 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PAN: Towards Fast Action Recognition via Learning Persistence of Appearance
Aug 08, 2020
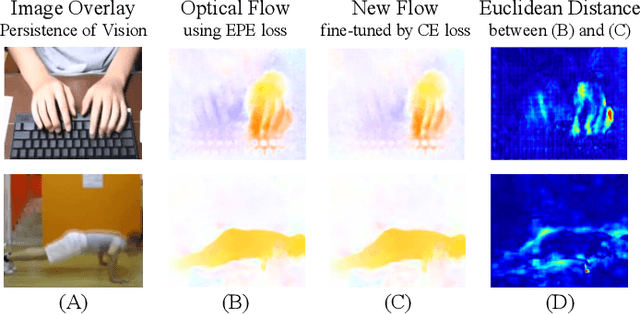
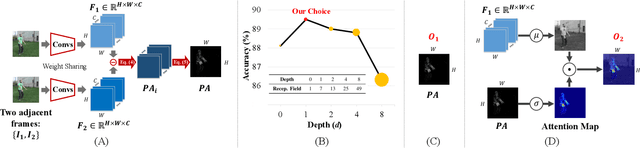
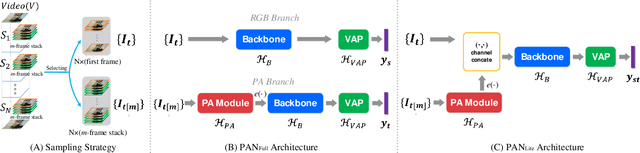
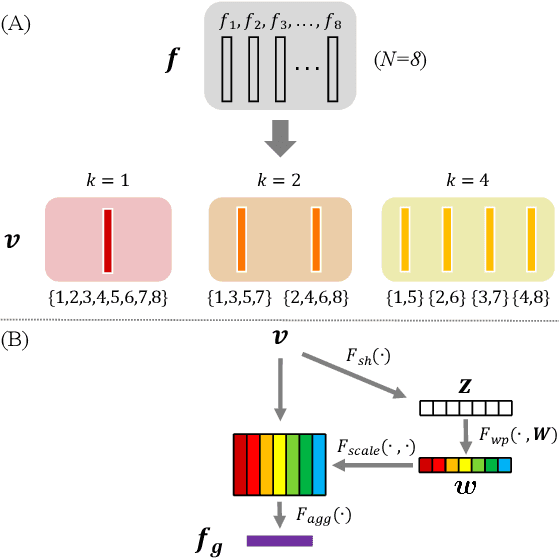
Efficiently modeling dynamic motion information in videos is crucial for action recognition task. Most state-of-the-art methods heavily rely on dense optical flow as motion representation. Although combining optical flow with RGB frames as input can achieve excellent recognition performance, the optical flow extraction is very time-consuming. This undoubtably will count against real-time action recognition. In this paper, we shed light on fast action recognition by lifting the reliance on optical flow. Our motivation lies in the observation that small displacements of motion boundaries are the most critical ingredients for distinguishing actions, so we design a novel motion cue called Persistence of Appearance (PA). In contrast to optical flow, our PA focuses more on distilling the motion information at boundaries. Also, it is more efficient by only accumulating pixel-wise differences in feature space, instead of using exhaustive patch-wise search of all the possible motion vectors. Our PA is over 1000x faster (8196fps vs. 8fps) than conventional optical flow in terms of motion modeling speed. To further aggregate the short-term dynamics in PA to long-term dynamics, we also devise a global temporal fusion strategy called Various-timescale Aggregation Pooling (VAP) that can adaptively model long-range temporal relationships across various timescales. We finally incorporate the proposed PA and VAP to form a unified framework called Persistent Appearance Network (PAN) with strong temporal modeling ability. Extensive experiments on six challenging action recognition benchmarks verify that our PAN outperforms recent state-of-the-art methods at low FLOPs. Codes and models are available at: https://github.com/zhang-can/PAN-PyTorch.
