 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaze Prediction in Virtual Reality Without Eye Tracking Using Visual and Head Motion Cues
Jan 26, 2026Gaze prediction plays a critical role in Virtual Reality (VR) applications by reducing sensor-induced latency and enabling computationally demanding techniques such as foveated rendering, which rely on anticipating user attention. However, direct eye tracking is often unavailable due to hardware limitations or privacy concerns. To address this, we present a novel gaze prediction framework that combines Head-Mounted Display (HMD) motion signals with visual saliency cues derived from video frames. Our method employs UniSal, a lightweight saliency encoder, to extract visual features, which are then fused with HMD motion data and processed through a time-series prediction module. We evaluate two lightweight architectures, TSMixer and LSTM, for forecasting future gaze directions. Experiments on the EHTask dataset, along with deployment on commercial VR hardware, show that our approach consistently outperforms baselines such as Center-of-HMD and Mean Gaze. These results demonstrate the effectiveness of predictive gaze modeling in reducing perceptual lag and enhancing natural interaction in VR environments where direct eye tracking is constrained.
Transformers with Stochastic Competition for Tabular Data Modelling
Jul 18, 2024Despite the prevalence and significance of tabular data across numerous industries and fields, it has been relatively underexplored in the realm of deep learning. Even today, neural networks are often overshadowed by techniques such as gradient boosted decision trees (GBDT). However, recent models are beginning to close this gap, outperforming GBDT in various setups and garnering increased attention in the field. Inspired by this development, we introduce a novel stochastic deep learning model specifically designed for tabular data. The foundation of this model is a Transformer-based architecture, carefully adapted to cater to the unique properties of tabular data through strategic architectural modifications and leveraging two forms of stochastic competition. First, we employ stochastic "Local Winner Takes All" units to promote generalization capacity through stochasticity and sparsity. Second, we introduce a novel embedding layer that selects among alternative linear embedding layers through a mechanism of stochastic competition. The effectiveness of the model is validated on a variety of widely-used, publicly available datasets. We demonstrate that, through the incorporation of these elements, our model yields high performance and marks a significant advancement in the application of deep learning to tabular data.
Continual Deep Learning on the Edge via Stochastic Local Competition among Subnetworks
Jul 15, 2024



Continual learning on edge devices poses unique challenges due to stringent resource constraints. This paper introduces a novel method that leverages stochastic competition principles to promote sparsity, significantly reducing deep network memory footprint and computational demand. Specifically, we propose deep networks that comprise blocks of units that compete locally to win the representation of each arising new task; competition takes place in a stochastic manner. This type of network organization results in sparse task-specific representations from each network layer; the sparsity pattern is obtained during training and is different among tasks. Crucially, our method sparsifies both the weights and the weight gradients, thus facilitating training on edge devices. This is performed on the grounds of winning probability for each unit in a block. During inference, the network retains only the winning unit and zeroes-out all weights pertaining to non-winning units for the task at hand. Thus, our approach is specifically tailored for deployment on edge devices, providing an efficient and scalable solution for continual learning in resource-limited environments.
DISCOVER: Making Vision Networks Interpretable via Competition and Dissection
Oct 07, 2023



Modern deep networks are highly complex and their inferential outcome very hard to interpret. This is a serious obstacle to their transparent deployment in safety-critical or bias-aware applications. This work contributes to post-hoc interpretability, and specifically Network Dissection. Our goal is to present a framework that makes it easier to discover the individual functionality of each neuron in a network trained on a vision task; discovery is performed in terms of textual description generation. To achieve this objective, we leverage: (i) recent advances in multimodal vision-text models and (ii) network layers founded upon the novel concept of stochastic local competition between linear units. In this setting, only a small subset of layer neurons are activated for a given input, leading to extremely high activation sparsity (as low as only $\approx 4\%$). Crucially, our proposed method infers (sparse) neuron activation patterns that enables the neurons to activate/specialize to inputs with specific characteristics, diversifying their individual functionality. This capacity of our method supercharges the potential of dissection processes: human understandable descriptions are generated only for the very few active neurons, thus facilitating the direct investigation of the network's decision process. As we experimentally show, our approach: (i) yields Vision Networks that retain or improve classification performance, and (ii) realizes a principled framework for text-based description and examination of the generated neuronal representations.
