 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Exploiting Neural Query Translation into Cross Lingual Information Retrieval
Oct 26, 2020
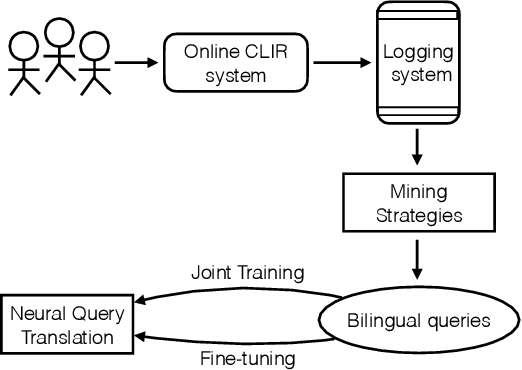
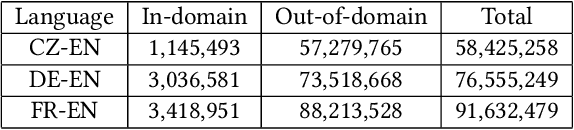
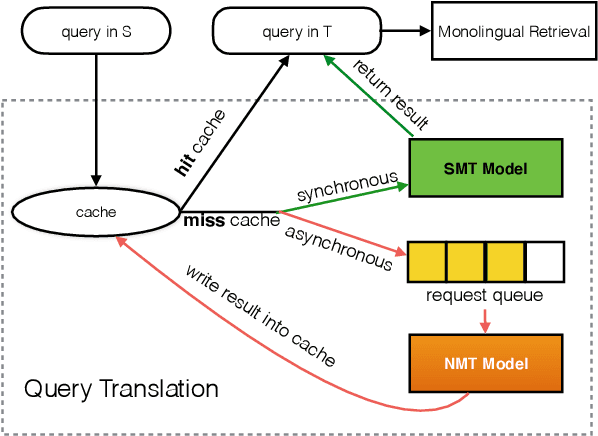

As a crucial role in cross-language information retrieval (CLIR), query translation has three main challenges: 1) the adequacy of translation; 2) the lack of in-domain parallel training data; and 3) the requisite of low latency. To this end, existing CLIR systems mainly exploit statistical-based machine translation (SMT) rather than the advanced neural machine translation (NMT), limiting the further improvements on both translation and retrieval quality. In this paper, we investigate how to exploit neural query translation model into CLIR system. Specifically, we propose a novel data augmentation method that extracts query translation pairs according to user clickthrough data, thus to alleviate the problem of domain-adaptation in NMT. Then, we introduce an asynchronous strategy which is able to leverage the advantages of the real-time in SMT and the veracity in NMT. Experimental results reveal that the proposed approach yields better retrieval quality than strong baselines and can be well applied into a real-world CLIR system, i.e. Aliexpress e-Commerce search engine. Readers can examine and test their cases on our website: https://aliexpress.com .
Can Human Sex Be Learned Using Only 2D Body Keypoint Estimations?
Nov 05, 2020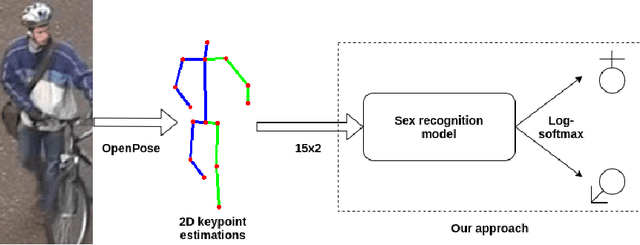

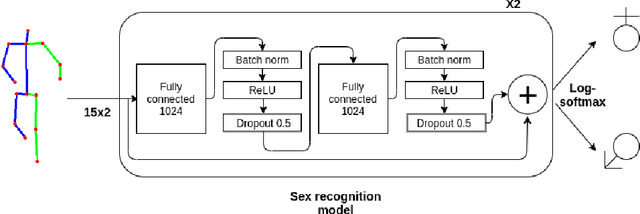
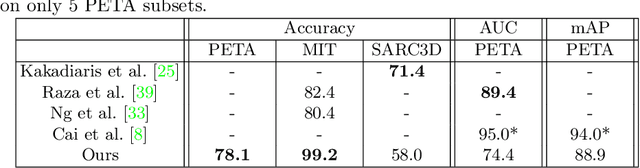
In this paper, we analyze human male and female sex recognition problem and present a fully automated classification system using only 2D keypoints. The keypoints represent human joints. A keypoint set consists of 15 joints and the keypoint estimations are obtained using an OpenPose 2D keypoint detector. We learn a deep learning model to distinguish males and females using the keypoints as input and binary labels as output. We use two public datasets in the experimental section - 3DPeople and PETA. On PETA dataset, we report a 77% accuracy. We provide model performance details on both PETA and 3DPeople. To measure the effect of noisy 2D keypoint detections on the performance, we run separate experiments on 3DPeople ground truth and noisy keypoint data. Finally, we extract a set of factors that affect the classification accuracy and propose future work. The advantage of the approach is that the input is small and the architecture is simple, which enables us to run many experiments and keep the real-time performance in inference. The source code, with the experiments and data preparation scripts, are available on GitHub (https://github.com/kristijanbartol/human-sex-classifier).
