 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Data Anomaly Detection for Structural Health Monitoring of Bridges using Shapelet Transform
Aug 31, 2020
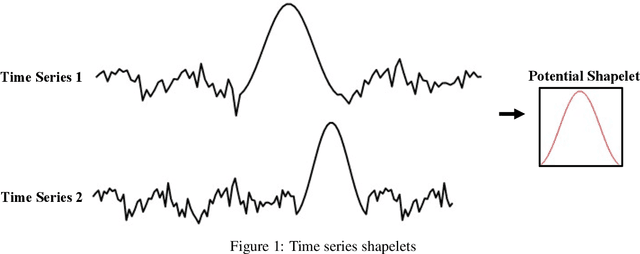

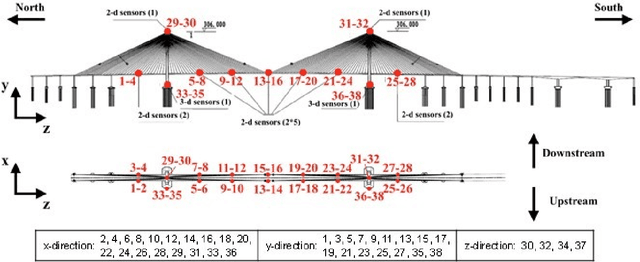
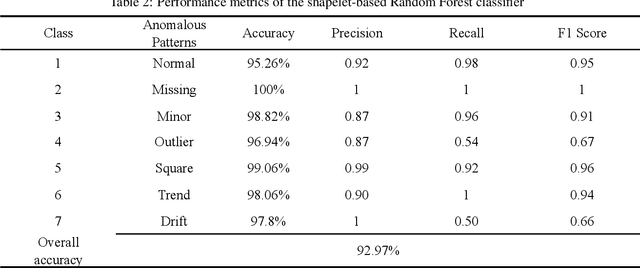
With the wider availability of sensor technology, a number of Structural Health Monitoring (SHM) systems are deployed to monitor civil infrastructure. The continuous monitoring provides valuable information about the structure that can help in providing a decision support system for retrofits and other structural modifications. However, when the sensors are exposed to harsh environmental conditions, the data measured by the SHM systems tend to be affected by multiple anomalies caused by faulty or broken sensors. Given a deluge of high-dimensional data collected continuously over time, research into using machine learning methods to detect anomalies are a topic of great interest to the SHM community. This paper contributes to this effort by proposing the use of a relatively new time series representation named Shapelet Transform in combination with a Random Forest classifier to autonomously identify anomalies in SHM data. The shapelet transform is a unique time series representation that is solely based on the shape of the time series data. In consideration of the individual characteristics unique to every anomaly, the application of this transform yields a new shape-based feature representation that can be combined with any standard machine learning algorithm to detect anomalous data with no manual intervention. For the present study, the anomaly detection framework consists of three steps: identifying unique shapes from anomalous data, using these shapes to transform the SHM data into a local-shape space and training machine learning algorithm on this transformed data to identify anomalies. The efficacy of this method is demonstrated by the identification of anomalies in acceleration data from a SHM system installed on a long-span bridge in China. The results show that multiple data anomalies in SHM data can be automatically detected with high accuracy using the proposed method.
