 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Taking A Closer Look at Synthesis: Fine-grained Attribute Analysis for Person Re-Identification
Oct 29, 2020

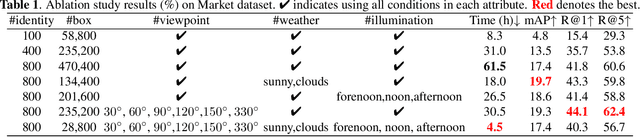


Person re-identification (re-ID) plays an important role in applications such as public security and video surveillance. Recently, learning from synthetic data, which benefits from the popularity of synthetic data engine, has achieved remarkable performance. However, in pursuit of high accuracy, researchers in the academic always focus on training with large-scale datasets at a high cost of time and label expenses, while neglect to explore the potential of performing efficient training from millions of synthetic data. To facilitate development in this field, we reviewed the previously developed synthetic dataset GPR and built an improved one (GPR+) with larger number of identities and distinguished attributes. Based on it, we quantitatively analyze the influence of dataset attribute on re-ID system. To our best knowledge, we are among the first attempts to explicitly dissect person re-ID from the aspect of attribute on synthetic dataset. This research helps us have a deeper understanding of the fundamental problems in person re-ID, which also provides useful insights for dataset building and future practical usage.
Ergodic Control Strategy for Multi-Agent Environment Exploration
Sep 29, 2020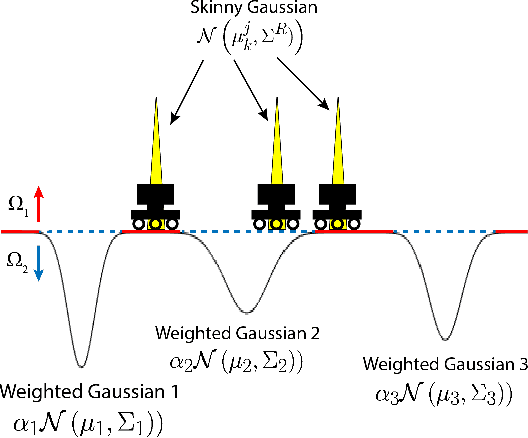
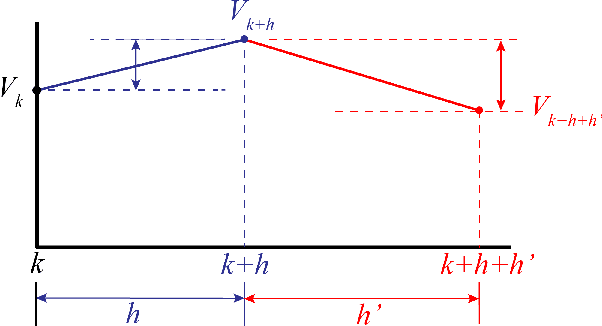
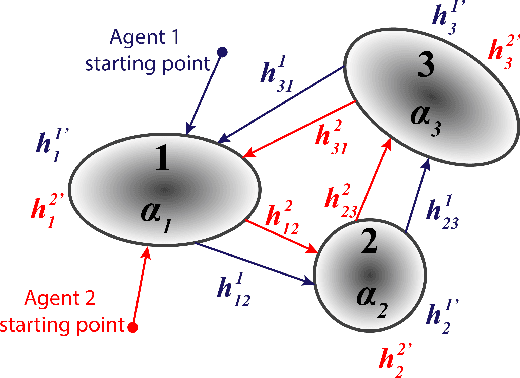
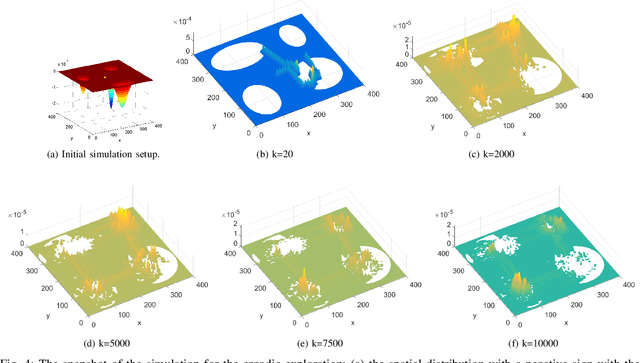
In this study, an ergodic environment exploration problem is introduced for a centralized multi-agent system. Given the reference distribution represented by the Mixture of Gaussian (MoG), the ergodicity is achieved when the time-averaged robot distribution is identical to the given reference distribution. The major challenge associated with this problem is to determine proper timing for a team of agents (robots) to visit each Gaussian component in the reference MoG for ergodicity. The ergodic function is defined as a measure of ergodicity and the condition for convergence is derived based on timing analysis. The proposed control strategy provides relatively reasonable performance to achieve the ergodicity. We provide the formal algorithm for centralized multi-agent control to achieve the ergodicity and simulation results are presented for the validation of the proposed algorithm.