Dereverberation using joint estimation of dry speech signal and acoustic system
Jul 24, 2020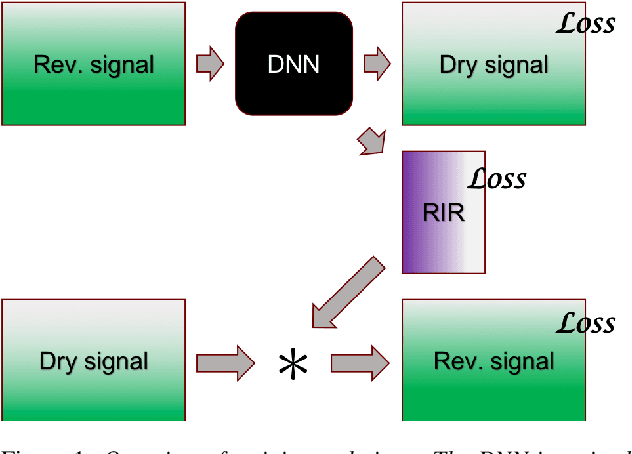
The purpose of speech dereverberation is to remove quality-degrading effects of a time-invariant impulse response filter from the signal. In this report, we describe an approach to speech dereverberation that involves joint estimation of the dry speech signal and of the room impulse response. We explore deep learning models that apply to each task separately, and how these can be combined in a joint model with shared parameters.
MorphEyes: Variable Baseline Stereo For Quadrotor Navigation
Nov 05, 2020
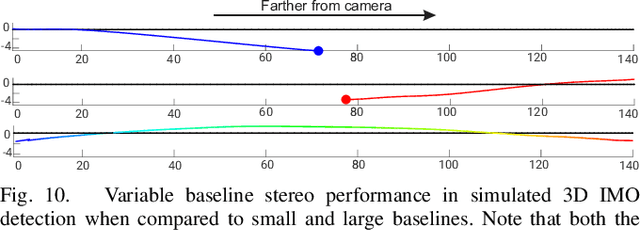
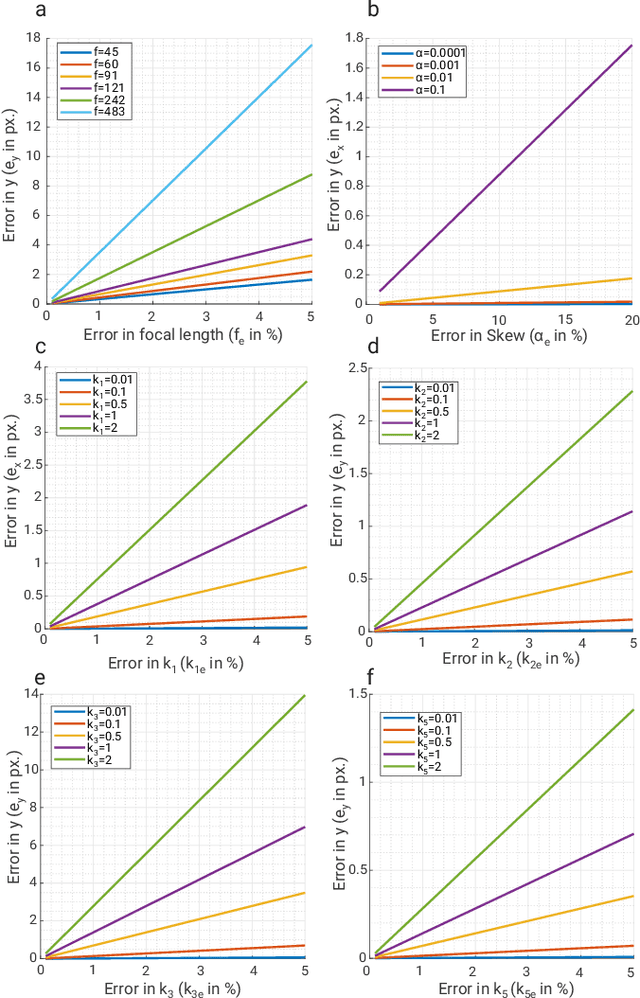
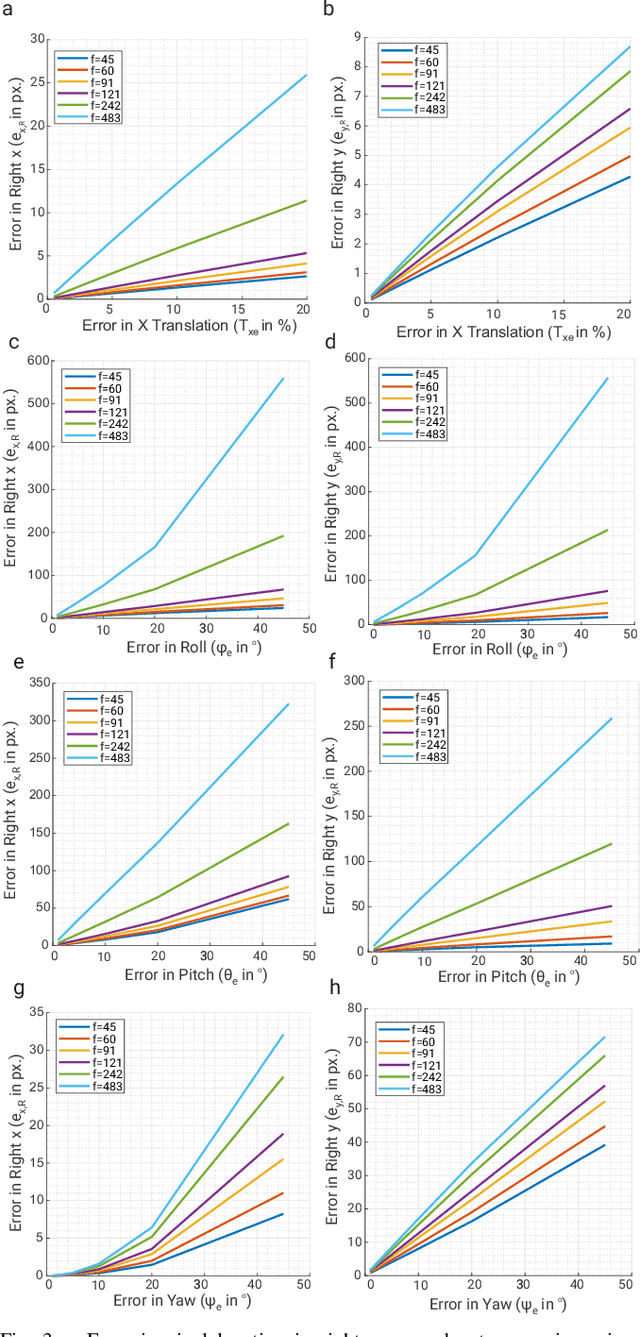
Morphable design and depth-based visual control are two upcoming trends leading to advancements in the field of quadrotor autonomy. Stereo-cameras have struck the perfect balance of weight and accuracy of depth estimation but suffer from the problem of depth range being limited and dictated by the baseline chosen at design time. In this paper, we present a framework for quadrotor navigation based on a stereo camera system whose baseline can be adapted on-the-fly. We present a method to calibrate the system at a small number of discrete baselines and interpolate the parameters for the entire baseline range. We present an extensive theoretical analysis of calibration and synchronization errors. We showcase three different applications of such a system for quadrotor navigation: (a) flying through a forest, (b) flying through an unknown shaped/location static/dynamic gap, and (c) accurate 3D pose detection of an independently moving object. We show that our variable baseline system is more accurate and robust in all three scenarios. To our knowledge, this is the first work that applies the concept of morphable design to achieve a variable baseline stereo vision system on a quadrotor.
