 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Image Registration for Ultrasound Localization Microscopy by Obtaining Gradients via Integration Across Iterations
Jun 17, 2026Tissue motion correction through image registration is essential for ultrasound localization microscopy (ULM). Parametric image registration is commonly formulated as an optimization problem where motion parameters are iteratively updated to maximize image similarity, and used optimization algorithms typically rely on gradient information, the explicit evaluation of which can become computationally demanding. This work investigates Extremum Seeking Control (ESC) as an alternative to explicit derivative evaluation in image registration. By obtaining descent information via integrating perturbed and demodulated image similarity metric across iterations, ESC avoids differentiation of the image similarity metric with respect to motion parameters in each iteration. The classical ESC, whose optimization behavior approximates that of classical gradient descent (GD), is first compared with GD for affine image registration using simulated ground-truth motions derived from a beating ex vivo porcine heart dataset. The results show that ESC achieves registration accuracy and convergence behavior comparable to GD while reducing per-iteration computational cost by approximately 3.5-fold. ESC is subsequently employed in a two-stage motion correction pipeline, where affine registration compensates for global tissue motion and B-spline registration corrects residual local deformation. The proposed method is applied to ULM imaging of a beating ex vivo porcine heart and achieves a spatial resolution of 219 um, substantially below the half-wavelength diffraction limit of 321 um associated with 2.4 MHz diverging-wave imaging. These results demonstrate that ESC provides an effective alternative to explicit derivative evaluation in ULM image registration, enabling accurate motion correction and high-quality super-resolution imaging.
D3LM: A Discrete DNA Diffusion Language Model for Bidirectional DNA Understanding and Generation
Mar 02, 2026Early DNA foundation models adopted BERT-style training, achieving good performance on DNA understanding tasks but lacking generative capabilities. Recent autoregressive models enable DNA generation, but employ left-to-right causal modeling that is suboptimal for DNA where regulatory relationships are inherently bidirectional. We present D3LM (\textbf{D}iscrete \textbf{D}NA \textbf{D}iffusion \textbf{L}anguage \textbf{M}odel), which unifies bidirectional representation learning and DNA generation through masked diffusion. D3LM directly adopts the Nucleotide Transformer (NT) v2 architecture but reformulates the training objective as masked diffusion in discrete DNA space, enabling both bidirectional understanding and generation capabilities within a single model. Compared to NT v2 of the same size, D3LM achieves improved performance on understanding tasks. Notably, on regulatory element generation, D3LM achieves an SFID of 10.92, closely approaching real DNA sequences (7.85) and substantially outperforming the previous best result of 29.16 from autoregressive models. Our work suggests diffusion language models as a promising paradigm for unified DNA foundation models. We further present the first systematic study of masked diffusion models in the DNA domain, investigating practical design choices such as tokenization schemes and sampling strategies, thereby providing empirical insights and a solid foundation for future research. D3LM has been released at https://huggingface.co/collections/Hengchang-Liu/d3lm.
Diffusion LMs Can Approximate Optimal Infilling Lengths Implicitly
Jan 31, 2026Diffusion language models (DLMs) provide a bidirectional generation framework naturally suited for infilling, yet their performance is constrained by the pre-specified infilling length. In this paper, we reveal that DLMs possess an inherent ability to discover the correct infilling length. We identify two key statistical phenomena in the first-step denoising confidence: a local \textit{Oracle Peak} that emerges near the ground-truth length and a systematic \textit{Length Bias} that often obscures this signal. By leveraging this signal and calibrating the bias, our training-free method \textbf{CAL} (\textbf{C}alibrated \textbf{A}daptive \textbf{L}ength) enables DLMs to approximate the optimal length through an efficient search before formal decoding. Empirical evaluations demonstrate that CAL improves Pass@1 by up to 47.7\% over fixed-length baselines and 40.5\% over chat-based adaptive methods in code infilling, while boosting BLEU-2 and ROUGE-L by up to 8.5\% and 9.9\% in text infilling. These results demonstrate that CAL paves the way for robust DLM infilling without requiring any specialized training. Code is available at https://github.com/NiuHechang/Calibrated_Adaptive_Length.
