 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RobustPointSet: A Dataset for Benchmarking Robustness of Point Cloud Classifiers
Nov 23, 2020

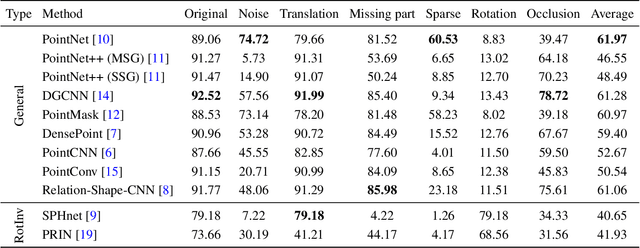

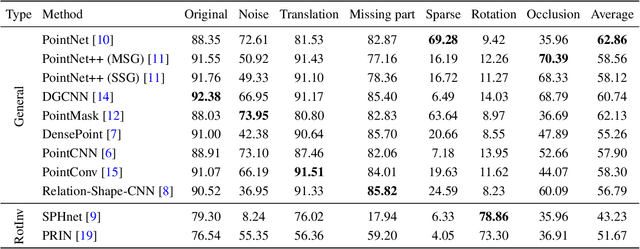
The 3D deep learning community has seen significant strides in pointcloud processing over the last few years. However, the datasets on which deep models have been trained have largely remained the same. Most datasets comprise clean, clutter-free pointclouds canonicalized for pose. Models trained on these datasets fail in uninterpretible and unintuitive ways when presented with data that contains transformations "unseen" at train time. While data augmentation enables models to be robust to "previously seen" input transformations, 1) we show that this does not work for unseen transformations during inference, and 2) data augmentation makes it difficult to analyze a model's inherent robustness to transformations. To this end, we create a publicly available dataset for robustness analysis of point cloud classification models (independent of data augmentation) to input transformations, called \textbf{RobustPointSet}. Our experiments indicate that despite all the progress in the point cloud classification, PointNet (the very first multi-layered perceptron-based approach) outperforms other methods (e.g., graph and neighbor based methods) when evaluated on transformed test sets. We also find that most of the current point cloud models are not robust to unseen transformations even if they are trained with extensive data augmentation. RobustPointSet can be accessed through https://github.com/AutodeskAILab/RobustPointSet.
Provable Worst Case Guarantees for the Detection of Out-of-Distribution Data
Jul 16, 2020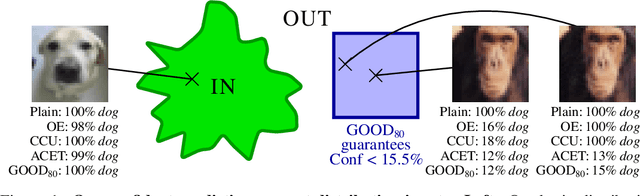
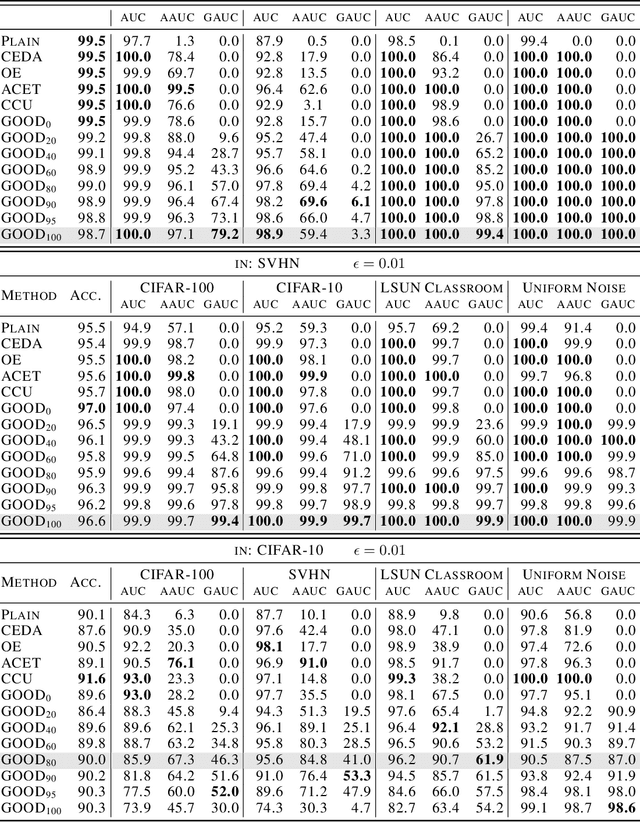

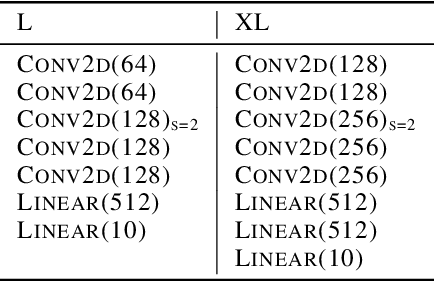
