 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Review of Single-Source Deep Unsupervised Visual Domain Adaptation
Sep 01, 2020
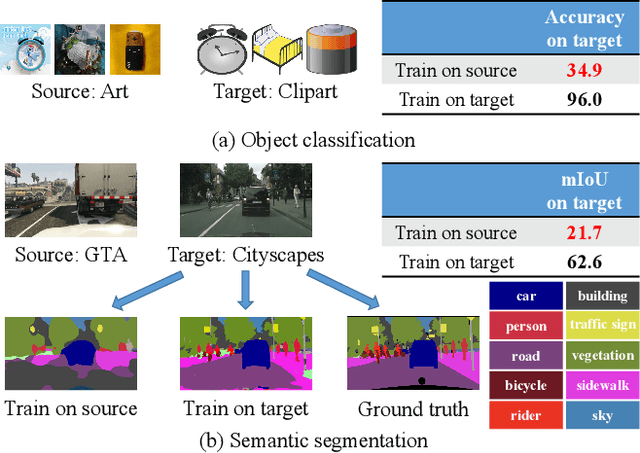
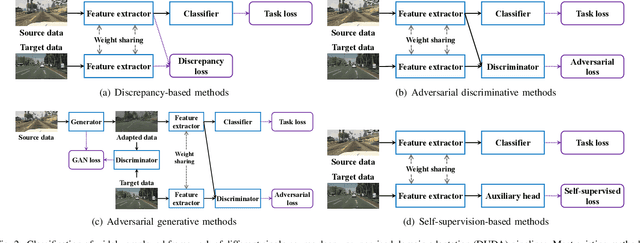

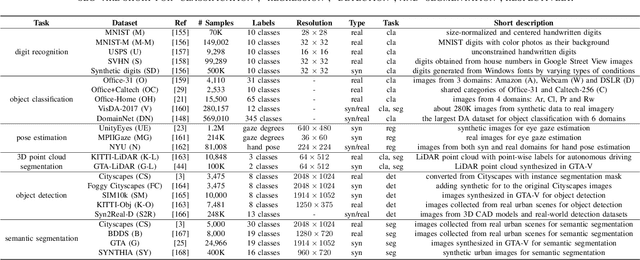
Large-scale labeled training datasets have enabled deep neural networks to excel across a wide range of benchmark vision tasks. However, in many applications, it is prohibitively expensive and time-consuming to obtain large quantities of labeled data. To cope with limited labeled training data, many have attempted to directly apply models trained on a large-scale labeled source domain to another sparsely labeled or unlabeled target domain. Unfortunately, direct transfer across domains often performs poorly due to the presence of domain shift or dataset bias. Domain adaptation is a machine learning paradigm that aims to learn a model from a source domain that can perform well on a different (but related) target domain. In this paper, we review the latest single-source deep unsupervised domain adaptation methods focused on visual tasks and discuss new perspectives for future research. We begin with the definitions of different domain adaptation strategies and the descriptions of existing benchmark datasets. We then summarize and compare different categories of single-source unsupervised domain adaptation methods, including discrepancy-based methods, adversarial discriminative methods, adversarial generative methods, and self-supervision-based methods. Finally, we discuss future research directions with challenges and possible solutions.
