 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Mixed Membership Models for Time Series
Sep 13, 2013
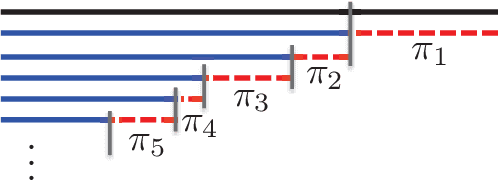
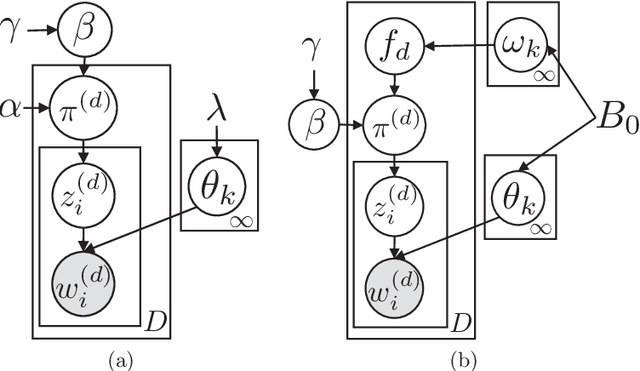
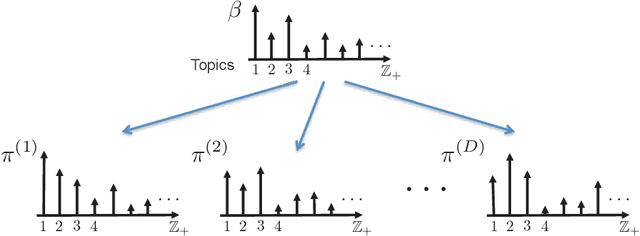
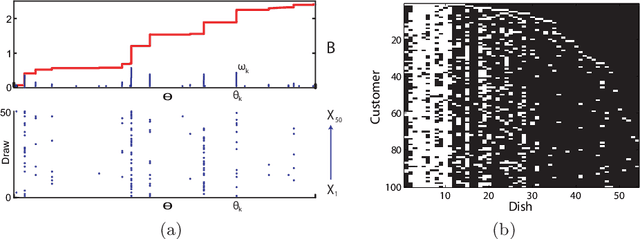
In this article we discuss some of the consequences of the mixed membership perspective on time series analysis. In its most abstract form, a mixed membership model aims to associate an individual entity with some set of attributes based on a collection of observed data. Although much of the literature on mixed membership models considers the setting in which exchangeable collections of data are associated with each member of a set of entities, it is equally natural to consider problems in which an entire time series is viewed as an entity and the goal is to characterize the time series in terms of a set of underlying dynamic attributes or "dynamic regimes". Indeed, this perspective is already present in the classical hidden Markov model, where the dynamic regimes are referred to as "states", and the collection of states realized in a sample path of the underlying process can be viewed as a mixed membership characterization of the observed time series. Our goal here is to review some of the richer modeling possibilities for time series that are provided by recent developments in the mixed membership framework.
The FaceChannelS: Strike of the Sequences for the AffWild 2 Challenge
Oct 04, 2020

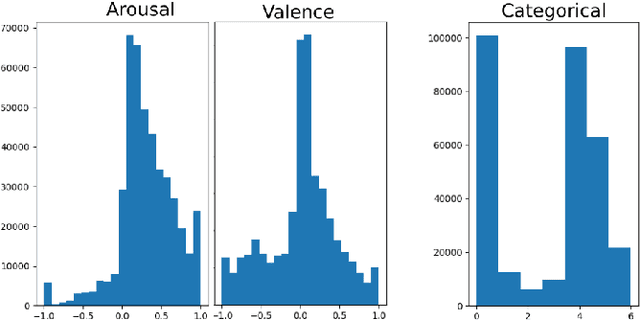
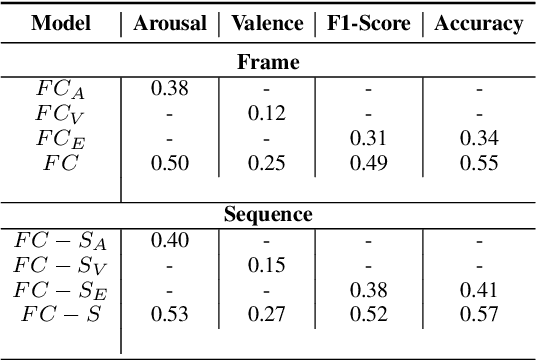
Predicting affective information from human faces became a popular task for most of the machine learning community in the past years. The development of immense and dense deep neural networks was backed by the availability of numerous labeled datasets. These models, most of the time, present state-of-the-art results in such benchmarks, but are very difficult to adapt to other scenarios. In this paper, we present one more chapter of benchmarking different versions of the FaceChannel neural network: we demonstrate how our little model can predict affective information from the facial expression on the novel AffWild2 dataset.