PDFFlow: parton distribution functions on GPU
Sep 14, 2020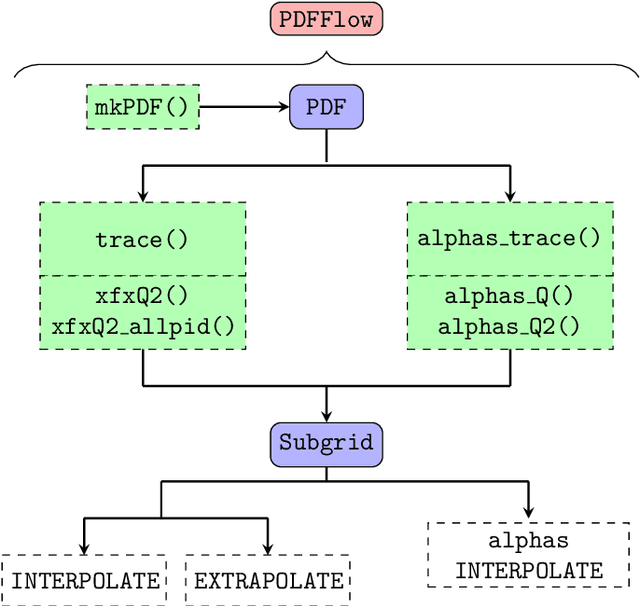

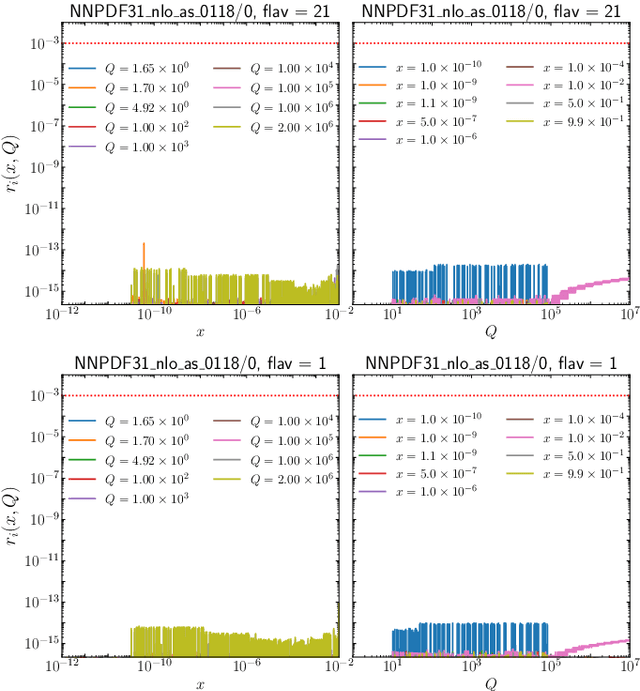
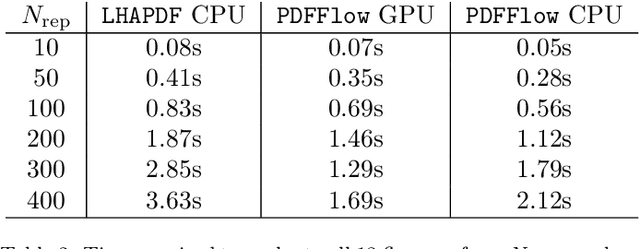
We present PDFFlow, a new software for fast evaluation of parton distribution functions (PDFs) designed for platforms with hardware accelerators. PDFs are essential for the calculation of particle physics observables through Monte Carlo simulation techniques. The evaluation of a generic set of PDFs for quarks and gluon at a given momentum fraction and energy scale requires the implementation of interpolation algorithms as introduced for the first time by the LHAPDF project. PDFFlow extends and implements these interpolation algorithms using Google's TensorFlow library providing the capabilities to perform PDF evaluations taking fully advantage of multi-threading CPU and GPU setups. We benchmark the performance of this library on multiple scenarios relevant for the particle physics community.