Motion Generation Interface of ROS to PODO Software Framework for Wheeled Huamanoid Robot
Jan 02, 2020
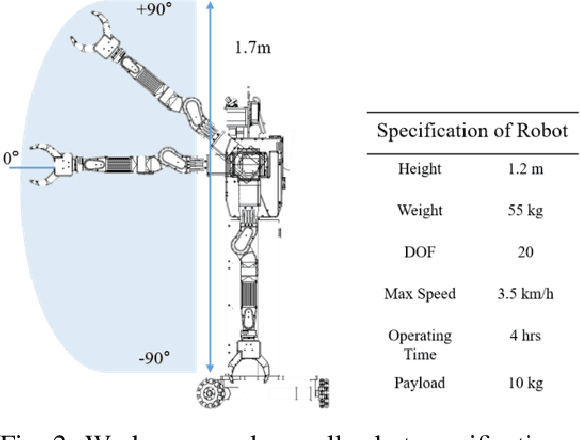
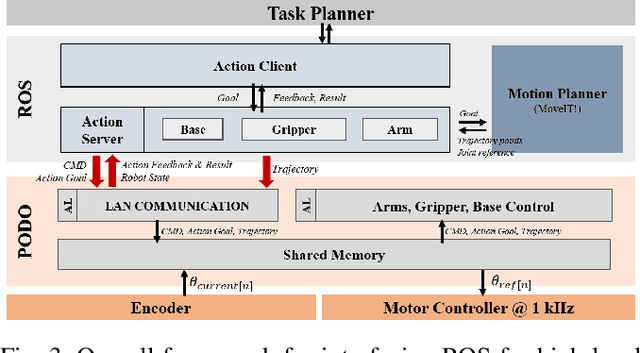

This paper discusses the development of robot motion generation interface between a real-time software architecture and a non-real-time robot operating system. In order for robots to execute intelligent manipulation or navigation, close integration of high-level perception and low-level control is required. However, many available open-source perception modules are developed in ROS, which operates on Linux OS that don't guarantee RT performance. This can lead to non-deterministic responses and stability problems that can adversely affect robot control. As a result, many robotic systems devote RTOS for low-level motion control. Similarly, the humanoid robot platform developed at KAIST, Hubo, utilizes a custom real-time software framework called PODO. Although PODO provides easy interface for motion generation, it lacks interface to high-level frameworks such as ROS. As such, we present a new motion generation interface between ROS and PODO that enables users to generate motion trajectories through standard ROS messages while leveraging a real-time motion controller. With the proposed communication interface, we demonstrate series of manipulator tasks on the actual wheeled humanoid platform, M-Hubo. The overall communication interface responsiveness was at most 27 milliseconds.
Contrastive Learning for Unpaired Image-to-Image Translation
Aug 20, 2020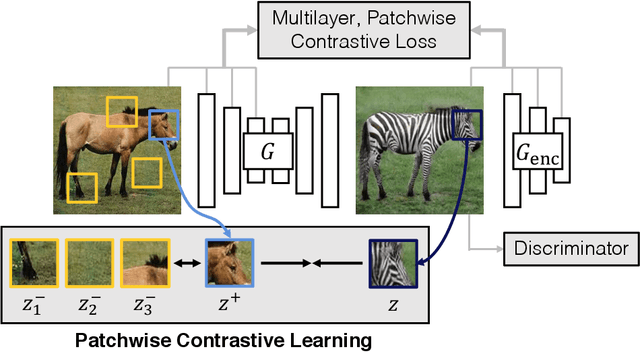
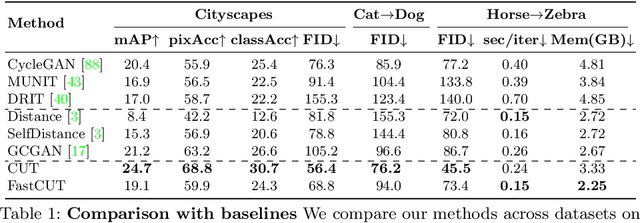
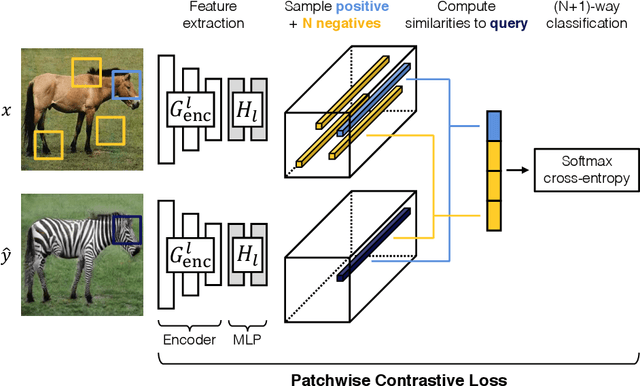
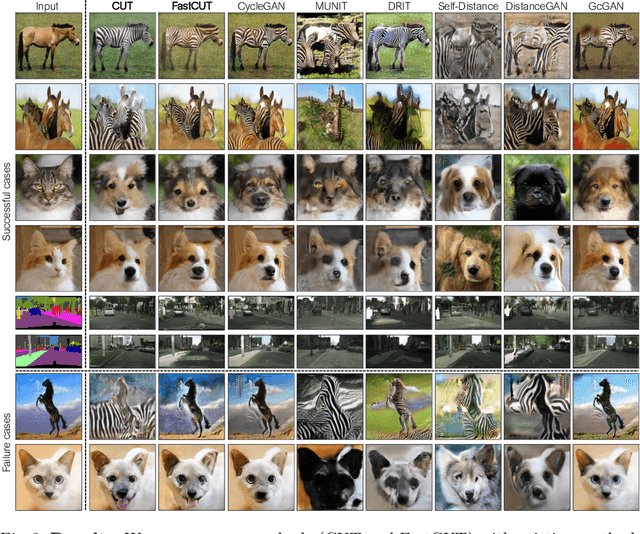
In image-to-image translation, each patch in the output should reflect the content of the corresponding patch in the input, independent of domain. We propose a straightforward method for doing so -- maximizing mutual information between the two, using a framework based on contrastive learning. The method encourages two elements (corresponding patches) to map to a similar point in a learned feature space, relative to other elements (other patches) in the dataset, referred to as negatives. We explore several