Online Multitask Learning with Long-Term Memory
Aug 17, 2020We introduce a novel online multitask setting. In this setting each task is partitioned into a sequence of segments that is unknown to the learner. Associated with each segment is a hypothesis from some hypothesis class. We give algorithms that are designed to exploit the scenario where there are many such segments but significantly fewer associated hypotheses. We prove regret bounds that hold for any segmentation of the tasks and any association of hypotheses to the segments. In the single-task setting this is equivalent to switching with long-term memory in the sense of [Bousquet and Warmuth; 2003]. We provide an algorithm that predicts on each trial in time linear in the number of hypotheses when the hypothesis class is finite. We also consider infinite hypothesis classes from reproducing kernel Hilbert spaces for which we give an algorithm whose per trial time complexity is cubic in the number of cumulative trials. In the single-task special case this is the first example of an efficient regret-bounded switching algorithm with long-term memory for a non-parametric hypothesis class.
Quantum Mathematics in Artificial Intelligence
Jan 12, 2021
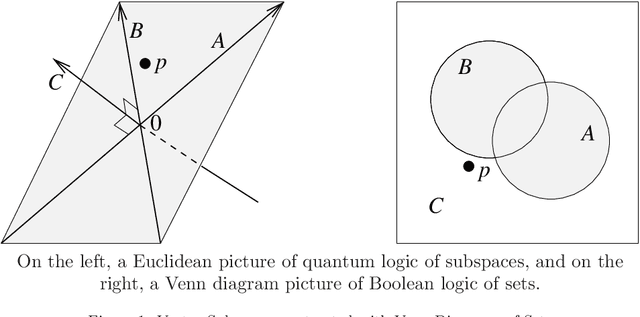
In the decade since 2010, successes in artificial intelligence have been at the forefront of computer science and technology, and vector space models have solidified a position at the forefront of artificial intelligence. At the same time, quantum computers have become much more powerful, and announcements of major advances are frequently in the news. The mathematical techniques underlying both these areas have more in common than is sometimes realized. Vector spaces took a position at the axiomatic heart of quantum mechanics in the 1930s, and this adoption was a key motivation for the derivation of logic and probability from the linear geometry of vector spaces. Quantum interactions between particles are modelled using the tensor product, which is also used to express objects and operations in artificial neural networks. This paper describes some of these common mathematical areas, including examples of how they are used in artificial intelligence (AI), particularly in automated reasoning and natural language processing (NLP). Techniques discussed include vector spaces, scalar products, subspaces and implication, orthogonal projection and negation, dual vectors, density matrices, positive operators, and tensor products. Application areas include information retrieval, categorization and implication, modelling word-senses and disambiguation, inference in knowledge bases, and semantic composition. Some of these approaches can potentially be implemented on quantum hardware. Many of the practical steps in this implementation are in early stages, and some are already realized. Explaining some of the common mathematical tools can help researchers in both AI and quantum computing further exploit these overlaps, recognizing and exploring new directions along the way.
