 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Effective Negation Modeling in Joint Audio-Text Models for Music
Jan 20, 2026Joint audio-text models are widely used for music retrieval, yet they struggle with semantic phenomena such as negation. Negation is fundamental for distinguishing the absence (or presence) of musical elements (e.g., "with vocals" vs. "without vocals"), but current systems fail to represent this reliably. In this work, we investigate and mitigate this limitation by training CLAP models from scratch on the Million Song Dataset with LP-MusicCaps-MSD captions. We introduce negation through text augmentation and a dissimilarity-based contrastive loss, designed to explicitly separate original and negated captions in the joint embedding space. To evaluate progress, we propose two protocols that frame negation modeling as retrieval and binary classification tasks. Experiments demonstrate that both methods, individually and combined, improve negation handling while largely preserving retrieval performance.
Evaluation of pretrained language models on music understanding
Sep 17, 2024Music-text multimodal systems have enabled new approaches to Music Information Research (MIR) applications such as audio-to-text and text-to-audio retrieval, text-based song generation, and music captioning. Despite the reported success, little effort has been put into evaluating the musical knowledge of Large Language Models (LLM). In this paper, we demonstrate that LLMs suffer from 1) prompt sensitivity, 2) inability to model negation (e.g. 'rock song without guitar'), and 3) sensitivity towards the presence of specific words. We quantified these properties as a triplet-based accuracy, evaluating the ability to model the relative similarity of labels in a hierarchical ontology. We leveraged the Audioset ontology to generate triplets consisting of an anchor, a positive (relevant) label, and a negative (less relevant) label for the genre and instruments sub-tree. We evaluated the triplet-based musical knowledge for six general-purpose Transformer-based models. The triplets obtained through this methodology required filtering, as some were difficult to judge and therefore relatively uninformative for evaluation purposes. Despite the relatively high accuracy reported, inconsistencies are evident in all six models, suggesting that off-the-shelf LLMs need adaptation to music before use.
I can listen but cannot read: An evaluation of two-tower multimodal systems for instrument recognition
Jul 25, 2024



Music two-tower multimodal systems integrate audio and text modalities into a joint audio-text space, enabling direct comparison between songs and their corresponding labels. These systems enable new approaches for classification and retrieval, leveraging both modalities. Despite the promising results they have shown for zero-shot classification and retrieval tasks, closer inspection of the embeddings is needed. This paper evaluates the inherent zero-shot properties of joint audio-text spaces for the case-study of instrument recognition. We present an evaluation and analysis of two-tower systems for zero-shot instrument recognition and a detailed analysis of the properties of the pre-joint and joint embeddings spaces. Our findings suggest that audio encoders alone demonstrate good quality, while challenges remain within the text encoder or joint space projection. Specifically, two-tower systems exhibit sensitivity towards specific words, favoring generic prompts over musically informed ones. Despite the large size of textual encoders, they do not yet leverage additional textual context or infer instruments accurately from their descriptions. Lastly, a novel approach for quantifying the semantic meaningfulness of the textual space leveraging an instrument ontology is proposed. This method reveals deficiencies in the systems' understanding of instruments and provides evidence of the need for fine-tuning text encoders on musical data.
Data Cleansing with Contrastive Learning for Vocal Note Event Annotations
Aug 05, 2020
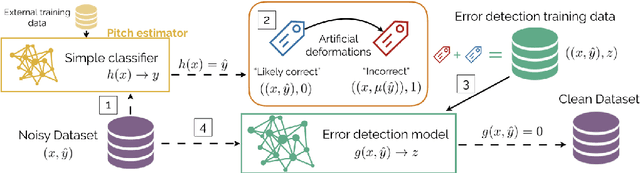

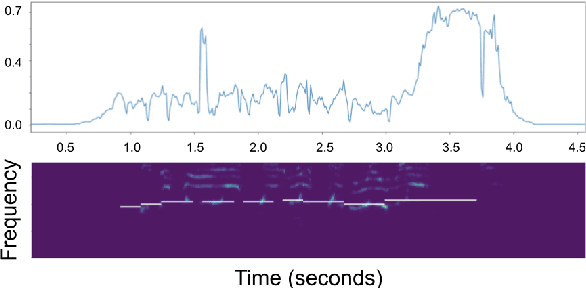
Data cleansing is a well studied strategy for cleaning erroneous labels in datasets, which has not yet been widely adopted in Music Information Retrieval. Previously proposed data cleansing models do not consider structured (e.g. time varying) labels, such as those common to music data. We propose a novel data cleansing model for time-varying, structured labels which exploits the local structure of the labels, and demonstrate its usefulness for vocal note event annotations in music. %Our model is trained in a contrastive learning manner by automatically creating local deformations of likely correct labels. Our model is trained in a contrastive learning manner by automatically contrasting likely correct labels pairs against local deformations of them. We demonstrate that the accuracy of a transcription model improves greatly when trained using our proposed strategy compared with the accuracy when trained using the original dataset. Additionally we use our model to estimate the annotation error rates in the DALI dataset, and highlight other potential uses for this type of model.
