 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaking A Closer Look at Synthesis: Fine-grained Attribute Analysis for Person Re-Identification
Paper and Code

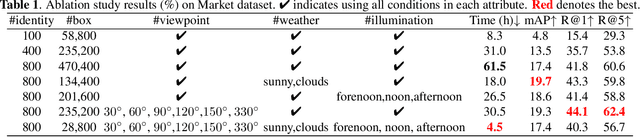


Person re-identification (re-ID) plays an important role in applications such as public security and video surveillance. Recently, learning from synthetic data, which benefits from the popularity of synthetic data engine, has achieved remarkable performance. However, in pursuit of high accuracy, researchers in the academic always focus on training with large-scale datasets at a high cost of time and label expenses, while neglect to explore the potential of performing efficient training from millions of synthetic data. To facilitate development in this field, we reviewed the previously developed synthetic dataset GPR and built an improved one (GPR+) with larger number of identities and distinguished attributes. Based on it, we quantitatively analyze the influence of dataset attribute on re-ID system. To our best knowledge, we are among the first attempts to explicitly dissect person re-ID from the aspect of attribute on synthetic dataset. This research helps us have a deeper understanding of the fundamental problems in person re-ID, which also provides useful insights for dataset building and future practical usage.