KrigHedge: GP Surrogates for Delta Hedging
Oct 26, 2020



We investigate a machine learning approach to option Greeks approximation based on Gaussian process (GP) surrogates. The method takes in noisily observed option prices, fits a nonparametric input-output map and then analytically differentiates the latter to obtain the various price sensitivities. Our motivation is to compute Greeks in cases where direct computation is expensive, such as in local volatility models, or can only ever be done approximately. We provide a detailed analysis of numerous aspects of GP surrogates, including choice of kernel family, simulation design, choice of trend function and impact of noise. We further discuss the application to Delta hedging, including a new Lemma that relates quality of the Delta approximation to discrete-time hedging loss. Results are illustrated with two extensive case studies that consider estimation of Delta, Theta and Gamma and benchmark approximation quality and uncertainty quantification using a variety of statistical metrics. Among our key take-aways are the recommendation to use Matern kernels, the benefit of including virtual training points to capture boundary conditions, and the significant loss of fidelity when training on stock-path-based datasets.
Inference in Stochastic Epidemic Models via Multinomial Approximations
Jun 24, 2020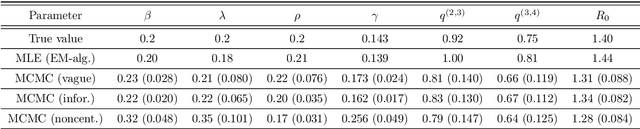
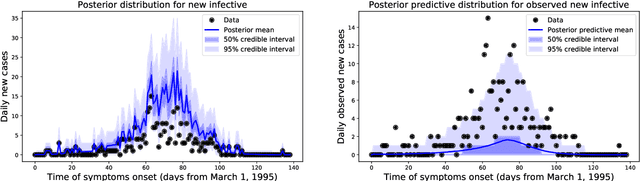
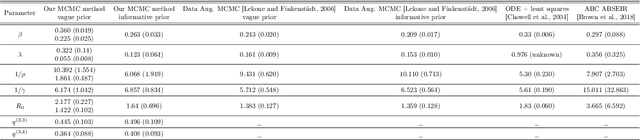
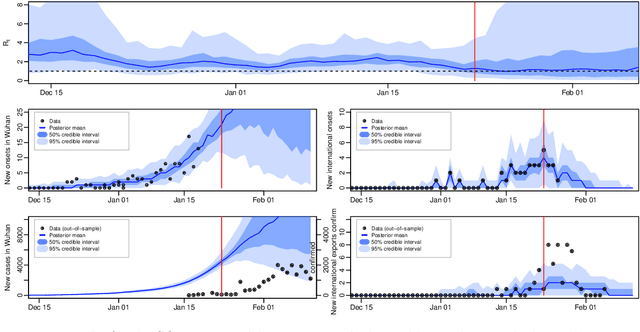
We introduce a new method for inference in stochastic epidemic models which uses recursive multinomial approximations to integrate over unobserved variables and thus circumvent likelihood intractability. The method is applicable to a class of discrete-time, finite-population compartmental models with partial, randomly under-reported or missing count observations. In contrast to state-of-the-art alternatives such as Approximate Bayesian Computation techniques, no forward simulation of the model is required and there are no tuning parameters. Evaluating the approximate marginal likelihood of model parameters is achieved through a computationally simple filtering recursion. The accuracy of the approximation is demonstrated through analysis of real and simulated data using a model of the 1995 Ebola outbreak in the Democratic Republic of Congo. We show how the method can be embedded within a Sequential Monte Carlo approach to estimating the time-varying reproduction number of COVID-19 in Wuhan, China, recently published by Kucharski et al. 2020.