A New Dataset for End-to-End Sign Language Translation: The Greek Elementary School Dataset
Oct 07, 2023



Automatic Sign Language Translation (SLT) is a research avenue of great societal impact. End-to-End SLT facilitates the interaction of Hard-of-Hearing (HoH) with hearing people, thus improving their social life and opportunities for participation in social life. However, research within this frame of reference is still in its infancy, and current resources are particularly limited. Existing SLT methods are either of low translation ability or are trained and evaluated on datasets of restricted vocabulary and questionable real-world value. A characteristic example is Phoenix2014T benchmark dataset, which only covers weather forecasts in German Sign Language. To address this shortage of resources, we introduce a newly constructed collection of 29653 Greek Sign Language video-translation pairs which is based on the official syllabus of Greek Elementary School. Our dataset covers a wide range of subjects. We use this novel dataset to train recent state-of-the-art Transformer-based methods widely used in SLT research. Our results demonstrate the potential of our introduced dataset to advance SLT research by offering a favourable balance between usability and real-world value.
* ICCVW2023 - ACVR
Stochastic Deep Networks with Linear Competing Units for Model-Agnostic Meta-Learning
Aug 02, 2022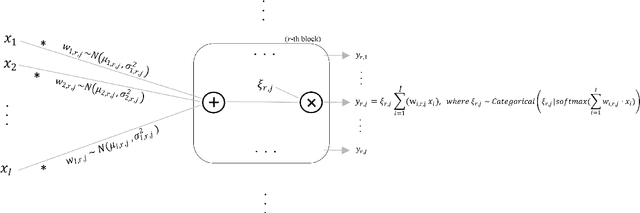
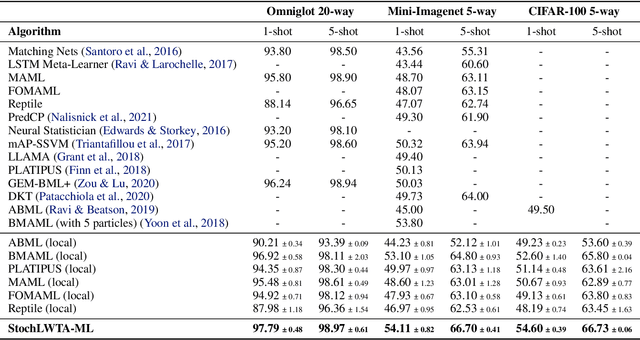
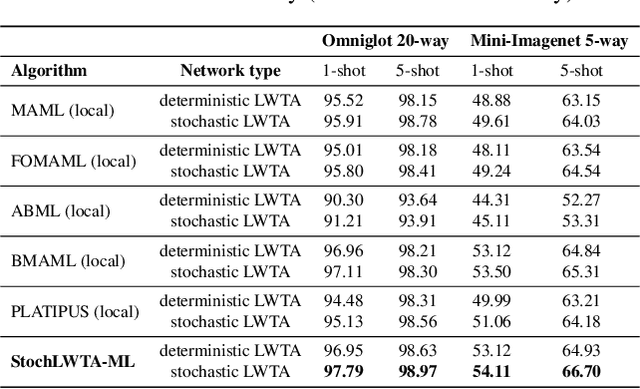
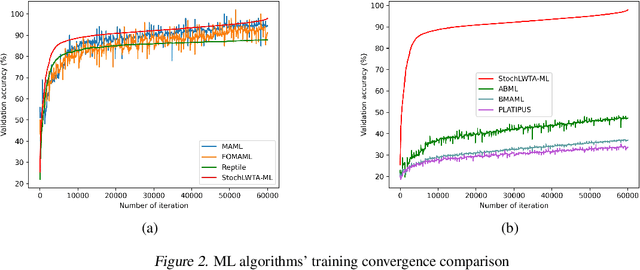
This work addresses meta-learning (ML) by considering deep networks with stochastic local winner-takes-all (LWTA) activations. This type of network units results in sparse representations from each model layer, as the units are organized into blocks where only one unit generates a non-zero output. The main operating principle of the introduced units rely on stochastic principles, as the network performs posterior sampling over competing units to select the winner. Therefore, the proposed networks are explicitly designed to extract input data representations of sparse stochastic nature, as opposed to the currently standard deterministic representation paradigm. Our approach produces state-of-the-art predictive accuracy on few-shot image classification and regression experiments, as well as reduced predictive error on an active learning setting; these improvements come with an immensely reduced computational cost.
