its internal process, the CTM is able to perform tasks that require complex sequential reasoning. The CTM can also leverage adaptive compute, where it can stop earlier for simpler tasks, or keep computing when faced with more challenging instances. The goal of this work is to share the CTM and its associated innovations, rather than pushing for new state-of-the-art results. To that end, we believe the CTM represents a significant step toward developing more biologically plausible and powerful artificial intelligence systems.
DAM: Towards A Foundation Model for Time Series Forecasting
Jul 25, 2024It is challenging to scale time series forecasting models such that they forecast accurately for multiple distinct domains and datasets, all with potentially different underlying collection procedures (e.g., sample resolution), patterns (e.g., periodicity), and prediction requirements (e.g., reconstruction vs. forecasting). We call this general task universal forecasting. Existing methods usually assume that input data is regularly sampled, and they forecast to pre-determined horizons, resulting in failure to generalise outside of the scope of their training. We propose the DAM - a neural model that takes randomly sampled histories and outputs an adjustable basis composition as a continuous function of time for forecasting to non-fixed horizons. It involves three key components: (1) a flexible approach for using randomly sampled histories from a long-tail distribution, that enables an efficient global perspective of the underlying temporal dynamics while retaining focus on the recent history; (2) a transformer backbone that is trained on these actively sampled histories to produce, as representational output, (3) the basis coefficients of a continuous function of time. We show that a single univariate DAM, trained on 25 time series datasets, either outperformed or closely matched existing SoTA models at multivariate long-term forecasting across 18 datasets, including 8 held-out for zero-shot transfer, even though these models were trained to specialise for each dataset-horizon combination. This single DAM excels at zero-shot transfer and very-long-term forecasting, performs well at imputation, is interpretable via basis function composition and attention, can be tuned for different inference-cost requirements, is robust to missing and irregularly sampled data {by design}.
An Analysis of Linear Time Series Forecasting Models
Mar 25, 2024Despite their simplicity, linear models perform well at time series forecasting, even when pitted against deeper and more expensive models. A number of variations to the linear model have been proposed, often including some form of feature normalisation that improves model generalisation. In this paper we analyse the sets of functions expressible using these linear model architectures. In so doing we show that several popular variants of linear models for time series forecasting are equivalent and functionally indistinguishable from standard, unconstrained linear regression. We characterise the model classes for each linear variant. We demonstrate that each model can be reinterpreted as unconstrained linear regression over a suitably augmented feature set, and therefore admit closed-form solutions when using a mean-squared loss function. We provide experimental evidence that the models under inspection learn nearly identical solutions, and finally demonstrate that the simpler closed form solutions are superior forecasters across 72% of test settings.
How Does It Function? Characterizing Long-term Trends in Production Serverless Workloads
Dec 15, 2023This paper releases and analyzes two new Huawei cloud serverless traces. The traces span a period of over 7 months with over 1.4 trillion function invocations combined. The first trace is derived from Huawei's internal workloads and contains detailed per-second statistics for 200 functions running across multiple Huawei cloud data centers. The second trace is a representative workload from Huawei's public FaaS platform. This trace contains per-minute arrival rates for over 5000 functions running in a single Huawei data center. We present the internals of a production FaaS platform by characterizing resource consumption, cold-start times, programming languages used, periodicity, per-second versus per-minute burstiness, correlations, and popularity. Our findings show that there is considerable diversity in how serverless functions behave: requests vary by up to 9 orders of magnitude across functions, with some functions executed over 1 billion times per day; scheduling time, execution time and cold-start distributions vary across 2 to 4 orders of magnitude and have very long tails; and function invocation counts demonstrate strong periodicity for many individual functions and on an aggregate level. Our analysis also highlights the need for further research in estimating resource reservations and time-series prediction to account for the huge diversity in how serverless functions behave. Datasets and code available at https://github.com/sir-lab/data-release
Latent Adversarial Debiasing: Mitigating Collider Bias in Deep Neural Networks
Nov 19, 2020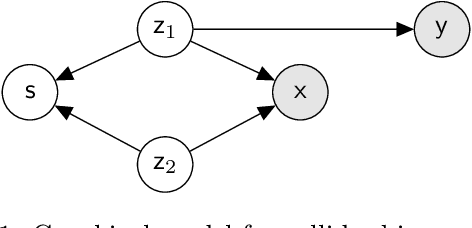
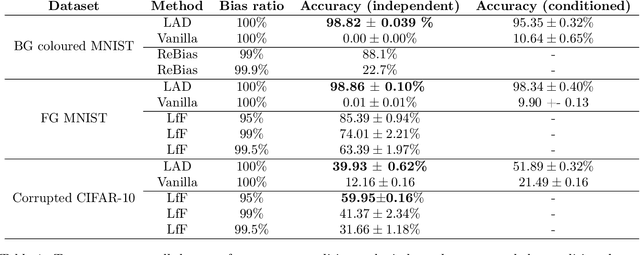
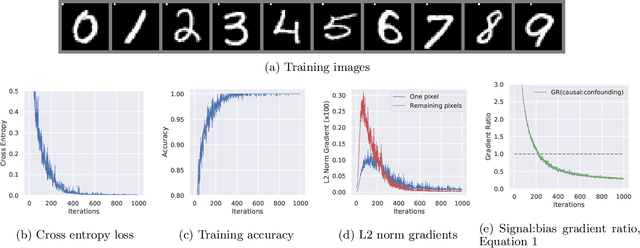
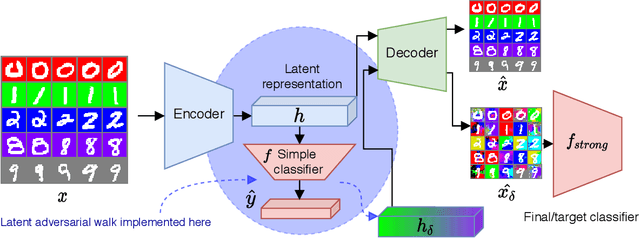
Collider bias is a harmful form of sample selection bias that neural networks are ill-equipped to handle. This bias manifests itself when the underlying causal signal is strongly correlated with other confounding signals due to the training data collection procedure. In the situation where the confounding signal is easy-to-learn, deep neural networks will latch onto this and the resulting model will generalise poorly to in-the-wild test scenarios. We argue herein that the cause of failure is a combination of the deep structure of neural networks and the greedy gradient-driven learning process used - one that prefers easy-to-compute signals when available. We show it is possible to mitigate against this by generating bias-decoupled training data using latent adversarial debiasing (LAD), even when the confounding signal is present in 100% of the training data. By training neural networks on these adversarial examples,we can improve their generalisation in collider bias settings. Experiments show state-of-the-art performance of LAD in label-free debiasing with gains of 76.12% on background coloured MNIST, 35.47% on fore-ground coloured MNIST, and 8.27% on corrupted CIFAR-10.