Identifying Pairs in Simulated Bio-Medical Time-Series
May 12, 2013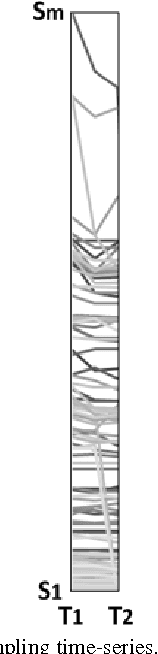
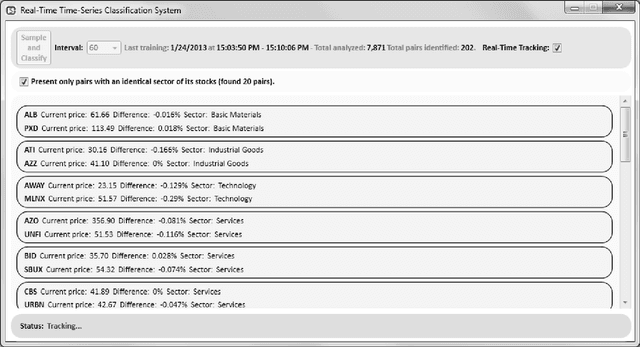
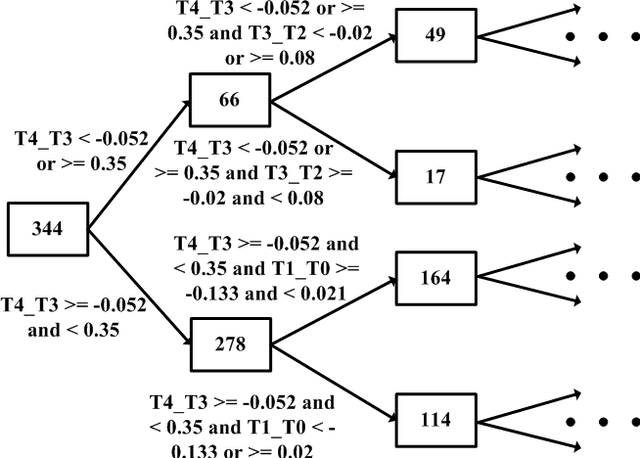

The paper presents a time-series-based classification approach to identify similarities in pairs of simulated human-generated patterns. An example for a pattern is a time-series representing a heart rate during a specific time-range, wherein the time-series is a sequence of data points that represent the changes in the heart rate values. A bio-medical simulator system was developed to acquire a collection of 7,871 price patterns of financial instruments. The financial instruments traded in real-time on three American stock exchanges, NASDAQ, NYSE, and AMEX, simulate bio-medical measurements. The system simulates a human in which each price pattern represents one bio-medical sensor. Data provided during trading hours from the stock exchanges allowed real-time classification. Classification is based on new machine learning techniques: self-labeling, which allows the application of supervised learning methods on unlabeled time-series and similarity ranking, which applied on a decision tree learning algorithm to classify time-series regardless of type and quantity.