Deep neural networks are known to be overconfident when applied to out-of-distribution (OOD) inputs which clearly do not belong to any class. This is a problem in safety-critical applications since a reliable assessment of the uncertainty of a classifier is a key property, allowing to trigger human intervention or to transfer into a safe state. In this paper, we are aiming for certifiable worst case guarantees for OOD detection by enforcing not only low confidence at the OOD point but also in an $l_\infty$-ball around it. For this purpose, we use interval bound propagation (IBP) to upper bound the maximal confidence in the $l_\infty$-ball and minimize this upper bound during training time. We show that non-trivial bounds on the confidence for OOD data generalizing beyond the OOD dataset seen at training time are possible. Moreover, in contrast to certified adversarial robustness which typically comes with significant loss in prediction performance, certified guarantees for worst case OOD detection are possible without much loss in accuracy.
Next word prediction based on the N-gram model for Kurdish Sorani and Kurmanji
Jul 27, 2020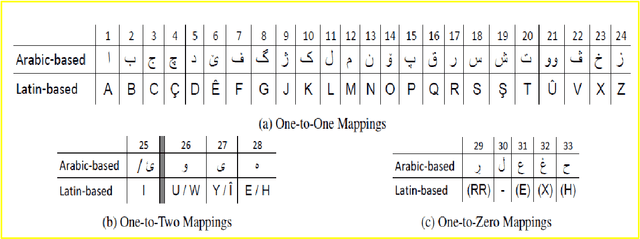

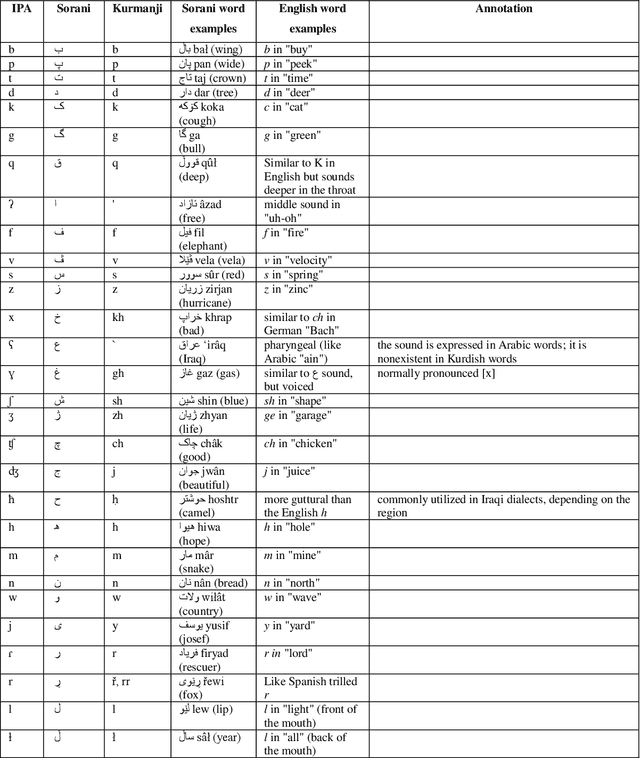
Next word prediction is an input technology that simplifies the process of typing by suggesting the next word to a user to select, as typing in a conversation consumes time. A few previous studies have focused on the Kurdish language, including the use of next word prediction. However, the lack of a Kurdish text corpus presents a challenge. Moreover, the lack of a sufficient number of N-grams for the Kurdish language, for instance, five grams, is the reason for the rare use of next Kurdish word prediction. Furthermore, the improper display of several Kurdish letters in the Rstudio software is another problem. This paper provides a Kurdish corpus, creates five, and presents a unique research work on next word prediction for Kurdish Sorani and Kurmanji. The N-gram model has been used for next word prediction to reduce the amount of time while typing in the Kurdish language. In addition, little work has been conducted on next Kurdish word prediction; thus, the N-gram model is utilized to suggest text accurately. To do so, R programming and RStudio are used to build the application. The model is 96.3% accurate.
