 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FedGAN: Federated Generative Adversarial Networks for Distributed Data
Jun 15, 2020
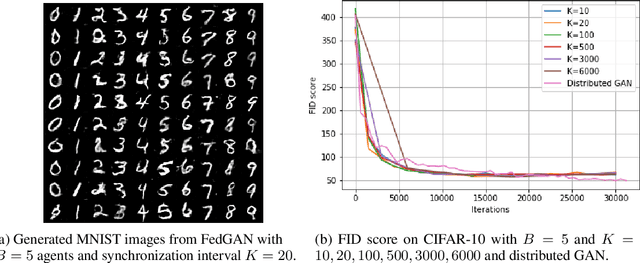
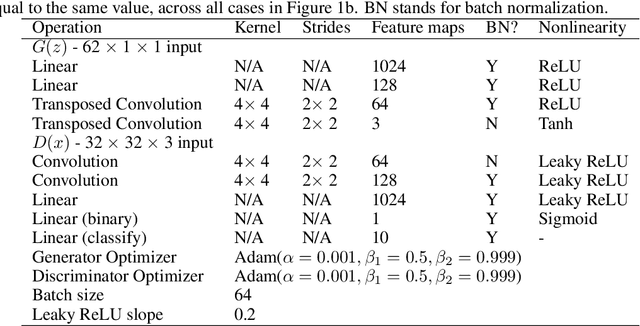
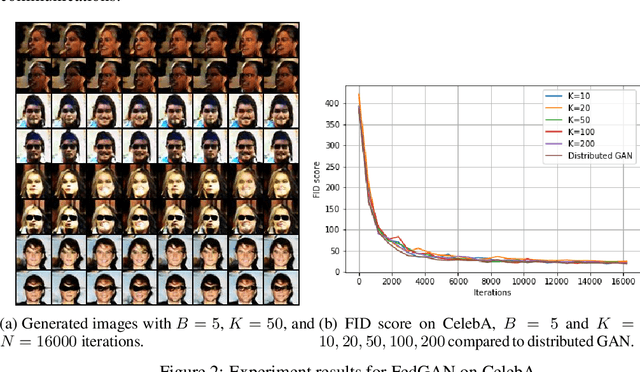
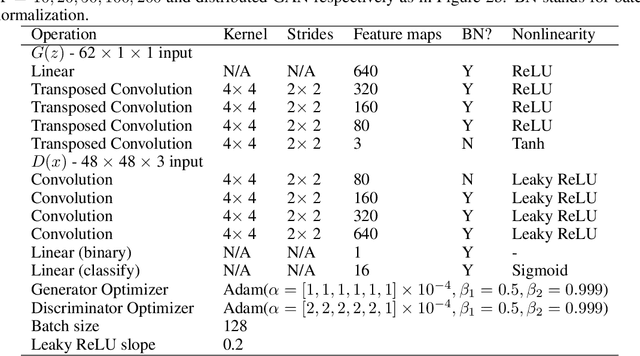
We propose Federated Generative Adversarial Network (FedGAN) for training a GAN across distributed sources of non-independent-and-identically-distributed data sources subject to communication and privacy constraints. Our algorithm uses local generators and discriminators which are periodically synced via an intermediary that averages and broadcasts the generator and discriminator parameters. We theoretically prove the convergence of FedGAN with both equal and two time-scale updates of generator and discriminator, under standard assumptions, using stochastic approximations and communication efficient stochastic gradient descents. We experiment FedGAN on toy examples (2D system, mixed Gaussian, and Swiss role), image datasets (MNIST, CIFAR-10, and CelebA), and time series datasets (household electricity consumption and electric vehicle charging sessions). We show FedGAN converges and has similar performance to general distributed GAN, while reduces communication complexity. We also show its robustness to reduced communications.