Encode the Unseen: Predictive Video Hashing for Scalable Mid-Stream Retrieval
Oct 02, 2020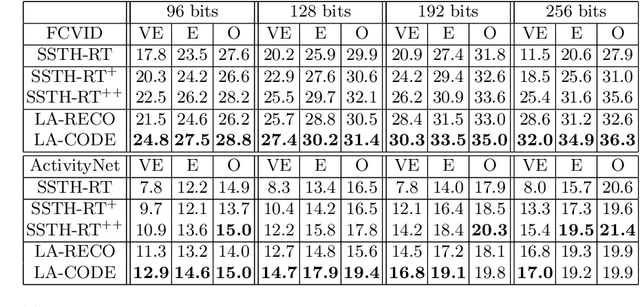
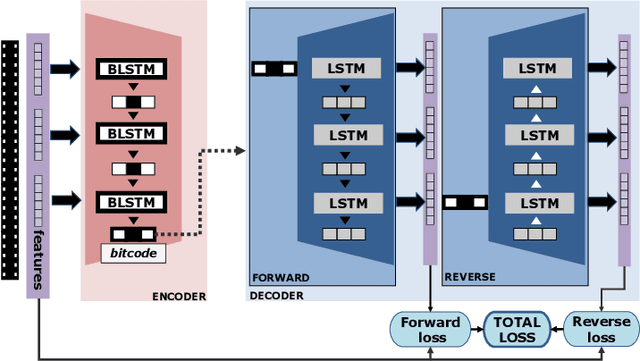
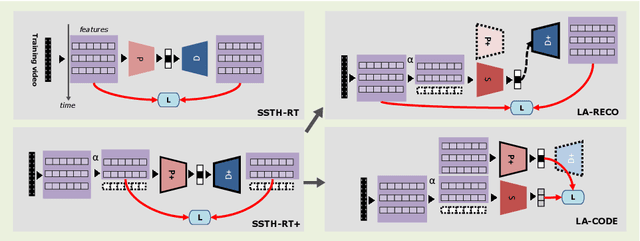

This paper tackles a new problem in computer vision: mid-stream video-to-video retrieval. This task, which consists in searching a database for content similar to a video right as it is playing, e.g. from a live stream, exhibits challenging characteristics. Only the beginning part of the video is available as query and new frames are constantly added as the video plays out. To perform retrieval in this demanding situation, we propose an approach based on a binary encoder that is both predictive and incremental in order to (1) account for the missing video content at query time and (2) keep up with repeated, continuously evolving queries throughout the streaming. In particular, we present the first hashing framework that infers the unseen future content of a currently playing video. Experiments on FCVID and ActivityNet demonstrate the feasibility of this task. Our approach also yields a significant mAP@20 performance increase compared to a baseline adapted from the literature for this task, for instance 7.4% (2.6%) increase at 20% (50%) of elapsed runtime on FCVID using bitcodes of size 192 bits.
SemEval-2020 Task 1: Unsupervised Lexical Semantic Change Detection
Jul 22, 2020
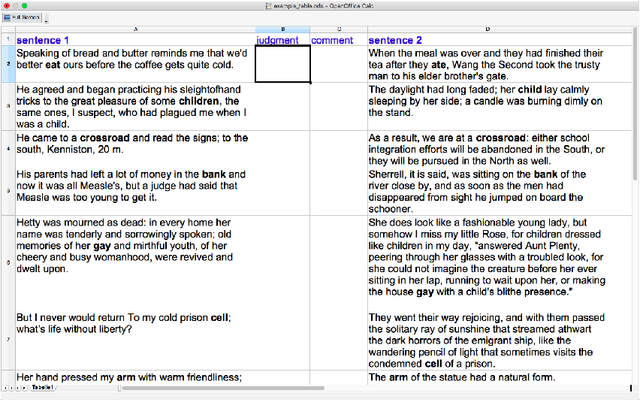
Lexical Semantic Change detection, i.e., the task of identifying words that change meaning over time, is a very active research area, with applications in NLP, lexicography, and linguistics. Evaluation is currently the most pressing problem in Lexical Semantic Change detection, as no gold standards are available to the community, which hinders progress. We present the results of the first shared task that addresses this gap by providing researchers with an evaluation framework and manually annotated, high-quality datasets for English, German, Latin, and Swedish. 33 teams submitted 186 systems, which were evaluated on two subtasks.
