 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fully Non-autoregressive Neural Machine Translation: Tricks of the Trade
Dec 31, 2020
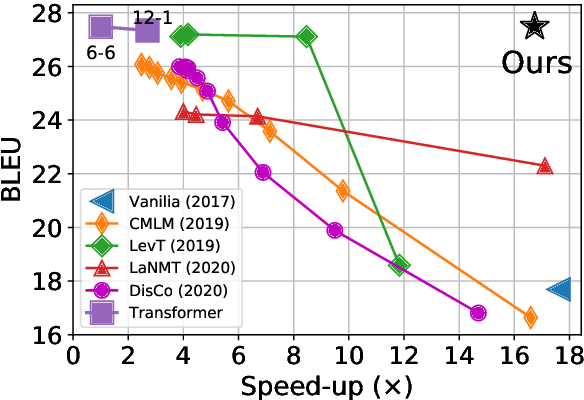
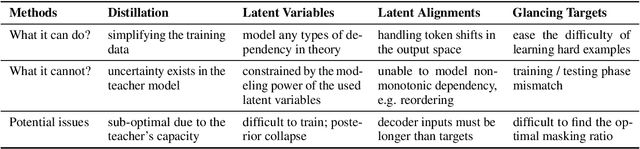

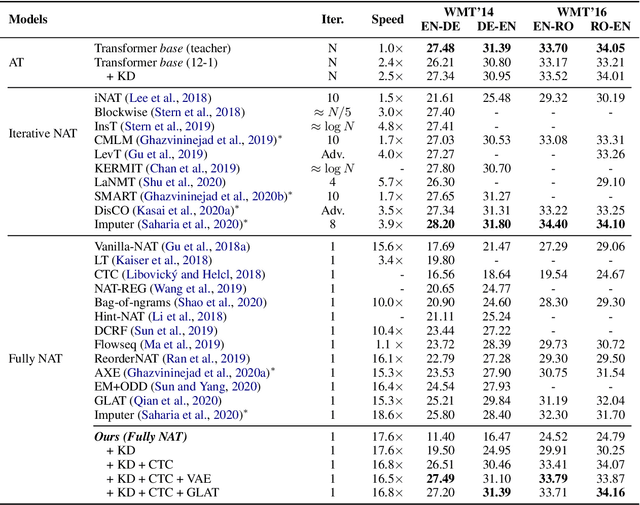
Fully non-autoregressive neural machine translation (NAT) is proposed to simultaneously predict tokens with single forward of neural networks, which significantly reduces the inference latency at the expense of quality drop compared to the Transformer baseline. In this work, we target on closing the performance gap while maintaining the latency advantage. We first inspect the fundamental issues of fully NAT models, and adopt dependency reduction in the learning space of output tokens as the basic guidance. Then, we revisit methods in four different aspects that have been proven effective for improving NAT models, and carefully combine these techniques with necessary modifications. Our extensive experiments on three translation benchmarks show that the proposed system achieves the new state-of-the-art results for fully NAT models, and obtains comparable performance with the autoregressive and iterative NAT systems. For instance, one of the proposed models achieves 27.49 BLEU points on WMT14 En-De with approximately 16.5X speed up at inference time.
Robust Real-Time Multi-View Eye Tracking
Jan 03, 2018

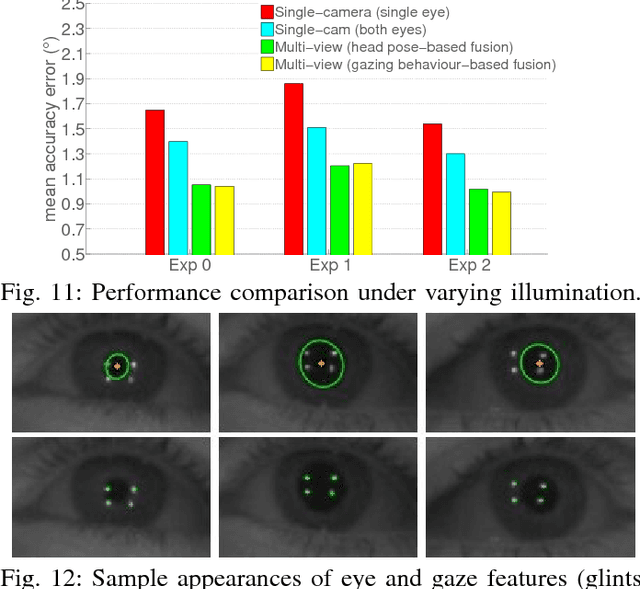
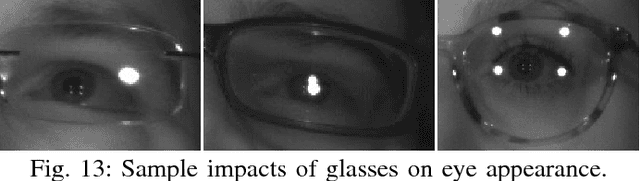
Despite significant advances in improving the gaze tracking accuracy under controlled conditions, the tracking robustness under real-world conditions, such as large head pose and movements, use of eyeglasses, illumination and eye type variations, remains a major challenge in eye tracking. In this paper, we revisit this challenge and introduce a real-time multi-camera