Learning Representations from Temporally Smooth Data
Dec 12, 2020
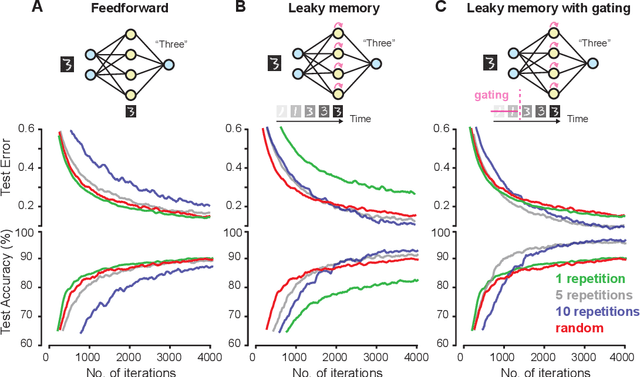
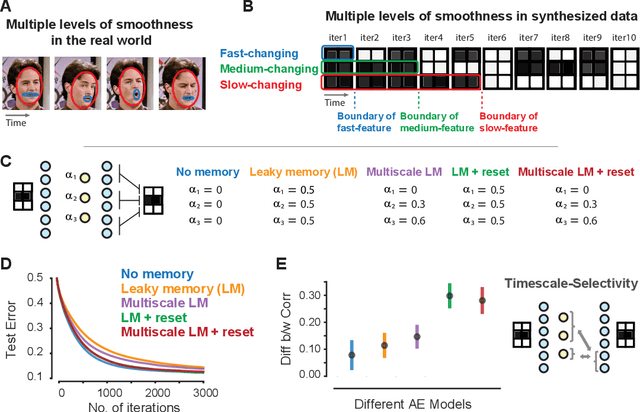
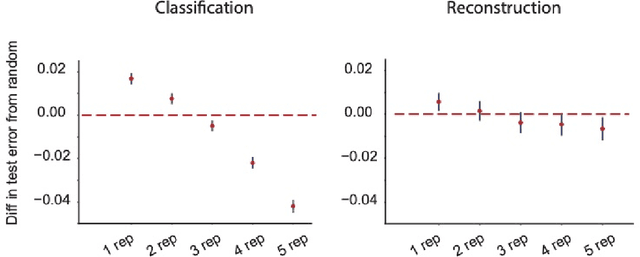
Events in the real world are correlated across nearby points in time, and we must learn from this temporally smooth data. However, when neural networks are trained to categorize or reconstruct single items, the common practice is to randomize the order of training items. What are the effects of temporally smooth training data on the efficiency of learning? We first tested the effects of smoothness in training data on incremental learning in feedforward nets and found that smoother data slowed learning. Moreover, sampling so as to minimize temporal smoothness produced more efficient learning than sampling randomly. If smoothness generally impairs incremental learning, then how can networks be modified to benefit from smoothness in the training data? We hypothesized that two simple brain-inspired mechanisms, leaky memory in activation units and memory-gating, could enable networks to rapidly extract useful representations from smooth data. Across all levels of data smoothness, these brain-inspired architectures achieved more efficient category learning than feedforward networks. This advantage persisted, even when leaky memory networks with gating were trained on smooth data and tested on randomly-ordered data. Finally, we investigated how these brain-inspired mechanisms altered the internal representations learned by the networks. We found that networks with multi-scale leaky memory and memory-gating could learn internal representations that un-mixed data sources which vary on fast and slow timescales across training samples. Altogether, we identified simple mechanisms enabling neural networks to learn more quickly from temporally smooth data, and to generate internal representations that separate timescales in the training signal.