Dynamic Nonparametric Edge-Clustering Model for Time-Evolving Sparse Networks
May 28, 2019
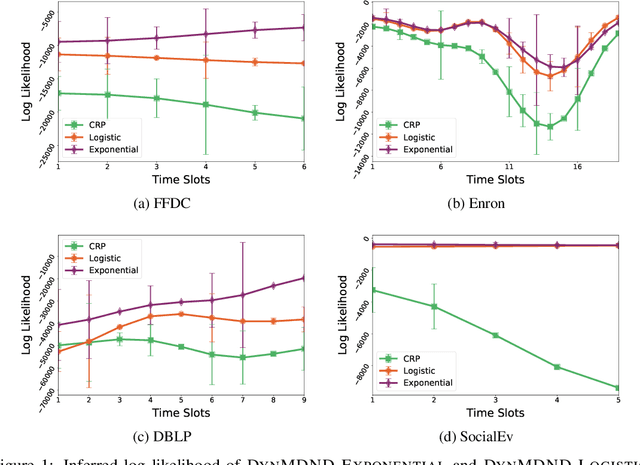
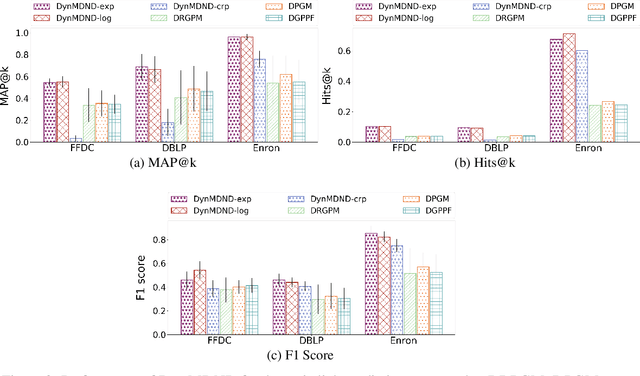
Interaction graphs, such as those recording emails between individuals or transactions between institutions, tend to be sparse yet structured, and often grow in an unbounded manner. Such behavior can be well-captured by structured, nonparametric edge-exchangeable graphs. However, such exchangeable models necessarily ignore temporal dynamics in the network. We propose a dynamic nonparametric model for interaction graphs that combine the sparsity of the exchangeable models with dynamic clustering patterns that tend to reinforce recent behavioral patterns. We show that our method yields improved held-out likelihood over stationary variants, and impressive predictive performance against a range of state-of-the-art dynamic interaction graph models.
Playing Catan with Cross-dimensional Neural Network
Aug 17, 2020


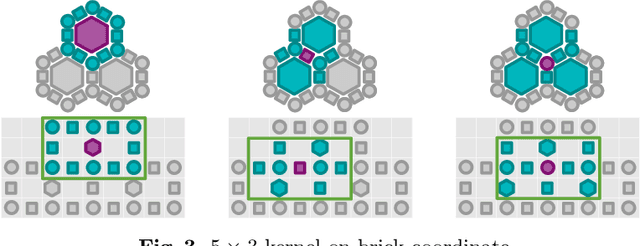
Catan is a strategic board game having interesting properties, including multi-player, imperfect information, stochastic, complex state space structure (hexagonal board where each vertex, edge and face has its own features, cards for each player, etc), and a large action space (including negotiation). Therefore, it is challenging to build AI agents by Reinforcement Learning (RL for short), without domain knowledge nor heuristics. In this paper, we introduce cross-dimensional neural networks to handle a mixture of information sources and a wide variety of outputs, and empirically demonstrate that the network dramatically improves RL in Catan. We also show that, for the first time, a RL agent can outperform jsettler, the best heuristic agent available.