PCNN: Deep Convolutional Networks for Short-term Traffic Congestion Prediction
Mar 16, 2020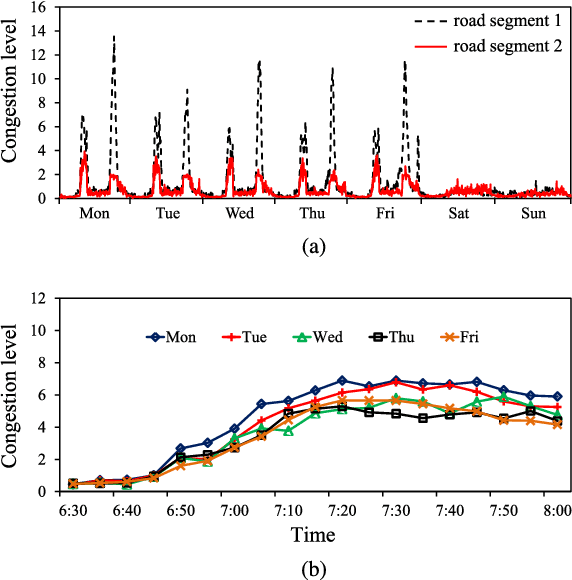
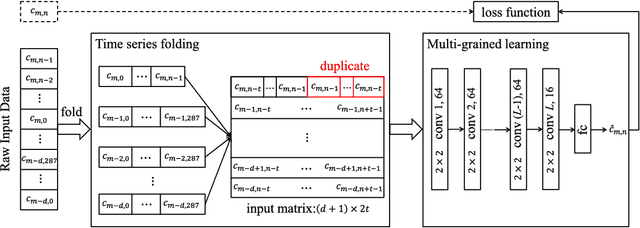
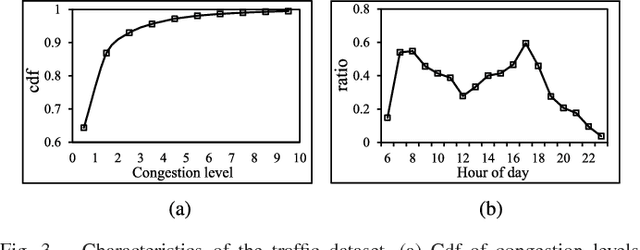
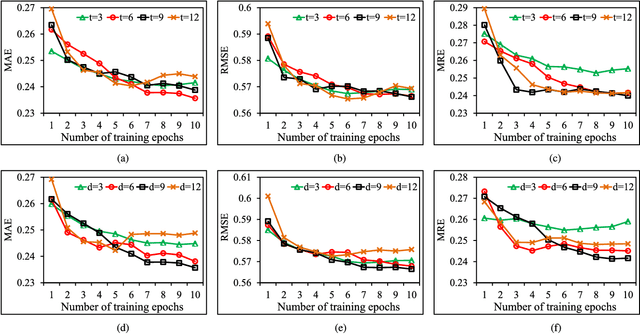
Traffic problems have seriously affected people's life quality and urban development, and forecasting the short-term traffic congestion is of great importance to both individuals and governments. However, understanding and modeling the traffic conditions can be extremely difficult, and our observations from real traffic data reveal that (1) similar traffic congestion patterns exist in the neighboring time slots and on consecutive workdays; (2) the levels of traffic congestion have clear multiscale properties. To capture these characteristics, we propose a novel method named PCNN based on deep Convolutional Neural Network, modeling Periodic traffic data for short-term traffic congestion prediction. PCNN has two pivotal procedures: time series folding and multi-grained learning. It first temporally folds the time series and constructs a two-dimensional matrix as the network input, such that both the real-time traffic conditions and past traffic patterns are well considered; then with a series of convolutions over the input matrix, it is able to model the local temporal dependency and multiscale traffic patterns. In particular, the global trend of congestion can be addressed at the macroscale; whereas more details and variations of the congestion can be captured at the microscale. Experimental results on a real-world urban traffic dataset confirm that folding time series data into a two-dimensional matrix is effective and PCNN outperforms the baselines significantly for the task of short-term congestion prediction.
