 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Variational Conditional-Dependence Hidden Markov Models for Human Action Recognition
Feb 13, 2020

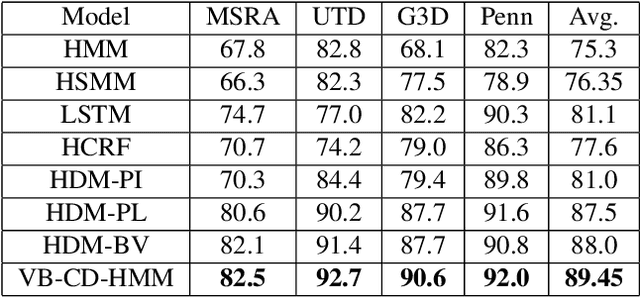
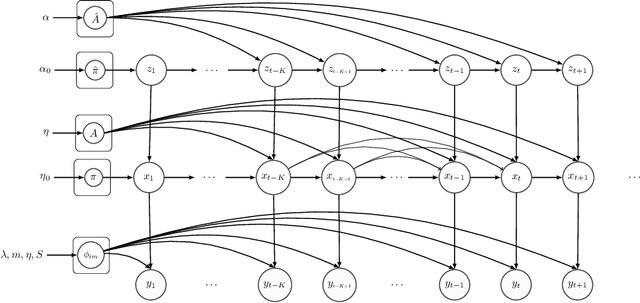

Hidden Markov Models (HMMs) are a powerful generative approach for modeling sequential data and time-series in general. However, the commonly employed assumption of the dependence of the current time frame to a single or multiple immediately preceding frames is unrealistic; more complicated dynamics potentially exist in real world scenarios. Human Action Recognition constitutes such a scenario, and has attracted increased attention with the advent of low-cost 3D sensors. The naturally arising variations and complex temporal dependencies have established this task as a challenging problem in the community. This paper revisits conventional sequential modeling approaches, aiming to address the problem of capturing time-varying temporal dependency patterns. To this end, we propose a different formulation of HMMs, whereby the dependence on past frames is dynamically inferred from the data. Specifically, we introduce a hierarchical extension by postulating an additional latent variable layer; therein, the (time-varying) temporal dependence patterns are treated as latent variables over which inference is performed. We leverage solid arguments from the Variational Bayes framework and derive a tractable inference algorithm based on the forward-backward algorithm. As we experimentally show using benchmark datasets, our approach yields competitive recognition accuracy and can effectively handle data with missing values.
Fast Bayesian Force Fields from Active Learning: Study of Inter-Dimensional Transformation of Stanene
Aug 26, 2020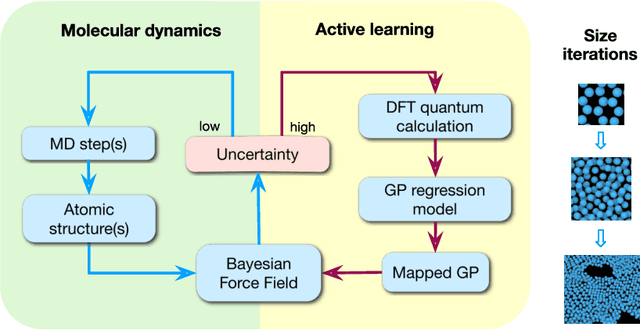
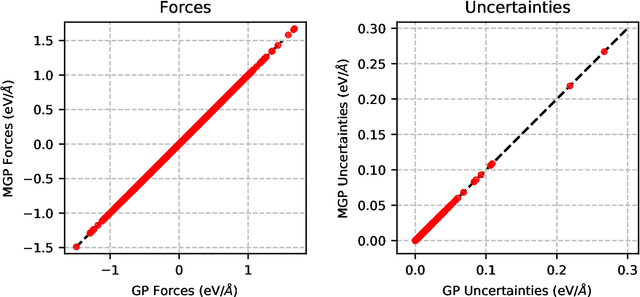
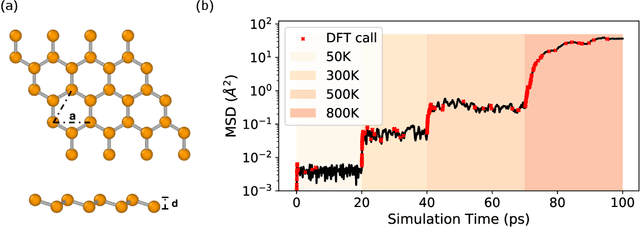
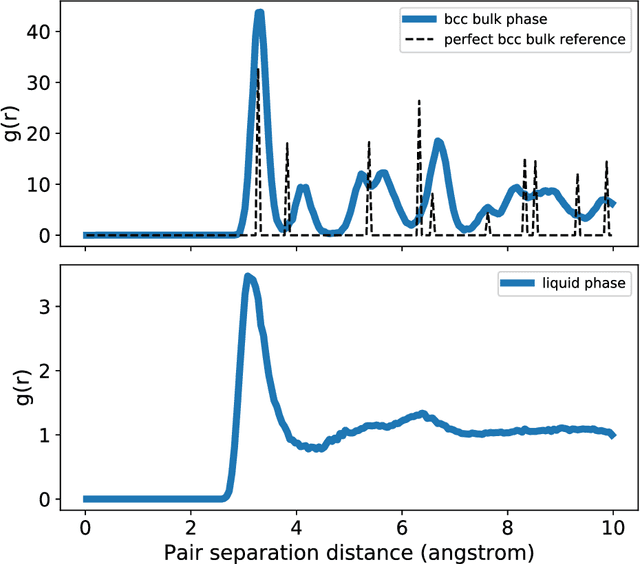
