 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AutoML: Exploration v.s. Exploitation
Dec 29, 2019



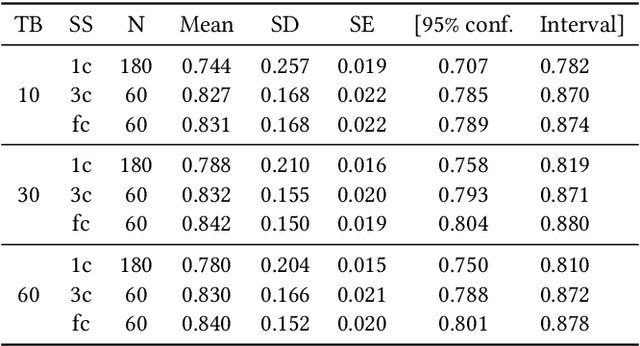
Building a machine learning (ML) pipeline in an automated way is a crucial and complex task as it is constrained with the available time budget and resources. This encouraged the research community to introduce several solutions to utilize the available time and resources. A lot of work is done to suggest the most promising classifiers for a given dataset using sundry of techniques including meta-learning based techniques. This gives the autoML framework the chance to spend more time exploiting those classifiers and tuning their hyper-parameters. In this paper, we empirically study the hypothesis of improving the pipeline performance by exploiting the most promising classifiers within the limited time budget. We also study the effect of increasing the time budget over the pipeline performance. The empirical results across autoSKLearn, TPOT and ATM, show that exploiting the most promising classifiers does not achieve a statistically better performance than exploring the entire search space. The same conclusion is also applied for long time budgets.
Optimising Stochastic Routing for Taxi Fleets with Model Enhanced Reinforcement Learning
Oct 22, 2020
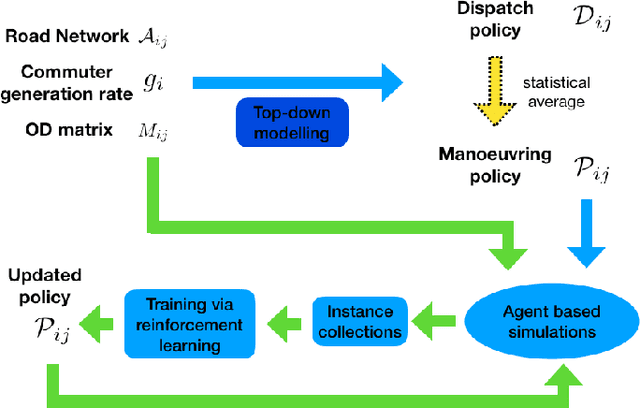
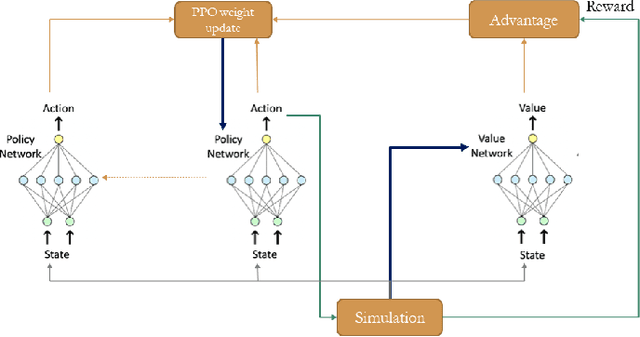
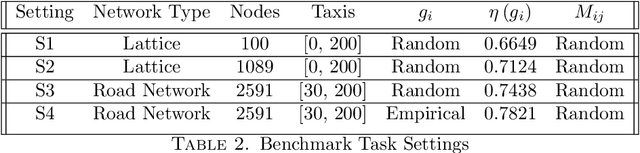
The future of mobility-as-a-Service (Maas)should embrace an integrated system of ride-hailing, street-hailing and ride-sharing with optimised intelligent vehicle routing in response to a real-time, stochastic demand pattern. We aim to optimise routing policies for a large fleet of vehicles for street-hailing services, given a stochastic demand pattern in small to medium-sized road networks. A model-based dispatch algorithm, a high performance model-free reinforcement learning based algorithm and a novel hybrid algorithm combining the benefits of both the top-down approach and the model-free reinforcement learning have been proposed to route the \emph{vacant} vehicles. We design our reinforcement learning based routing algorithm using proximal policy optimisation and combined intrinsic and extrinsic rewards to strike a balance between exploration and exploitation. Using a large-scale agent-based microscopic simulation platform to evaluate our proposed algorithms, our model-free reinforcement learning and hybrid algorithm show excellent performance on both artificial road network and community-based Singapore road network with empirical demands, and our hybrid algorithm can significantly accelerate the model-free learner in the process of learning.
