 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sparse-View Spectral CT Reconstruction Using Deep Learning
Nov 30, 2020

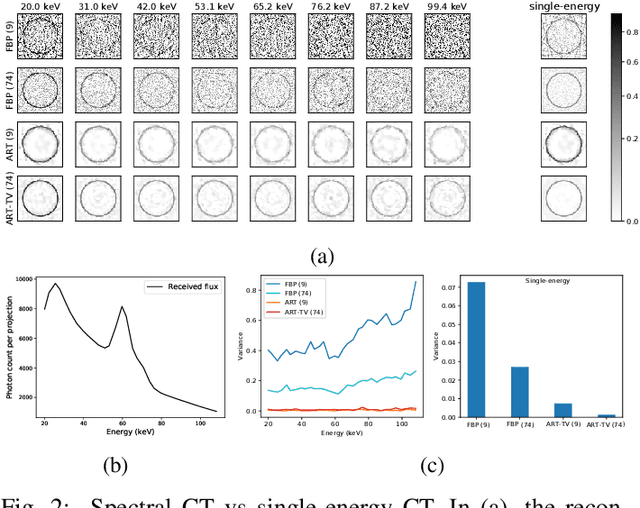
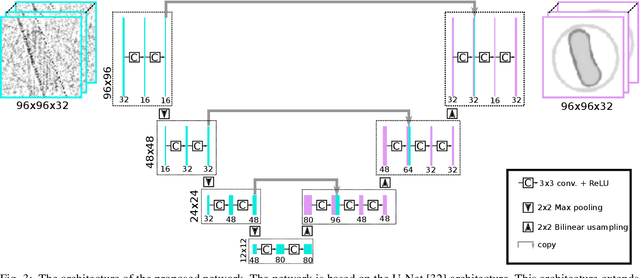

Spectral CT is an emerging technology capable of providing high chemical specificity, which is crucial for many applications such as detecting threats in luggage. Such applications often require both fast and high-quality image reconstruction based on sparse-view (few) projections. The conventional FBP method is fast but it produces low-quality images dominated by noise and artifacts when few projections are available. Iterative methods with, e.g., TV regularizers can circumvent that but they are computationally expensive, with the computational load proportionally increasing with the number of spectral channels. Instead, we propose an approach for fast reconstruction of sparse-view spectral CT data using U-Net with multi-channel input and output. The network is trained to output high-quality images from input images reconstructed by FBP. The network is fast at run-time and because the internal convolutions are shared between the channels, the computation load increases only at the first and last layers, making it an efficient approach to process spectral data with a large number of channels. We validated our approach using real CT scans. The results show qualitatively and quantitatively that our approach is able to outperform the state-of-the-art iterative methods. Furthermore, the results indicate that the network is able to exploit the coupling of the channels to enhance the overall quality and robustness.
Malaria detection from RBC images using shallow Convolutional Neural Networks
Oct 22, 2020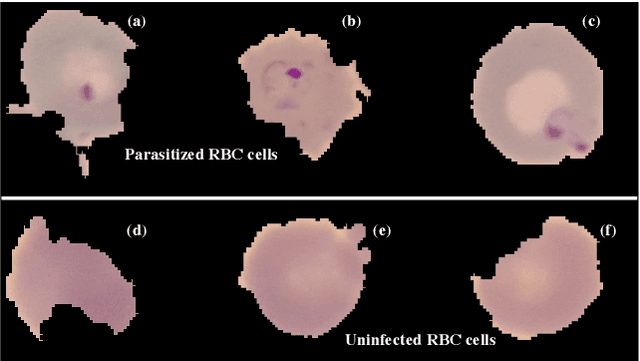
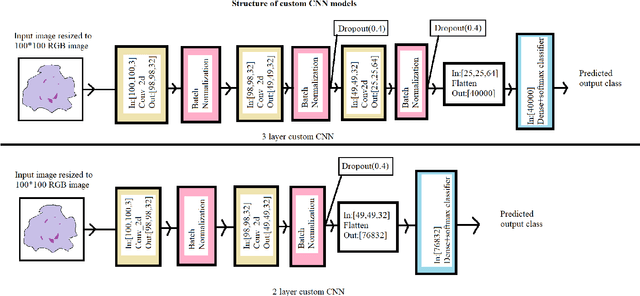
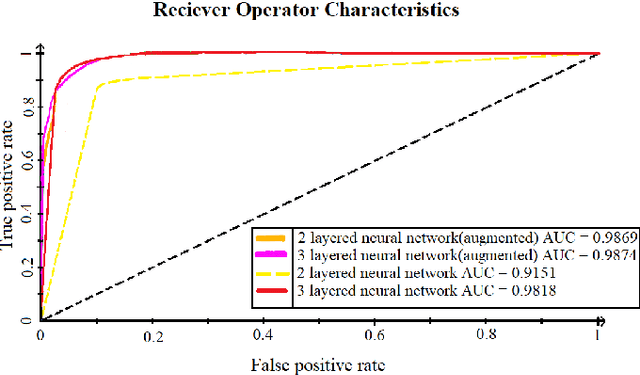
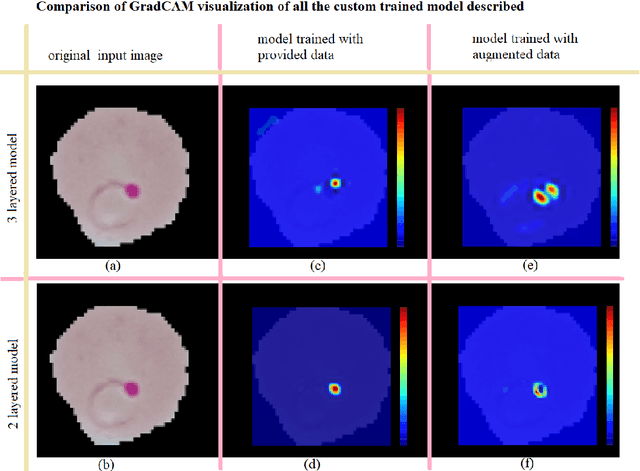
The advent of Deep Learning models like VGG-16 and Resnet-50 has considerably revolutionized the field of image classification, and by using these Convolutional Neural Networks (CNN) architectures, one can get a high classification accuracy on a wide variety of image datasets. However, these Deep Learning models have a very high computational complexity and so