 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRANet: Point Cloud Registration with an Artificial Agent
Sep 23, 2021
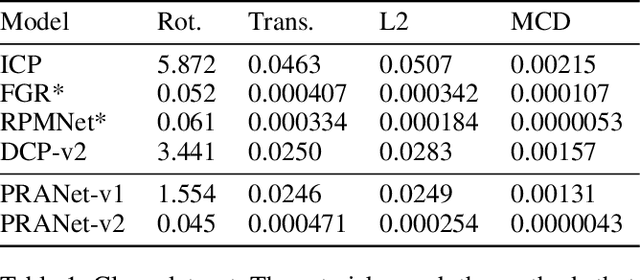
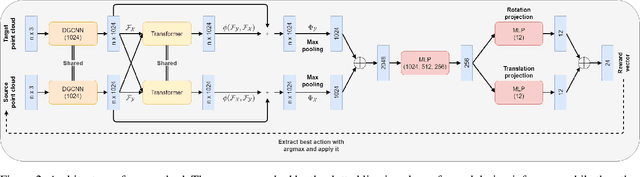
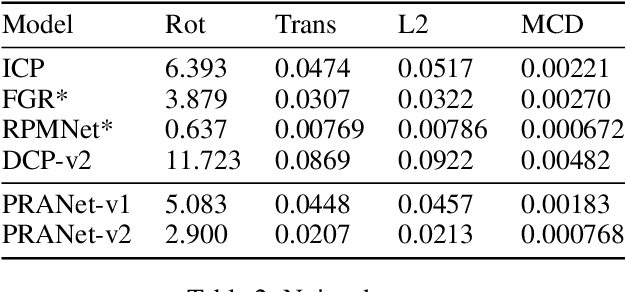
Point cloud registration plays a critical role in a multitude of computer vision tasks, such as pose estimation and 3D localization. Recently, a plethora of deep learning methods were formulated that aim to tackle this problem. Most of these approaches find point or feature correspondences, from which the transformations are computed. We give a different perspective and frame the registration problem as a Markov Decision Process. Instead of directly searching for the transformation, the problem becomes one of finding a sequence of translation and rotation actions that is equivalent to this transformation. To this end, we propose an artificial agent trained end-to-end using deep supervised learning. In contrast to conventional reinforcement learning techniques, the observations are sampled i.i.d. and thus no experience replay buffer is required, resulting in a more streamlined training process. Experiments on ModelNet40 show results comparable or superior to the state of the art in the case of clean, noisy and partially visible datasets.
Online Multitask Learning with Long-Term Memory
Aug 17, 2020
We introduce a novel online multitask setting. In this setting each task is partitioned into a sequence of segments that is unknown to the learner. Associated with each segment is a hypothesis from some hypothesis class. We give algorithms that are designed to exploit the scenario where there are many such segments but significantly fewer associated hypotheses. We prove regret bounds that hold for any segmentation of the tasks and any association of hypotheses to the segments. In the single-task setting this is equivalent to switching with long-term memory in the sense of [Bousquet and Warmuth; 2003]. We provide an algorithm that predicts on each trial in time linear in the number of hypotheses when the hypothesis class is finite. We also consider infinite hypothesis classes from reproducing kernel Hilbert spaces for which we give an algorithm whose per trial time complexity is cubic in the number of cumulative trials. In the single-task special case this is the first example of an efficient regret-bounded switching algorithm with long-term memory for a non-parametric hypothesis class.
Online Matrix Completion with Side Information
Jun 17, 2019
We give an online algorithm and prove novel mistake and regret bounds for online binary matrix completion with side information. The bounds we prove are of the form $\tilde{\mathcal{O}}({\mathcal{D}}/{\gamma^2})$. The term ${1}/{\gamma^2}$ is analogous to the usual margin term in SVM (perceptron) bounds. More specifically, if we assume that there is some factorization of the underlying $m\times n$ matrix into $\mathbf{P} \mathbf{Q}^{\top}$ where the rows of $\mathbf{P}$ are interpreted as ``classifiers'' in $\Re^d$ and the rows of $\mathbf{Q}$ as ``instances'' in $\Re^d$, then $\gamma$ is is the maximum (normalized) margin over all factorizations $\mathbf{P} \mathbf{Q}^{\top}$ consistent with the observed matrix. The quasi-dimension term $\mathcal{D}$ measures the quality of side information. In the presence of no side information, $\mathcal{D} = m+n$. However, if the side information is predictive of the underlying factorization of the matrix, then in the best case, $\mathcal{D} \in \mathcal{O}(k + \ell)$ where $k$ is the number of distinct row factors and $\ell$ is the number of distinct column factors. We additionally provide a generalization of our algorithm to the inductive setting. In this setting, the side information is not specified in advance. The results are similar to the transductive setting but in the best case, the quasi-dimension $\mathcal{D}$ is now bounded by $\mathcal{O}(k^2 + \ell^2)$.