Recalibration of Neural Networks for Point Cloud Analysis
Nov 25, 2020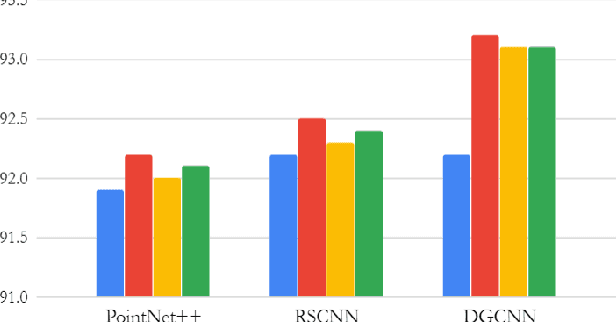
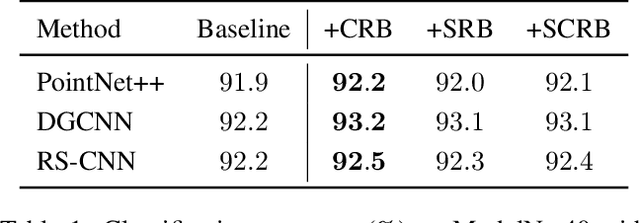
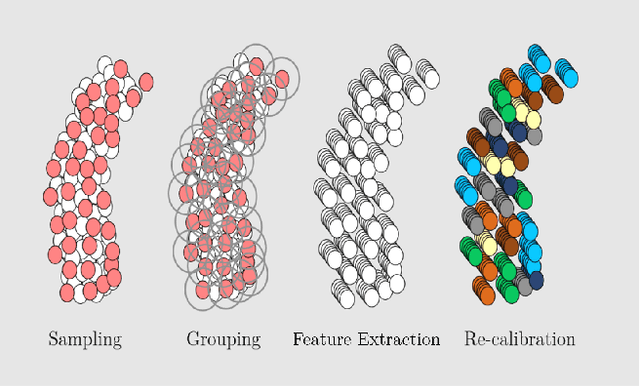

Spatial and channel re-calibration have become powerful concepts in computer vision. Their ability to capture long-range dependencies is especially useful for those networks that extract local features, such as CNNs. While re-calibration has been widely studied for image analysis, it has not yet been used on shape representations. In this work, we introduce re-calibration modules on deep neural networks for 3D point clouds. We propose a set of re-calibration blocks that extend Squeeze and Excitation blocks and that can be added to any network for 3D point cloud analysis that builds a global descriptor by hierarchically combining features from multiple local neighborhoods. We run two sets of experiments to validate our approach. First, we demonstrate the benefit and versatility of our proposed modules by incorporating them into three state-of-the-art networks for 3D point cloud analysis: PointNet++, DGCNN, and RSCNN. We evaluate each network on two tasks: object classification on ModelNet40, and object part segmentation on ShapeNet. Our results show an improvement of up to 1% in accuracy for ModelNet40 compared to the baseline method. In the second set of experiments, we investigate the benefits of re-calibration blocks on Alzheimer's Disease (AD) diagnosis. Our results demonstrate that our proposed methods yield a 2% increase in accuracy for diagnosing AD and a 2.3% increase in concordance index for predicting AD onset with time-to-event analysis. Concluding, re-calibration improves the accuracy of point cloud architectures, while only minimally increasing the number of parameters.