critical design choices for making contrastive learning effective in the image synthesis setting. Notably, we use a multilayer, patch-based approach, rather than operate on entire images. Furthermore, we draw negatives from within the input image itself, rather than from the rest of the dataset. We demonstrate that our framework enables one-sided translation in the unpaired image-to-image translation setting, while improving quality and reducing training time. In addition, our method can even be extended to the training setting where each "domain" is only a single image.
Application of Structural Similarity Analysis of Visually Salient Areas and Hierarchical Clustering in the Screening of Similar Wireless Capsule Endoscopic Images
Apr 01, 2020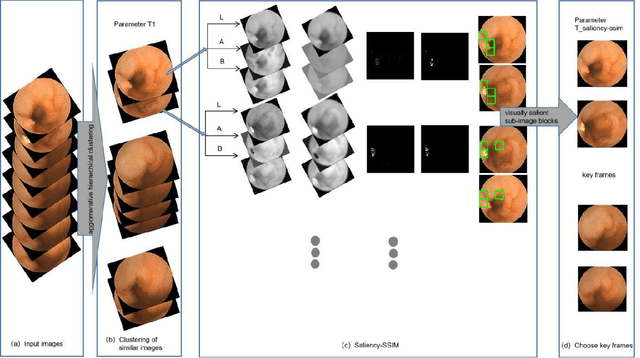
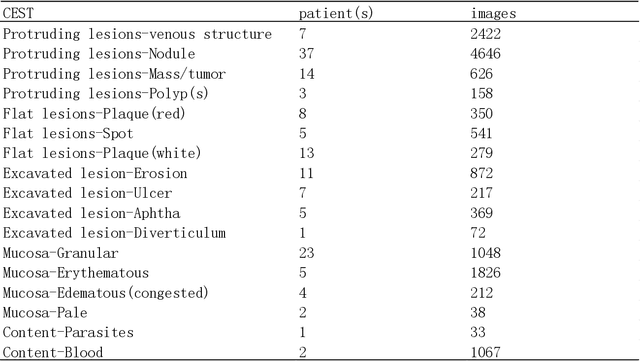

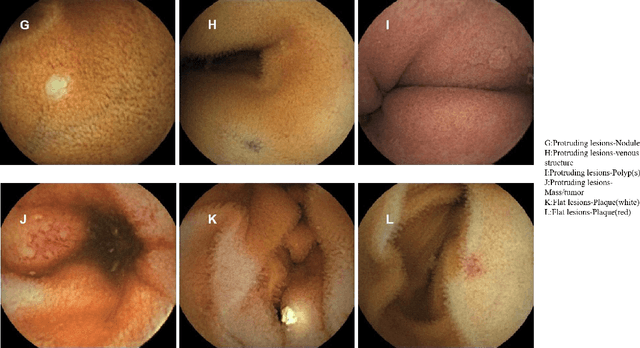
Small intestinal capsule endoscopy is the mainstream method for inspecting small intestinal lesions,but a single small intestinal capsule endoscopy will produce 60,000 - 120,000 images, the majority of which are similar and have no diagnostic value. It takes 2 - 3 hours for doctors to identify lesions from these images. This is time-consuming and increase the probability of misdiagnosis and missed diagnosis since doctors are likely to experience visual fatigue while focusing on a large number of similar images for an extended period of time.In order to solve these problems, we proposed a similar wireless capsule endoscope (WCE) image screening method based on structural similarity analysis and the hierarchical clustering of visually salient sub-image blocks. The similarity clustering of images was automatically identified by hierarchical clustering based on the hue,saturation,value (HSV) spatial color characteristics of the images,and the keyframe images were extracted based on the structural similarity of the visually salient sub-image blocks, in order to accurately identify and screen out similar small intestinal capsule endoscopic images. Subsequently, the proposed method was applied to the capsule endoscope imaging workstation. After screening out similar images in the complete data gathered by the Type I OMOM Small Intestinal Capsule Endoscope from 52 cases covering 17 common types of small intestinal lesions, we obtained a lesion recall of 100% and an average similar image reduction ratio of 76%. With similar images screened out, the average play time of the OMOM image workstation was 18 minutes, which greatly reduced the time spent by doctors viewing the images.