A Probabilistic Model with Commonsense Constraints for Pattern-based Temporal Fact Extraction
Jun 11, 2020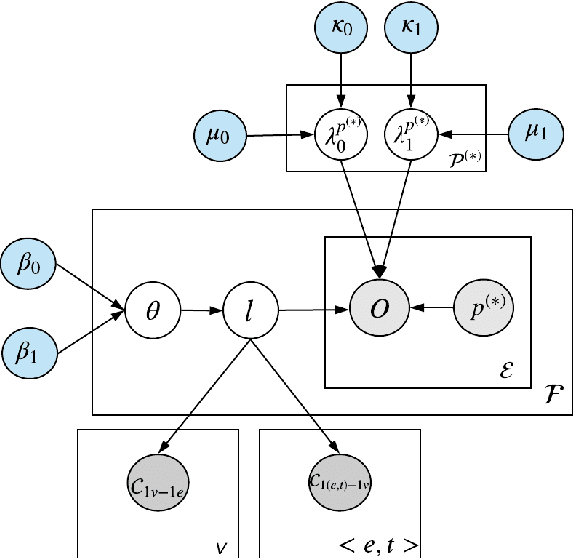
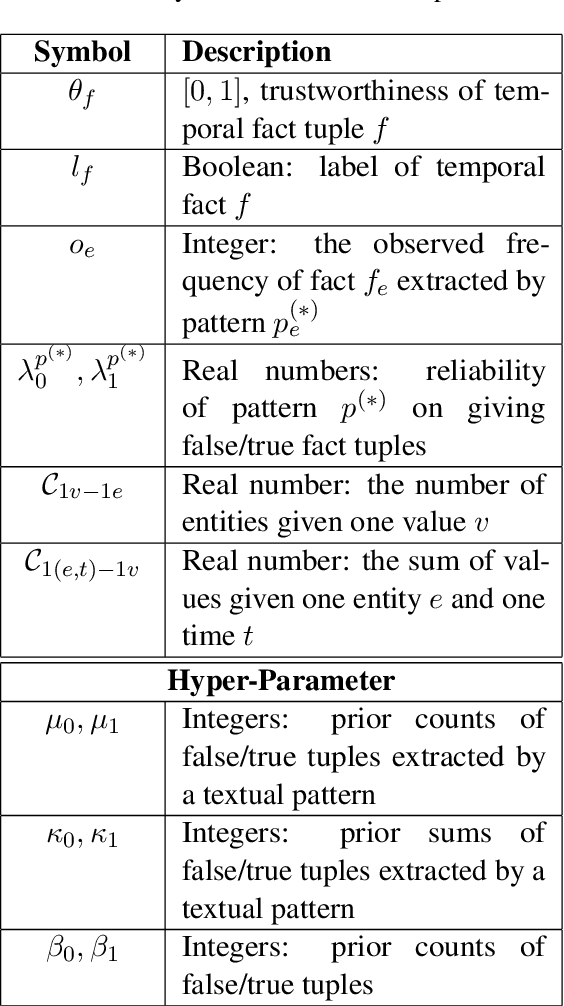
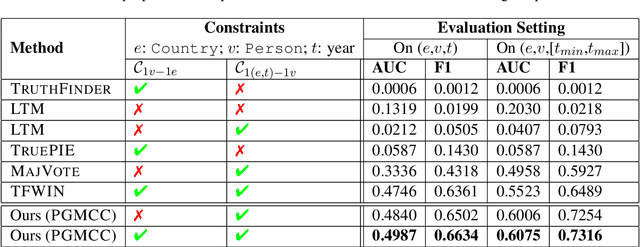
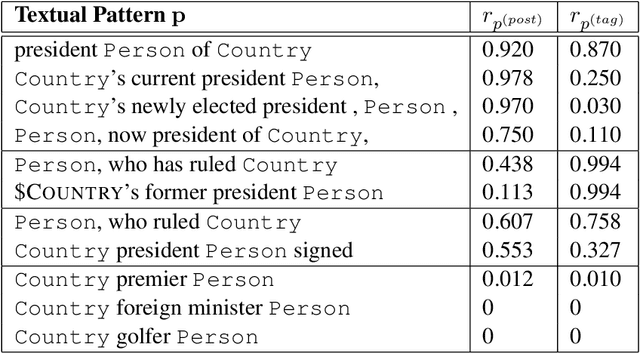
Textual patterns (e.g., Country's president Person) are specified and/or generated for extracting factual information from unstructured data. Pattern-based information extraction methods have been recognized for their efficiency and transferability. However, not every pattern is reliable: A major challenge is to derive the most complete and accurate facts from diverse and sometimes conflicting extractions. In this work, we propose a probabilistic graphical model which formulates fact extraction in a generative process. It automatically infers true facts and pattern reliability without any supervision. It has two novel designs specially for temporal facts: (1) it models pattern reliability on two types of time signals, including temporal tag in text and text generation time; (2) it models commonsense constraints as observable variables. Experimental results demonstrate that our model significantly outperforms existing methods on extracting true temporal facts from news data.