We present a way to dramatically accelerate Gaussian process models for interatomic force fields based on many-body kernels by mapping both forces and uncertainties onto functions of low-dimensional features. This allows for automated active learning of models combining near-quantum accuracy, built-in uncertainty, and constant cost of evaluation that is comparable to classical analytical models, capable of simulating millions of atoms. Using this approach, we perform large scale molecular dynamics simulations of the stability of the stanene monolayer. We discover an unusual phase transformation mechanism of 2D stanene, where ripples lead to nucleation of bilayer defects, densification into a disordered multilayer structure, followed by formation of bulk liquid at high temperature or nucleation and growth of the 3D bcc crystal at low temperature. The presented method opens possibilities for rapid development of fast accurate uncertainty-aware models for simulating long-time large-scale dynamics of complex materials.
Going to Extremes: Weakly Supervised Medical Image Segmentation
Sep 25, 2020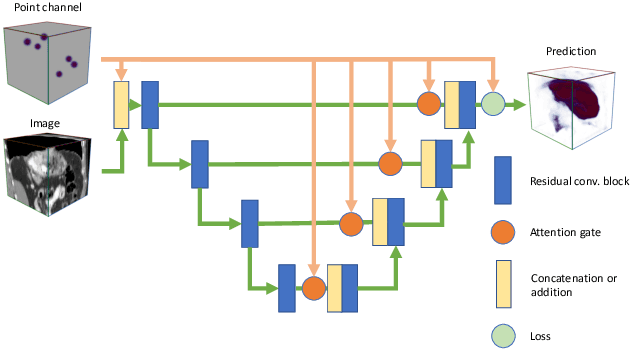
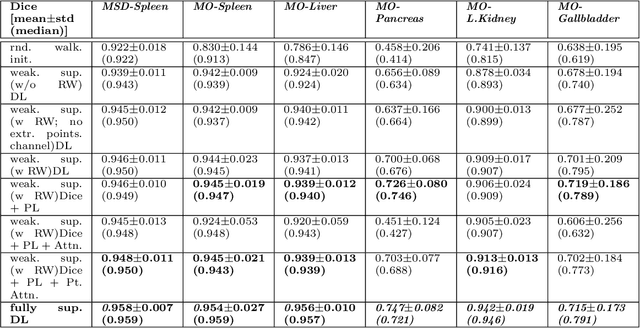
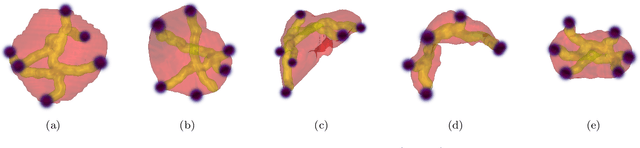

Medical image annotation is a major hurdle for developing precise and robust machine learning models. Annotation is expensive, time-consuming, and often requires expert knowledge, particularly in the medical field. Here, we suggest using minimal user interaction in the form of extreme point clicks to train a segmentation model which, in effect, can be used to speed up medical image annotation. An initial segmentation is generated based on the extreme points utilizing the random walker algorithm. This initial segmentation is then used as a noisy supervision signal to train a fully convolutional network that can segment the organ of interest, based on the provided user clicks. Through experimentation on several medical imaging datasets, we show that the predictions of the network can be refined using several rounds of training with the prediction from the same weakly annotated data. Further improvements are shown utilizing the clicked points within a custom-designed loss and attention mechanism. Our approach has the potential to speed up the process of generating new training datasets for the development of new machine learning and deep learning-based models for, but not exclusively, medical image analysis.