Automated Linear-Time Detection and Quality Assessment of Superpixels in Uncalibrated True- or False-Color RGB Images
Jan 08, 2017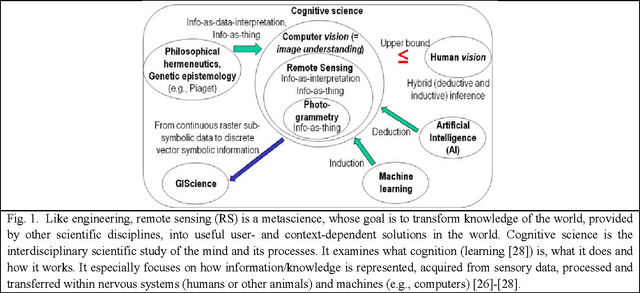
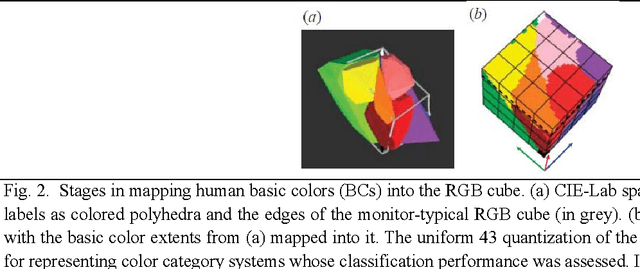
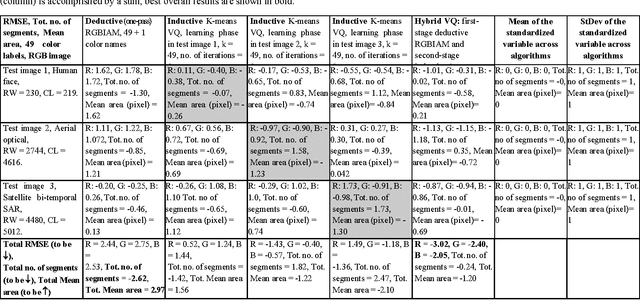
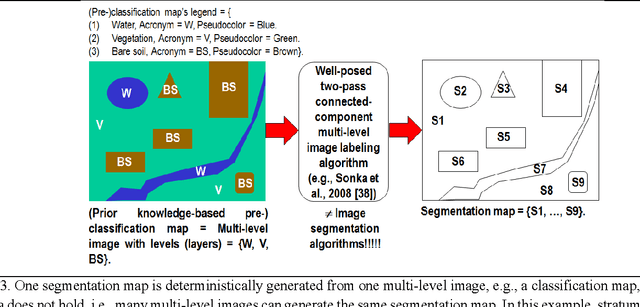
Capable of automated near real time superpixel detection and quality assessment in an uncalibrated monitor typical red green blue (RGB) image, depicted in either true or false colors, an original low level computer vision (CV) lightweight computer program, called RGB Image Automatic Mapper (RGBIAM), is designed and implemented. Constrained by the Calibration Validation (CalVal) requirements of the Quality Assurance Framework for Earth Observation (QA4EO) guidelines, RGBIAM requires as mandatory an uncalibrated RGB image pre processing first stage, consisting of an automated statistical model based color constancy algorithm. The RGBIAM hybrid inference pipeline comprises: (I) a direct quantitative to nominal (QN) RGB variable transform, where RGB pixel values are mapped onto a prior dictionary of color names, equivalent to a static polyhedralization of the RGB cube. Prior color naming is the deductive counterpart of inductive vector quantization (VQ), whose typical VQ error function to minimize is a root mean square error (RMSE). In the output multi level color map domain, superpixels are automatically detected in linear time as connected sets of pixels featuring the same color label. (II) An inverse nominal to quantitative (NQ) RGB variable transform, where a superpixelwise constant RGB image approximation is generated in linear time to assess a VQ error image. The hybrid direct and inverse RGBIAM QNQ transform is: (i) general purpose, data and application independent. (ii) Automated, i.e., it requires no user machine interaction. (iii) Near real time, with a computational complexity increasing linearly with the image size. (iv) Implemented in tile streaming mode, to cope with massive images. Collected outcome and process quality indicators, including degree of automation, computational efficiency, VQ rate and VQ error, are consistent with theoretical expectations.