Graph Cut Segmentation Methods Revisited with a Quantum Algorithm
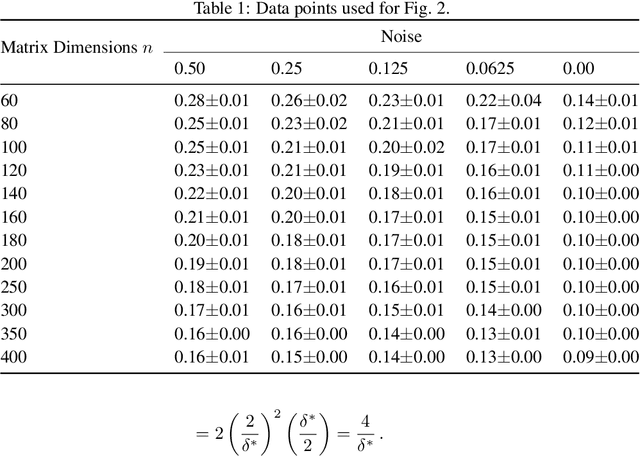
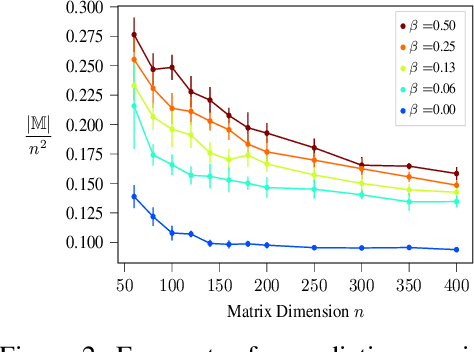
Dec 07, 2018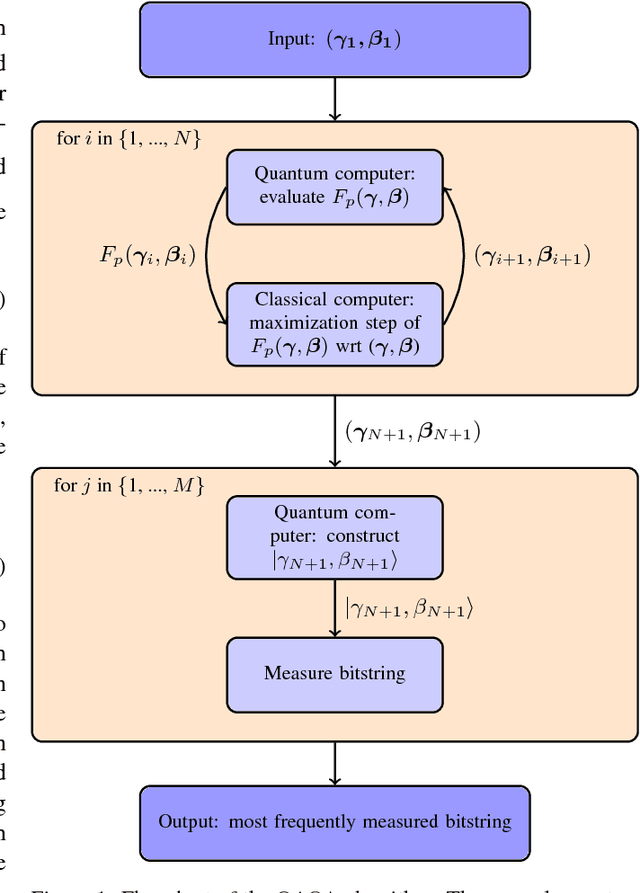
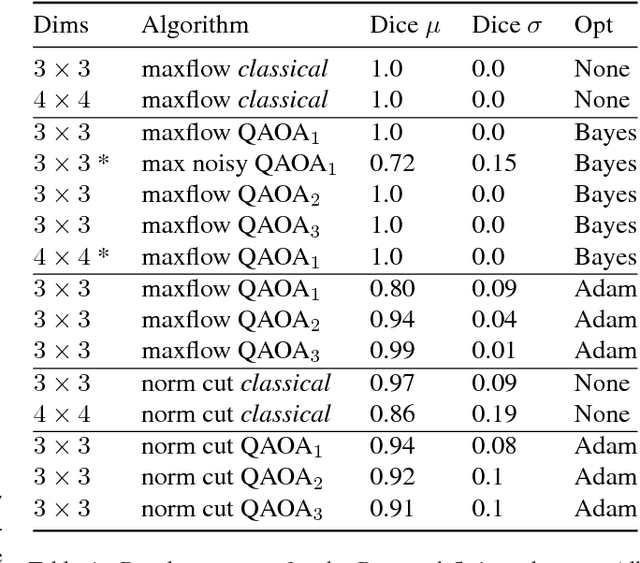
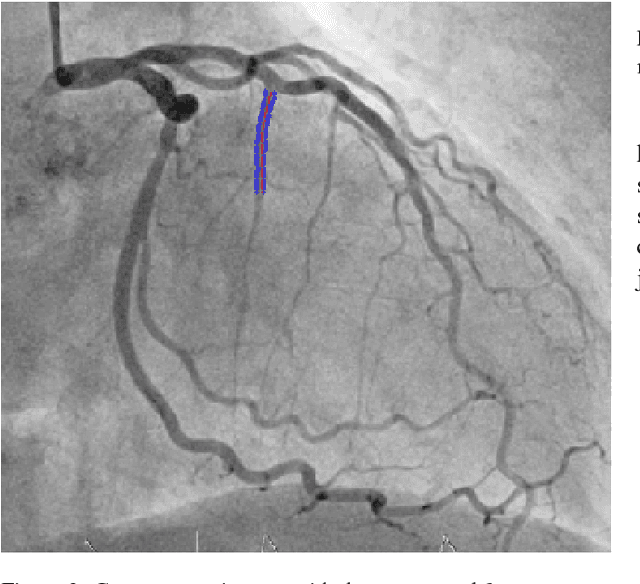
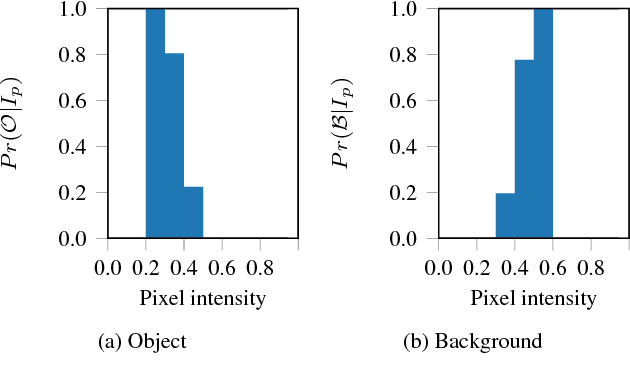
The design and performance of computer vision algorithms are greatly influenced by the hardware on which they are implemented. CPUs, multi-core CPUs, FPGAs and GPUs have inspired new algorithms and enabled existing ideas to be realized. This is notably the case with GPUs, which has significantly changed the landscape of computer vision research through deep learning. As the end of Moores law approaches, researchers and hardware manufacturers are exploring alternative hardware computing paradigms. Quantum computers are a very promising alternative and offer polynomial or even exponential speed-ups over conventional computing for some problems. This paper presents a novel approach to image segmentation that uses new quantum computing hardware. Segmentation is formulated as a graph cut problem that can be mapped to the quantum approximation optimization algorithm (QAOA). This algorithm can be implemented on current and near-term quantum computers. Encouraging results are presented on artificial and medical imaging data. This represents an important, practical step towards leveraging quantum computers for computer vision.