Semi-supervised Federated Learning for Activity Recognition
Nov 06, 2020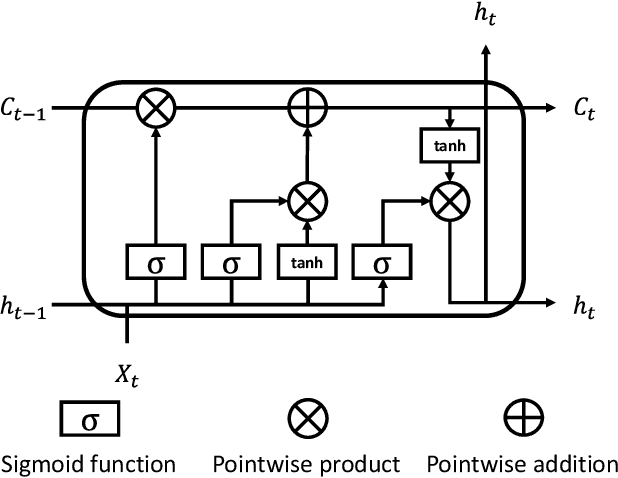
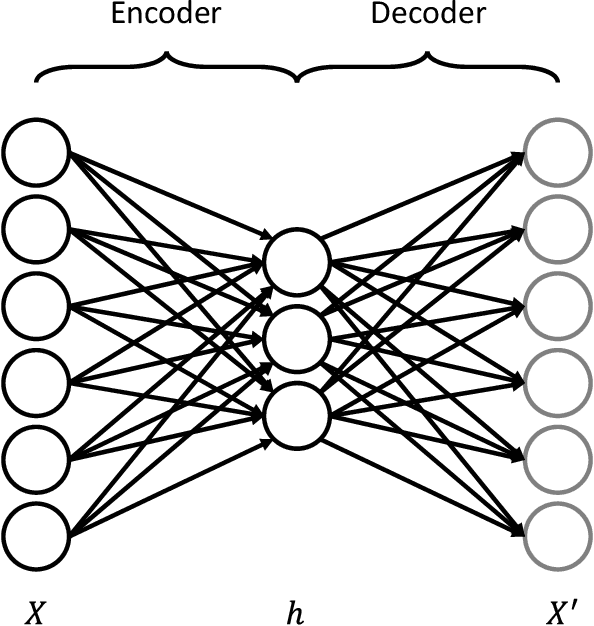

The proliferation of IoT sensors and edge devices makes it possible to use deep learning models to recognise daily activities locally using in-home monitoring technologies. Recently, federated learning systems that use edge devices as clients to collect and utilise IoT sensory data for human activity recognition have been commonly used as a new way to combine local (individual-level) and global (group-level) models. This approach provides better scalability and generalisability and also offers higher privacy compared with the traditional centralised analysis and learning models. The assumption behind federated learning, however, relies on supervised learning on clients. This requires a large volume of labelled data, which is difficult to collect in uncontrolled IoT environments such as remote in-home monitoring. In this paper, we propose an activity recognition system that uses semi-supervised federated learning, wherein clients conduct unsupervised learning on autoencoders with unlabelled local data to learn general representations, and a cloud server conducts supervised learning on an activity classifier with labelled data. Our experimental results show that using autoencoders and a long short-term memory (LSTM) classifier, the accuracy of our proposed system is comparable to that of a supervised federated learning system. Meanwhile, we demonstrate that our system is not affected by the Non-IID distribution of local data, and can even achieve better accuracy than supervised federated learning on some datasets. Additionally, we show that our proposed system can reduce the number of needed labels in the system and the size of local models without losing much accuracy, and has shorter local activity recognition time than supervised federated learning.