Locally adaptive factor processes for multivariate time series
Jun 21, 2013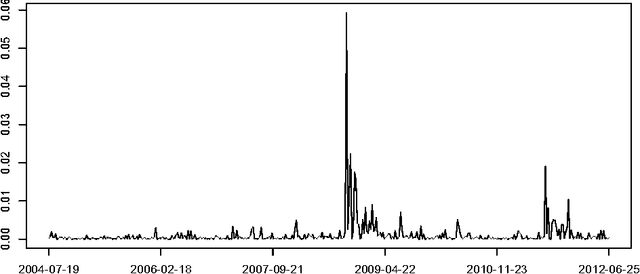
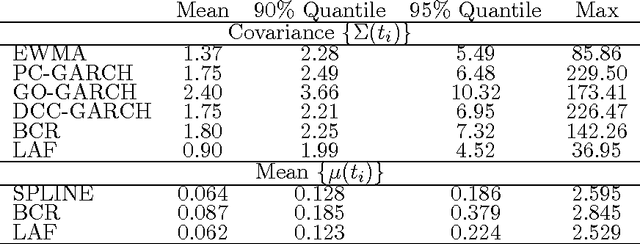
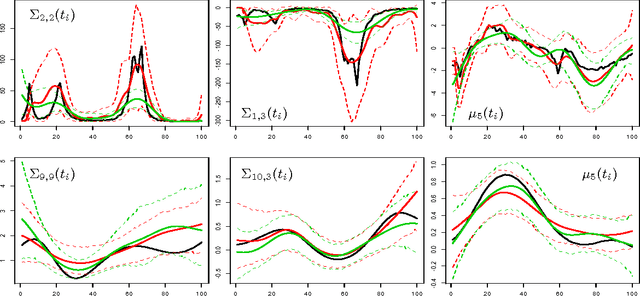
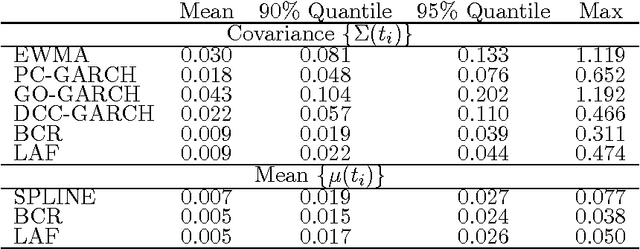
In modeling multivariate time series, it is important to allow time-varying smoothness in the mean and covariance process. In particular, there may be certain time intervals exhibiting rapid changes and others in which changes are slow. If such time-varying smoothness is not accounted for, one can obtain misleading inferences and predictions, with over-smoothing across erratic time intervals and under-smoothing across times exhibiting slow variation. This can lead to mis-calibration of predictive intervals, which can be substantially too narrow or wide depending on the time. We propose a locally adaptive factor process for characterizing multivariate mean-covariance changes in continuous time, allowing locally varying smoothness in both the mean and covariance matrix. This process is constructed utilizing latent dictionary functions evolving in time through nested Gaussian processes and linearly related to the observed data with a sparse mapping. Using a differential equation representation, we bypass usual computational bottlenecks in obtaining MCMC and online algorithms for approximate Bayesian inference. The performance is assessed in simulations and illustrated in a financial application.