Tracking Results and Utilization of Artificial Intelligence (tru-AI) in Radiology: Early-Stage COVID-19 Pandemic Observations
Oct 14, 2020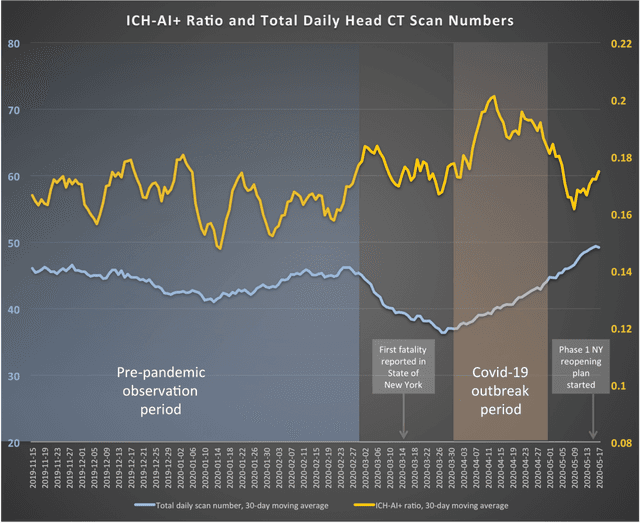

Objective: To introduce a method for tracking results and utilization of Artificial Intelligence (tru-AI) in radiology. By tracking both large-scale utilization and AI results data, the tru-AI approach is designed to calculate surrogates for measuring important disease-related observational quantities over time, such as the prevalence of intracranial hemorrhage during the COVID-19 pandemic outbreak. Methods: To quantitatively investigate the clinical applicability of the tru-AI approach, we analyzed service requests for automatically identifying intracranial hemorrhage (ICH) on head CT using a commercial AI solution. This software is typically used for AI-based prioritization of radiologists' reading lists for reducing turnaround times in patients with emergent clinical findings, such as ICH or pulmonary embolism.We analyzed data of N=9,421 emergency-setting non-contrast head CT studies at a major US healthcare system acquired from November 1, 2019 through June 2, 2020, and compared two observation periods, namely (i) a pre-pandemic epoch from November 1, 2019 through February 29, 2020, and (ii) a period during the COVID-19 pandemic outbreak, April 1-30, 2020. Results: Although daily CT scan counts were significantly lower during (40.1 +/- 7.9) than before (44.4 +/- 7.6) the COVID-19 outbreak, we found that ICH was more likely to be observed by AI during than before the COVID-19 outbreak (p<0.05), with approximately one daily ICH+ case more than statistically expected. Conclusion: Our results suggest that, by tracking both large-scale utilization and AI results data in radiology, the tru-AI approach can contribute clinical value as a versatile exploratory tool, aiming at a better understanding of pandemic-related effects on healthcare.