Monitoring-based Differential Privacy Mechanism Against Query-Flooding Parameter Duplication Attack
Nov 01, 2020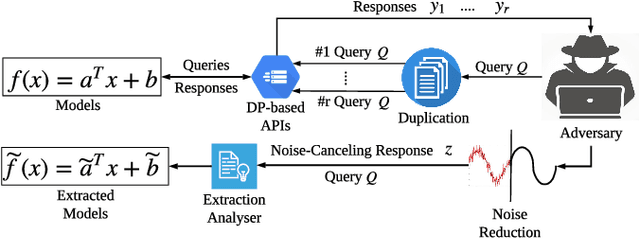

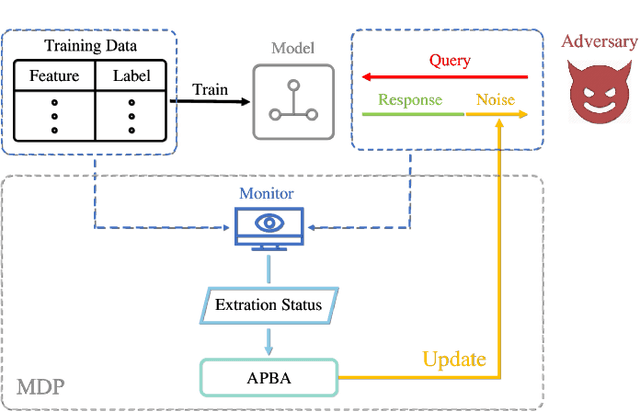
Public intelligent services enabled by machine learning algorithms are vulnerable to model extraction attacks that can steal confidential information of the learning models through public queries. Though there are some protection options such as differential privacy (DP) and monitoring, which are considered promising techniques to mitigate this attack, we still find that the vulnerability persists. In this paper, we propose an adaptive query-flooding parameter duplication (QPD) attack. The adversary can infer the model information with black-box access and no prior knowledge of any model parameters or training data via QPD. We also develop a defense strategy using DP called monitoring-based DP (MDP) against this new attack. In MDP, we first propose a novel real-time model extraction status assessment scheme called Monitor to evaluate the situation of the model. Then, we design a method to guide the differential privacy budget allocation called APBA adaptively. Finally, all DP-based defenses with MDP could dynamically adjust the amount of noise added in the model response according to the result from Monitor and effectively defends the QPD attack. Furthermore, we thoroughly evaluate and compare the QPD attack and MDP defense performance on real-world models with DP and monitoring protection.