Learning Compact Physics-Aware Delayed Photocurrent Models Using Dynamic Mode Decomposition
Aug 27, 2020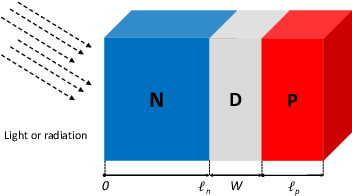

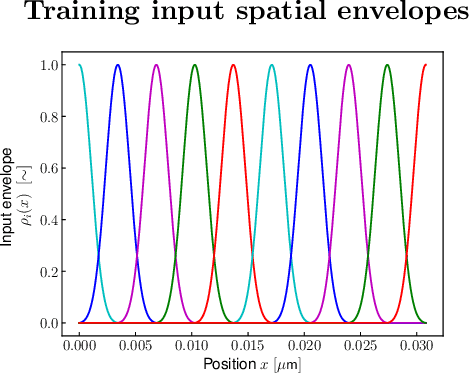
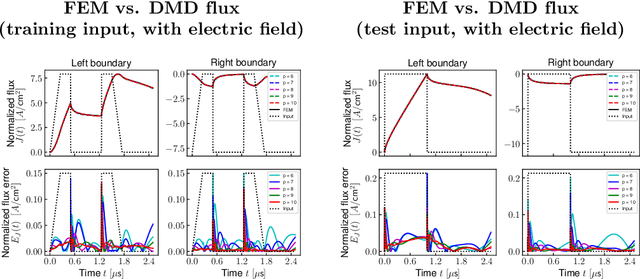
Radiation-induced photocurrent in semiconductor devices can be simulated using complex physics-based models, which are accurate, but computationally expensive. This presents a challenge for implementing device characteristics in high-level circuit simulations where it is computationally infeasible to evaluate detailed models for multiple individual circuit elements. In this work we demonstrate a procedure for learning compact delayed photocurrent models that are efficient enough to implement in large-scale circuit simulations, but remain faithful to the underlying physics. Our approach utilizes Dynamic Mode Decomposition (DMD), a system identification technique for learning reduced order discrete-time dynamical systems from time series data based on singular value decomposition. To obtain physics-aware device models, we simulate the excess carrier density induced by radiation pulses by solving numerically the Ambipolar Diffusion Equation, then use the simulated internal state as training data for the DMD algorithm. Our results show that the significantly reduced order delayed photocurrent models obtained via this method accurately approximate the dynamics of the internal excess carrier density -- which can be used to calculate the induced current at the device boundaries -- while remaining compact enough to incorporate into larger circuit simulations.
Frame-To-Frame Consistent Semantic Segmentation
Aug 27, 2020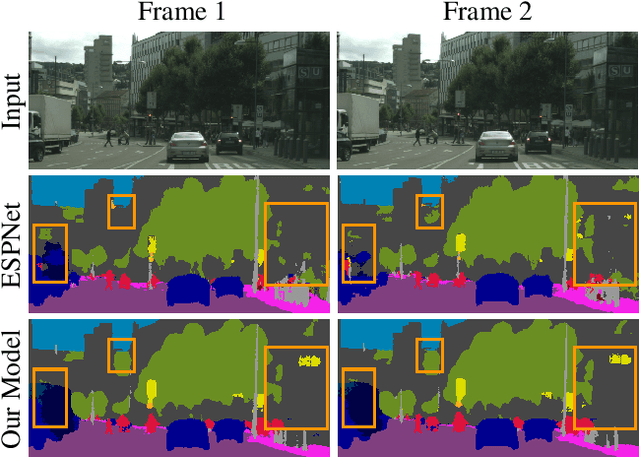
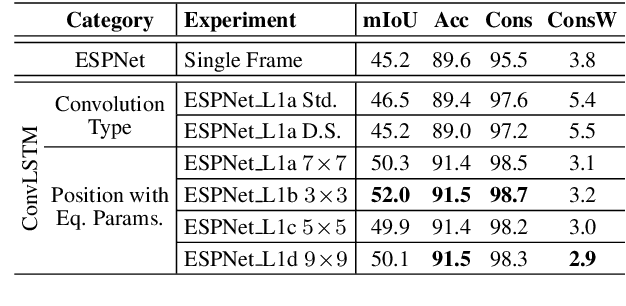
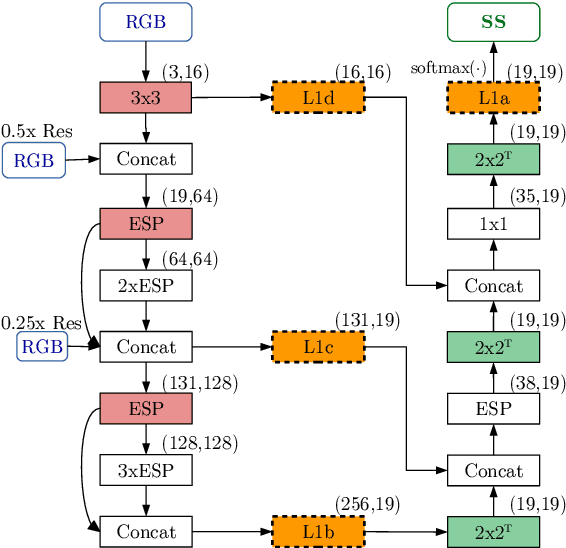
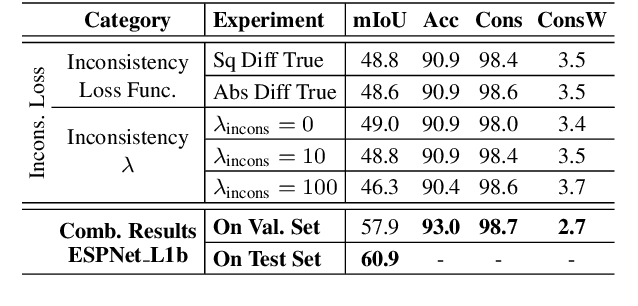
In this work, we aim for temporally consistent semantic segmentation throughout frames in a video. Many semantic segmentation algorithms process images individually which leads to an inconsistent scene interpretation due to illumination changes, occlusions and other variations over time. To achieve a temporally consistent prediction, we train a