Multiple Word Embeddings for Increased Diversity of Representation
Oct 09, 2020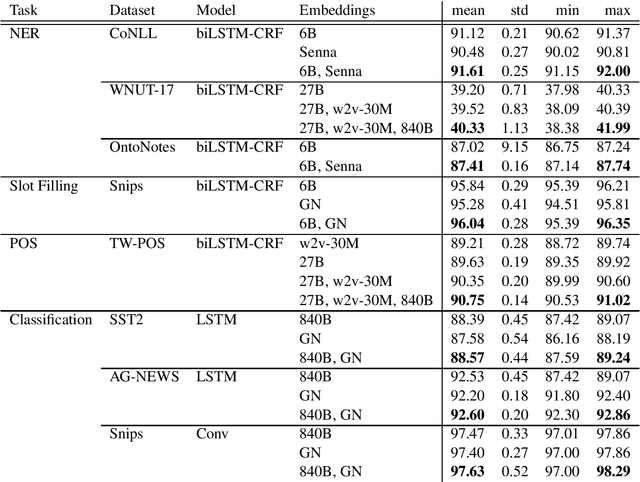

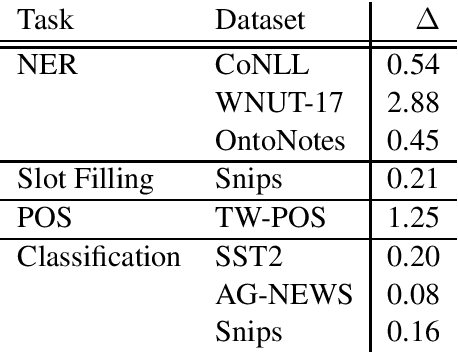
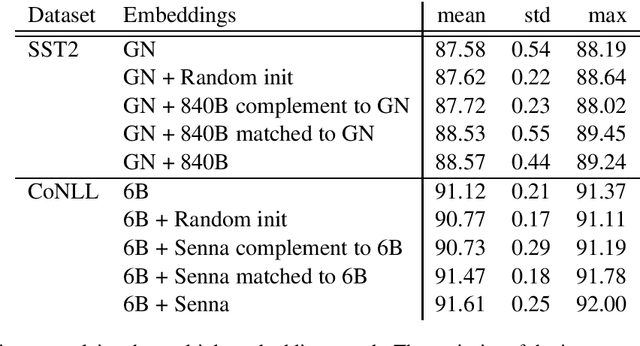
Most state-of-the-art models in natural language processing (NLP) are neural models built on top of large, pre-trained, contextual language models that generate representations of words in context and are fine-tuned for the task at hand. The improvements afforded by these "contextual embeddings" come with a high computational cost. In this work, we explore a simple technique that substantially and consistently improves performance over a strong baseline with negligible increase in run time. We concatenate multiple pre-trained embeddings to strengthen our representation of words. We show that this concatenation technique works across many tasks, datasets, and model types. We analyze aspects of pre-trained embedding similarity and vocabulary coverage and find that the representational diversity between different pre-trained embeddings is the driving force of why this technique works. We provide open source implementations of our models in both TensorFlow and PyTorch.