eye tracking framework to improve the tracking robustness. First, differently from previous work, we design a multi-view tracking setup that allows for acquiring multiple eye appearances simultaneously. Leveraging multi-view appearances enables to more reliably detect gaze features under challenging conditions, particularly when they are obstructed in conventional single-view appearance due to large head movements or eyewear effects. The features extracted on various appearances are then used for estimating multiple gaze outputs. Second, we propose to combine estimated gaze outputs through an adaptive fusion mechanism to compute user's overall point of regard. The proposed mechanism firstly determines the estimation reliability of each gaze output according to user's momentary head pose and predicted gazing behavior, and then performs a reliability-based weighted fusion. We demonstrate the efficacy of our framework with extensive simulations and user experiments on a collected dataset featuring 20 subjects. Our results show that in comparison with state-of-the-art eye trackers, the proposed framework provides not only a significant enhancement in accuracy but also a notable robustness. Our prototype system runs at 30 frames-per-second (fps) and achieves 1 degree accuracy under challenging experimental scenarios, which makes it suitable for applications demanding high accuracy and robustness.
Hierarchical Prosody Modeling for Non-Autoregressive Speech Synthesis
Nov 17, 2020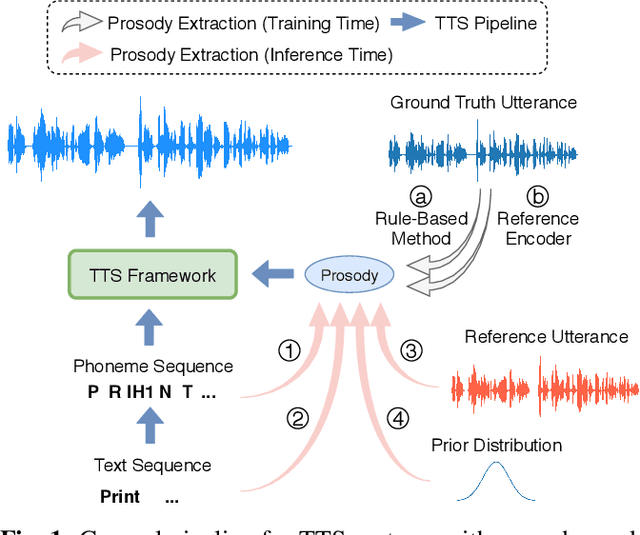
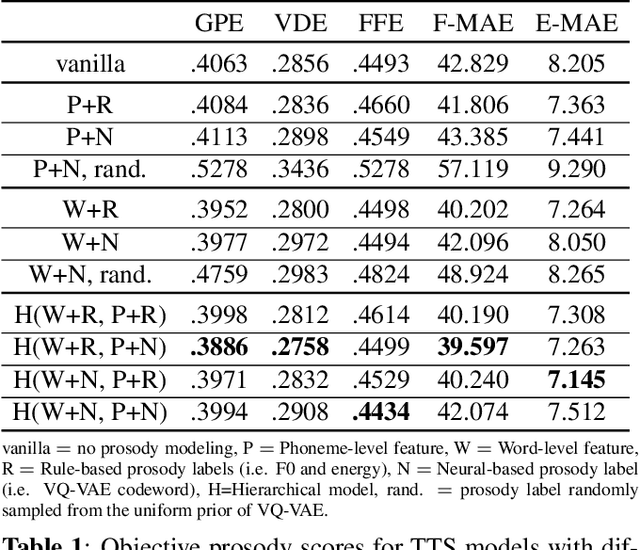
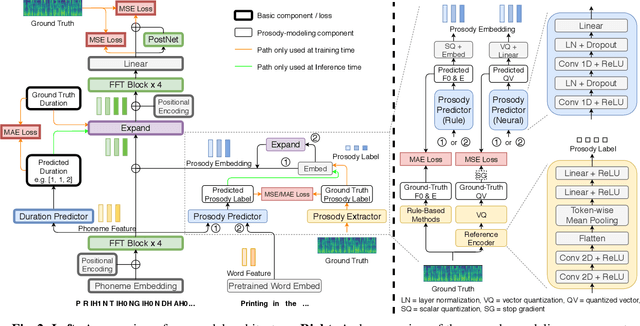
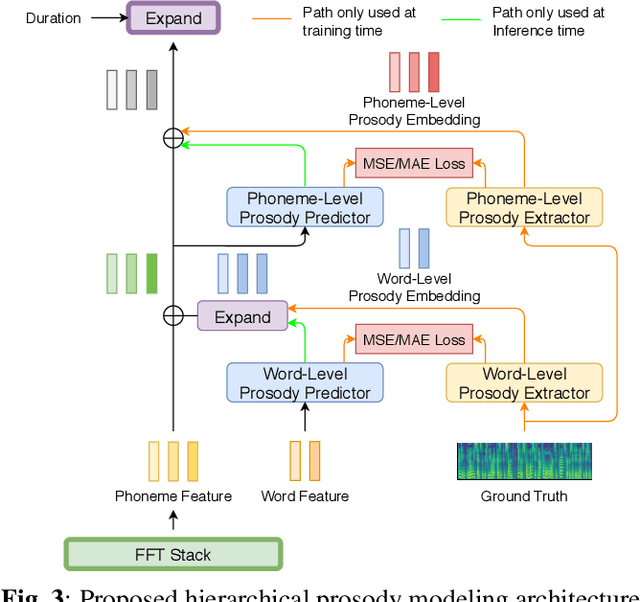