Collision Avoidance in Tightly-Constrained Environments without Coordination: a Hierarchical Control Approach
Nov 01, 2020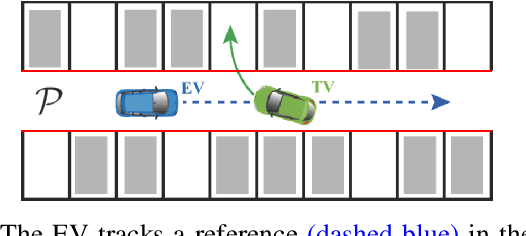
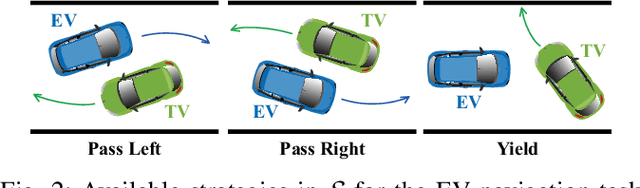
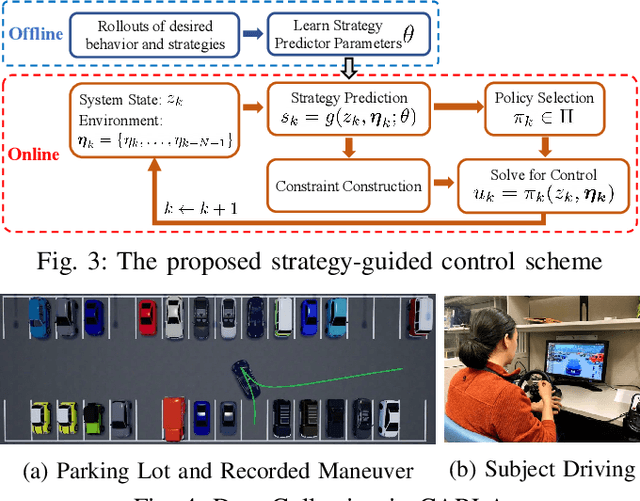
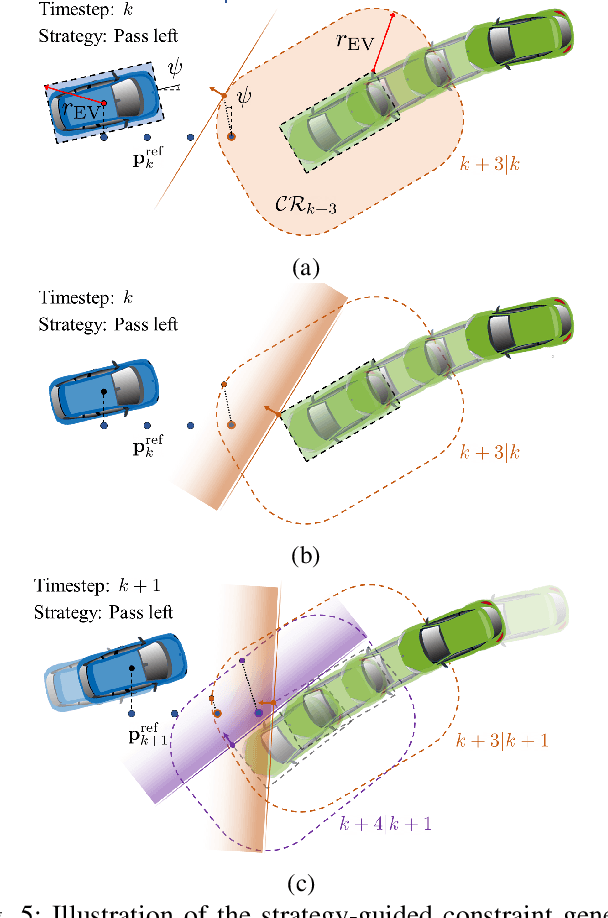
We present a hierarchical control approach for maneuvering an autonomous vehicle (AV) in a tightly-constrained environment where other moving AVs and/or human driven vehicles are present. A two-level hierarchy is proposed: a high-level data-driven strategy predictor and a lower-level model-based feedback controller. The strategy predictor maps a high-dimensional environment encoding into a set of high-level strategies. Our approach uses data collected on an offline simulator to train a neural network model as the strategy predictor. Depending on the online selected strategy, a set of time-varying hyperplanes in the AV's motion space is generated and included in the lower level control. The latter is a Strategy-Guided Optimization-Based Collision Avoidance (SG-OBCA) algorithm where the strategy-dependent hyperplane constraints are used to drive a model-based receding horizon controller towards a predicted feasible area. The strategy also informs switching from the SG-OBCA control policy to a safety or emergency control policy. We demonstrate the effectiveness of the proposed data-driven hierarchical control framework in simulations and experiments on a 1/10 scale autonomous car platform where the strategy-guided approach outperforms a model predictive control baseline in both cases.