incur a high computational cost of running these algorithms as well as make it hard to interpret the results. In this paper, we present a shallow CNN architecture which gives the same classification accuracy as the VGG-16 and Resnet-50 models for thin blood smear RBC slide images for detection of malaria, while decreasing the computational run time by an order of magnitude. This can offer a significant advantage for commercial deployment of these algorithms, especially in poorer countries in Africa and some parts of the Indian subcontinent, where the menace of malaria is quite severe.
3D-OES: Viewpoint-Invariant Object-Factorized Environment Simulators
Nov 12, 2020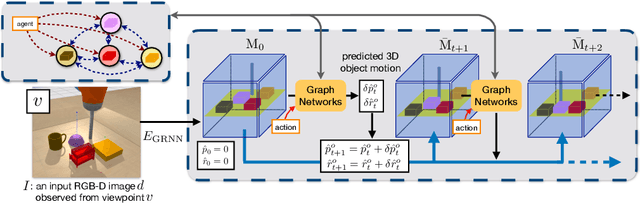


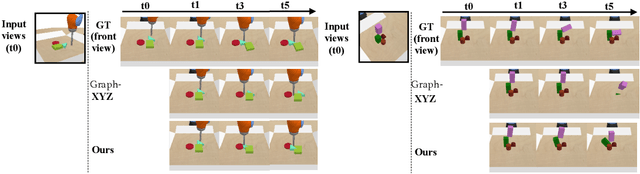
We propose an action-conditioned dynamics model that predicts scene changes caused by object and agent interactions in a viewpoint-invariant 3D neural scene representation space, inferred from RGB-D videos. In this 3D feature space, objects do not interfere with one another and their appearance persists over time and across viewpoints. This permits our model to predict future scenes long in the future by simply "moving" 3D object features based on cumulative object motion predictions. Object motion predictions are computed by a graph neural network that operates over the object features extracted from the 3D neural scene representation. Our model's simulations can be decoded by a neural renderer into2D image views from any desired viewpoint, which aids the interpretability of our latent 3D simulation space. We show our model generalizes well its predictions across varying number and appearances of interacting objects as well as across camera viewpoints, outperforming existing 2D and 3D dynamics models. We further demonstrate sim-to-real transfer of the learnt dynamics by applying our model trained solely in simulation to model-based control for pushing objects to desired locations under clutter on a real robotic setup
MultiCheXNet: A Multi-Task Learning Deep Network For Pneumonia-like Diseases Diagnosis From X-ray Scans
Aug 05, 2020