Prosody modeling is an essential component in modern text-to-speech (TTS) frameworks. By explicitly providing prosody features to the TTS model, the style of synthesized utterances can thus be controlled. However, predicting natural and reasonable prosody at inference time is challenging. In this work, we analyzed the behavior of non-autoregressive TTS models under different prosody-modeling settings and proposed a hierarchical architecture, in which the prediction of phoneme-level prosody features are conditioned on the word-level prosody features. The proposed method outperforms other competitors in terms of audio quality and prosody naturalness in our objective and subjective evaluation.
ERNIE-DOC: The Retrospective Long-Document Modeling Transformer
Dec 31, 2020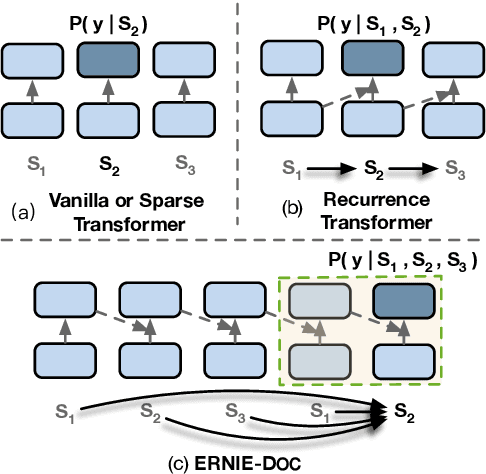
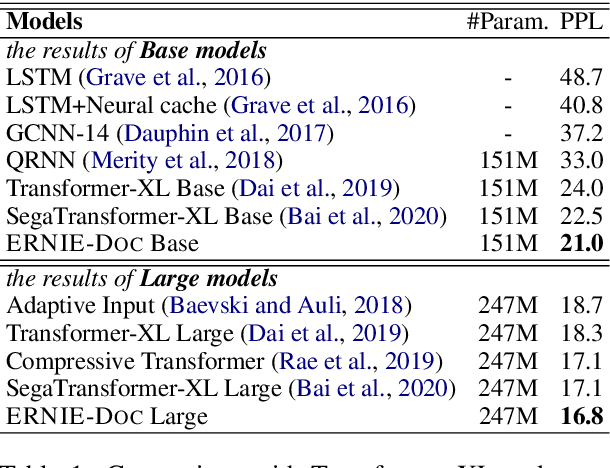
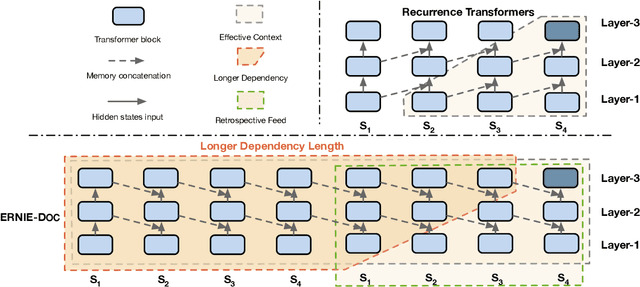
Transformers are not suited for processing long document input due to its quadratically increasing memory and time consumption. Simply truncating a long document or applying the sparse attention mechanism will incur the context fragmentation problem or inferior modeling capability with comparable model size. In this paper, we propose ERNIE-DOC, a document-level language pretraining model based on Recurrence Transformers. Two well-designed techniques, namely the retrospective feed mechanism and the enhanced recurrence mechanism enable ERNIE-DOC with much longer effective context length to capture the contextual information of a whole document. We pretrain ERNIE-DOC to explicitly learn the relationship among segments with an additional document-aware segment reordering objective. Various experiments on both English and Chinese document-level tasks are conducted. ERNIE-DOC achieves SOTA language modeling result of 16.8 ppl on WikiText-103 and outperforms competitive pretraining models on most language understanding tasks such as text classification, question answering by a large margin.