Prostate motion modelling using biomechanically-trained deep neural networks on unstructured nodes
Jul 09, 2020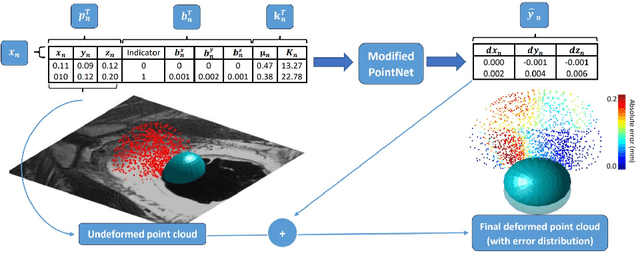
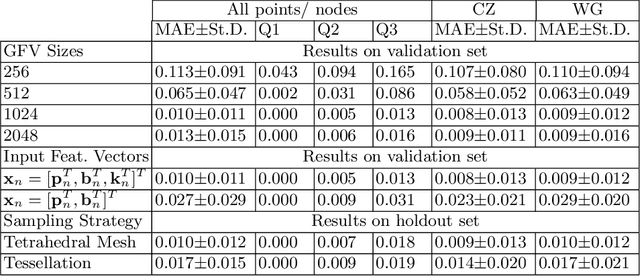
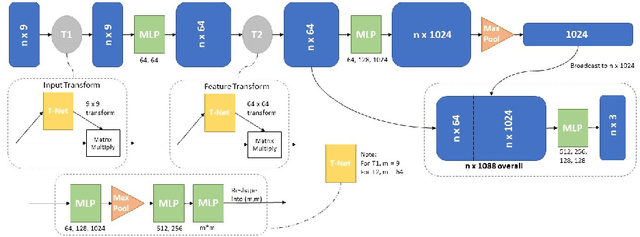
In this paper, we propose to train deep neural networks with biomechanical simulations, to predict the prostate motion encountered during ultrasound-guided interventions. In this application, unstructured points are sampled from segmented pre-operative MR images to represent the anatomical regions of interest. The point sets are then assigned with point-specific material properties and displacement loads, forming the un-ordered input feature vectors. An adapted PointNet can be trained to predict the nodal displacements, using finite element (FE) simulations as ground-truth data. Furthermore, a versatile bootstrap aggregating mechanism is validated to accommodate the variable number of feature vectors due to different patient geometries, comprised of a training-time bootstrap sampling and a model averaging inference. This results in a fast and accurate approximation to the FE solutions without requiring subject-specific solid meshing. Based on 160,000 nonlinear FE simulations on clinical imaging data from 320 patients, we demonstrate that the trained networks generalise to unstructured point sets sampled directly from holdout patient segmentation, yielding a near real-time inference and an expected error of 0.017 mm in predicted nodal displacement.
A Reference Software Architecture for Social Robots
Jul 09, 2020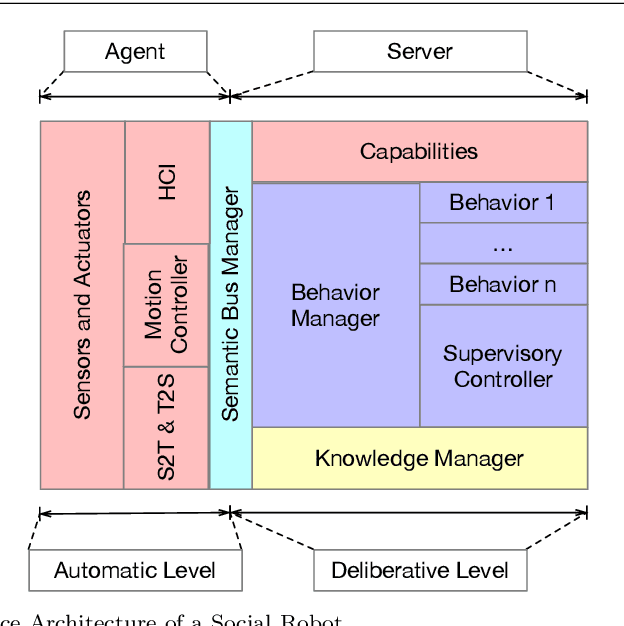
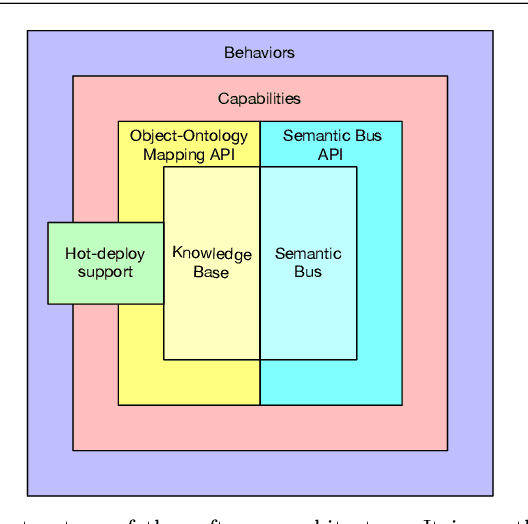
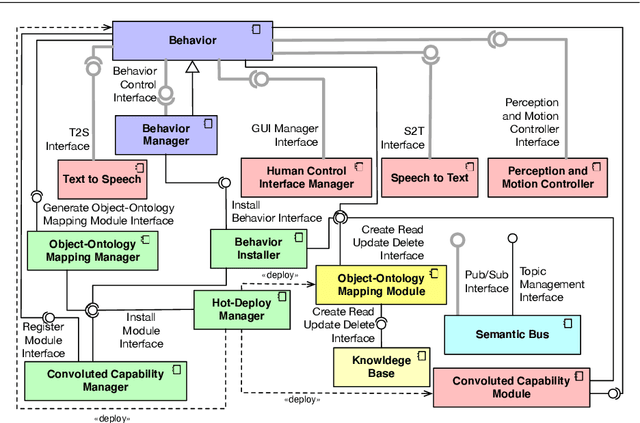
Social Robotics poses tough challenges to software designers who are required to take care of difficult architectural drivers like acceptability, trust of robots as well as to guarantee that robots establish a personalised interaction with their users. Moreover, in this context recurrent software design issues such as ensuring interoperability, improving reusability and customizability of software components also arise. Designing and implementing social robotic software architectures is a time-intensive activity requiring multi-disciplinary expertise: this makes difficult to rapidly develop, customise, and personalise robotic solutions. These challenges may be mitigated at design time by choosing certain architectural styles, implementing