* 37 pages
Online Service Migration in Edge Computing with Incomplete Information: A Deep Recurrent Actor-Critic Method
Dec 17, 2020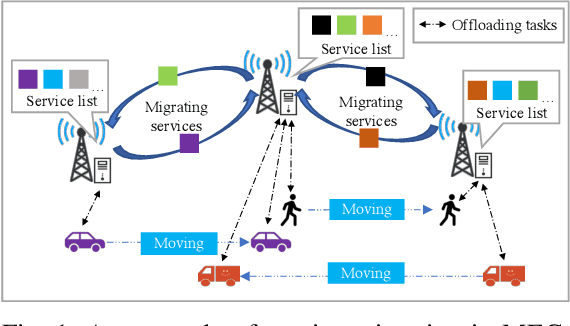
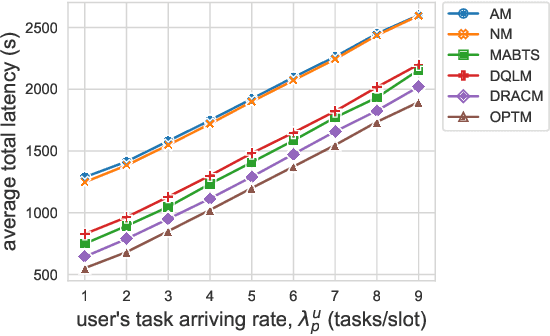
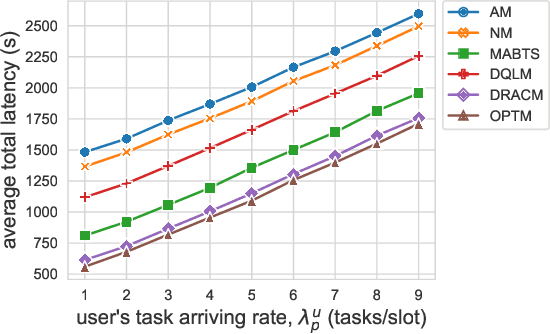
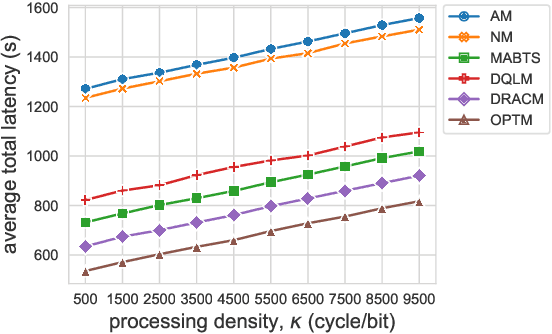
Multi-access Edge Computing (MEC) is a key technology in the fifth-generation (5G) network and beyond. MEC extends cloud computing to the network edge (e.g., base stations, MEC servers) to support emerging resource-intensive applications on mobile devices. As a crucial problem in MEC, service migration needs to decide where to migrate user services for maintaining high Quality-of-Service (QoS), when users roam between MEC servers with limited coverage and capacity. However, finding an optimal migration policy is intractable due to the highly dynamic MEC environment and user mobility. Many existing works make centralized migration decisions based on complete system-level information, which can be time-consuming and suffer from the scalability issue with the rapidly increasing number of mobile users. To address these challenges, we propose a new learning-driven method, namely Deep Recurrent Actor-Critic based service Migration (DRACM), which is user-centric and can make effective online migration decisions given incomplete system-level information. Specifically, the service migration problem is modeled as a Partially Observable Markov Decision Process (POMDP). To solve the POMDP, we design an encoder network that combines a Long Short-Term Memory (LSTM) and an embedding matrix for effective extraction of hidden information. We then propose a tailored off-policy actor-critic algorithm with a clipped surrogate objective for efficient training. Results from extensive experiments based on real-world mobility traces demonstrate that our method consistently outperforms both the heuristic and state-of-the-art learning-driven algorithms, and achieves near-optimal results on various MEC scenarios.