* Proc. ICML 2022
Rethinking Bayesian Learning for Data Analysis: The Art of Prior and Inference in Sparsity-Aware Modeling
May 28, 2022
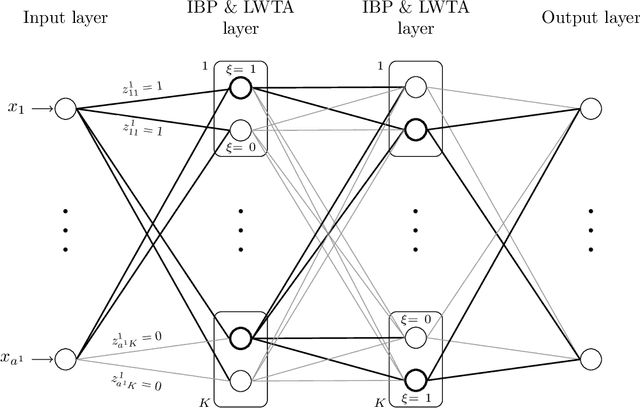
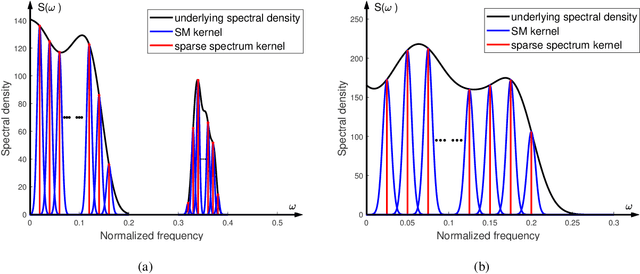
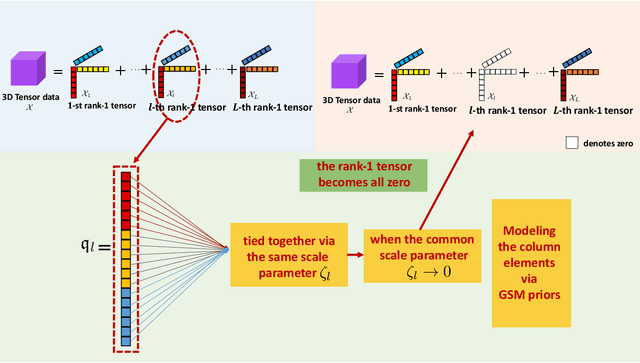
Sparse modeling for signal processing and machine learning has been at the focus of scientific research for over two decades. Among others, supervised sparsity-aware learning comprises two major paths paved by: a) discriminative methods and b) generative methods. The latter, more widely known as Bayesian methods, enable uncertainty evaluation w.r.t. the performed predictions. Furthermore, they can better exploit related prior information and naturally introduce robustness into the model, due to their unique capacity to marginalize out uncertainties related to the parameter estimates. Moreover, hyper-parameters associated with the adopted priors can be learnt via the training data. To implement sparsity-aware learning, the crucial point lies in the choice of the function regularizer for discriminative methods and the choice of the prior distribution for Bayesian learning. Over the last decade or so, due to the intense research on deep learning, emphasis has been put on discriminative techniques. However, a come back of Bayesian methods is taking place that sheds new light on the design of deep neural networks, which also establish firm links with Bayesian models and inspire new paths for unsupervised learning, such as Bayesian tensor decomposition. The goal of this article is two-fold. First, to review, in a unified way, some recent advances in incorporating sparsity-promoting priors into three highly popular data modeling tools, namely deep neural networks, Gaussian processes, and tensor decomposition. Second, to review their associated inference techniques from different aspects, including: evidence maximization via optimization and variational inference methods. Challenges such as small data dilemma, automatic model structure search, and natural prediction uncertainty evaluation are also discussed. Typical signal processing and machine learning tasks are demonstrated.