specific architectural patterns and using particular technologies. Leveraging on our experience in the MARIO project, in this paper we propose a series of principles that social robots may benefit from. These principles lay also the foundations for the design of a reference software architecture for Social Robots. The ultimate goal of this work is to establish a common ground based on a reference software architecture to allow to easily reuse robotic software components in order to rapidly develop, implement, and personalise Social Robots.
Properly Learning Poisson Binomial Distributions in Almost Polynomial Time
Nov 12, 2015We give an algorithm for properly learning Poisson binomial distributions. A Poisson binomial distribution (PBD) of order $n$ is the discrete probability distribution of the sum of $n$ mutually independent Bernoulli random variables. Given $\widetilde{O}(1/\epsilon^2)$ samples from an unknown PBD $\mathbf{p}$, our algorithm runs in time $(1/\epsilon)^{O(\log \log (1/\epsilon))}$, and outputs a hypothesis PBD that is $\epsilon$-close to $\mathbf{p}$ in total variation distance. The previously best known running time for properly learning PBDs was $(1/\epsilon)^{O(\log(1/\epsilon))}$. As one of our main contributions, we provide a novel structural characterization of PBDs. We prove that, for all $\epsilon >0,$ there exists an explicit collection $\cal{M}$ of $(1/\epsilon)^{O(\log \log (1/\epsilon))}$ vectors of multiplicities, such that for any PBD $\mathbf{p}$ there exists a PBD $\mathbf{q}$ with $O(\log(1/\epsilon))$ distinct parameters whose multiplicities are given by some element of ${\cal M}$, such that $\mathbf{q}$ is $\epsilon$-close to $\mathbf{p}$. Our proof combines tools from Fourier analysis and algebraic geometry. Our approach to the proper learning problem is as follows: Starting with an accurate non-proper hypothesis, we fit a PBD to this hypothesis. More specifically, we essentially start with the hypothesis computed by the computationally efficient non-proper learning algorithm in our recent work~\cite{DKS15}. Our aforementioned structural characterization allows us to reduce the corresponding fitting problem to a collection of $(1/\epsilon)^{O(\log \log(1/\epsilon))}$ systems of low-degree polynomial inequalities. We show that each such system can be solved in time $(1/\epsilon)^{O(\log \log(1/\epsilon))}$, which yields the overall running time of our algorithm.