Neural Music Synthesis for Flexible Timbre Control
Nov 01, 2018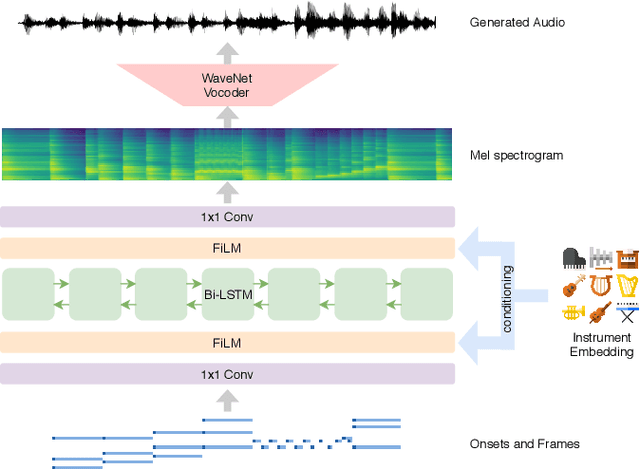
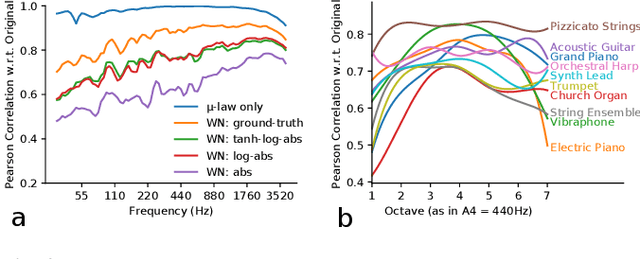
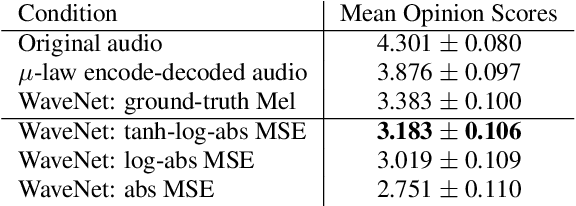
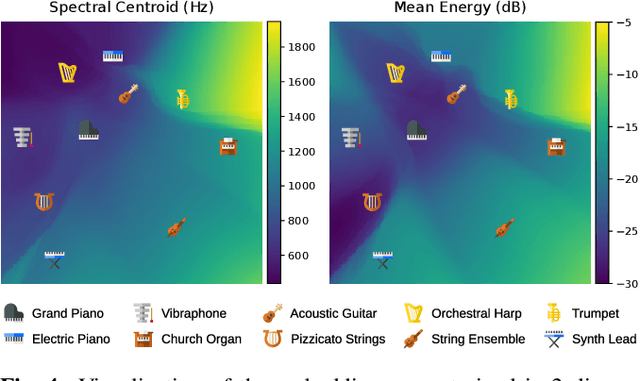
The recent success of raw audio waveform synthesis models like WaveNet motivates a new approach for music synthesis, in which the entire process --- creating audio samples from a score and instrument information --- is modeled using generative neural networks. This paper describes a neural music synthesis model with flexible timbre controls, which consists of a recurrent neural network conditioned on a learned instrument embedding followed by a WaveNet vocoder. The learned embedding space successfully captures the diverse variations in timbres within a large dataset and enables timbre control and morphing by interpolating between instruments in the embedding space. The synthesis quality is evaluated both numerically and perceptually, and an interactive web demo is presented.