Scaling Deep Contrastive Learning Batch Size with Almost Constant Peak Memory Usage
Jan 18, 2021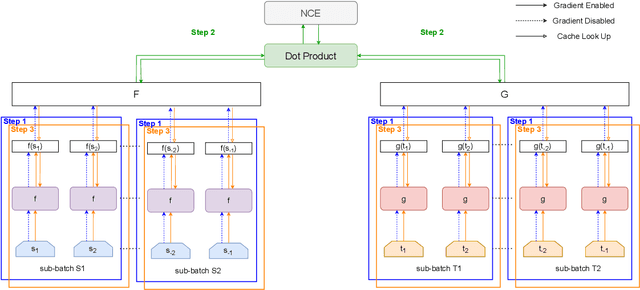
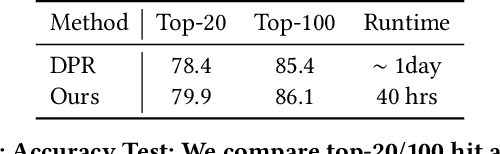
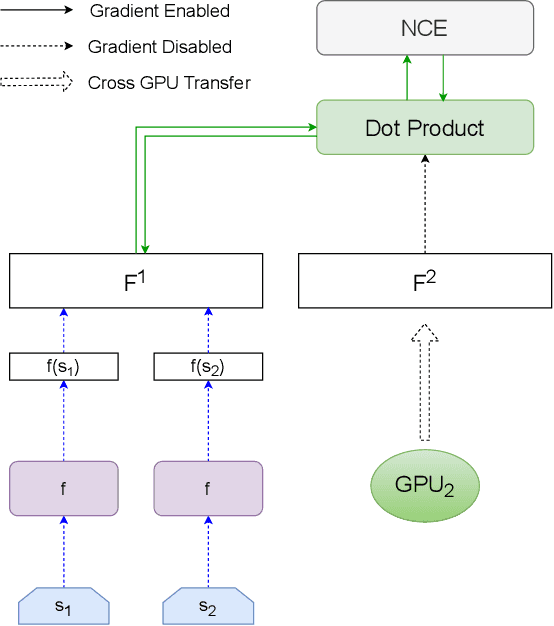
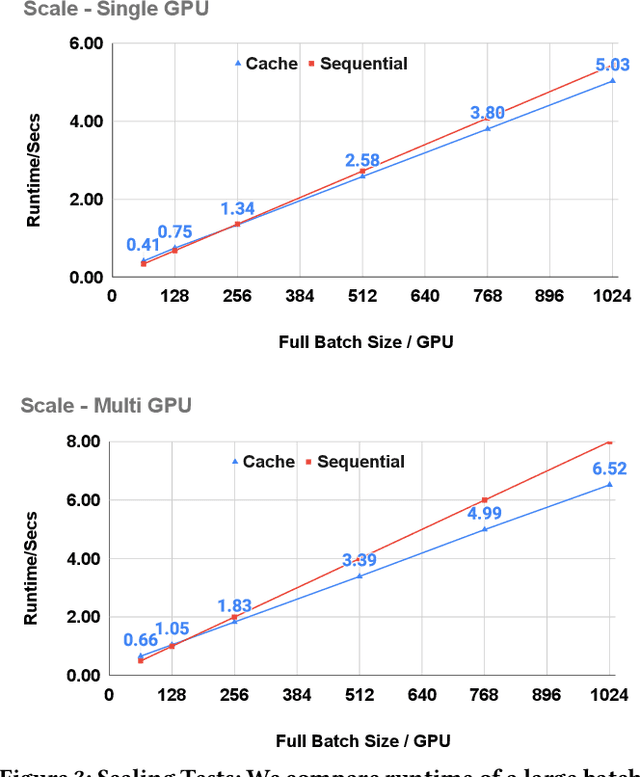
Contrastive learning has been applied successfully to learn numerical vector representations of various forms of data, such as texts and images. Learned encoders exhibit versatile transfer capabilities to many downstream tasks. Representation based search is highly efficient with state-of-the-art performance. Previous researches demonstrated that learning high-quality representations requires a large number of negatives in contrastive loss. In practice, the technique of in-batch negative is used, where for each example in a batch, other batch examples' positives will be taken as its negatives, avoiding encoding extra negatives. This, however, still conditions each example's loss on all batch examples and requires fitting the entire large batch into GPU memory. This paper introduces a re-computation technique that decouples back propagation between contrastive loss and the encoder, removing encoder backward pass data dependency along the batch dimension. As a result, gradients can be computed for one subset of the batch at a time, leading to an almost constant peak GPU memory usage for batches of different sizes.