FracTrain: Fractionally Squeezing Bit Savings Both Temporally and Spatially for Efficient DNN Training
Dec 24, 2020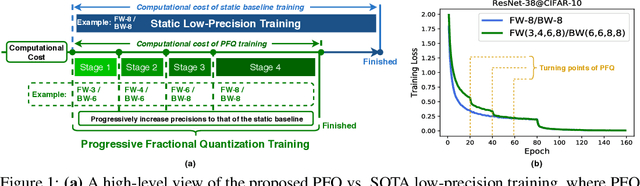
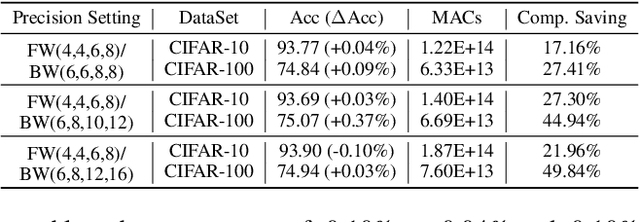
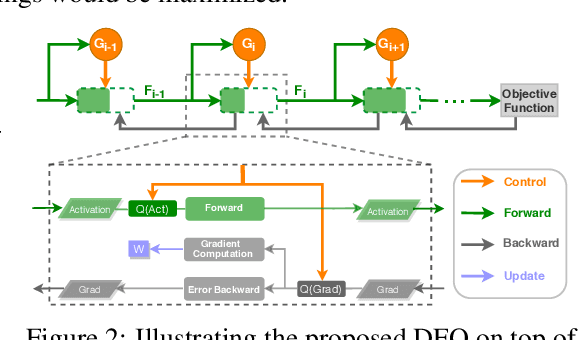

Recent breakthroughs in deep neural networks (DNNs) have fueled a tremendous demand for intelligent edge devices featuring on-site learning, while the practical realization of such systems remains a challenge due to the limited resources available at the edge and the required massive training costs for state-of-the-art (SOTA) DNNs. As reducing precision is one of the most effective knobs for boosting training time/energy efficiency, there has been a growing interest in low-precision DNN training. In this paper, we explore from an orthogonal direction: how to fractionally squeeze out more training cost savings from the most redundant bit level, progressively along the training trajectory and dynamically per input. Specifically, we propose FracTrain that integrates (i) progressive fractional quantization which gradually increases the precision of activations, weights, and gradients that will not reach the precision of SOTA static quantized DNN training until the final training stage, and (ii) dynamic fractional quantization which assigns precisions to both the activations and gradients of each layer in an input-adaptive manner, for only "fractionally" updating layer parameters. Extensive simulations and ablation studies (six models, four datasets, and three training settings including standard, adaptation, and fine-tuning) validate the effectiveness of FracTrain in reducing computational cost and hardware-quantified energy/latency of DNN training while achieving a comparable or better (-0.12%~+1.87%) accuracy. For example, when training ResNet-74 on CIFAR-10, FracTrain achieves 77.6% and 53.5% computational cost and training latency savings, respectively, compared with the best SOTA baseline, while achieving a comparable (-0.07%) accuracy. Our codes are available at: https://github.com/RICE-EIC/FracTrain.