Tree Echo State Autoencoders with Grammars
Apr 19, 2020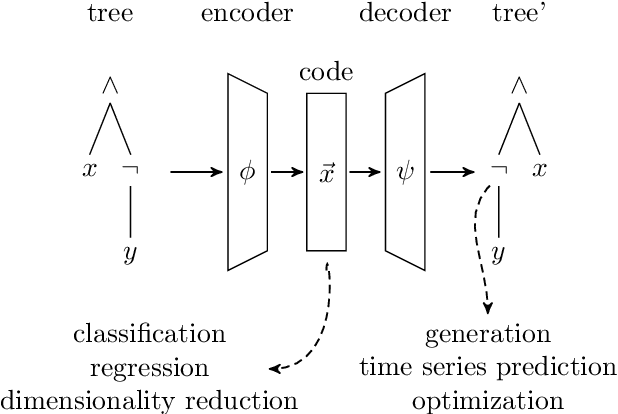

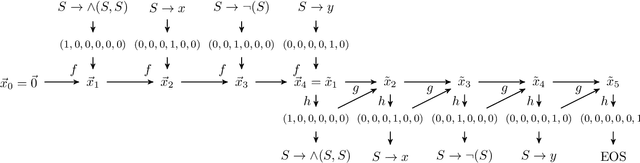
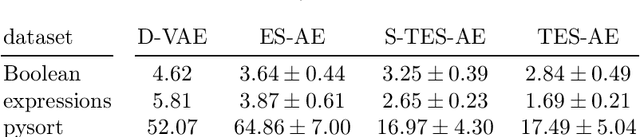
Tree data occurs in many forms, such as computer programs, chemical molecules, or natural language. Unfortunately, the non-vectorial and discrete nature of trees makes it challenging to construct functions with tree-formed output, complicating tasks such as optimization or time series prediction. Autoencoders address this challenge by mapping trees to a vectorial latent space, where tasks are easier to solve, and then mapping the solution back to a tree structure. However, existing autoencoding approaches for tree data fail to take the specific grammatical structure of tree domains into account and rely on deep learning, thus requiring large training datasets and long training times. In this paper, we propose tree echo state autoencoders (TES-AE), which are guided by a tree grammar and can be trained within seconds by virtue of reservoir computing. In our evaluation on three datasets, we demonstrate that our proposed approach is not only much faster than a state-of-the-art deep learning autoencoding approach (D-VAE) but also has less autoencoding error if little data and time is given.
A brief history on Homomorphic learning: A privacy-focused approach to machine learning
Sep 11, 2020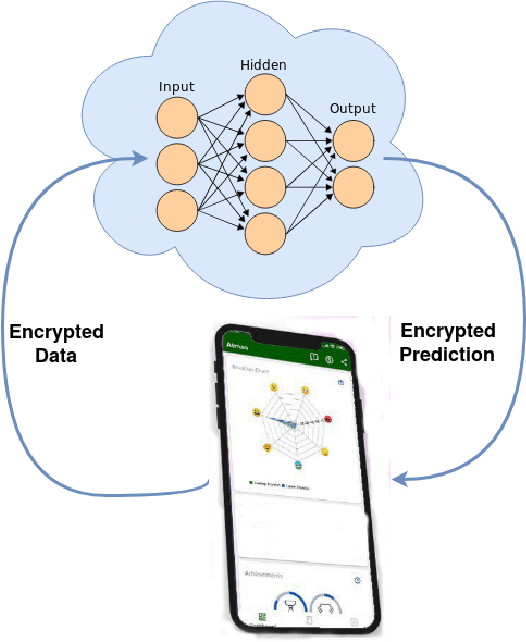


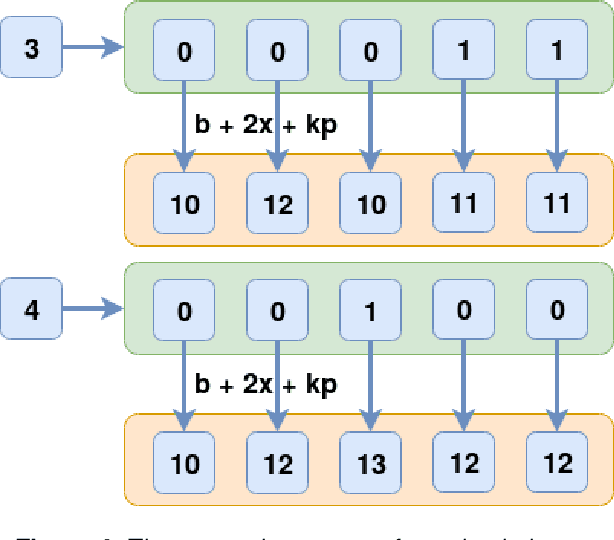
