 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Document Classification with Distant Supervision to Increase the Efficiency of Systematic Reviews
Paper and Code
Dec 09, 2020
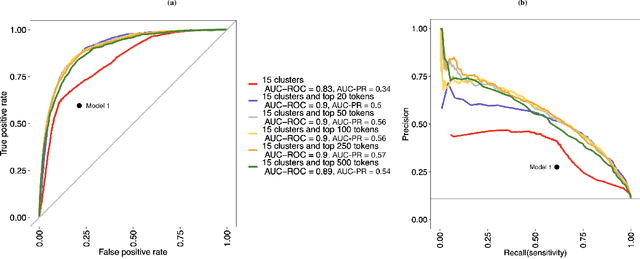
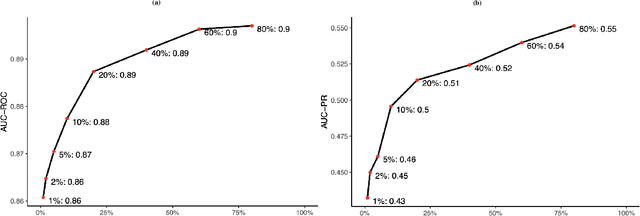
Objective: Systematic reviews of scholarly documents often provide complete and exhaustive summaries of literature relevant to a research question. However, well-done systematic reviews are expensive, time-demanding, and labor-intensive. Here, we propose an automatic document classification approach to significantly reduce the effort in reviewing documents. Methods: We first describe a manual document classification procedure that is used to curate a pertinent training dataset and then propose three classifiers: a keyword-guided method, a cluster analysis-based refined method, and a random forest approach that utilizes a large set of feature tokens. As an example, this approach is used to identify documents studying female sex workers that are assumed to contain content relevant to either HIV or violence. We compare the performance of the three classifiers by cross-validation and conduct a sensitivity analysis on the portion of data utilized in training the model. Results: The random forest approach provides the highest area under the curve (AUC) for both receiver operating characteristic (ROC) and precision/recall (PR). Analyses of precision and recall suggest that random forest could facilitate manually reviewing 20\% of the articles while containing 80\% of the relevant cases. Finally, we found a good classifier could be obtained by using a relatively small training sample size. Conclusions: In sum, the automated procedure of document classification presented here could improve both the precision and efficiency of systematic reviews, as well as facilitating live reviews, where reviews are updated regularly.