convolutional neural network (CNN) which propagates features through consecutive frames in a video using a convolutional long short term memory (ConvLSTM) cell. Besides the temporal feature propagation, we penalize inconsistencies in our loss function. We show in our experiments that the performance improves when utilizing video information compared to single frame prediction. The mean intersection over union (mIoU) metric on the Cityscapes validation set increases from 45.2 % for the single frames to 57.9 % for video data after implementing the ConvLSTM to propagate features trough time on the ESPNet. Most importantly, inconsistency decreases from 4.5 % to 1.3 % which is a reduction by 71.1 %. Our results indicate that the added temporal information produces a frame-to-frame consistent and more accurate image understanding compared to single frame processing. Code and videos are available at https://github.com/mrebol/f2f-consistent-semantic-segmentation
Few-shot Object Grounding and Mapping for Natural Language Robot Instruction Following
Nov 14, 2020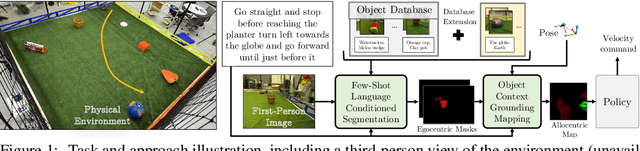
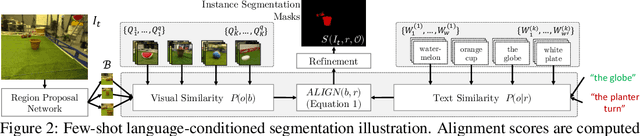
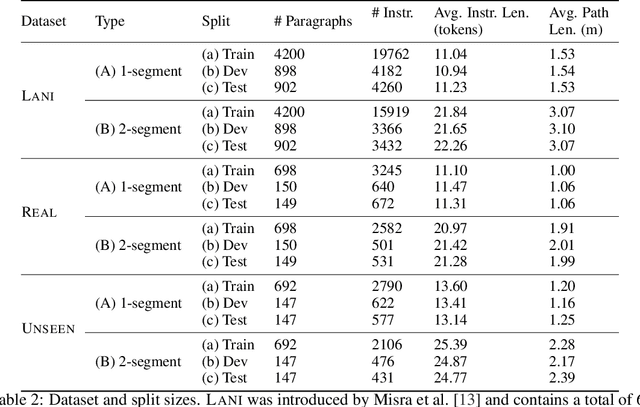
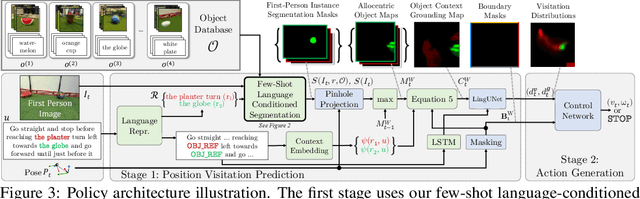
We study the problem of learning a robot policy to follow natural language instructions that can be easily extended to reason about new objects. We introduce a few-shot language-conditioned object grounding method trained from augmented reality data that uses exemplars to identify objects and align them to their mentions in instructions. We present a learned map representation that encodes object locations and their instructed use, and construct it from our few-shot grounding output. We integrate this mapping approach into an instruction-following policy, thereby allowing it to reason about previously unseen objects at test-time by simply adding exemplars. We evaluate on the task of learning to map raw observations and instructions to continuous control of a physical quadcopter. Our approach significantly outperforms the prior state of the art in the presence of new objects, even when the prior approach observes all objects during training.