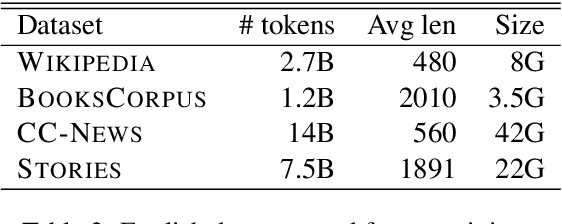
Automatic Extraction of Rules Governing Morphological Agreement
Oct 02, 2020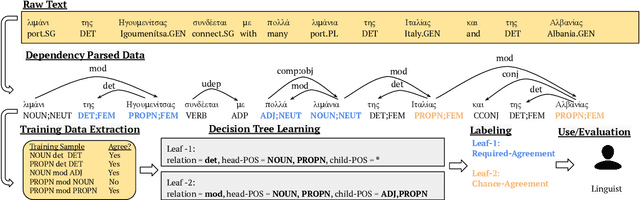
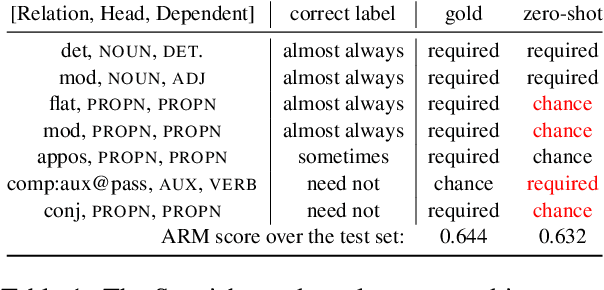
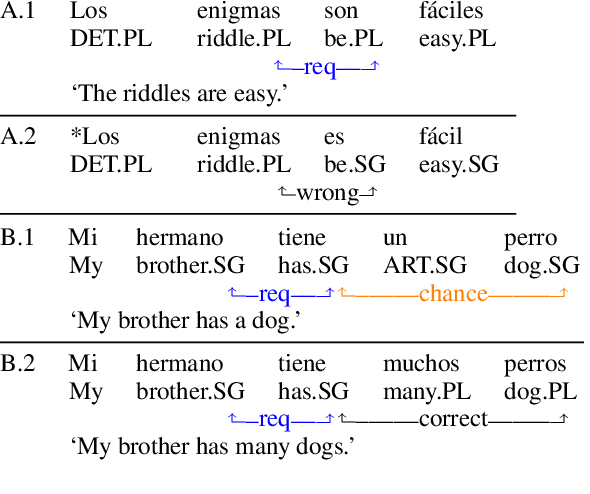
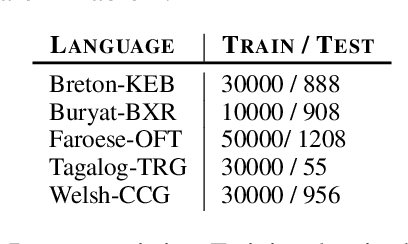
Creating a descriptive grammar of a language is an indispensable step for language documentation and preservation. However, at the same time it is a tedious, time-consuming task. In this paper, we take steps towards automating this process by devising an automated framework for extracting a first-pass grammatical specification from raw text in a concise, human- and machine-readable format. We focus on extracting rules describing agreement, a morphosyntactic phenomenon at the core of the grammars of many of the world's languages. We apply our framework to all languages included in the Universal Dependencies project, with promising results. Using cross-lingual transfer, even with no expert annotations in the language of interest, our framework extracts a grammatical specification which is nearly equivalent to those created with large amounts of gold-standard annotated data. We confirm this finding with human expert evaluations of the rules that our framework produces, which have an average accuracy of 78%. We release an interface demonstrating the extracted rules at https://neulab.github.io/lase/.