Convolutional Neural Networks for cytoarchitectonic brain mapping at large scale
Nov 25, 2020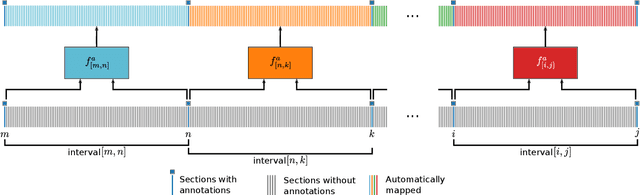
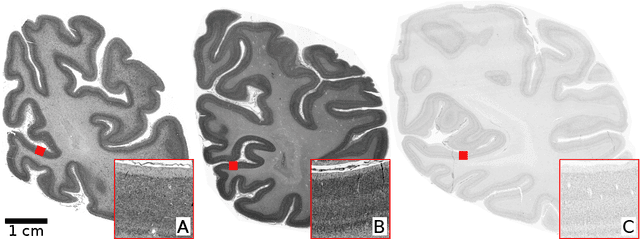
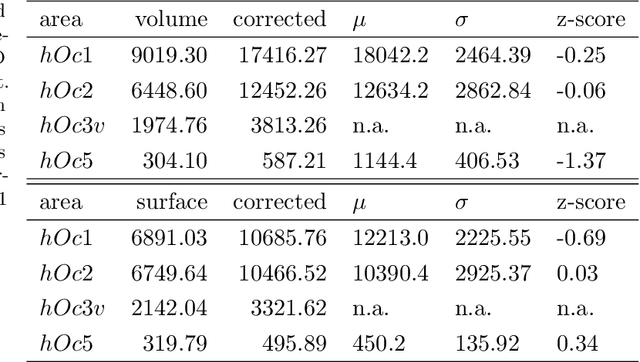
Human brain atlases provide spatial reference systems for data characterizing brain organization at different levels, coming from different brains. Cytoarchitecture is a basic principle of the microstructural organization of the brain, as regional differences in the arrangement and composition of neuronal cells are indicators of changes in connectivity and function. Automated scanning procedures and observer-independent methods are prerequisites to reliably identify cytoarchitectonic areas, and to achieve reproducible models of brain segregation. Time becomes a key factor when moving from the analysis of single regions of interest towards high-throughput scanning of large series of whole-brain sections. Here we present a new workflow for mapping cytoarchitectonic areas in large series of cell-body stained histological sections of human postmortem brains. It is based on a Deep Convolutional Neural Network (CNN), which is trained on a pair of section images with annotations, with a large number of un-annotated sections in between. The model learns to create all missing annotations in between with high accuracy, and faster than our previous workflow based on observer-independent mapping. The new workflow does not require preceding 3D-reconstruction of sections, and is robust against histological artefacts. It processes large data sets with sizes in the order of multiple Terabytes efficiently. The workflow was integrated into a web interface, to allow access without expertise in deep learning and batch computing. Applying deep neural networks for cytoarchitectonic mapping opens new perspectives to enable high-resolution models of brain areas, introducing CNNs to identify borders of brain areas.
Enabling certification of verification-agnostic networks via memory-efficient semidefinite programming
Oct 22, 2020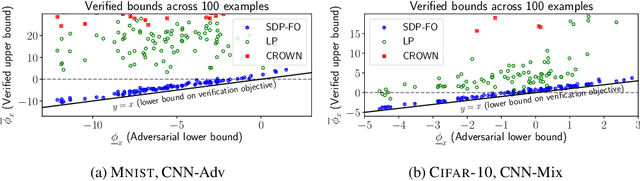
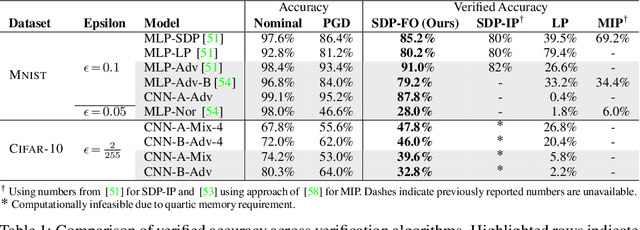
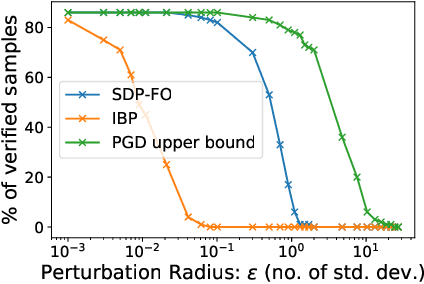

