 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaymo Driverless Car Data Analysis and Driving Modeling using CNN and LSTM
Apr 29, 2025Self driving cars has been the biggest innovation in the automotive industry, but to achieve human level accuracy or near human level accuracy is the biggest challenge that research scientists are facing today. Unlike humans autonomous vehicles do not work on instincts rather they make a decision based on the training data that has been fed to them using machine learning models using which they can make decisions in different conditions they face in the real world. With the advancements in machine learning especially deep learning the self driving car research skyrocketed. In this project we have presented multiple ways to predict acceleration of the autonomous vehicle using Waymo's open dataset. Our main approach was to using CNN to mimic human action and LSTM to treat this as a time series problem.
Multi-Modal Retrieval using Graph Neural Networks
Oct 04, 2020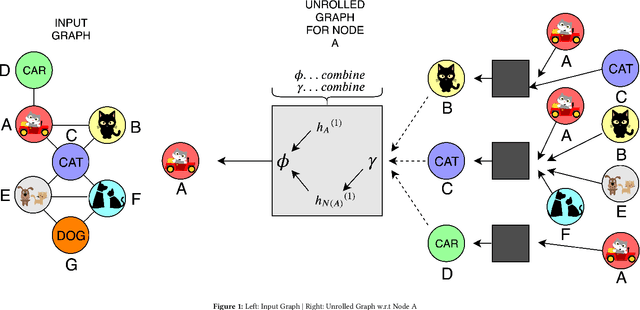

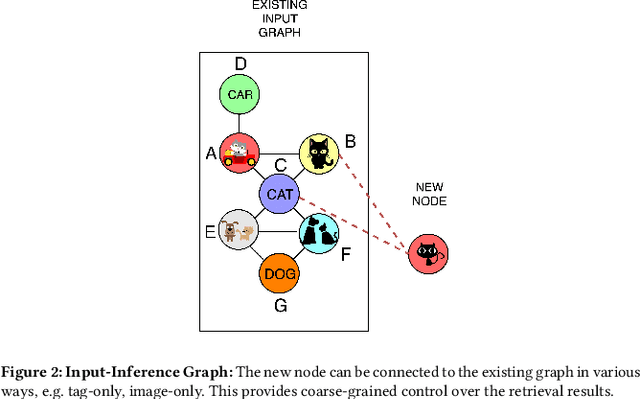

Most real world applications of image retrieval such as Adobe Stock, which is a marketplace for stock photography and illustrations, need a way for users to find images which are both visually (i.e. aesthetically) and conceptually (i.e. containing the same salient objects) as a query image. Learning visual-semantic representations from images is a well studied problem for image retrieval. Filtering based on image concepts or attributes is traditionally achieved with index-based filtering (e.g. on textual tags) or by re-ranking after an initial visual embedding based retrieval. In this paper, we learn a joint vision and concept embedding in the same high-dimensional space. This joint model gives the user fine-grained control over the semantics of the result set, allowing them to explore the catalog of images more rapidly. We model the visual and concept relationships as a graph structure, which captures the rich information through node neighborhood. This graph structure helps us learn multi-modal node embeddings using Graph Neural Networks. We also introduce a novel inference time control, based on selective neighborhood connectivity allowing the user control over the retrieval algorithm. We evaluate these multi-modal embeddings quantitatively on the downstream relevance task of image retrieval on MS-COCO dataset and qualitatively on MS-COCO and an Adobe Stock dataset.