Deep learning in magnetic resonance prostate segmentation: A review and a new perspective
Nov 16, 2020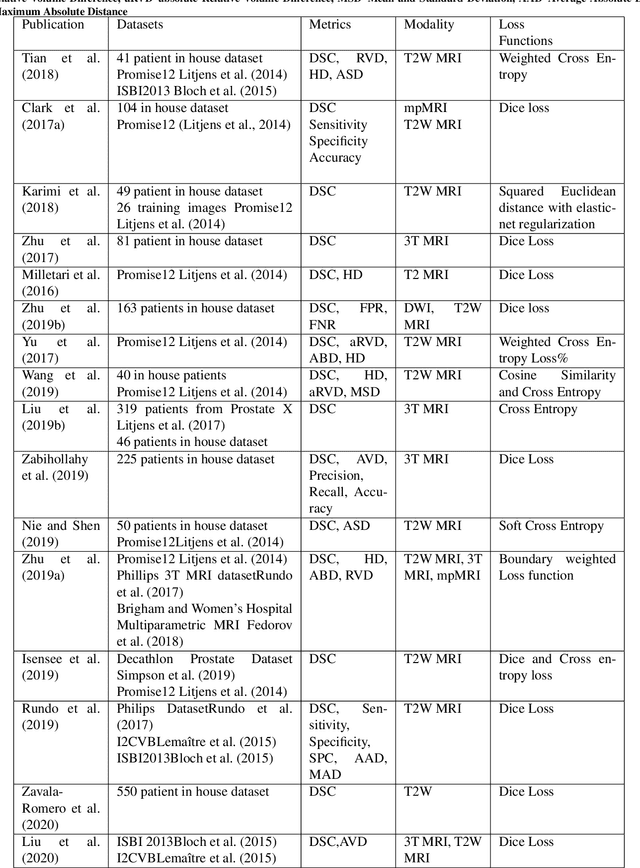
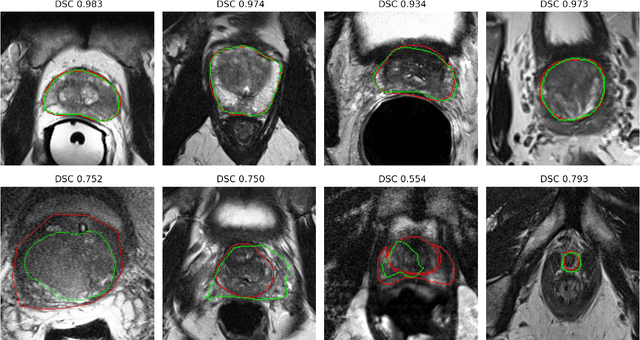
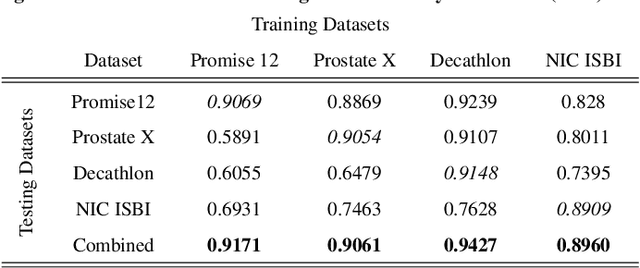
Prostate radiotherapy is a well established curative oncology modality, which in future will use Magnetic Resonance Imaging (MRI)-based radiotherapy for daily adaptive radiotherapy target definition. However the time needed to delineate the prostate from MRI data accurately is a time consuming process. Deep learning has been identified as a potential new technology for the delivery of precision radiotherapy in prostate cancer, where accurate prostate segmentation helps in cancer detection and therapy. However, the trained models can be limited in their application to clinical setting due to different acquisition protocols, limited publicly available datasets, where the size of the datasets are relatively small. Therefore, to explore the field of prostate segmentation and to discover a generalisable solution, we review the state-of-the-art deep learning algorithms in MR prostate segmentation; provide insights to the field by discussing their limitations and strengths; and propose an optimised 2D U-Net for MR prostate segmentation. We evaluate the performance on four publicly available datasets using Dice Similarity Coefficient (DSC) as performance metric. Our experiments include within dataset evaluation and cross-dataset evaluation. The best result is achieved by composite evaluation (DSC of 0.9427 on Decathlon test set) and the poorest result is achieved by cross-dataset evaluation (DSC of 0.5892, Prostate X training set, Promise 12 testing set). We outline the challenges and provide recommendations for future work. Our research provides a new perspective to MR prostate segmentation and more importantly, we provide standardised experiment settings for researchers to evaluate their algorithms. Our code is available at https://github.com/AIEMMU/MRI\_Prostate.