Real-Time Visual Tracking: Promoting the Robustness of Correlation Filter Learning
Sep 09, 2016
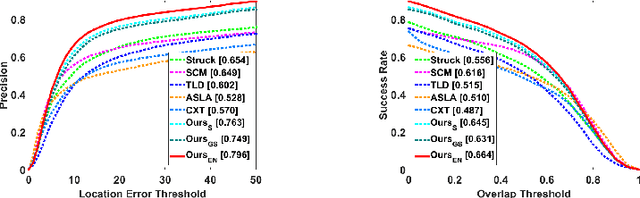
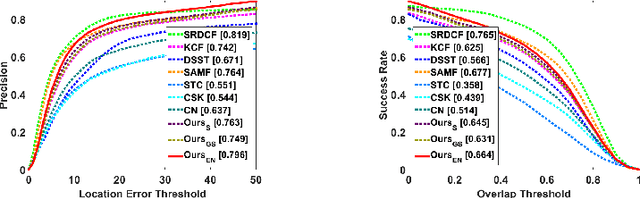
Correlation filtering based tracking model has received lots of attention and achieved great success in real-time tracking, however, the lost function in current correlation filtering paradigm could not reliably response to the appearance changes caused by occlusion and illumination variations. This study intends to promote the robustness of the correlation filter learning. By exploiting the anisotropy of the filter response, three sparsity related loss functions are proposed to alleviate the overfitting issue of previous methods and improve the overall tracking performance. As a result, three real-time trackers are implemented. Extensive experiments in various challenging situations demonstrate that the robustness of the learned correlation filter has been greatly improved via the designed loss functions. In addition, the study reveals, from an experimental perspective, how different loss functions essentially influence the tracking performance. An important conclusion is that the sensitivity of the peak values of the filter in successive frames is consistent with the tracking performance. This is a useful reference criterion in designing a robust correlation filter for visual tracking.
Improving the Decision-Making Process of Self-Adaptive Systems by Accounting for Tactic Volatility
Apr 23, 2020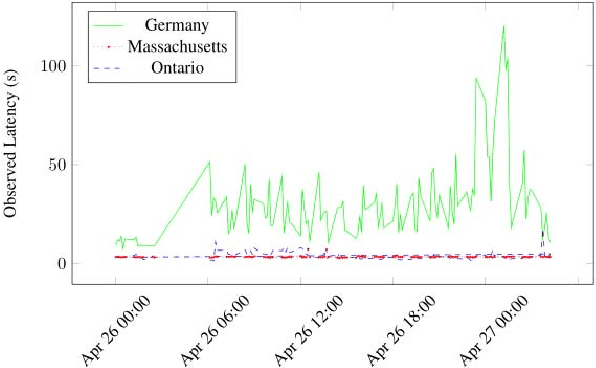
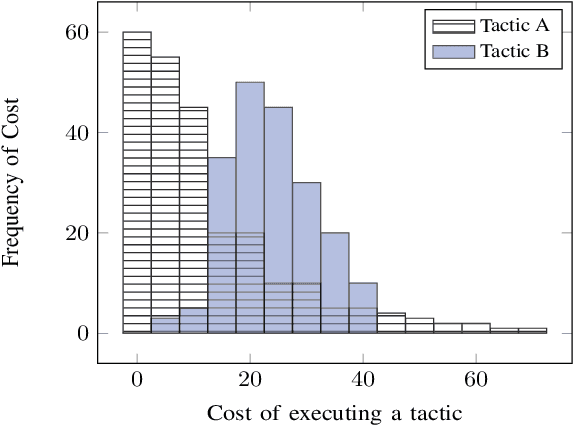
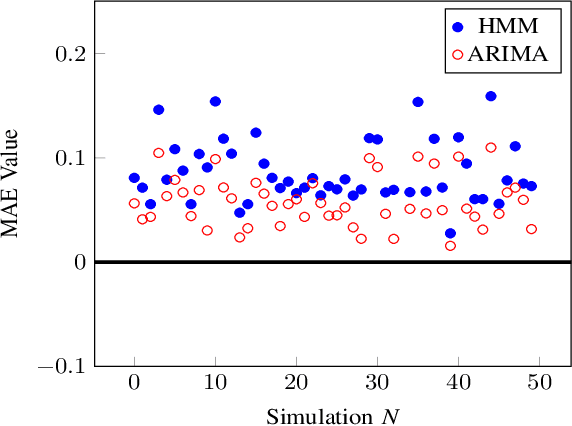
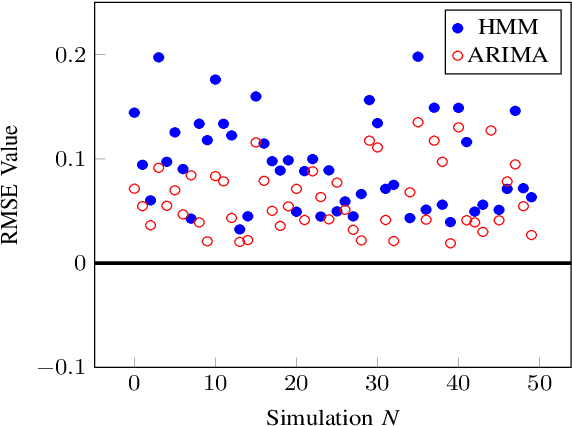
When self-adaptive systems encounter changes within their surrounding environments, they enact tactics to perform necessary adaptations. For example, a self-adaptive cloud-based system may have a tactic that initiates additional computing resources when response time thresholds are surpassed, or there may be a tactic to activate a specific security measure when an intrusion is