Multi-Modal Retrieval using Graph Neural Networks
Oct 04, 2020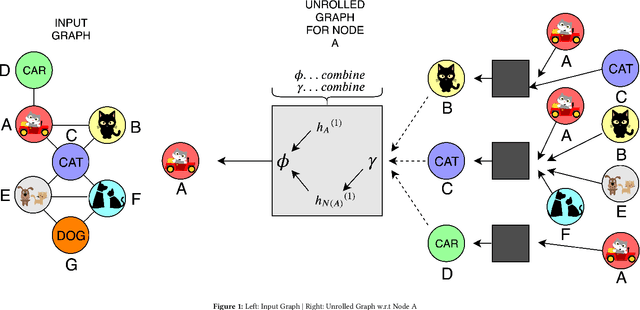

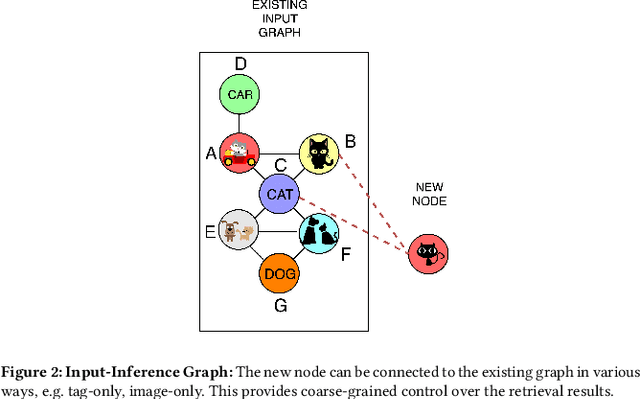

Most real world applications of image retrieval such as Adobe Stock, which is a marketplace for stock photography and illustrations, need a way for users to find images which are both visually (i.e. aesthetically) and conceptually (i.e. containing the same salient objects) as a query image. Learning visual-semantic representations from images is a well studied problem for image retrieval. Filtering based on image concepts or attributes is traditionally achieved with index-based filtering (e.g. on textual tags) or by re-ranking after an initial visual embedding based retrieval. In this paper, we learn a joint vision and concept embedding in the same high-dimensional space. This joint model gives the user fine-grained control over the semantics of the result set, allowing them to explore the catalog of images more rapidly. We model the visual and concept relationships as a graph structure, which captures the rich information through node neighborhood. This graph structure helps us learn multi-modal node embeddings using Graph Neural Networks. We also introduce a novel inference time control, based on selective neighborhood connectivity allowing the user control over the retrieval algorithm. We evaluate these multi-modal embeddings quantitatively on the downstream relevance task of image retrieval on MS-COCO dataset and qualitatively on MS-COCO and an Adobe Stock dataset.
Optimization of XNOR Convolution for Binary Convolutional Neural Networks on GPU
Jul 28, 2020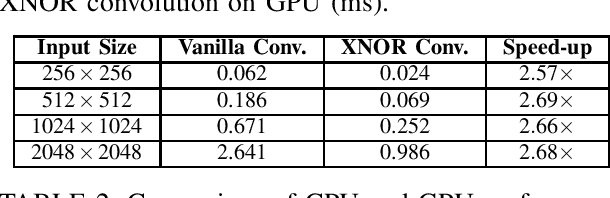
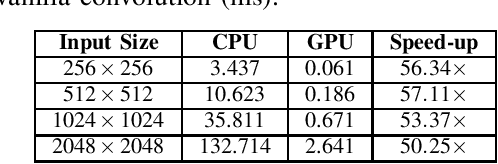
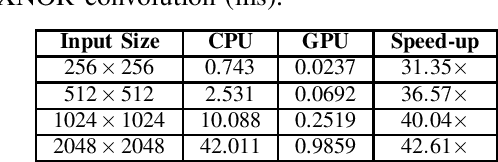
Binary convolutional networks have lower computational load and lower memory foot-print compared to their full-precision counterparts. So, they are a feasible alternative for the deployment of computer vision applications on limited capacity embedded devices. Once trained on less resource-constrained computational environments, they can be deployed for real-time inference on such devices. In this study, we propose an implementation of binary convolutional network inference on GPU by focusing on optimization of XNOR convolution. Experimental results show that using GPU can provide a speed-up of up to $42.61\times$ with a kernel size of $3\times3$. The implementation is publicly available at https://github.com/metcan/Binary-Convolutional-Neural-Network-Inference-on-GPU