Cryptography and data science research grew exponential with the internet boom. Legacy encryption techniques force users to make a trade-off between usability, convenience, and security. Encryption makes valuable data inaccessible, as it needs to be decrypted each time to perform any operation. Billions of dollars could be saved, and millions of people could benefit from cryptography methods that don't compromise between usability, convenience, and security. Homomorphic encryption is one such paradigm that allows running arbitrary operations on encrypted data. It enables us to run any sophisticated machine learning algorithm without access to the underlying raw data. Thus, homomorphic learning provides the ability to gain insights from sensitive data that has been neglected due to various governmental and organization privacy rules. In this paper, we trace back the ideas of homomorphic learning formally posed by Ronald L. Rivest and Len Alderman as "Can we compute upon encrypted data?" in their 1978 paper. Then we gradually follow the ideas sprouting in the brilliant minds of Shafi Goldwasser, Kristin Lauter, Dan Bonch, Tomas Sander, Donald Beaver, and Craig Gentry to address that vital question. It took more than 30 years of collective effort to finally find the answer "yes" to that important question.
RiskOracle: A Minute-level Citywide Traffic Accident Forecasting Framework
Feb 19, 2020
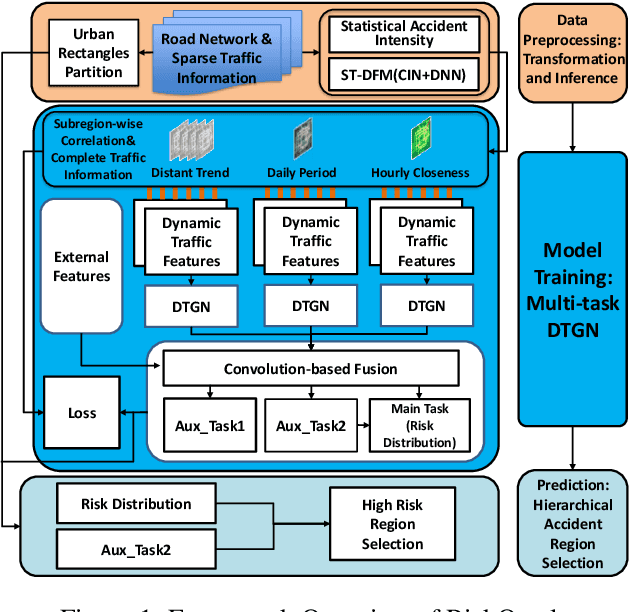
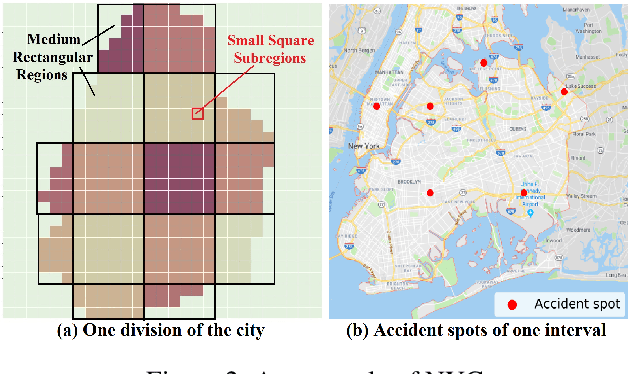
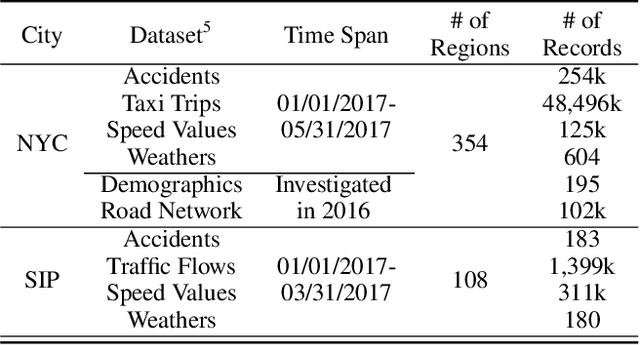
Real-time traffic accident forecasting is increasingly important for public safety and urban management (e.g., real-time safe route planning and emergency response deployment). Previous works on accident forecasting are often performed on hour levels, utilizing existed neural networks with static region-wise correlations taken into account. However, it is still challenging when the granularity