Convex relaxations have emerged as a promising approach for verifying desirable properties of neural networks like robustness to adversarial perturbations. Widely used Linear Programming (LP) relaxations only work well when networks are trained to facilitate verification. This precludes applications that involve verification-agnostic networks, i.e., networks not specially trained for verification. On the other hand, semidefinite programming (SDP) relaxations have successfully be applied to verification-agnostic networks, but do not currently scale beyond small networks due to poor time and space asymptotics. In this work, we propose a first-order dual SDP algorithm that (1) requires memory only linear in the total number of network activations, (2) only requires a fixed number of forward/backward passes through the network per iteration. By exploiting iterative eigenvector methods, we express all solver operations in terms of forward and backward passes through the network, enabling efficient use of hardware like GPUs/TPUs. For two verification-agnostic networks on MNIST and CIFAR-10, we significantly improve L-inf verified robust accuracy from 1% to 88% and 6% to 40% respectively. We also demonstrate tight verification of a quadratic stability specification for the decoder of a variational autoencoder.
Real-Time Anomaly Detection and Localization in Crowded Scenes
Nov 21, 2015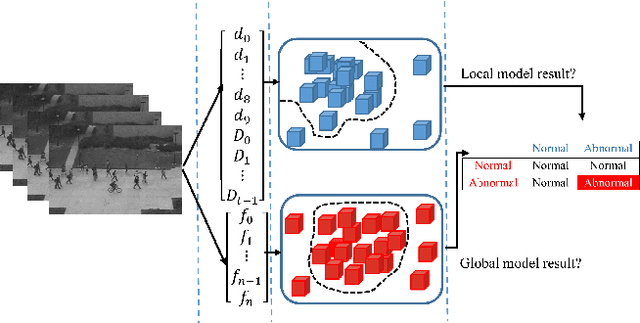

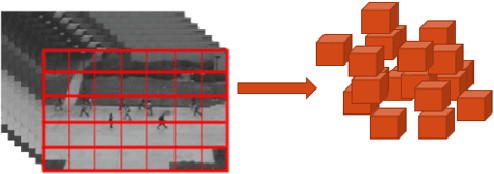
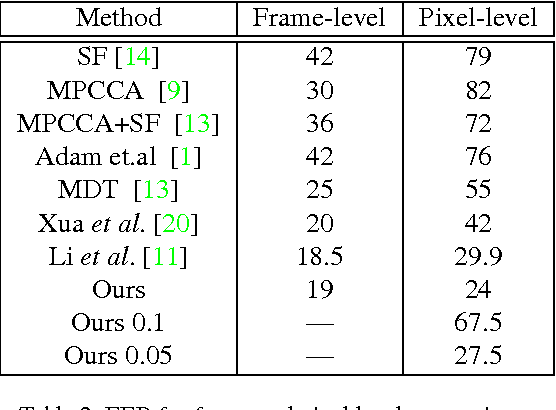
In this paper, we propose a method for real-time anomaly detection and localization in crowded scenes. Each video is defined as a set of non-overlapping cubic patches, and is described using two local and global descriptors. These descriptors capture the video properties from different aspects. By incorporating simple and cost-effective Gaussian classifiers, we can distinguish normal activities and anomalies in videos. The local and global features are based on structure similarity between adjacent patches and the features learned in an unsupervised way, using a sparse auto- encoder. Experimental results show that our algorithm is comparable to a state-of-the-art procedure on UCSD ped2 and UMN benchmarks, but even more time-efficient. The experiments confirm that our system can reliably detect and localize anomalies as soon as they happen in a video.