Provable Acceleration of Neural Net Training via Polyak's Momentum
Oct 04, 2020
Incorporating a so-called "momentum" dynamic in gradient descent methods is widely used in neural net training as it has been broadly observed that, at least empirically, it often leads to significantly faster convergence. At the same time, there are very few theoretical guarantees in the literature to explain this apparent acceleration effect. In this paper we show that Polyak's momentum, in combination with over-parameterization of the model, helps achieve faster convergence in training a one-layer ReLU network on $n$ examples. We show specifically that gradient descent with Polyak's momentum decreases the initial training error at a rate much faster than that of vanilla gradient descent. We provide a bound for a fixed sample size $n$, and we show that gradient descent with Polyak's momentum converges at an accelerated rate to a small error that is controllable by the number of neurons $m$. Prior work [DZPS19] showed that using vanilla gradient descent, and with a similar method of over-parameterization, the error decays as $(1-\kappa_n)^t$ after $t$ iterations, where $\kappa_n$ is a problem-specific parameter. Our result shows that with the appropriate choice of parameters one has a rate of $(1-\sqrt{\kappa_n})^t$. This work establishes that momentum does indeed speed up neural net training.
Expedited Multi-Target Search with Guaranteed Performance via Multi-fidelity Gaussian Processes
May 18, 2020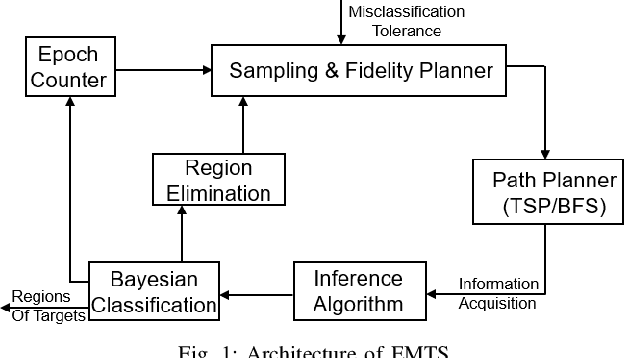
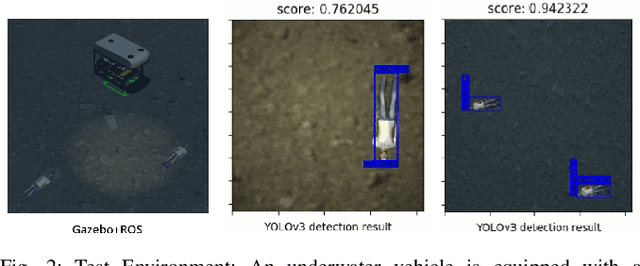
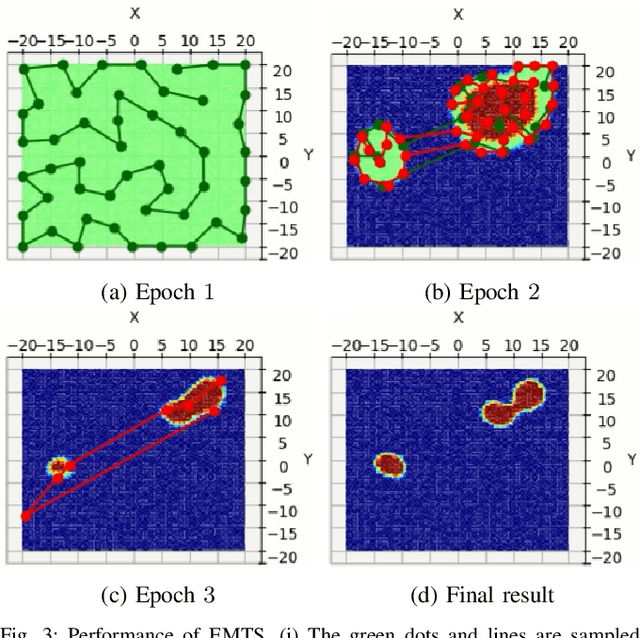
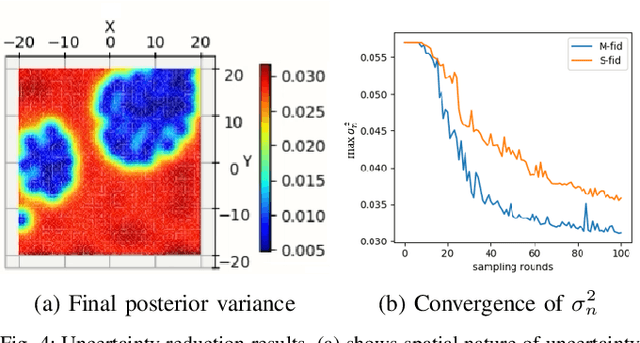