We present MultiCheXNet, an end-to-end Multi-task learning model, that is able to take advantage of different X-rays data sets of Pneumonia-like diseases in one neural architecture, performing three tasks at the same time; diagnosis, segmentation and localization. The common encoder in our architecture can capture useful common features present in the different tasks. The common encoder has another advantage of efficient computations, which speeds up the inference time compared to separate models. The specialized decoders heads can then capture the task-specific features. We employ teacher forcing to address the issue of negative samples that hurt the segmentation and localization performance. Finally,we employ transfer learning to fine tune the classifier on unseen pneumonia-like diseases. The MTL architecture can be trained on joint or dis-joint labeled data sets. The training of the architecture follows a carefully designed protocol, that pre trains different sub-models on specialized datasets, before being integrated in the joint MTL model. Our experimental setup involves variety of data sets, where the baseline performance of the 3 tasks is compared to the MTL architecture performance. Moreover, we evaluate the transfer learning mode to COVID-19 data set,both from individual classifier model, and from MTL architecture classification head.
Dependent Matérn Processes for Multivariate Time Series
Feb 11, 2015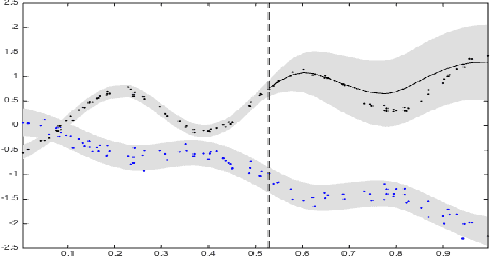
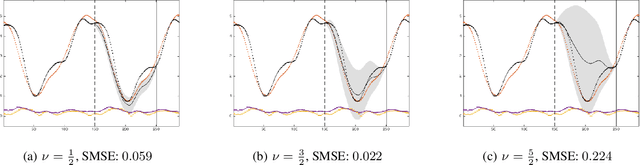
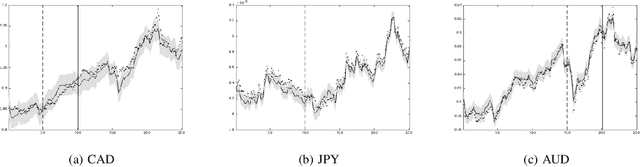
For the challenging task of modeling multivariate time series, we propose a new class of models that use dependent Mat\'ern processes to capture the underlying structure of data, explain their interdependencies, and predict their unknown values. Although similar models have been proposed in the econometric, statistics, and machine learning literature, our approach has several advantages that distinguish it from existing methods: 1) it is flexible to provide high prediction accuracy, yet its complexity is controlled to avoid overfitting; 2) its interpretability separates it from black-box methods; 3) finally, its computational efficiency makes it scalable for high-dimensional time series. In this paper, we use several simulated and real data sets to illustrate these advantages. We will also briefly discuss some extensions of our model.