Multi-task Deep Learning for Real-Time 3D Human Pose Estimation and Action Recognition
Dec 15, 2019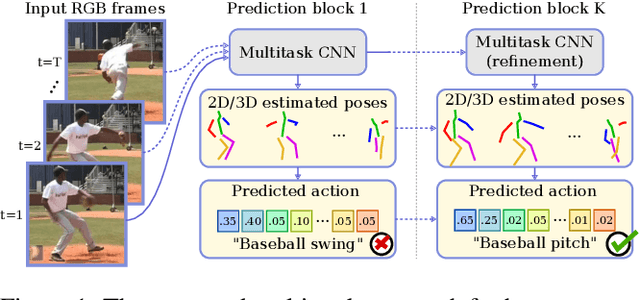
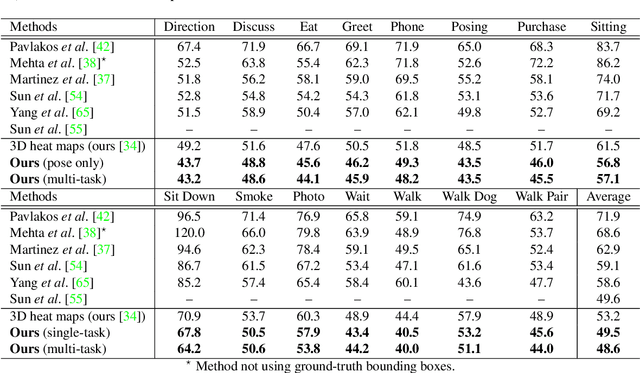
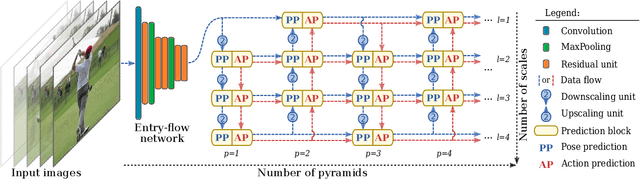
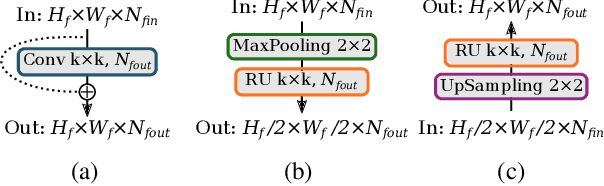
Human pose estimation and action recognition are related tasks since both problems are strongly dependent on the human body representation and analysis. Nonetheless, most recent methods in the literature handle the two problems separately. In this work, we propose a multi-task framework for jointly estimating 2D or 3D human poses from monocular color images and classifying human actions from video sequences. We show that a single architecture can be used to solve both problems in an efficient way and still achieves state-of-the-art or comparable results at each task while running at more than 100 frames per second. The proposed method benefits from high parameters sharing between the two tasks by unifying still images and video clips processing in a single pipeline, allowing the model to be trained with data from different categories simultaneously and in a seamlessly way. Additionally, we provide important insights for end-to-end training the proposed multi-task model by decoupling key prediction parts, which consistently leads to better accuracy on both tasks. The reported results on four datasets (MPII, Human3.6M, Penn Action and NTU RGB+D) demonstrate the effectiveness of our method on the targeted tasks. Our source code and trained weights are publicly available at https://github.com/dluvizon/deephar.
Automating Document Classification with Distant Supervision to Increase the Efficiency of Systematic Reviews
Dec 09, 2020
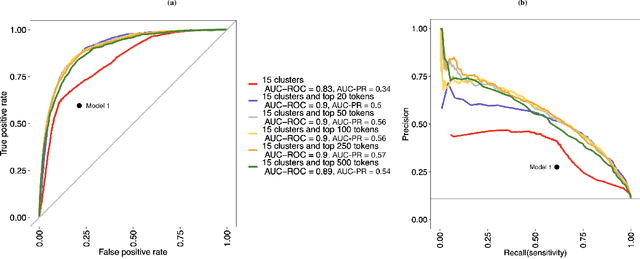
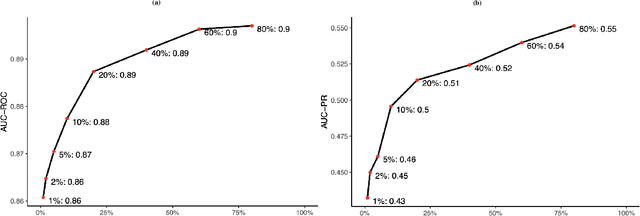
Objective: Systematic reviews of scholarly documents often provide complete and exhaustive summaries of literature relevant to a research question. However, well-done systematic reviews are expensive, time-demanding, and labor-intensive. Here, we propose an automatic document classification approach to significantly reduce the effort in reviewing documents. Methods: We first describe a manual document classification procedure that is used to curate a pertinent training dataset and then propose three classifiers: a keyword-guided method, a cluster analysis-based refined method, and a random forest approach that utilizes a large set of feature tokens. As an example, this approach is used to identify documents studying female sex workers that are assumed to contain content relevant to either HIV or violence. We compare the performance of the three classifiers by cross-validation and conduct a sensitivity analysis on the portion of data utilized in training the model. Results: The random forest approach provides the highest area under the curve (AUC) for both receiver operating characteristic (ROC) and precision/recall (PR). Analyses of precision and recall suggest that random forest could facilitate manually reviewing 20\% of the articles while containing 80\% of the relevant cases. Finally, we found a good classifier could be obtained by using a relatively small training sample size. Conclusions: In sum, the automated procedure of document classification presented here could improve both the precision and efficiency of systematic reviews, as well as facilitating live reviews, where reviews are updated regularly.