Domain Concretization from Examples: Addressing Missing Domain Knowledge via Robust Planning
Nov 18, 2020
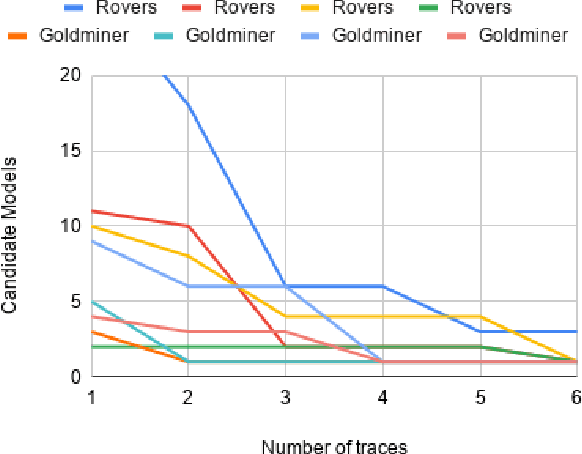
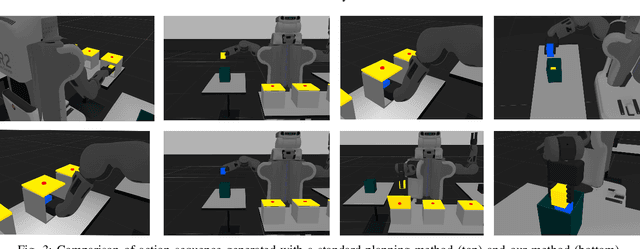
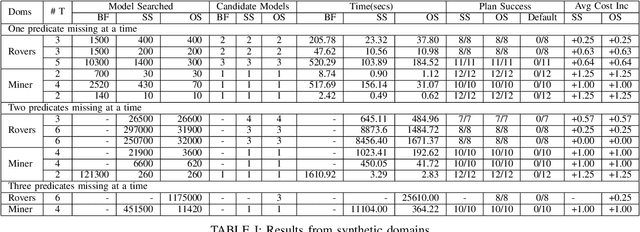
The assumption of complete domain knowledge is not warranted for robot planning and decision-making in the real world. It could be due to design flaws or arise from domain ramifications or qualifications. In such cases, existing planning and learning algorithms could produce highly undesirable behaviors. This problem is more challenging than partial observability in the sense that the agent is unaware of certain knowledge, in contrast to it being partially observable: the difference between known unknowns and unknown unknowns. In this work, we formulate it as the problem of Domain Concretization, an inverse problem to domain abstraction. Based on an incomplete domain model provided by the designer and teacher traces from human users, our algorithm searches for a candidate model set under a minimalistic model assumption. It then generates a robust plan with the maximum probability of success under the set of candidate models. In addition to a standard search formulation in the model-space, we propose a sample-based search method and also an online version of it to improve search time. We tested our approach on IPC domains and a simulated robotics domain where incompleteness was introduced by removing domain features from the complete model. Results show that our planning algorithm increases the plan success rate without impacting the cost much.
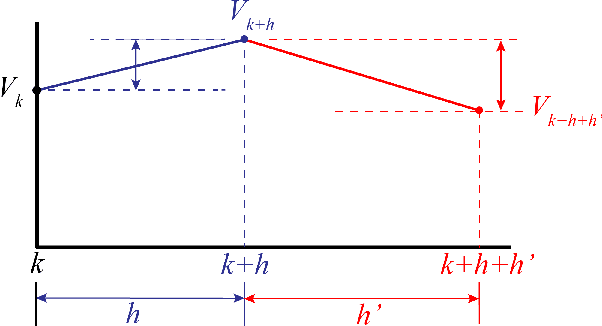
Predicting the Future Behavior of a Time-Varying Probability Distribution
Nov 20, 2014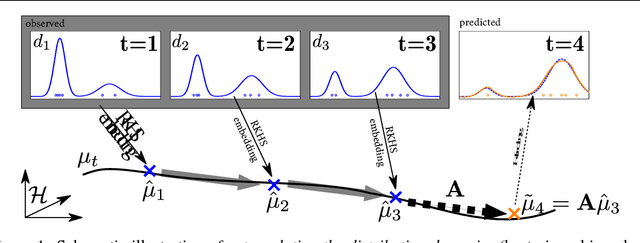
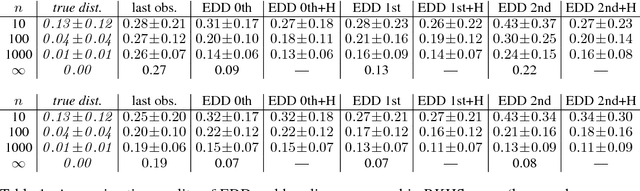


We study the problem of predicting the future, though only in the probabilistic sense of estimating a future state of a time-varying probability distribution. This is not only an interesting academic problem, but solving this extrapolation problem also has many practical application, e.g. for training classifiers that have to operate under time-varying conditions. Our main contribution is a method for predicting the next step of the time-varying distribution from a given sequence of sample sets from earlier time steps. For this we rely on two recent machine learning techniques: embedding probability distributions into a reproducing kernel Hilbert space, and learning operators by vector-valued regression. We illustrate the working principles and the practical usefulness of our method by experiments on synthetic and real data. We also highlight an exemplary application: training a classifier in a domain adaptation setting without having access to examples from the test time distribution at training time.