RiskOracle: A Minute-level Citywide Traffic Accident Forecasting Framework
Feb 19, 2020
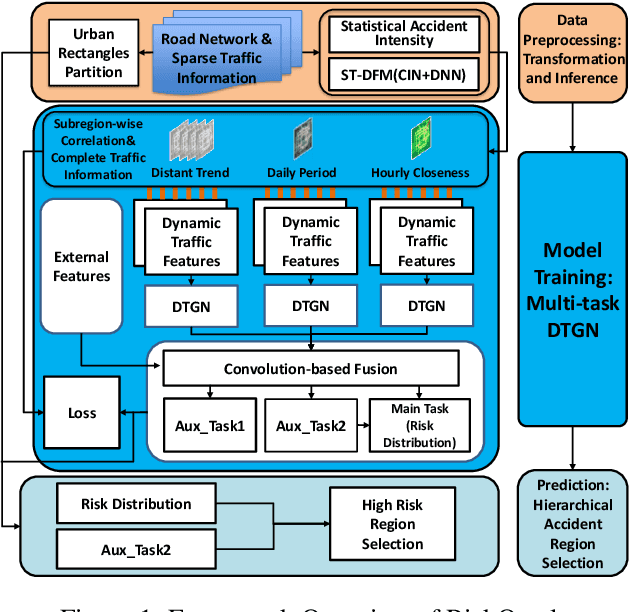
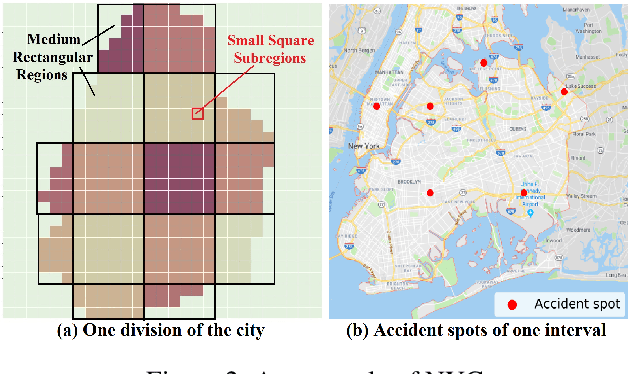
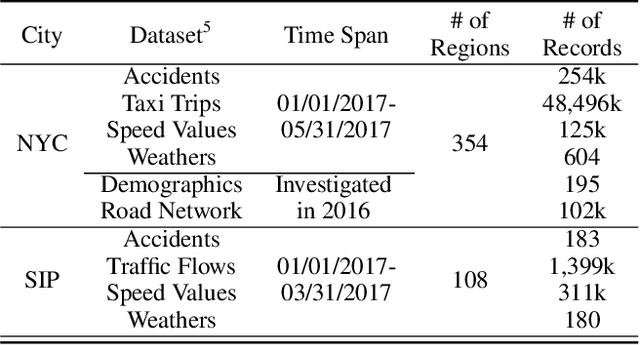
Real-time traffic accident forecasting is increasingly important for public safety and urban management (e.g., real-time safe route planning and emergency response deployment). Previous works on accident forecasting are often performed on hour levels, utilizing existed neural networks with static region-wise correlations taken into account. However, it is still challenging when the granularity of forecasting step improves as the highly dynamic nature of road network and inherent rareness of accident records in one training sample, which leads to biased results and zero-inflated issue. In this work, we propose a novel framework RiskOracle, to improve the prediction granularity to minute levels. Specifically, we first transform the zero-risk values in labels to fit the training network. Then, we propose the Differential Time-varying Graph neural network (DTGN) to capture the immediate changes of traffic status and dynamic inter-subregion correlations. Furthermore, we adopt multi-task and region selection schemes to highlight citywide most-likely accident subregions, bridging the gap between biased risk values and sporadic accident distribution. Extensive experiments on two real-world datasets demonstrate the effectiveness and scalability of our RiskOracle framework.