Unsupervised Multi-hop Question Answering by Question Generation
Oct 23, 2020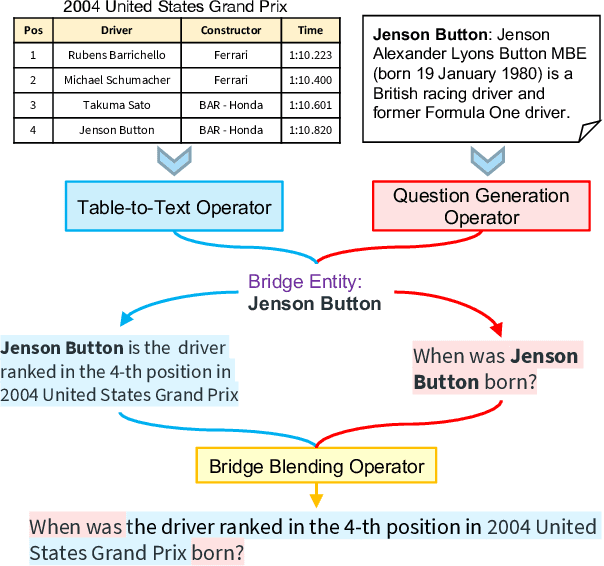
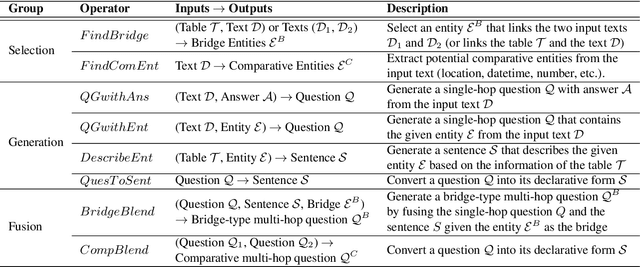

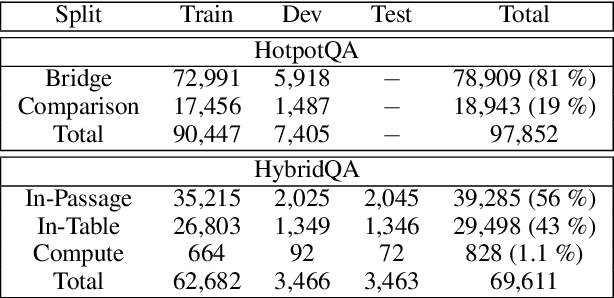
Obtaining training data for Multi-hop Question Answering (QA) is extremely time-consuming and resource-intensive. To address this, we propose the problem of \textit{unsupervised} multi-hop QA, assuming that no human-labeled multi-hop question-answer pairs are available. We propose MQA-QG, an unsupervised question answering framework that can generate human-like multi-hop training pairs from both homogeneous and heterogeneous data sources. Our model generates questions by first selecting or generating relevant information from each data source and then integrating the multiple information to form a multi-hop question. We find that we can train a competent multi-hop QA model with only generated data. The F1 gap between the unsupervised and fully-supervised models is less than 20 in both the HotpotQA and the HybridQA dataset. Further experiments reveal that an unsupervised pretraining with the QA data generated by our model would greatly reduce the demand for human-annotated training data for multi-hop QA.