Taking A Closer Look at Synthesis: Fine-grained Attribute Analysis for Person Re-Identification
Oct 29, 2020
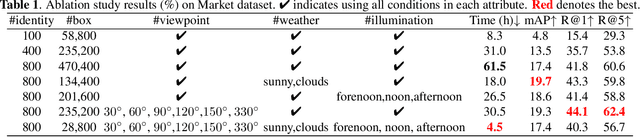


Person re-identification (re-ID) plays an important role in applications such as public security and video surveillance. Recently, learning from synthetic data, which benefits from the popularity of synthetic data engine, has achieved remarkable performance. However, in pursuit of high accuracy, researchers in the academic always focus on training with large-scale datasets at a high cost of time and label expenses, while neglect to explore the potential of performing efficient training from millions of synthetic data. To facilitate development in this field, we reviewed the previously developed synthetic dataset GPR and built an improved one (GPR+) with larger number of identities and distinguished attributes. Based on it, we quantitatively analyze the influence of dataset attribute on re-ID system. To our best knowledge, we are among the first attempts to explicitly dissect person re-ID from the aspect of attribute on synthetic dataset. This research helps us have a deeper understanding of the fundamental problems in person re-ID, which also provides useful insights for dataset building and future practical usage.
IntelligentPooling: Practical Thompson Sampling for mHealth
Jul 31, 2020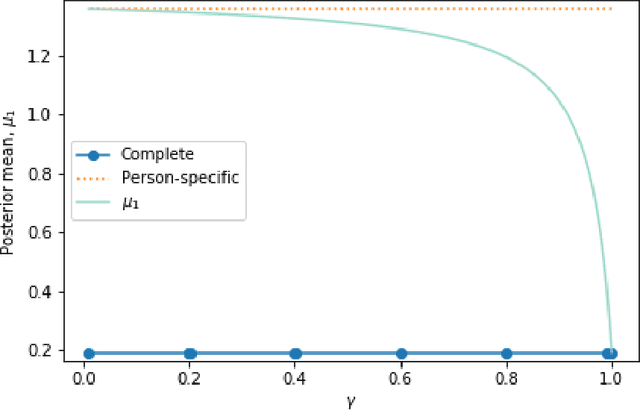
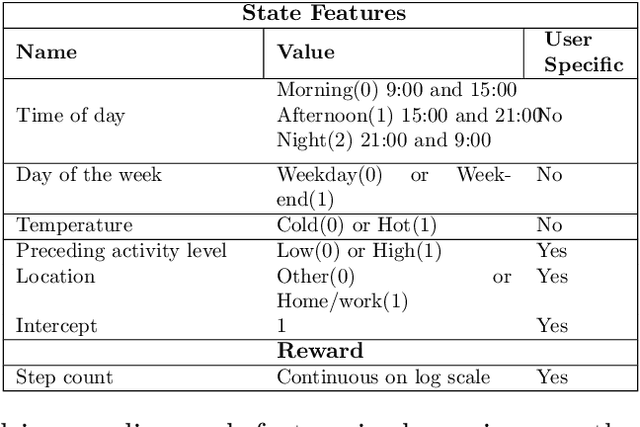
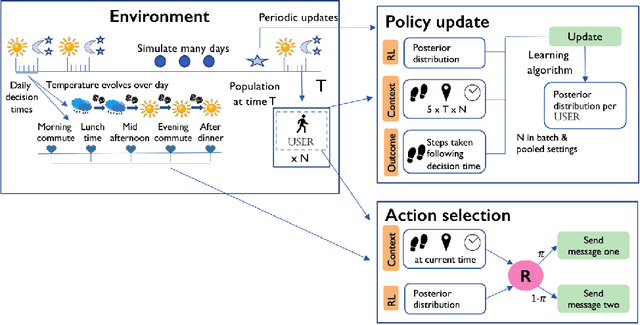

In mobile health (mHealth) smart devices deliver behavioral treatments repeatedly over time to a user with the goal of helping the user adopt and maintain healthy behaviors. Reinforcement learning appears ideal for learning how to optimally make these sequential treatment decisions. However, significant challenges must be overcome before reinforcement learning can be effectively deployed in a mobile healthcare setting. In this work we are concerned with the following challenges: 1) individuals who are in the same context can exhibit differential response to treatments 2) only a limited amount of data is available for learning on any one individual, and 3) non-stationary responses to treatment. To address these challenges we generalize Thompson-Sampling bandit algorithms to develop IntelligentPooling. IntelligentPooling learns personalized treatment policies thus addressing challenge one. To address the second challenge, IntelligentPooling