Searching for a Search Method: Benchmarking Search Algorithms for Generating NLP Adversarial Examples
Oct 12, 2020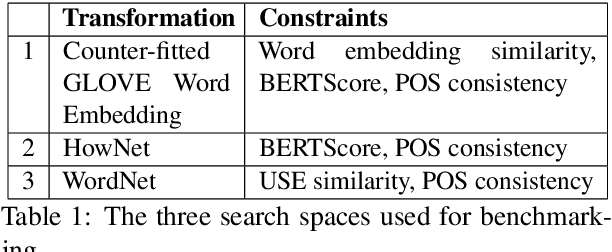
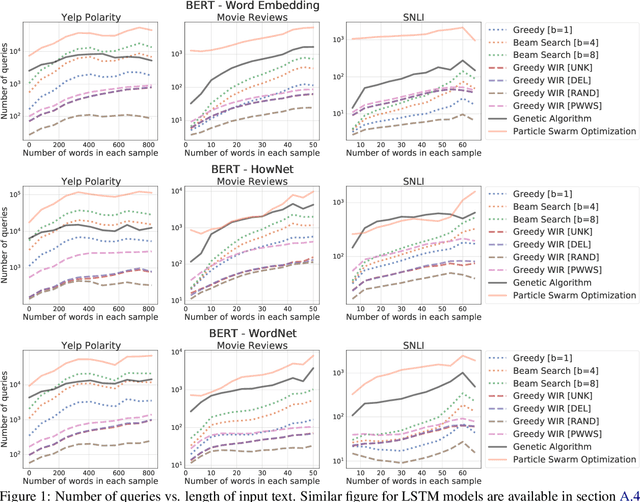
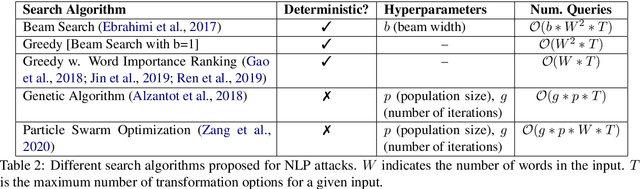
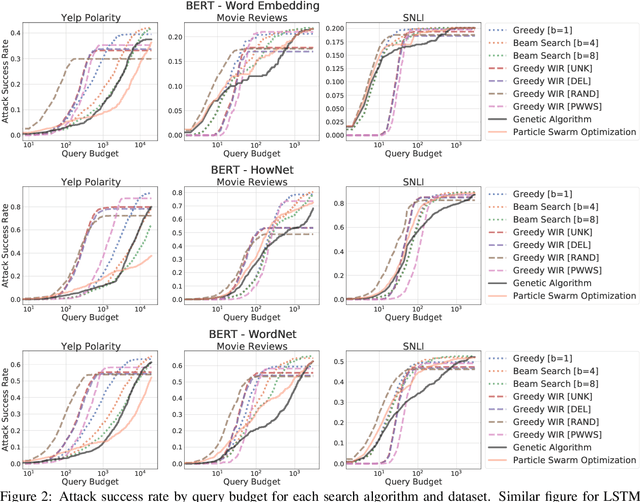
We study the behavior of several black-box search algorithms used for generating adversarial examples for natural language processing (NLP) tasks. We perform a fine-grained analysis of three elements relevant to search: search algorithm, search space, and search budget. When new search algorithms are proposed in past work, the attack search space is often modified alongside the search algorithm. Without ablation studies benchmarking the search algorithm change with the search space held constant, one cannot tell if an increase in attack success rate is a result of an improved search algorithm or a less restrictive search space. Additionally, many previous studies fail to properly consider the search algorithms' run-time cost, which is essential for downstream tasks like adversarial training. Our experiments provide a reproducible benchmark of search algorithms across a variety of search spaces and query budgets to guide future research in adversarial NLP. Based on our experiments, we recommend greedy attacks with word importance ranking when under a time constraint or attacking long inputs, and either beam search or particle swarm optimization otherwise. Code implementation shared via https://github.com/QData/TextAttack-Search-Benchmark
Supervised training of spiking neural networks for robust deployment on mixed-signal neuromorphic processors
Feb 12, 2021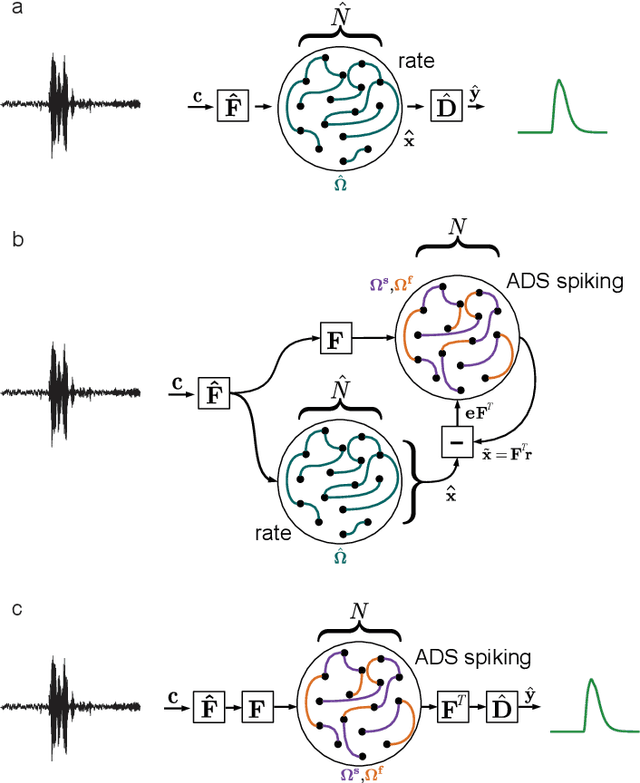
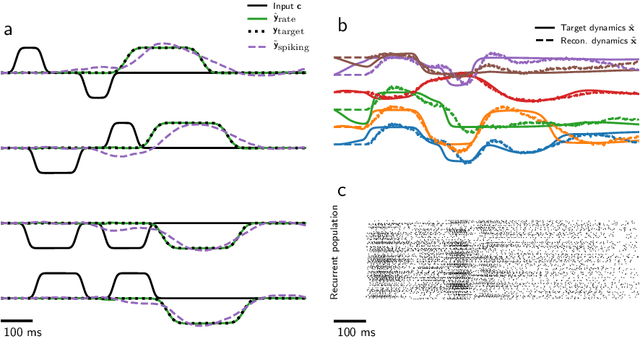