Online Initialization and Extrinsic Spatial-Temporal Calibration for Monocular Visual-Inertial Odometry
Apr 12, 2020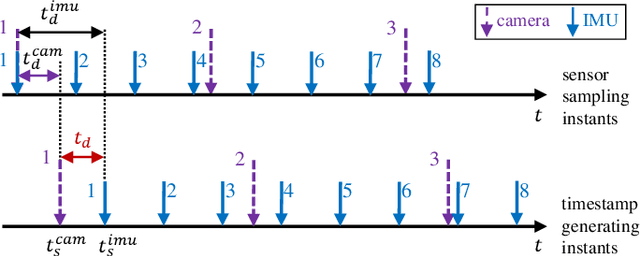
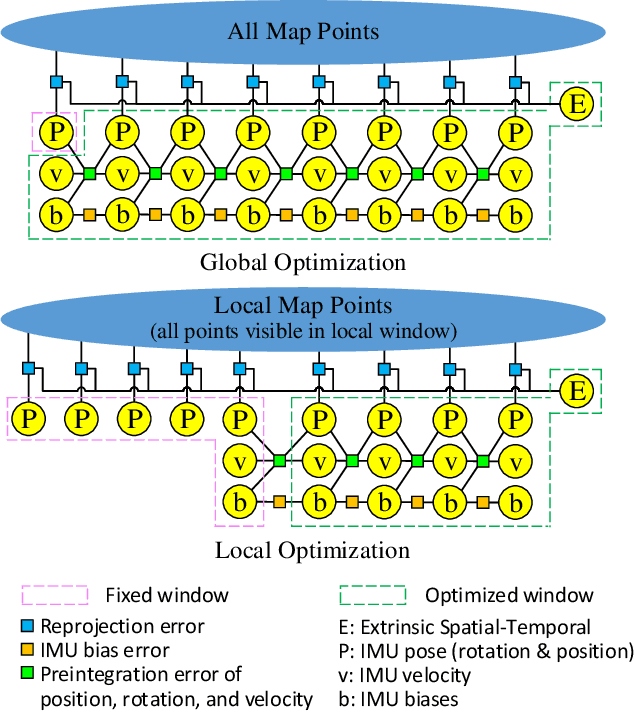
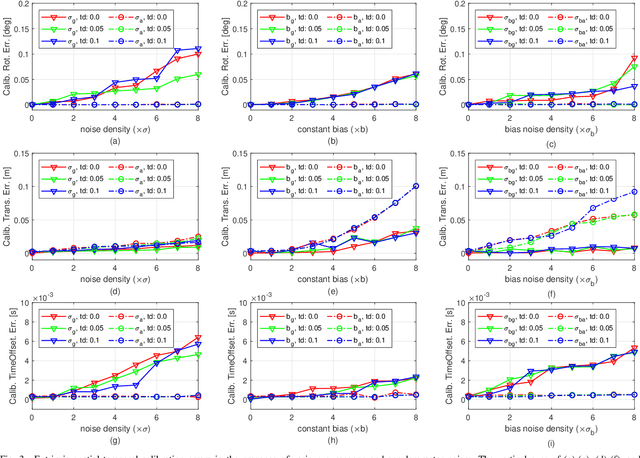
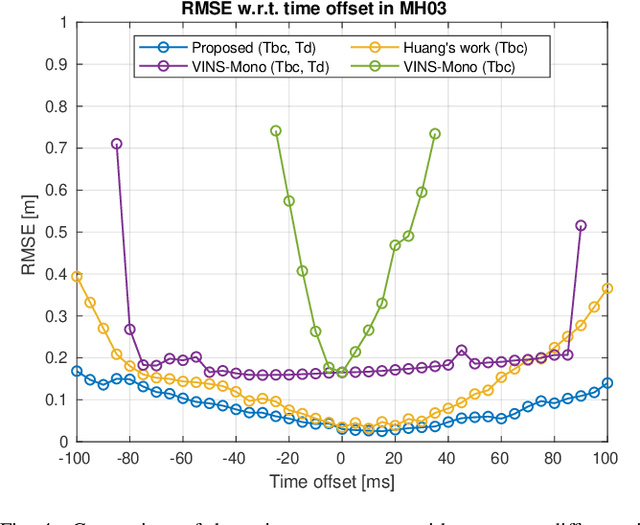
This paper presents an online initialization method for bootstrapping the optimization-based monocular visual-inertial odometry (VIO). The method can online calibrate the relative transformation (spatial) and time offsets (temporal) among camera and IMU, as well as estimate the initial values of metric scale, velocity, gravity, gyroscope bias, and accelerometer bias during the initialization stage. To compensate for the impact of time offset, our method includes two short-term motion interpolation algorithms for the camera and IMU pose estimation. Besides, it includes a three-step process to incrementally estimate the parameters from coarse to fine. First, the extrinsic rotation, gyroscope bias, and time offset are estimated by minimizing the rotation difference between the camera and IMU. Second, the metric scale, gravity, and extrinsic translation are approximately estimated by using the compensated camera poses and ignoring the accelerometer bias. Third, these values are refined by taking into account the accelerometer bias and the gravitational magnitude. For further optimizing the system states, a nonlinear optimization algorithm, which considers the time offset, is introduced for global and local optimization. Experimental results on public datasets show that the initial values and the extrinsic parameters, as well as the sensor poses, can be accurately estimated by the proposed method.