Competing Mutual Information Constraints with Stochastic Competition-based Activations for Learning Diversified Representations
Jan 10, 2022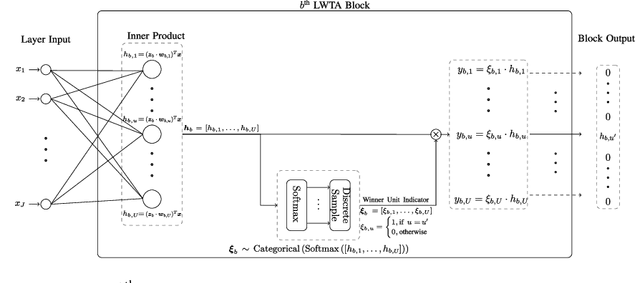
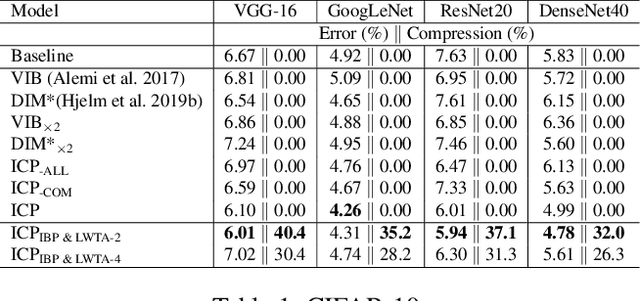
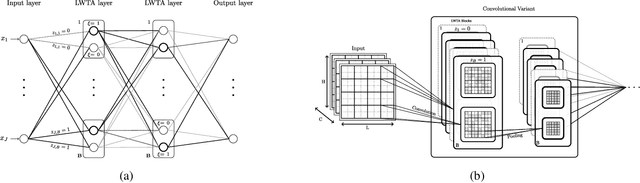
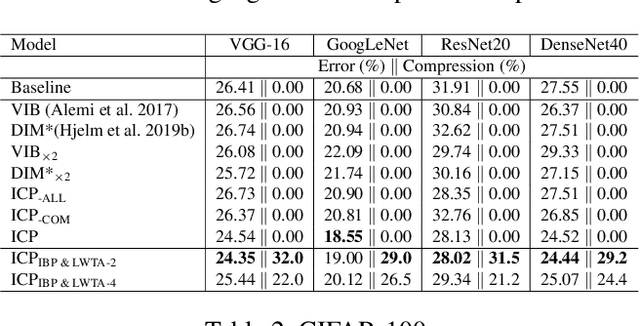
This work aims to address the long-established problem of learning diversified representations. To this end, we combine information-theoretic arguments with stochastic competition-based activations, namely Stochastic Local Winner-Takes-All (LWTA) units. In this context, we ditch the conventional deep architectures commonly used in Representation Learning, that rely on non-linear activations; instead, we replace them with sets of locally and stochastically competing linear units. In this setting, each network layer yields sparse outputs, determined by the outcome of the competition between units that are organized into blocks of competitors. We adopt stochastic arguments for the competition mechanism, which perform posterior sampling to determine the winner of each block. We further endow the considered networks with the ability to infer the sub-part of the network that is essential for modeling the data at hand; we impose appropriate stick-breaking priors to this end. To further enrich the information of the emerging representations, we resort to information-theoretic principles, namely the Information Competing Process (ICP). Then, all the components are tied together under the stochastic Variational Bayes framework for inference. We perform a thorough experimental investigation for our approach using benchmark datasets on image classification. As we experimentally show, the resulting networks yield significant discriminative representation learning abilities. In addition, the introduced paradigm allows for a principled investigation mechanism of the emerging intermediate network representations.