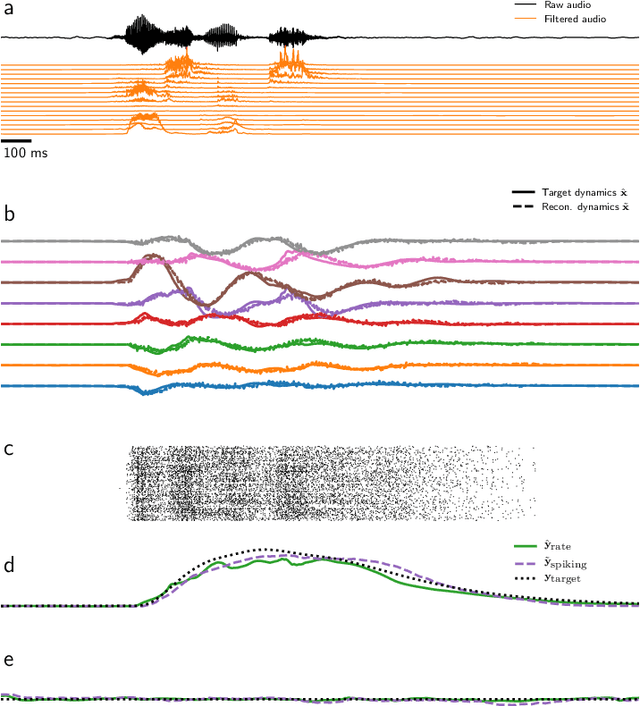
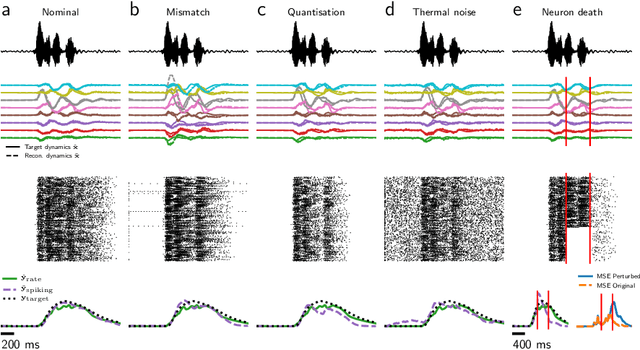
Mixed-signal analog/digital electronic circuits can emulate spiking neurons and synapses with extremely high energy efficiency, following an approach known as "neuromorphic engineering". However, analog circuits are sensitive to variation in fabrication among transistors in a chip ("device mismatch"). In the case of neuromorphic implementation of Spiking Neural Networks (SNNs), mismatch is expressed as differences in effective parameters between identically-configured neurons and synapses. Each fabricated chip therefore provides a different distribution of parameters such as time constants or synaptic weights. Without the expensive overhead in terms of area and power of extra on-chip learning or calibration circuits, device mismatch and other noise sources represent a critical challenge for the deployment of pre-trained neural network chips. Here we present a supervised learning approach that addresses this challenge by maximizing robustness to mismatch and other common sources of noise. The proposed method trains (SNNs) to perform temporal classification tasks by mimicking a pre-trained dynamical system, using a local learning rule adapted from non-linear control theory. We demonstrate the functionality of our model on two tasks that require memory to perform successfully, and measure the robustness of our approach to several forms of noise and variability present in the network. We show that our approach is more robust than several common alternative approaches for training SNNs. Our method provides a viable way to robustly deploy pre-trained networks on mixed-signal neuromorphic hardware, without requiring per-device training or calibration.