detected. In real-world environments, these tactics frequently experience tactic volatility which is variable behavior during the execution of the tactic. Unfortunately, current self-adaptive approaches do not account for tactic volatility in their decision-making processes, and merely assume that tactics do not experience volatility. This limitation creates uncertainty in the decision-making process and may adversely impact the system's ability to effectively and efficiently adapt. Additionally, many processes do not properly account for volatility that may effect the system's Service Level Agreement (SLA). This can limit the system's ability to act proactively, especially when utilizing tactics that contain latency. To address the challenge of sufficiently accounting for tactic volatility, we propose a Tactic Volatility Aware (TVA) solution. Using Multiple Regression Analysis (MRA), TVA enables self-adaptive systems to accurately estimate the cost and time required to execute tactics. TVA also utilizes Autoregressive Integrated Moving Average (ARIMA) for time series forecasting, allowing the system to proactively maintain specifications.
Neural Representations in Hybrid Recommender Systems: Prediction versus Regularization
Oct 12, 2020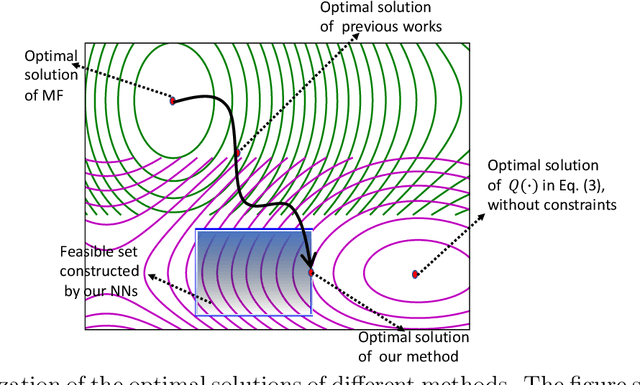
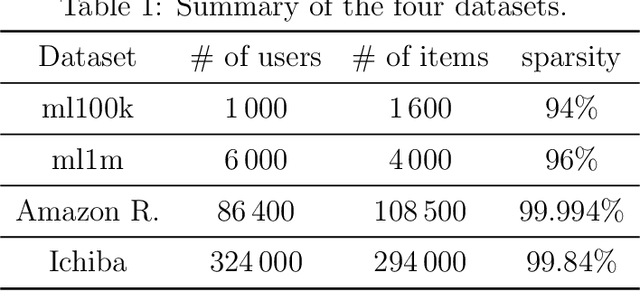
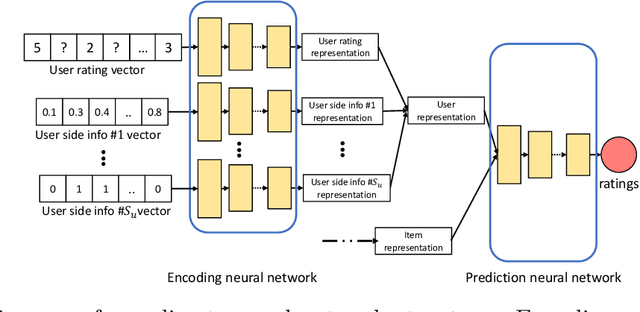
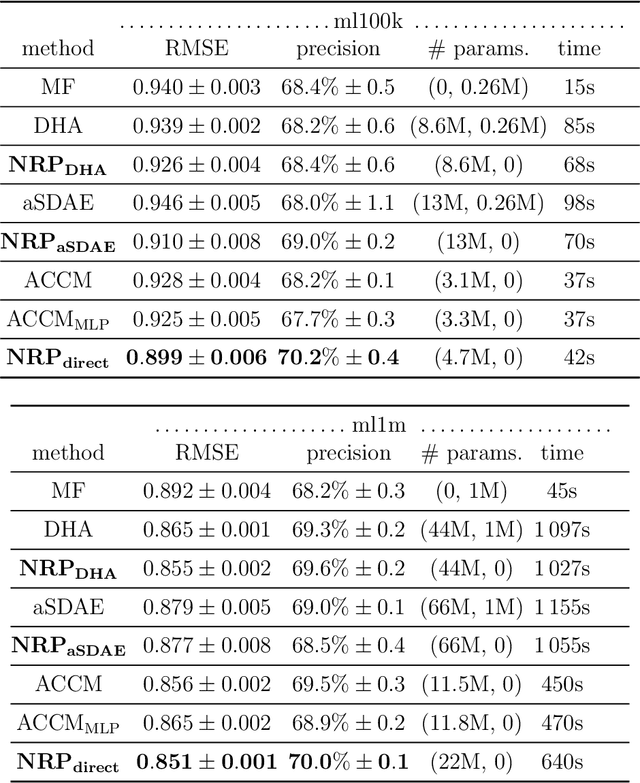
Autoencoder-based hybrid recommender systems have become popular recently because of their ability to learn user and item representations by reconstructing various information sources, including users' feedback on items (e.g., ratings) and side information of users and items (e.g., users' occupation and items' title). However, existing systems still use representations learned by matrix factorization (MF) to predict the rating, while using representations learned by neural networks as the regularizer. In this paper, we define the neural representation for prediction (NRP) framework and apply it to the autoencoder-based