Stochastic Local Winner-Takes-All Networks Enable Profound Adversarial Robustness
Dec 05, 2021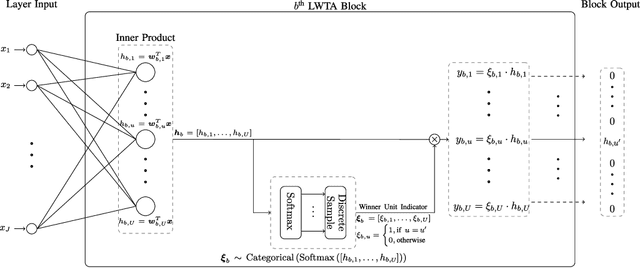
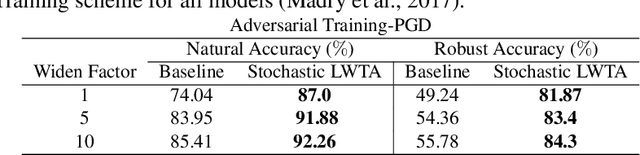
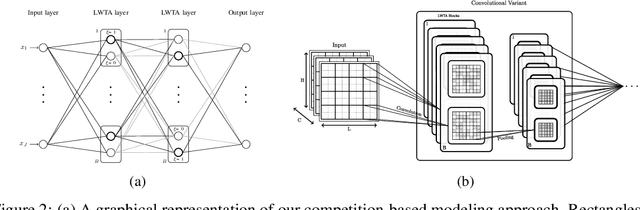
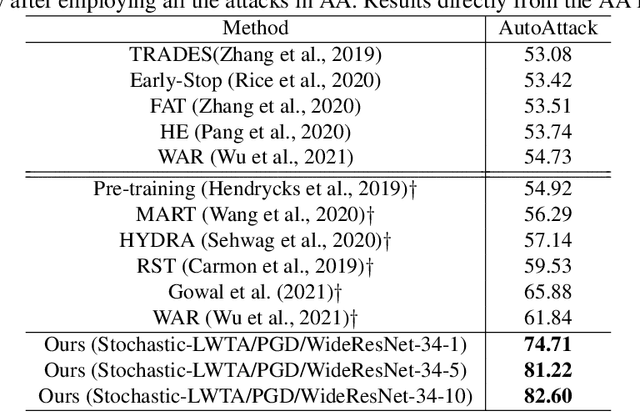
This work explores the potency of stochastic competition-based activations, namely Stochastic Local Winner-Takes-All (LWTA), against powerful (gradient-based) white-box and black-box adversarial attacks; we especially focus on Adversarial Training settings. In our work, we replace the conventional ReLU-based nonlinearities with blocks comprising locally and stochastically competing linear units. The output of each network layer now yields a sparse output, depending on the outcome of winner sampling in each block. We rely on the Variational Bayesian framework for training and inference; we incorporate conventional PGD-based adversarial training arguments to increase the overall adversarial robustness. As we experimentally show, the arising networks yield state-of-the-art robustness against powerful adversarial attacks while retaining very high classification rate in the benign case.
Stochastic Transformer Networks with Linear Competing Units: Application to end-to-end SL Translation
Oct 01, 2021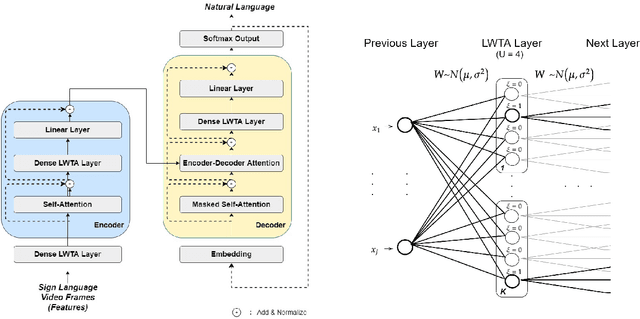
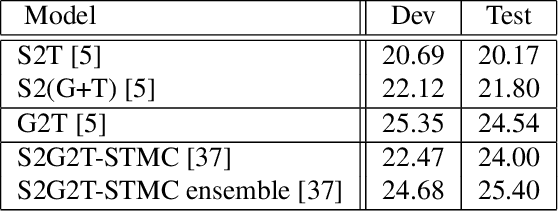


Automating sign language translation (SLT) is a challenging real world application. Despite its societal importance, though, research progress in the field remains rather poor. Crucially, existing methods that yield viable performance necessitate the availability of laborious to obtain gloss sequence groundtruth. In this paper, we attenuate this need, by introducing an end-to-end SLT model that does not entail explicit use of glosses; the model only needs text groundtruth. This is in stark contrast to existing end-to-end models that use gloss sequence groundtruth, either in the form of a modality that is recognized at an intermediate model stage, or in the form of a parallel output process, jointly trained with the SLT model. Our approach constitutes a Transformer network with a novel type of layers that combines: (i) local winner-takes-all (LWTA) layers with stochastic winner sampling, instead of conventional ReLU layers, (ii) stochastic weights with posterior distributions estimated via variational inference, and (iii) a weight compression technique at inference time that exploits estimated posterior variance to perform massive, almost lossless compression. We demonstrate that our approach can reach the currently best reported BLEU-4 score on the PHOENIX 2014T benchmark, but without making use of glosses for model training, and with a memory footprint reduced by more than 70%.