Skewed Laplace Spectral Mixture kernels for long-term forecasting in Gaussian process
Nov 08, 2020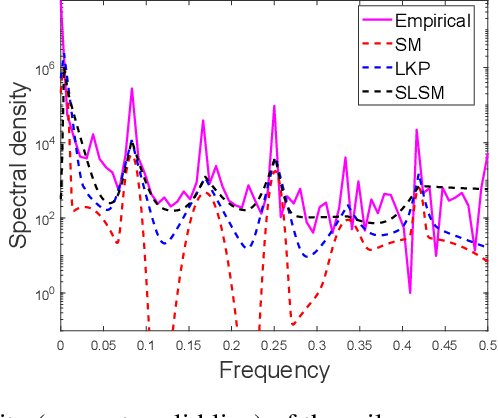
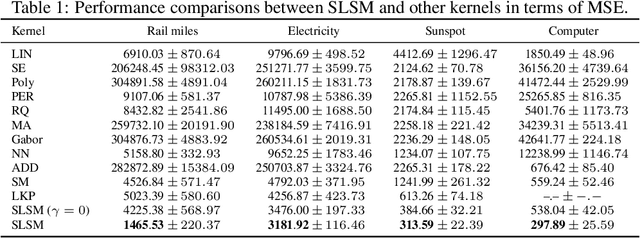
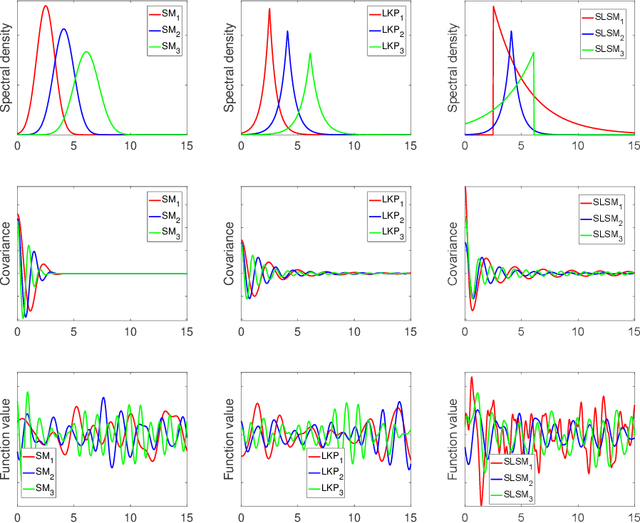
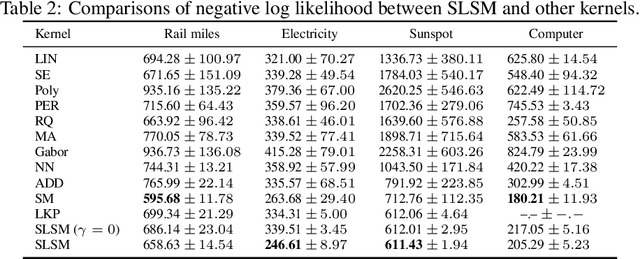
Long-term forecasting involves predicting a horizon that is far ahead of the last observation. It is a problem of highly practical relevance, for instance for companies in order to decide upon expensive long-term investments. Despite recent progress and success of Gaussian Processes (GPs) based on Spectral Mixture kernels, long-term forecasting remains a challenging problem for these kernels because they decay exponentially at large horizons. This is mainly due their use of a mixture of Gaussians to model spectral densities. The challenges underlying long-term forecasting become evident by investigating the distribution of the Fourier coefficients of (the training part of) the signal, which is non-smooth, heavy-tailed, sparse and skewed. Notably the heavy tail and skewness characteristics of such distribution in spectral domain allow to capture long range covariance of the signal in the time domain. Motivated by these observations, we propose to model spectral densities using a Skewed Laplace Spectral Mixture (SLSM) due to the skewness of its peaks, sparsity, non-smoothness, and heavy tail characteristics. By applying the inverse Fourier Transform to this spectral density we obtain a new GP kernel for long-term forecasting. Results of extensive experiments, including a multivariate time series, show the beneficial effect of the proposed SLSM kernel for long-term extrapolation and robustness to the choice of the number of mixture components.