recommendation systems. We theoretically analyze how our objective function is related to the previous MF and autoencoder-based methods and explain what it means to use neural representations as the regularizer. We also apply the NRP framework to a direct neural network structure which predicts the ratings without reconstructing the user and item information. We conduct extensive experiments on two MovieLens datasets and two real-world e-commerce datasets. The results confirm that neural representations are better for prediction than regularization and show that the NRP framework, combined with the direct neural network structure, outperforms the state-of-the-art methods in the prediction task, with less training time and memory.
Graph Minors Meet Machine Learning: the Power of Obstructions
Jun 08, 2020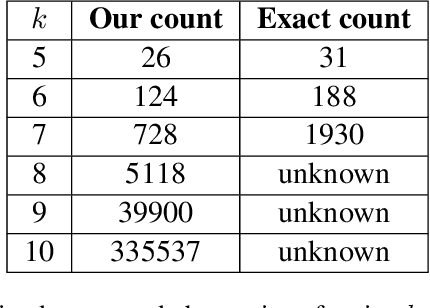
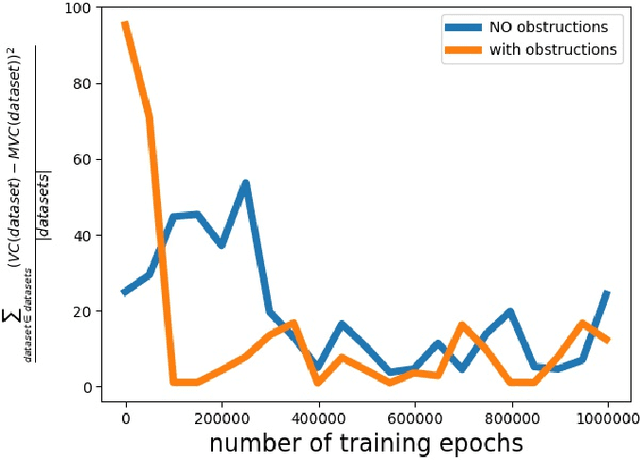

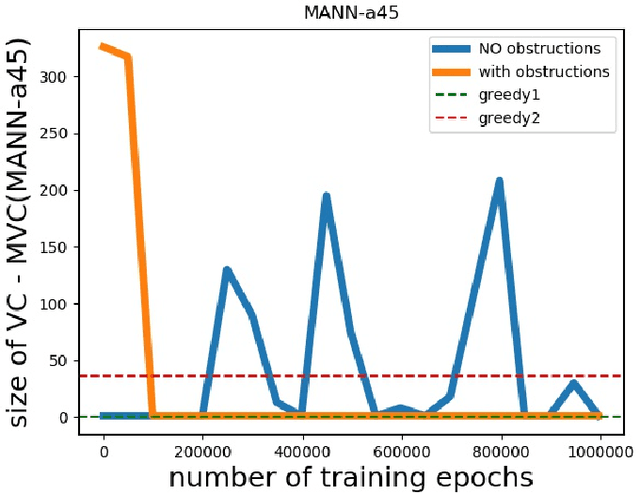
Computational intractability has for decades motivated the development of a plethora of methodologies that mainly aimed at a quality-time trade-off. The use of Machine Learning techniques has finally emerged as one of the possible tools to obtain approximate solutions to ${\cal NP}$-hard combinatorial optimization problems. In a recent article, Dai et al. introduced a method for computing such approximate solutions for instances of the Vertex Cover problem. In this paper we consider the effectiveness of selecting a proper training strategy by considering special problem instances called "obstructions" that we believe carry some intrinsic properties of the problem itself. Capitalizing on the recent work of Dai et al. on the Vertex Cover problem, and using the same case study as well as 19 other problem instances, we show the utility of using obstructions for training neural networks. Experiments show that training with obstructions results in a huge reduction in number of iterations needed for convergence, thus gaining a substantial reduction in the time needed for training the model.