We consider a scenario in which an autonomous vehicle equipped with a downward facing camera operates in a 3D environment and is tasked with searching for an unknown number of stationary targets on the 2D floor of the environment. The key challenge is to minimize the search time while ensuring a high detection accuracy. We model the sensing field using a multi-fidelity Gaussian process that systematically describes the sensing information available at different altitudes from the floor. Based on the sensing model, we design a novel algorithm called Expedited Multi-Target Search (EMTS) that (i) addresses the coverage-accuracy trade-off: sampling at locations farther from the floor provides wider field of view but less accurate measurements, (ii) computes an occupancy map of the floor within a prescribed accuracy and quickly eliminates unoccupied regions from the search space, and (iii) travels efficiently to collect the required samples for target detection. We rigorously analyze the algorithm and establish formal guarantees on the target detection accuracy and the expected detection time. We illustrate the algorithm using a simulated multi-target search scenario.
Automatic Assignment of Radiology Examination Protocols Using Pre-trained Language Models with Knowledge Distillation
Sep 01, 2020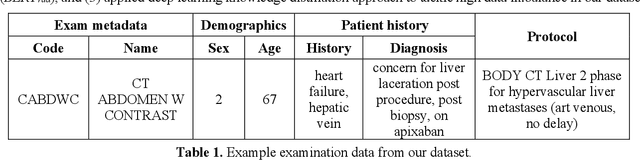
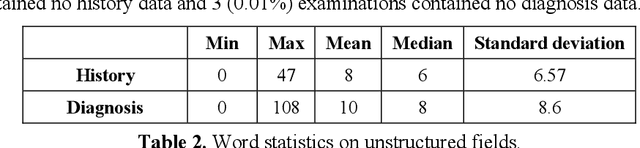
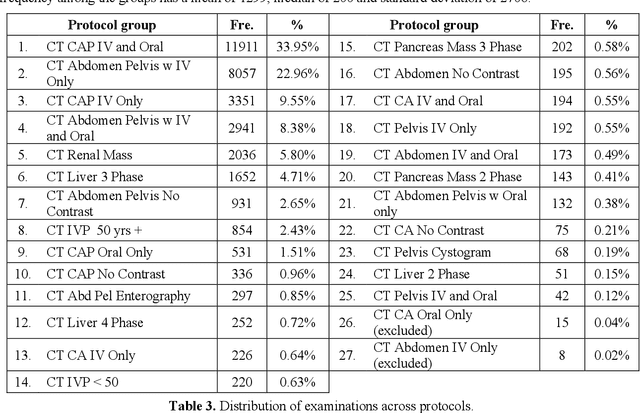
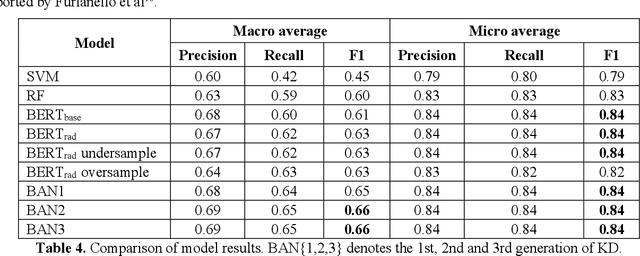
Selecting radiology examination protocol is a repetitive, error-prone, and time-consuming process. In this paper, we present a deep learning approach to automatically assign protocols to computer tomography examinations, by pre-training a domain-specific BERT model ($BERT_{rad}$). To handle the high data imbalance across exam protocols, we used a knowledge distillation approach that up-sampled the minority classes through data augmentation. We compared classification performance of the described approach with the statistical n-gram models using Support Vector Machine (SVM) and Random Forest (RF) classifiers, as well as the Google's $BERT_{base}$ model. SVM and RF achieved macro-averaged F1 scores of 0.45 and 0.6 while $BERT_{base}$ and $BERT_{rad}$ achieved 0.61 and 0.63. Knowledge distillation improved overall performance on the minority classes, achieving a F1 score of 0.66. Additionally, by choosing the optimal threshold, the BERT models could classify over 50% of test samples within 5% error rate and potentially alleviate half of radiologist protocoling workload.