Variance-adaptive confidence sequences by betting
Oct 19, 2020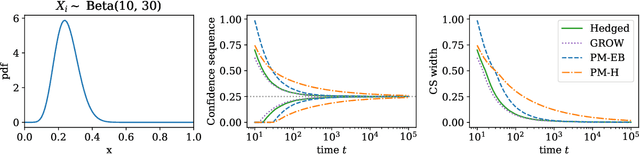
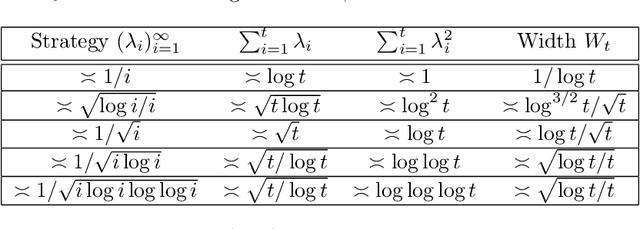
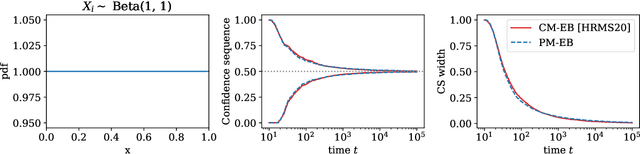

This paper derives confidence intervals (CI) and time-uniform confidence sequences (CS) for an unknown mean based on bounded observations. Our methods are based on a new general approach for deriving concentration bounds, that can be seen as a generalization (and improvement) of the classical Chernoff method. At its heart, it is based on deriving a new class of composite nonnegative martingales with initial value one, with strong connections to betting and the method of mixtures. We show how to extend these ideas to sampling without replacement. In all cases considered, the bounds are adaptive to the unknown variance, and empirically outperform competing approaches based on Hoeffding's or empirical Bernstein's inequalities and their recent supermartingale generalizations.
Data Cleansing with Contrastive Learning for Vocal Note Event Annotations
Aug 05, 2020
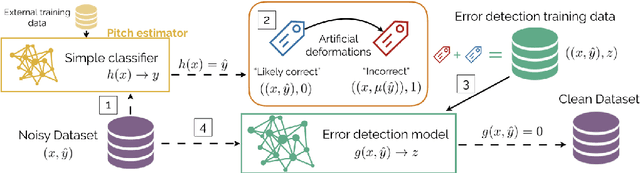

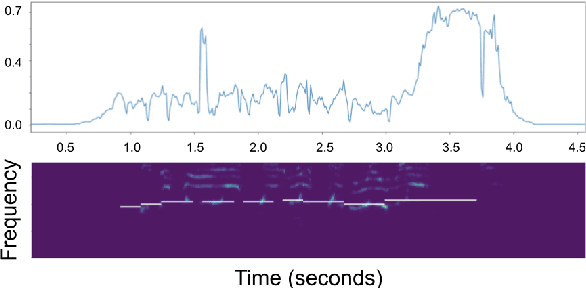
Data cleansing is a well studied strategy for cleaning erroneous labels in datasets, which has not yet been widely adopted in Music Information Retrieval. Previously proposed data cleansing models do not consider structured (e.g. time varying) labels, such as those common to music data. We propose a novel data cleansing model for time-varying, structured labels which exploits the local structure of the labels, and demonstrate its usefulness for vocal note event annotations in music. %Our model is trained in a contrastive learning manner by automatically creating local deformations of likely correct labels. Our model is trained in a contrastive learning manner by automatically contrasting likely correct labels pairs against local deformations of them. We demonstrate that the accuracy of a transcription model improves greatly when trained using our proposed strategy compared with the accuracy when trained using the original dataset. Additionally we use our model to estimate the annotation error rates in the DALI dataset, and highlight other potential uses for this type of model.