Learning Attribute-Structure Co-Evolutions in Dynamic Graphs
Jul 25, 2020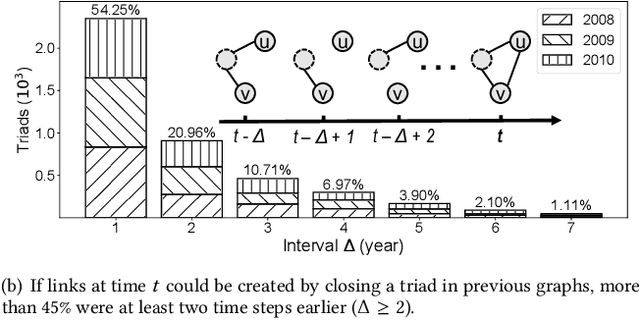
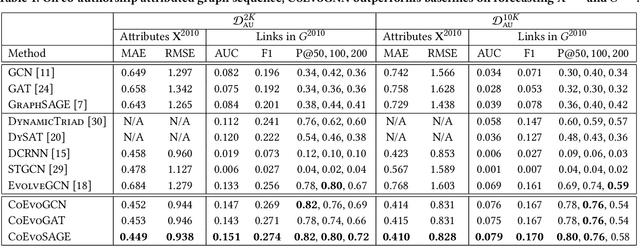
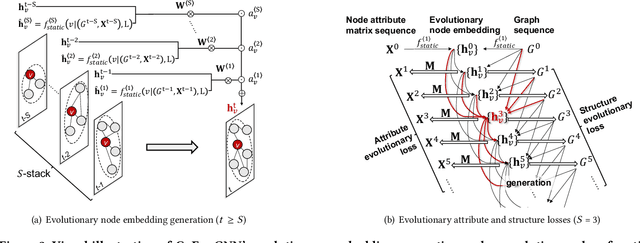
Most graph neural network models learn embeddings of nodes in static attributed graphs for predictive analysis. Recent attempts have been made to learn temporal proximity of the nodes. We find that real dynamic attributed graphs exhibit complex co-evolution of node attributes and graph structure. Learning node embeddings for forecasting change of node attributes and birth and death of links over time remains an open problem. In this work, we present a novel framework called CoEvoGNN for modeling dynamic attributed graph sequence. It preserves the impact of earlier graphs on the current graph by embedding generation through the sequence. It has a temporal self-attention mechanism to model long-range dependencies in the evolution. Moreover, CoEvoGNN optimizes model parameters jointly on two dynamic tasks, attribute inference and link prediction over time. So the model can capture the co-evolutionary patterns of attribute change and link formation. This framework can adapt to any graph neural algorithms so we implemented and investigated three methods based on it: CoEvoGCN, CoEvoGAT, and CoEvoSAGE. Experiments demonstrate the framework (and its methods) outperform strong baselines on predicting an entire unseen graph snapshot of personal attributes and interpersonal links in dynamic social graphs and financial graphs.
MAM: Masked Acoustic Modeling for End-to-End Speech-to-Text Translation
Oct 22, 2020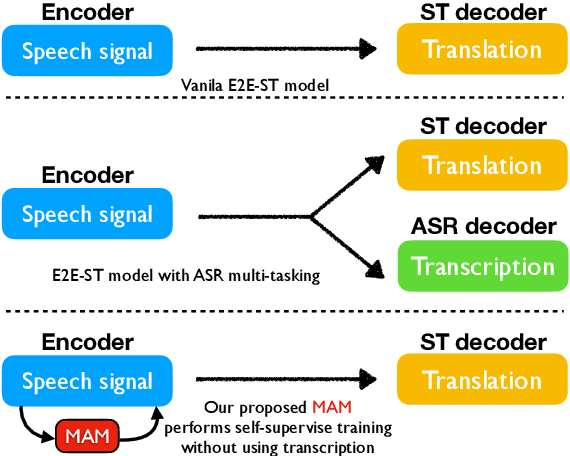
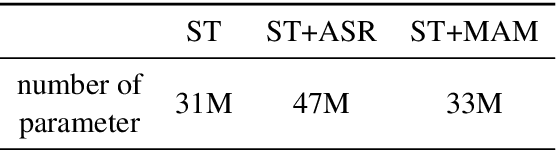

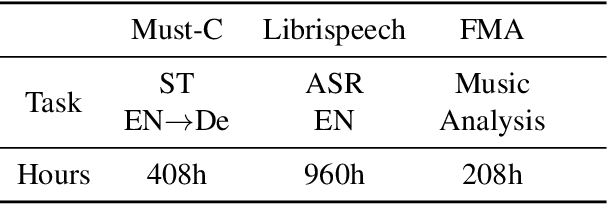