Inheritance-guided Hierarchical Assignment for Clinical Automatic Diagnosis
Jan 27, 2021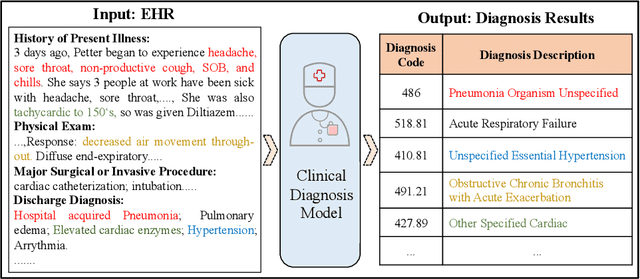
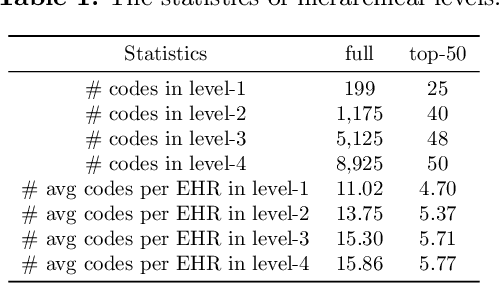
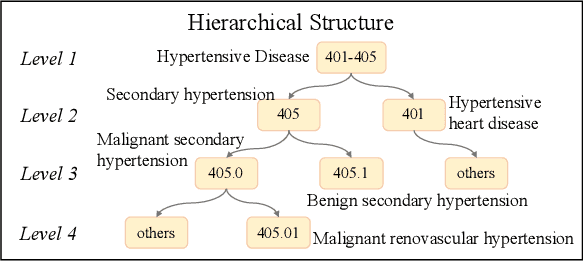
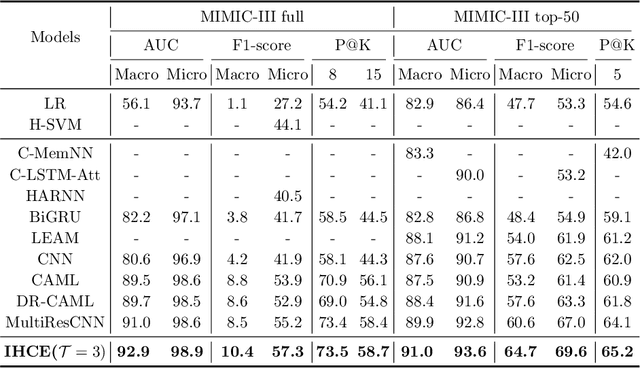
Clinical diagnosis, which aims to assign diagnosis codes for a patient based on the clinical note, plays an essential role in clinical decision-making. Considering that manual diagnosis could be error-prone and time-consuming, many intelligent approaches based on clinical text mining have been proposed to perform automatic diagnosis. However, these methods may not achieve satisfactory results due to the following challenges. First, most of the diagnosis codes are rare, and the distribution is extremely unbalanced. Second, existing methods are challenging to capture the correlation between diagnosis codes. Third, the lengthy clinical note leads to the excessive dispersion of key information related to codes. To tackle these challenges, we propose a novel framework to combine the inheritance-guided hierarchical assignment and co-occurrence graph propagation for clinical automatic diagnosis. Specifically, we propose a hierarchical joint prediction strategy to address the challenge of unbalanced codes distribution. Then, we utilize graph convolutional neural networks to obtain the correlation and semantic representations of medical ontology. Furthermore, we introduce multi attention mechanisms to extract crucial information. Finally, extensive experiments on MIMIC-III dataset clearly validate the effectiveness of our method.