Once-for-All Adversarial Training: In-Situ Tradeoff between Robustness and Accuracy for Free
Oct 22, 2020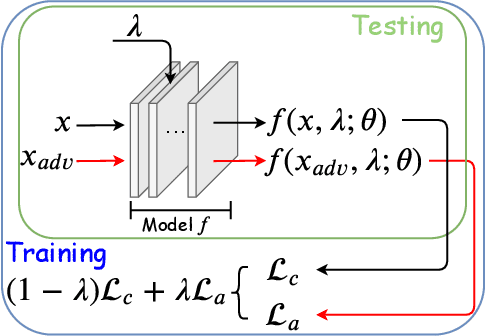
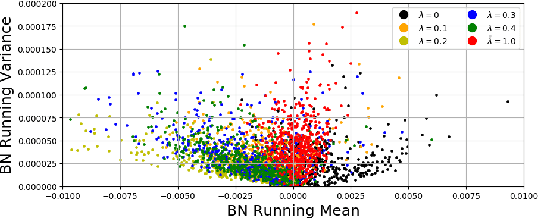
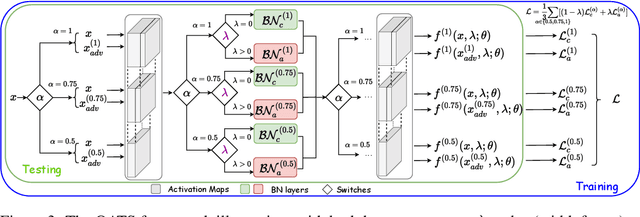
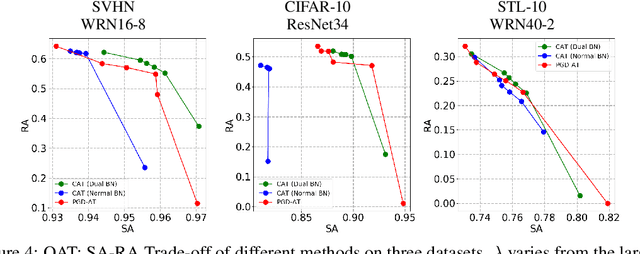
Adversarial training and its many variants substantially improve deep network robustness, yet at the cost of compromising standard accuracy. Moreover, the training process is heavy and hence it becomes impractical to thoroughly explore the trade-off between accuracy and robustness. This paper asks this new question: how to quickly calibrate a trained model in-situ, to examine the achievable trade-offs between its standard and robust accuracies, without (re-)training it many times? Our proposed framework, Once-for-all Adversarial Training (OAT), is built on an innovative model-conditional training framework, with a controlling hyper-parameter as the input. The trained model could be adjusted among different standard and robust accuracies "for free" at testing time. As an important knob, we exploit dual batch normalization to separate standard and adversarial feature statistics, so that they can be learned in one model without degrading performance. We further extend OAT to a Once-for-all Adversarial Training and Slimming (OATS) framework, that allows for the joint trade-off among accuracy, robustness and runtime efficiency. Experiments show that, without any re-training nor ensembling, OAT/OATS achieve similar or even superior performance compared to dedicatedly trained models at various configurations. Our codes and pretrained models are available at: https://github.com/VITA-Group/Once-for-All-Adversarial-Training.