updates each user's degree of personalization while making use of available data on other users to speed up learning. Lastly, IntelligentPooling allows responsivity to vary as a function of a user's time since beginning treatment, thus addressing challenge three. We show that IntelligentPooling achieves an average of 26% lower regret than state-of-the-art. We demonstrate the promise of this approach and its ability to learn from even a small group of users in a live clinical trial.
Clinical Risk Prediction with Temporal Probabilistic Asymmetric Multi-Task Learning
Jun 23, 2020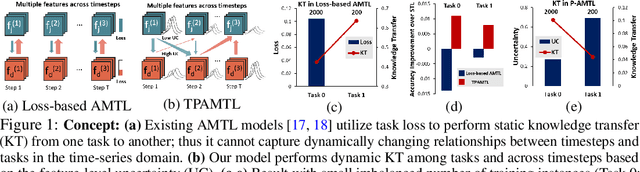

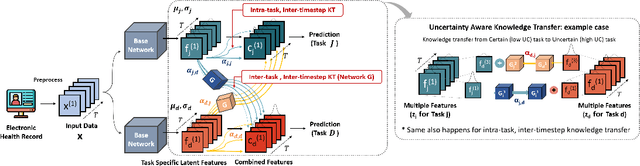
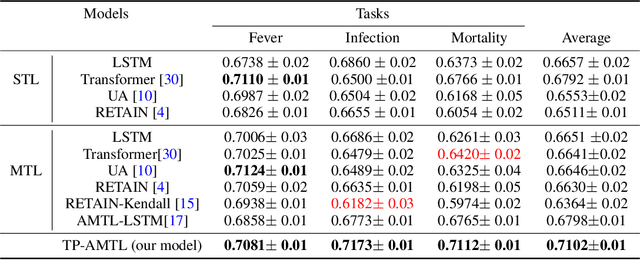
Although recent multi-task learning methods have shown to be effective in improving the generalization of deep neural networks, they should be used with caution for safety-critical applications, such as clinical risk prediction. This is because even if they achieve improved task-average performance, they may still yield degraded performance on individual tasks, which may be critical (e.g., prediction of mortality risk). Existing asymmetric multi-task learning methods tackle this negative transfer problem by performing knowledge transfer from tasks with low loss to tasks with high loss. However, using loss as a measure of reliability is risky since it could be a result of overfitting. In the case of time-series prediction tasks, knowledge learned for one task (e.g., predicting the sepsis onset) at a specific timestep may be useful for learning another task (e.g., prediction of mortality) at a later timestep, but lack of loss at each timestep makes it difficult to measure the reliability at each timestep. To capture such dynamically changing asymmetric relationships between tasks in time-series data, we propose a novel temporal asymmetric multi-task learning model that performs knowledge transfer from certain tasks/timesteps to relevant uncertain tasks, based on feature-level uncertainty. We validate our model on multiple clinical risk prediction tasks against various deep learning models for time-series prediction, which our model significantly outperforms, without any sign of negative transfer. Further qualitative analysis of learned knowledge graphs by clinicians shows that they are helpful in analyzing the predictions of the model. Our final code is available at https://github.com/anhtuan5696/TPAMTL.