Auto-CASH: Autonomous Classification Algorithm Selection with Deep Q-Network
Jul 07, 2020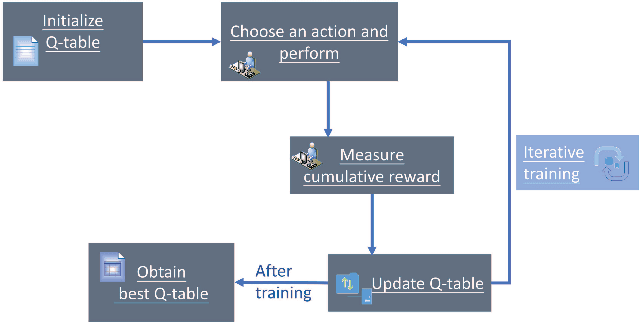

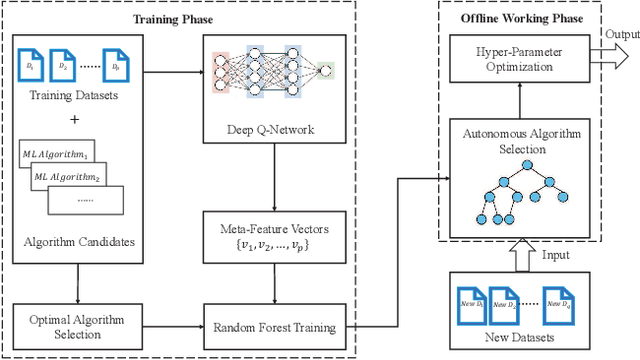
The great amount of datasets generated by various data sources have posed the challenge to machine learning algorithm selection and hyperparameter configuration. For a specific machine learning task, it usually takes domain experts plenty of time to select an appropriate algorithm and configure its hyperparameters. If the problem of algorithm selection and hyperparameter optimization can be solved automatically, the task will be executed more efficiently with performance guarantee. Such problem is also known as the CASH problem. Early work either requires a large amount of human labor, or suffers from high time or space complexity. In our work, we present Auto-CASH, a pre-trained model based on meta-learning, to solve the CASH problem more efficiently. Auto-CASH is the first approach that utilizes Deep Q-Network to automatically select the meta-features for each dataset, thus reducing the time cost tremendously without introducing too much human labor. To demonstrate the effectiveness of our model, we conduct extensive experiments on 120 real-world classification datasets. Compared with classical and the state-of-art CASH approaches, experimental results show that Auto-CASH achieves better performance within shorter time.
OvA-INN: Continual Learning with Invertible Neural Networks
Jun 24, 2020
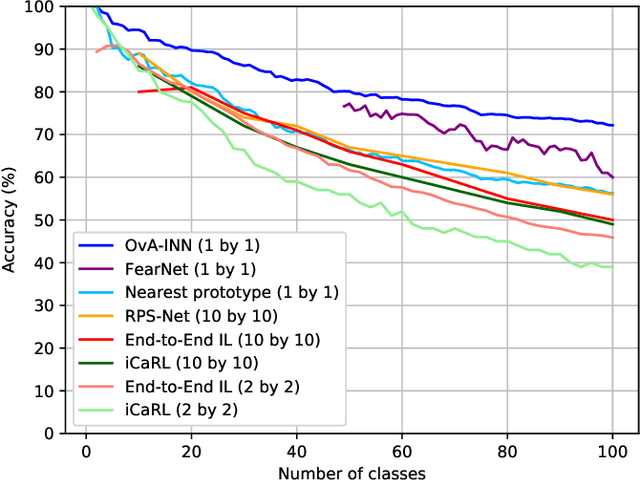
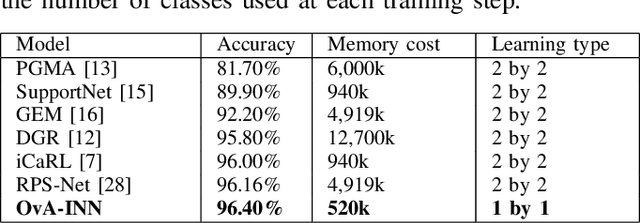
In the field of Continual Learning, the objective is to learn several tasks one after the other without access to the data from previous tasks. Several solutions have been proposed to tackle this problem but they usually assume that the user knows which of the tasks to perform at test time on a particular sample, or rely on small samples from previous data and most of them suffer of a substantial drop in accuracy when updated with batches of only one class at a time. In this article, we propose a new method, OvA-INN, which is able to learn one class at a time and without storing any of the previous data. To achieve this, for each class, we train a specific Invertible Neural Network to extract the relevant features to compute the likelihood on this class. At test time, we can predict the class of a sample by identifying the network which predicted the highest likelihood. With this method, we show that we can take advantage of pretrained models by stacking an Invertible Network on top of a feature extractor. This way, we are able to outperform state-of-the-art approaches that rely on features learning for the Continual Learning of MNIST and CIFAR-100 datasets. In our experiments, we reach 72% accuracy on CIFAR-100 after training our model one class at a time.