Nonconvex Regularized Robust Regression with Oracle Properties in Polynomial Time
Jul 09, 2019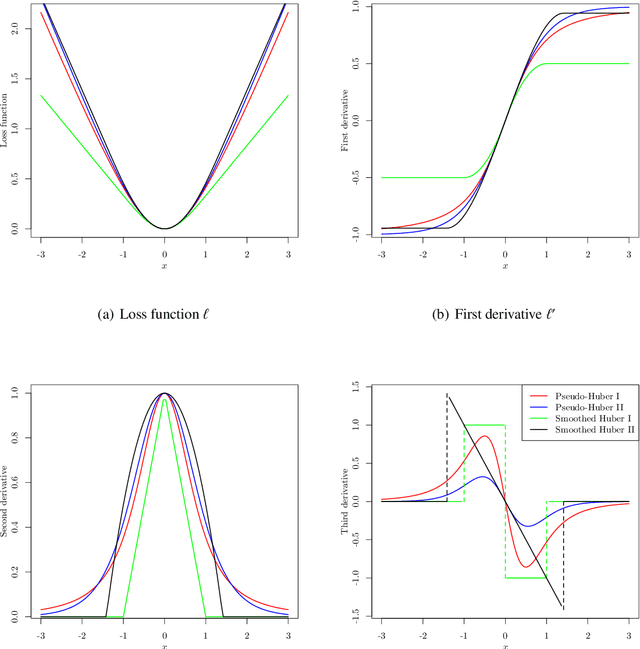
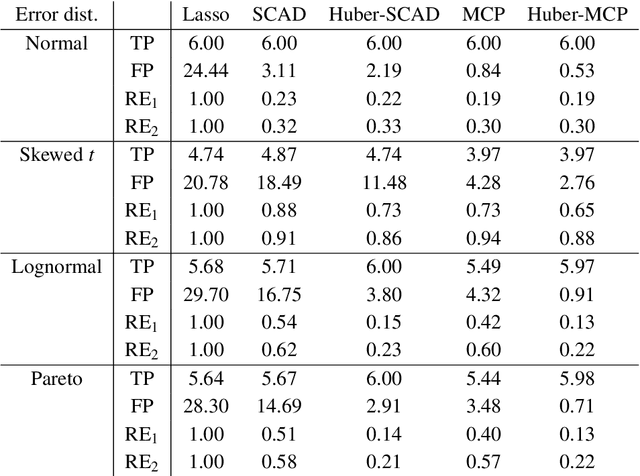
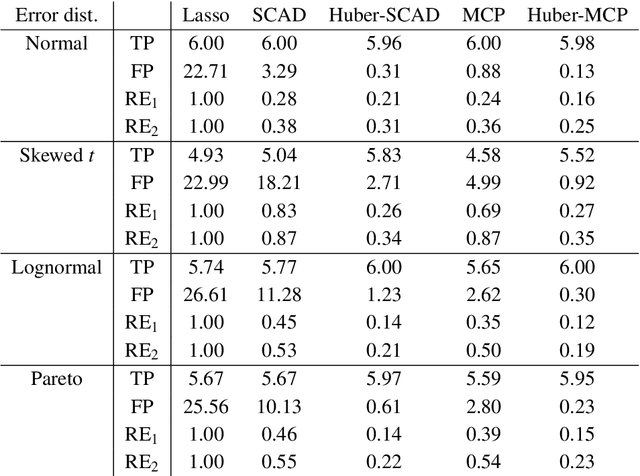
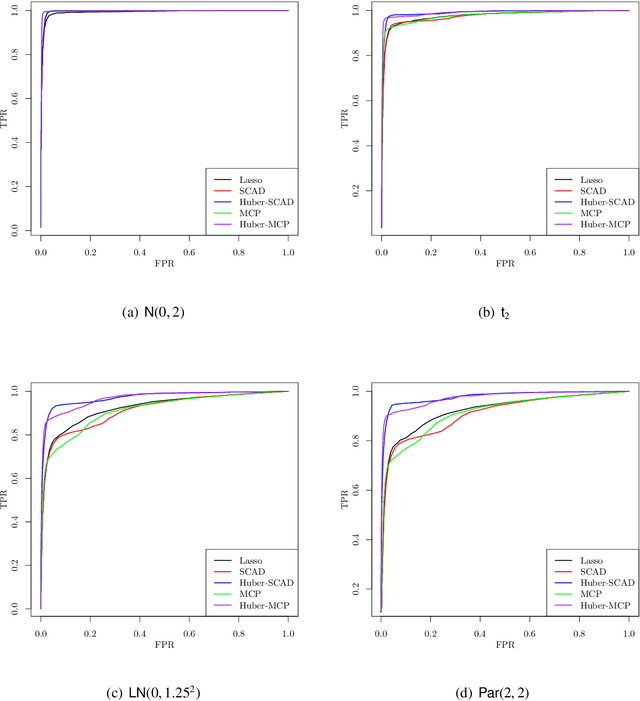
This paper investigates tradeoffs among optimization errors, statistical rates of convergence and the effect of heavy-tailed random errors for high-dimensional adaptive Huber regression with nonconvex regularization. When the additive errors in linear models have only bounded second moment, our results suggest that adaptive Huber regression with nonconvex regularization yields statistically optimal estimators that satisfy oracle properties as if the true underlying support set were known beforehand. Computationally, we need as many as O(log s + log log d) convex relaxations to reach such oracle estimators, where s and d denote the sparsity and ambient dimension, respectively. Numerical studies lend strong support to our methodology and theory.