Ergodic Control Strategy for Multi-Agent Environment Exploration
Sep 29, 2020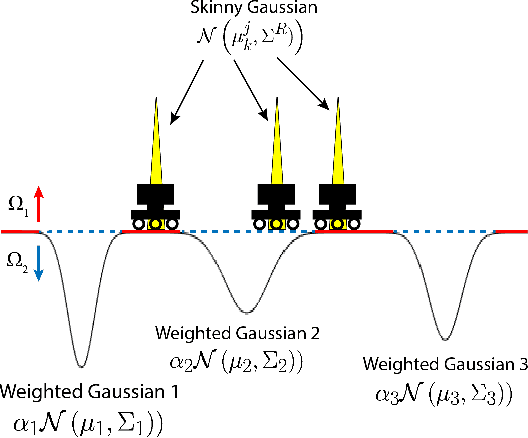
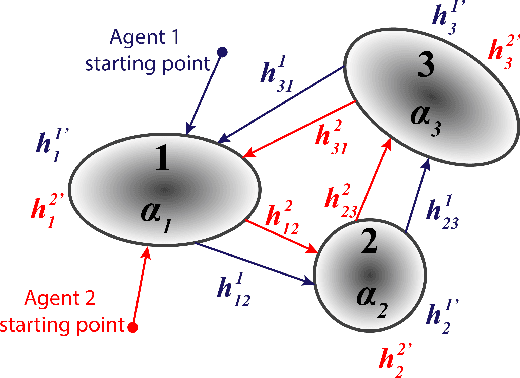
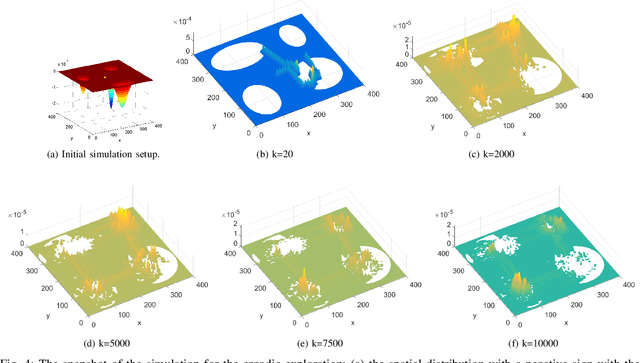
In this study, an ergodic environment exploration problem is introduced for a centralized multi-agent system. Given the reference distribution represented by the Mixture of Gaussian (MoG), the ergodicity is achieved when the time-averaged robot distribution is identical to the given reference distribution. The major challenge associated with this problem is to determine proper timing for a team of agents (robots) to visit each Gaussian component in the reference MoG for ergodicity. The ergodic function is defined as a measure of ergodicity and the condition for convergence is derived based on timing analysis. The proposed control strategy provides relatively reasonable performance to achieve the ergodicity. We provide the formal algorithm for centralized multi-agent control to achieve the ergodicity and simulation results are presented for the validation of the proposed algorithm.