End-to-end Speech-to-text Translation (E2E- ST), which directly translates source language speech to target language text, is widely useful in practice, but traditional cascaded approaches (ASR+MT) often suffer from error propagation in the pipeline. On the other hand, existing end-to-end solutions heavily depend on the source language transcriptions for pre-training or multi-task training with Automatic Speech Recognition (ASR). We instead propose a simple technique to learn a robust speech encoder in a self-supervised fashion only on the speech side, which can utilize speech data without transcription. This technique, termed Masked Acoustic Modeling (MAM), can also perform pre-training, for the first time, on any acoustic signals (including non-speech ones) without annotation. Compared with current state-of-the-art models on ST, our technique achieves +1.4 BLEU improvement without using transcriptions, and +1.2 BLEU using transcriptions. The pre-training of MAM with arbitrary acoustic signals also boosts the downstream speech-related tasks.
Deep-learning based down-scaling of summer monsoon rainfall data over Indian region
Dec 08, 2020
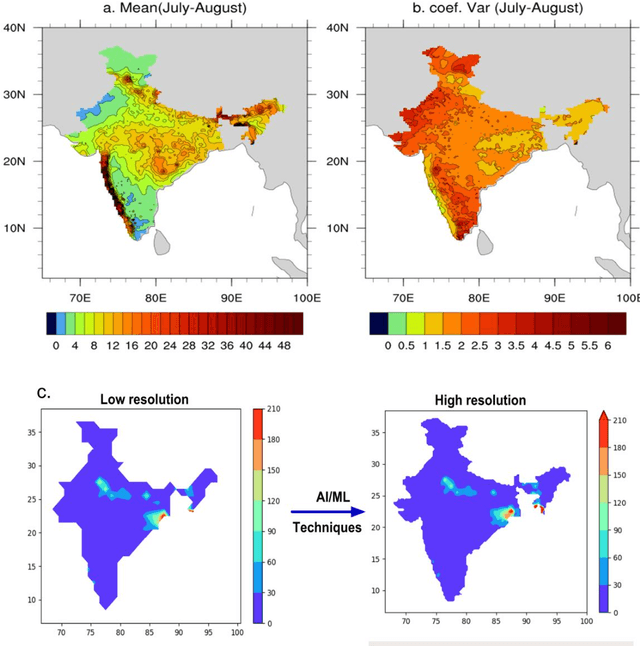
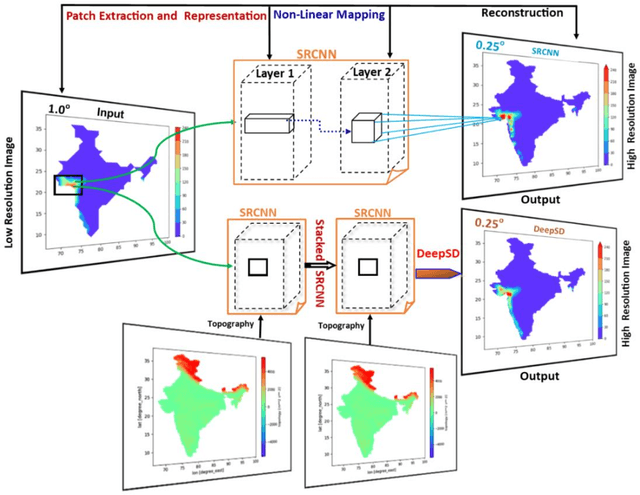
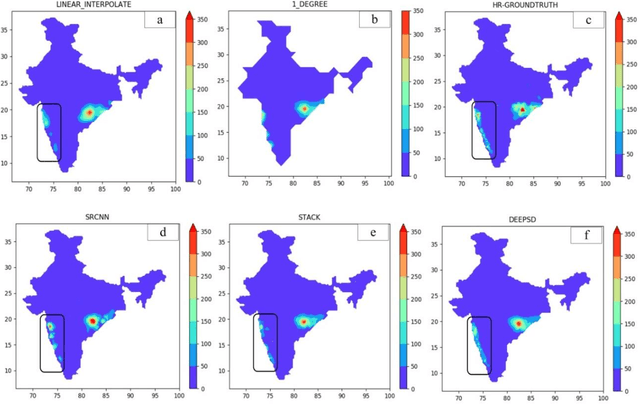
Downscaling is necessary to generate high-resolution observation data to validate the climate model forecast or monitor rainfall at the micro-regional level operationally. Dynamical and statistical downscaling models are often used to get information at high-resolution gridded data over larger domains. As rainfall variability is dependent on the complex Spatio-temporal process leading to non-linear or chaotic Spatio-temporal variations, no single downscaling method can be considered efficient enough. In data with complex topographies, quasi-periodicities, and non-linearities, deep Learning (DL) based methods provide an efficient solution in downscaling rainfall data for regional climate forecasting and real-time rainfall observation data at high spatial resolutions. In this work, we employed three deep learning-based algorithms derived from the super-resolution convolutional neural network (SRCNN) methods, to precipitation data, in particular, IMD and TRMM data to produce 4x-times high-resolution