Revisiting Maximum Entropy Inverse Reinforcement Learning: New Perspectives and Algorithms
Dec 01, 2020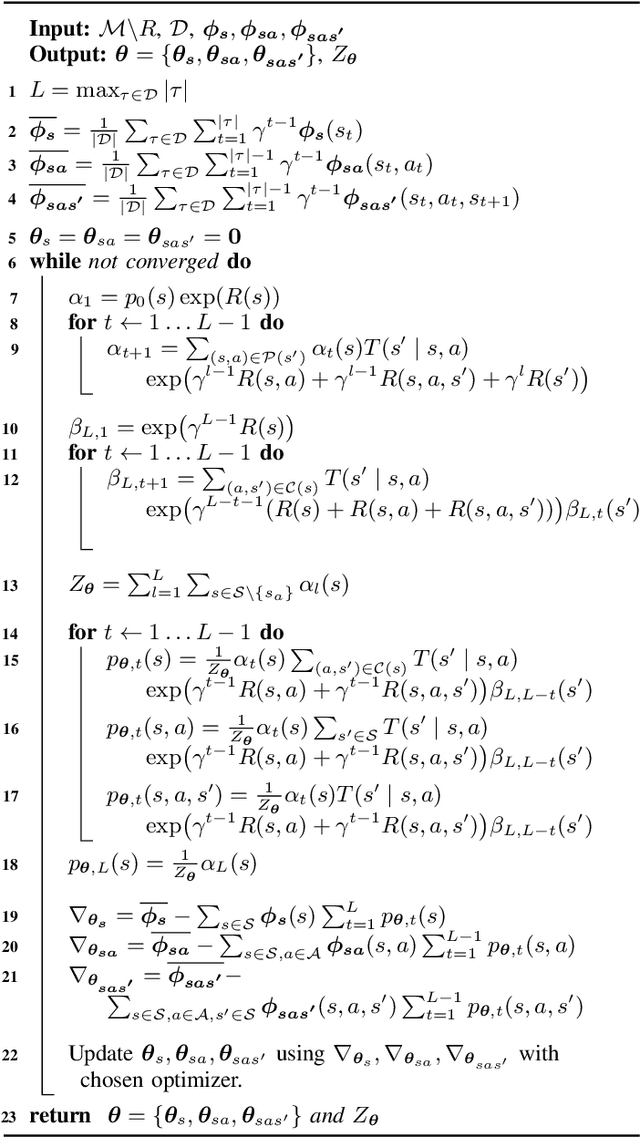
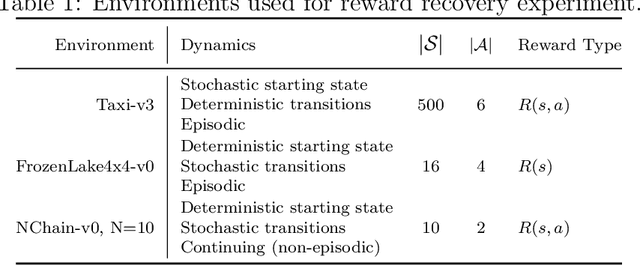
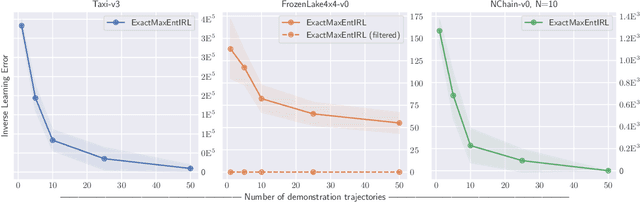
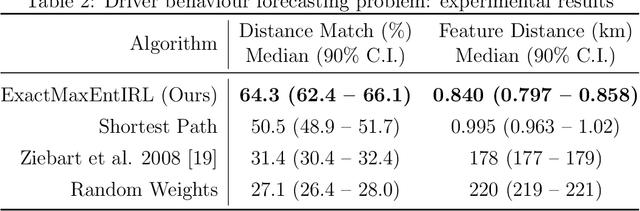
We provide new perspectives and inference algorithms for Maximum Entropy (MaxEnt) Inverse Reinforcement Learning (IRL), which provides a principled method to find a most non-committal reward function consistent with given expert demonstrations, among many consistent reward functions. We first present a generalized MaxEnt formulation based on minimizing a KL-divergence instead of maximizing an entropy. This improves the previous heuristic derivation of the MaxEnt IRL model (for stochastic MDPs), allows a unified view of MaxEnt IRL and Relative Entropy IRL, and leads to a model-free learning algorithm for the MaxEnt IRL model. Second, a careful review of existing inference algorithms and implementations showed that they approximately compute the marginals required for learning the model. We provide examples to illustrate this, and present an efficient and exact inference algorithm. Our algorithm can handle variable length demonstrations; in addition, while a basic version takes time quadratic in the maximum demonstration length L, an improved version of this algorithm reduces this to linear using a padding trick. Experiments show that our exact algorithm improves reward learning as compared to the approximate ones. Furthermore, our algorithm scales up to a large, real-world dataset involving driver behaviour forecasting. We provide an optimized implementation compatible with the OpenAI Gym interface. Our new insight and algorithms could possibly lead to further interest and exploration of the original MaxEnt IRL model.