AdnFM: An Attentive DenseNet based Factorization Machine for CTR Prediction
Dec 20, 2020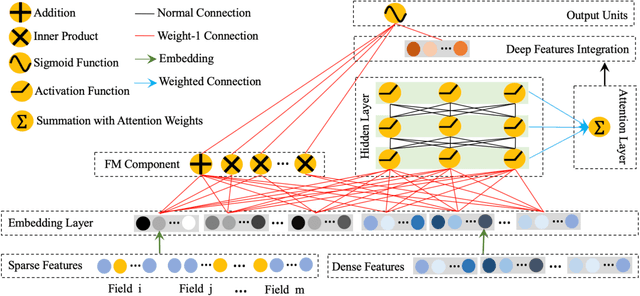
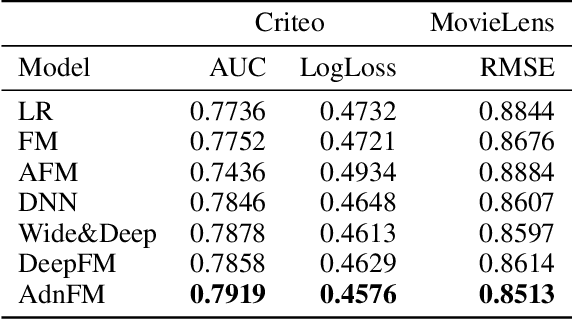
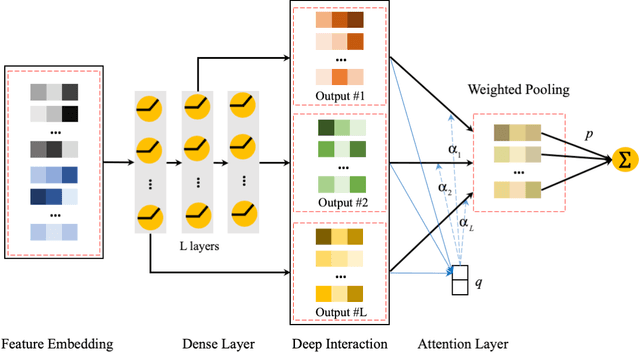
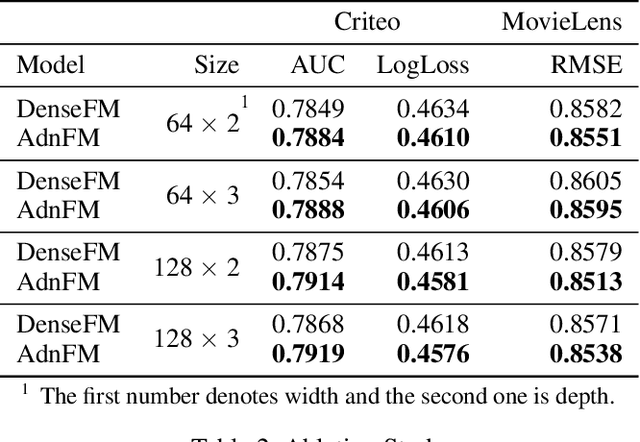
In this paper, we consider the Click-Through-Rate (CTR) prediction problem. Factorization Machines and their variants consider pair-wise feature interactions, but normally we won't do high-order feature interactions using FM due to high time complexity. Given the success of deep neural networks (DNNs) in many fields, researchers have proposed several DNN-based models to learn high-order feature interactions. Multi-layer perceptrons (MLP) have been widely employed to learn reliable mappings from feature embeddings to final logits. In this paper, we aim to explore more about these high-order features interactions. However, high-order feature interaction deserves more attention and further development. Inspired by the great achievements of Densely Connected Convolutional Networks (DenseNet) in computer vision, we propose a novel model called Attentive DenseNet based Factorization Machines (AdnFM). AdnFM can extract more comprehensive deep features by using all the hidden layers from a feed-forward neural network as implicit high-order features, then selects dominant features via an attention mechanism. Also, high-order interactions in the implicit way using DNNs are more cost-efficient than in the explicit way, for example in FM. Extensive experiments on two real-world datasets show that the proposed model can effectively improve the performance of CTR prediction.