downscaled rainfall data during the summer monsoon season. Among the three algorithms, namely SRCNN, stacked SRCNN, and DeepSD, employed here, the best spatial distribution of rainfall amplitude and minimum root-mean-square error is produced by DeepSD based downscaling. Hence, the use of the DeepSD algorithm is advocated for future use. We found that spatial discontinuity in amplitude and intensity rainfall patterns is the main obstacle in the downscaling of precipitation. Furthermore, we applied these methods for model data postprocessing, in particular, ERA5 data. Downscaled ERA5 rainfall data show a much better distribution of spatial covariance and temporal variance when compared with observation.
Self-Concordant Analysis of Generalized Linear Bandits with Forgetting
Nov 02, 2020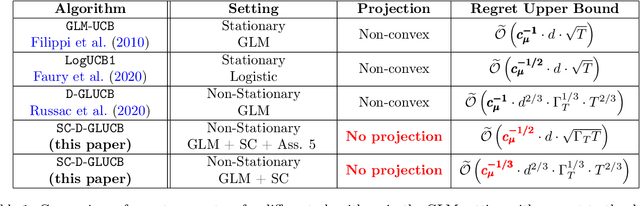
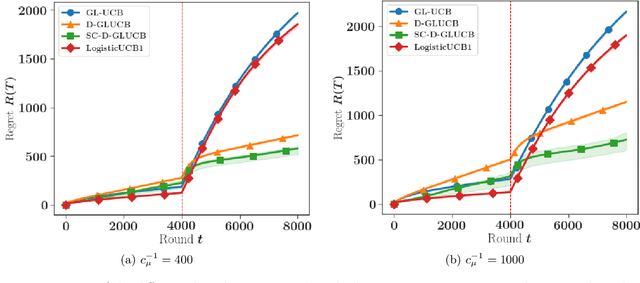
Contextual sequential decision problems with categorical or numerical observations are ubiquitous and Generalized Linear Bandits (GLB) offer a solid theoretical framework to address them. In contrast to the case of linear bandits, existing algorithms for GLB have two drawbacks undermining their applicability. First, they rely on excessively pessimistic concentration bounds due to the non-linear nature of the model. Second, they require either non-convex projection steps or burn-in phases to enforce boundedness of the estimators. Both of these issues are worsened when considering non-stationary models, in which the GLB parameter may vary with time. In this work, we focus on self-concordant GLB (which include logistic and Poisson regression) with forgetting achieved either by the use of a sliding window or exponential weights. We propose a novel confidence-based algorithm for the maximum-likehood estimator with forgetting and analyze its perfomance in abruptly changing environments. These results as well as the accompanying numerical simulations highlight the potential of the proposed approach to address non-stationarity in GLB.