PDFFlow: parton distribution functions on GPU
Sep 14, 2020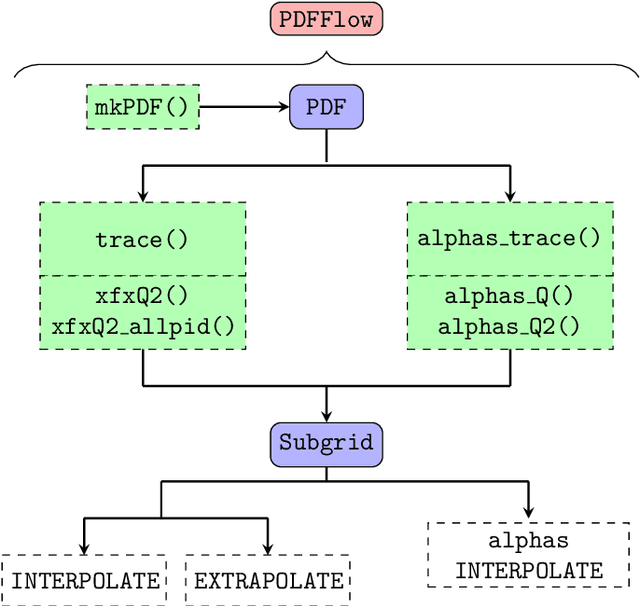

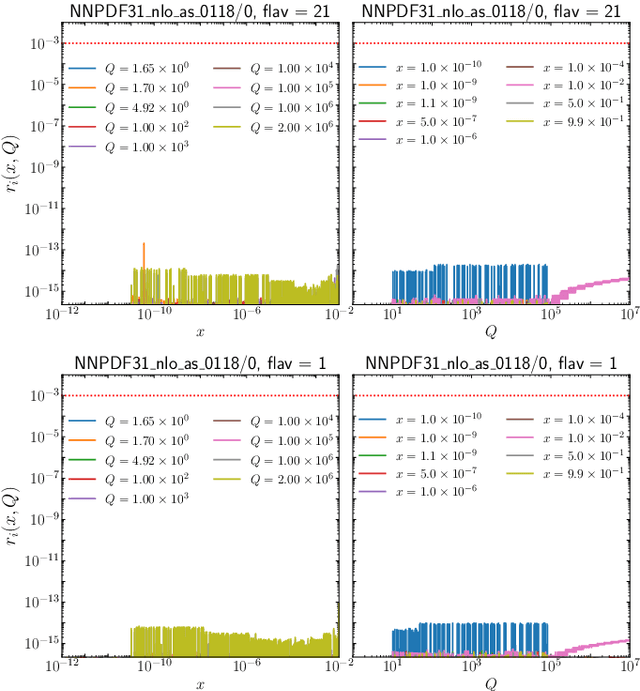
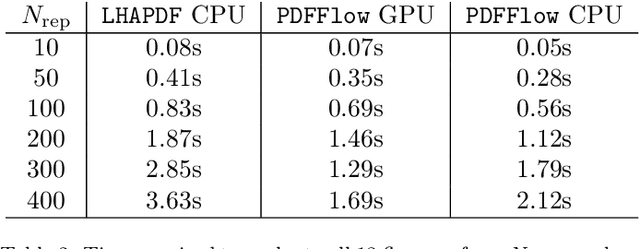
We present PDFFlow, a new software for fast evaluation of parton distribution functions (PDFs) designed for platforms with hardware accelerators. PDFs are essential for the calculation of particle physics observables through Monte Carlo simulation techniques. The evaluation of a generic set of PDFs for quarks and gluon at a given momentum fraction and energy scale requires the implementation of interpolation algorithms as introduced for the first time by the LHAPDF project. PDFFlow extends and implements these interpolation algorithms using Google's TensorFlow library providing the capabilities to perform PDF evaluations taking fully advantage of multi-threading CPU and GPU setups. We benchmark the performance of this library on multiple scenarios relevant for the particle physics community.