of forecasting step improves as the highly dynamic nature of road network and inherent rareness of accident records in one training sample, which leads to biased results and zero-inflated issue. In this work, we propose a novel framework RiskOracle, to improve the prediction granularity to minute levels. Specifically, we first transform the zero-risk values in labels to fit the training network. Then, we propose the Differential Time-varying Graph neural network (DTGN) to capture the immediate changes of traffic status and dynamic inter-subregion correlations. Furthermore, we adopt multi-task and region selection schemes to highlight citywide most-likely accident subregions, bridging the gap between biased risk values and sporadic accident distribution. Extensive experiments on two real-world datasets demonstrate the effectiveness and scalability of our RiskOracle framework.
What Communication Modalities Do Users Prefer in Real Time HRI?
Jun 13, 2016
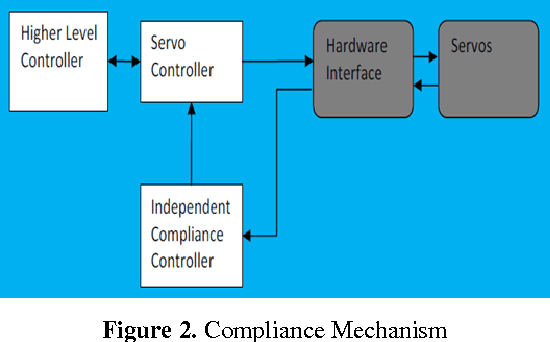
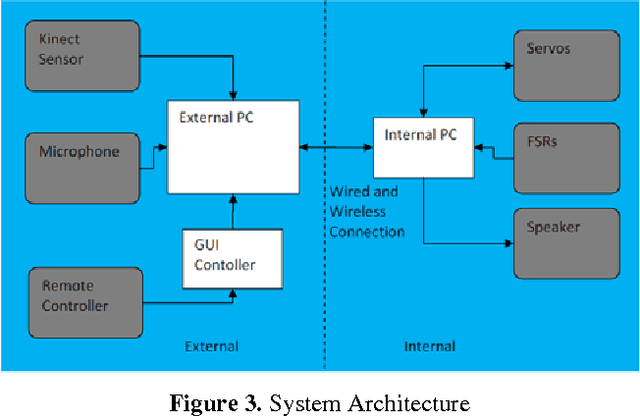

This paper investigates users' preferred interaction modalities when playing an imitation game with KASPAR, a small child-sized humanoid robot. The study involved 16 adult participants teaching the robot to mime a nursery rhyme via one of three interaction modalities in a real-time Human-Robot Interaction (HRI) experiment: voice, guiding touch and visual demonstration. The findings suggest that the users appeared to have no preference in terms of human effort for completing the task. However, there was a significant difference in human enjoyment preferences of input modality and a marginal difference in the robot's perceived ability to imitate.