High-dimensional macroeconomic forecasting using message passing algorithms
Apr 23, 2020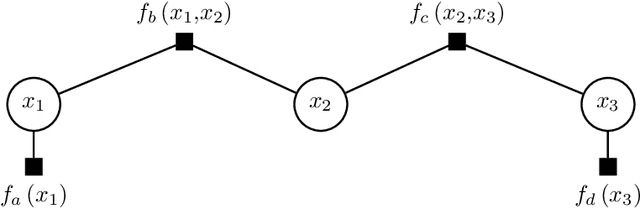
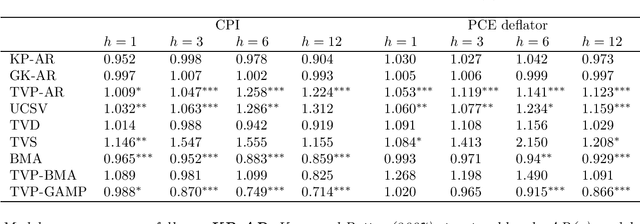
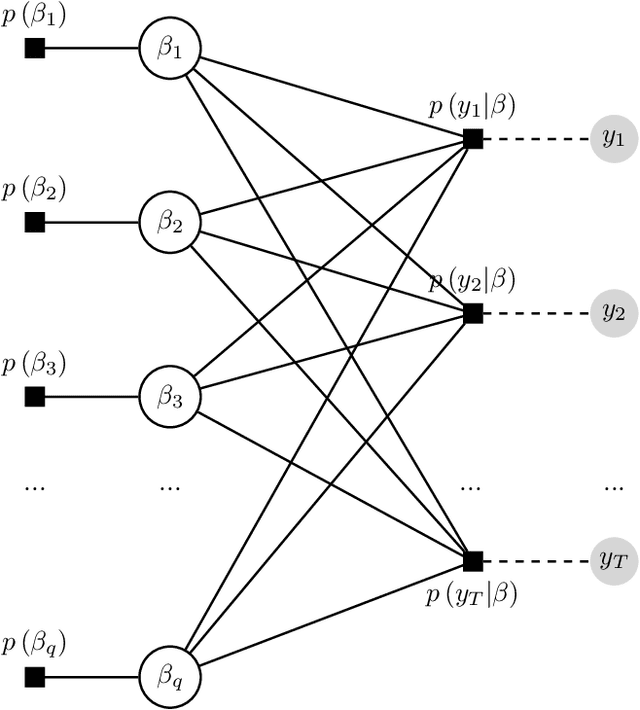
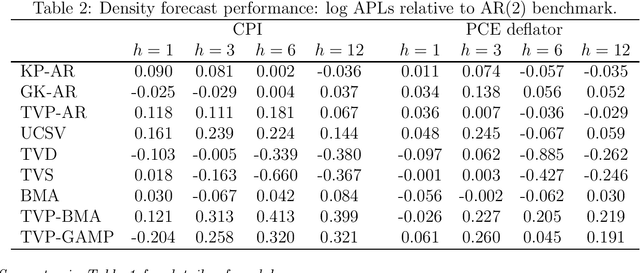
This paper proposes two distinct contributions to econometric analysis of large information sets and structural instabilities. First, it treats a regression model with time-varying coefficients, stochastic volatility and exogenous predictors, as an equivalent high-dimensional static regression problem with thousands of covariates. Inference in this specification proceeds using Bayesian hierarchical priors that shrink the high-dimensional vector of coefficients either towards zero or time-invariance. Second, it introduces the frameworks of factor graphs and message passing as a means of designing efficient Bayesian estimation algorithms. In particular, a Generalized Approximate Message Passing (GAMP) algorithm is derived that has low algorithmic complexity and is trivially parallelizable. The result is a comprehensive methodology that can be used to estimate time-varying parameter regressions with arbitrarily large number of exogenous predictors. In a forecasting exercise for U.S. price inflation this methodology is shown to work very well.