Optimal Path Planning for Automated Dimensional Inspection of Free-Form Surfaces
May 15, 2020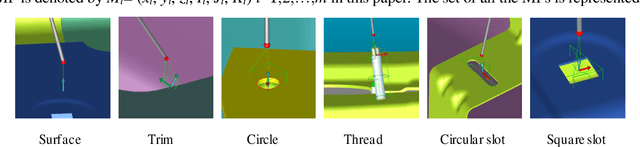

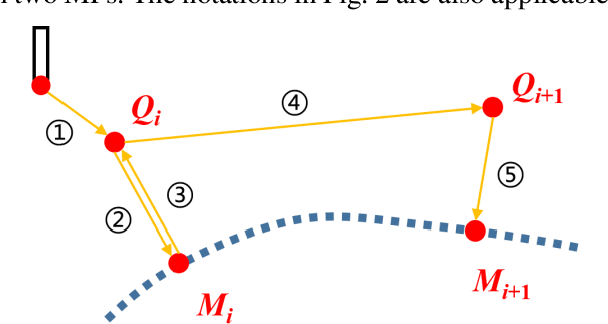
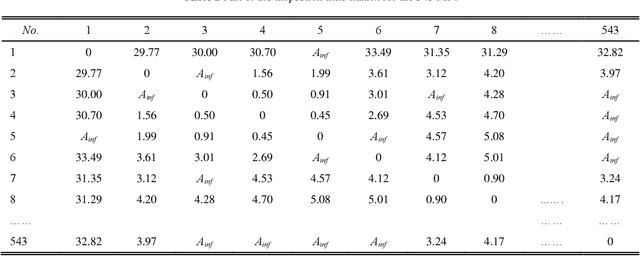
Structural dimensional inspection is vital for the process monitoring, quality control, and fault diagnosis in the mass production of auto bodies. Comparing with the non-contact measurement, the high-precision five-axis measuring machine with the touch-trigger probe is a preferred choice for data collection. It can assist manufacturers in making accurate inspection quickly. As the increase of free-form surfaces and diverse surface orientations in auto body design, existing inspection approaches cannot capture some new critical features in the curvature of auto bodies in an efficient way. Therefore, we need to develop new path planning methods for automated dimensional inspection of free-form surfaces. This paper proposes an optimal path planning system for automated programming of measuring point inspection by incorporating probe rotations and effective collision detection. Specifically, the methodological contributions include: (i) a dynamic searching volume-based algorithm is developed to detect potential collisions in the local path between measurement points; (ii) a local path generation method is proposed with the integration of the probe trajectory and the stylus rotation. Then, the inspection time matrix is proposed to quantify the measuring time of diverse local paths; (iii) an optimization approach of the global inspection path for all critical points on the auto body is developed to minimize the total inspection time. A case study has been conducted on an auto body to verify the performance of the proposed method. Results show that the collision-free path for the free-form auto body could be generated automatically with off-line programming, and the proposed method produces about 40% fewer dummy points and needs 32% less movement time in the auto body inspection process.