Hybrid Attention Networks for Flow and Pressure Forecasting in Water Distribution Systems
Apr 14, 2020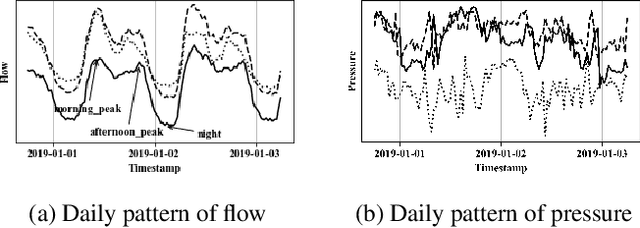
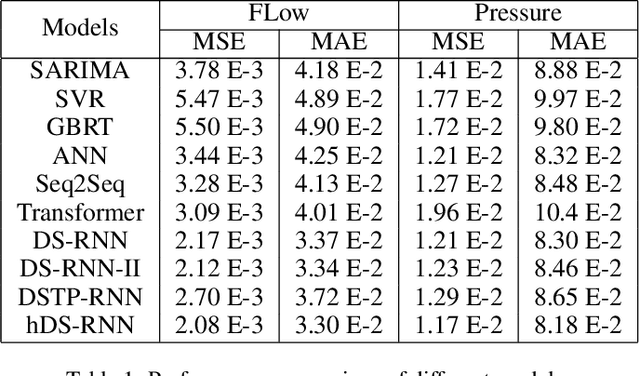
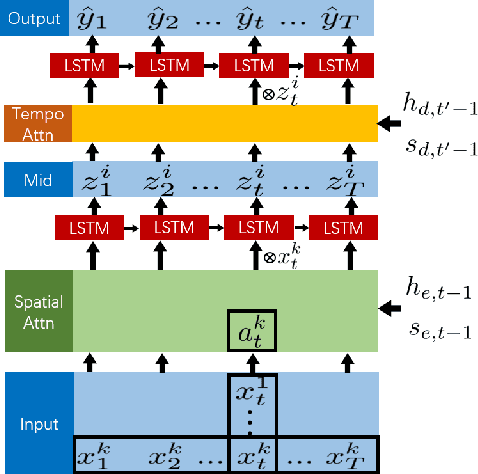
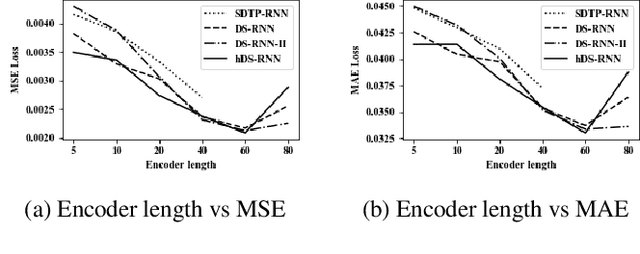
Multivariate geo-sensory time series prediction is challenging because of the complex spatial and temporal correlation. In urban water distribution systems (WDS), numerous spatial-correlated sensors have been deployed to continuously collect hydraulic data. Forecasts of monitored flow and pressure time series are of vital importance for operational decision making, alerts and anomaly detection. To address this issue, we proposed a hybrid dual-stage spatial-temporal attention-based recurrent neural networks (hDS-RNN). Our model consists of two stages: a spatial attention-based encoder and a temporal attention-based decoder. Specifically, a hybrid spatial attention mechanism that employs inputs along temporal and spatial axes is proposed. Experiments on a real-world dataset are conducted and demonstrate that our model outperformed 9 baseline models in flow and pressure series prediction in WDS.