Robust navigation with tinyML for autonomous mini-vehicles
Jul 01, 2020

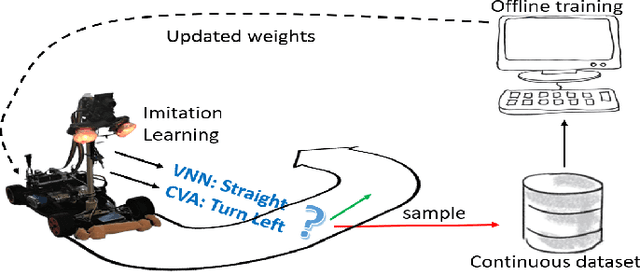
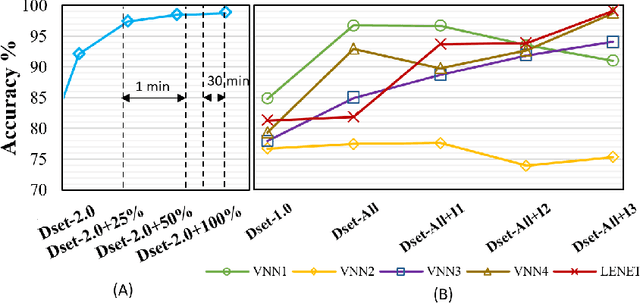
Autonomous navigation vehicles have rapidly improved thanks to the breakthroughs of Deep Learning. However, scaling autonomous driving to low-power and real-time systems deployed on dynamic environments poses several challenges that prevent their adoption. In this work, we show an end-to-end integration of data, algorithms, and deployment tools that enables the deployment of a family of tiny-CNNs on extra-low-power MCUs for autonomous driving mini-vehicles (image classification task). Our end-to-end environment enables a closed-loop learning system that allows the CNNs (learners) to learn through demonstration by imitating the original computer-vision algorithm (teacher) while doubling the throughput. Thereby, our CNNs gain robustness to lighting conditions and increase their accuracy up to 20% when deployed in the most challenging setup with a very fast-rate camera. Further, we leverage GAP8, a parallel ultra-low-power RISC-V SoC, to meet the real-time requirements. When running a family of CNN for an image classification task, GAP8 reduces their latency by over 20x compared to using an STM32L4 (Cortex-M4) or obtains +21.4% accuracy than an NXP k64f (Cortex-M4) solution with the same energy budget.
Explainable Deep Reinforcement Learning for UAV Autonomous Navigation
Sep 30, 2020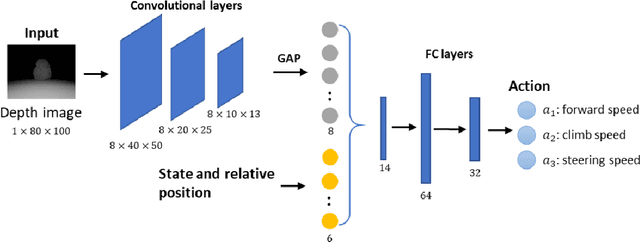


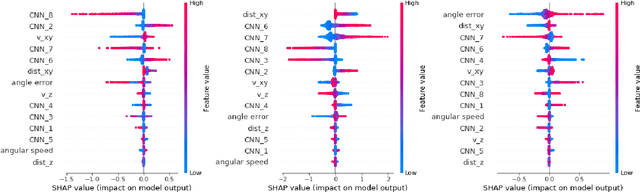
Modern deep reinforcement learning plays an important role to solve a wide range of complex decision-making tasks. However, due to the use of deep neural networks, the trained models are lacking transparency which causes distrust from their user and hard to be used in the critical field such as self-driving car and unmanned aerial vehicles. In this paper, an explainable deep reinforcement learning method is proposed to deal with the multirotor obstacle avoidance and navigation problem. Both visual and textual explanation is provided to make the trained agent more transparency and comprehensible for humans. Our model can provide real-time decision explanation for non-expert users. Also, some global explanation results are provided for experts to diagnose the learned policy. Our method is validated in the simulation environment. The simulation result shows our proposed method can get useful explanations to increase the user's trust to the network and also improve the network performance.