Controlling a remotely located Robot using Hand Gestures in real time: A DSP implementation
Jul 23, 2017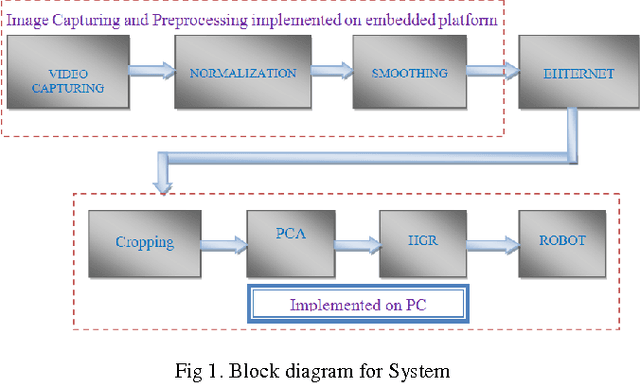

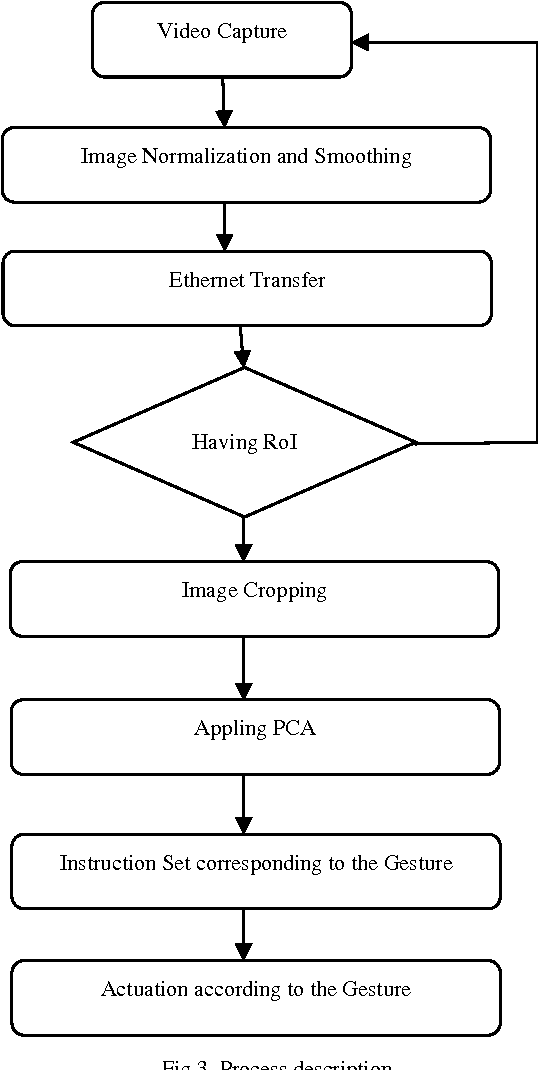
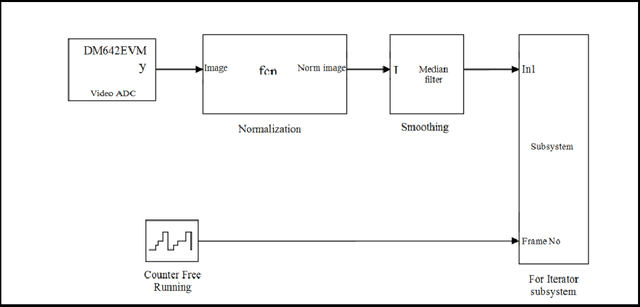
Telepresence is a necessity for present time as we can't reach everywhere and also it is useful in saving human life at dangerous places. A robot, which could be controlled from a distant location, can solve these problems. This could be via communication waves or networking methods. Also controlling should be in real time and smooth so that it can actuate on every minor signal in an effective way. This paper discusses a method to control a robot over the network from a distant location. The robot was controlled by hand gestures which were captured by the live camera. A DSP board TMS320DM642EVM was used to implement image pre-processing and fastening the whole system. PCA was used for gesture classification and robot actuation was done according to predefined procedures. Classification information was sent over the network in the experiment. This method is robust and could be used to control any kind of robot over distance.