Scalable Influence Maximization for Multiple Products in Continuous-Time Diffusion Networks
Jan 29, 2017
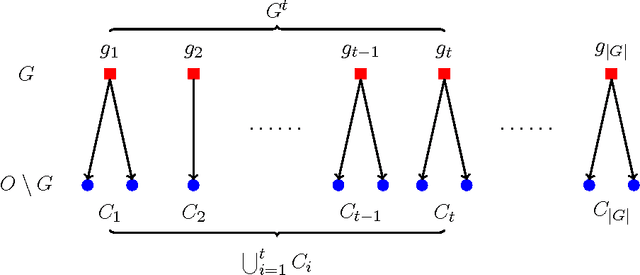
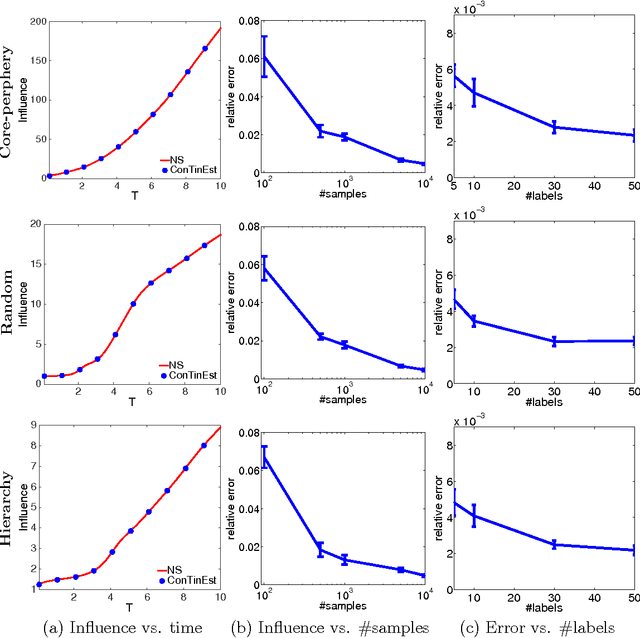
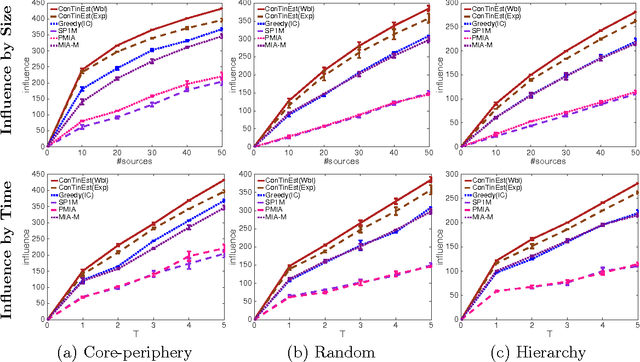
A typical viral marketing model identifies influential users in a social network to maximize a single product adoption assuming unlimited user attention, campaign budgets, and time. In reality, multiple products need campaigns, users have limited attention, convincing users incurs costs, and advertisers have limited budgets and expect the adoptions to be maximized soon. Facing these user, monetary, and timing constraints, we formulate the problem as a submodular maximization task in a continuous-time diffusion model under the intersection of a matroid and multiple knapsack constraints. We propose a randomized algorithm estimating the user influence in a network ($|\mathcal{V}|$ nodes, $|\mathcal{E}|$ edges) to an accuracy of $\epsilon$ with $n=\mathcal{O}(1/\epsilon^2)$ randomizations and $\tilde{\mathcal{O}}(n|\mathcal{E}|+n|\mathcal{V}|)$ computations. By exploiting the influence estimation algorithm as a subroutine, we develop an adaptive threshold greedy algorithm achieving an approximation factor $k_a/(2+2 k)$ of the optimal when $k_a$ out of the $k$ knapsack constraints are active. Extensive experiments on networks of millions of nodes demonstrate that the proposed algorithms achieve the state-of-the-art in terms of effectiveness and scalability.