Feature space approximation for kernel-based supervised learning
Nov 25, 2020
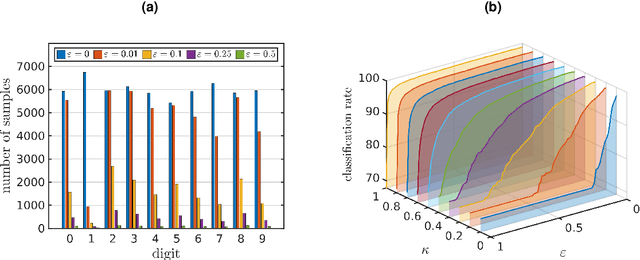
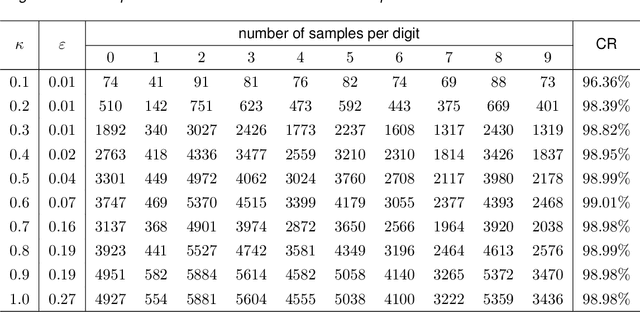
We propose a method for the approximation of high- or even infinite-dimensional feature vectors, which play an important role in supervised learning. The goal is to reduce the size of the training data, resulting in lower storage consumption and computational complexity. Furthermore, the method can be regarded as a regularization technique, which improves the generalizability of learned target functions. We demonstrate significant improvements in comparison to the computation of data-driven predictions involving the full training data set. The method is applied to classification and regression problems from different application areas such as image recognition, system identification, and oceanographic time series analysis.
Adaptive Online Estimation of Piecewise Polynomial Trends
Sep 30, 2020
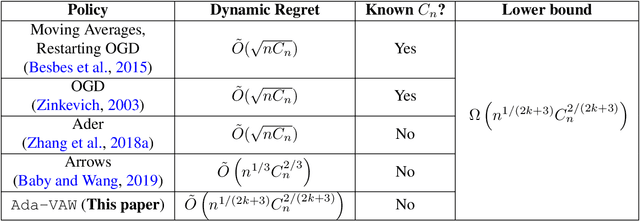
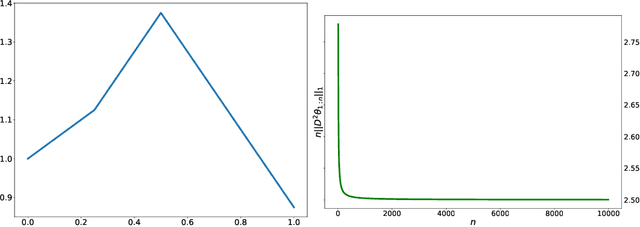

We consider the framework of non-stationary stochastic optimization [Besbes et al, 2015] with squared error losses and noisy gradient feedback where the dynamic regret of an online learner against a time varying comparator sequence is studied. Motivated from the theory of non-parametric regression, we introduce a new variational constraint that enforces the comparator sequence to belong to a discrete $k^{th}$ order Total Variation ball of radius $C_n$. This variational constraint models comparators that have piece-wise polynomial structure which has many relevant practical applications [Tibshirani, 2014]. By establishing connections to the theory of wavelet based non-parametric regression, we design a polynomial time algorithm that achieves the nearly optimal dynamic regret of $\tilde{O}(n^{\frac{1}{2k+3}}C_n^{\frac{2}{2k+3}})$. The proposed policy is adaptive to the unknown radius $C_n$. Further, we show that the same policy is minimax optimal for several other non-parametric families of interest.
Monitoring and Diagnosability of Perception Systems
Nov 16, 2020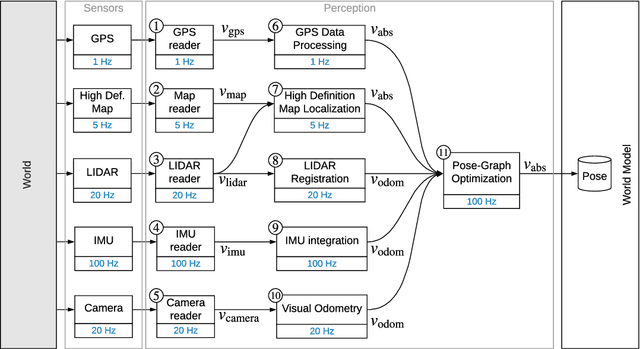
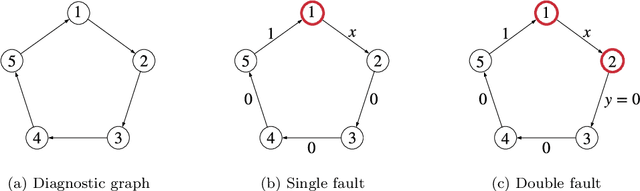
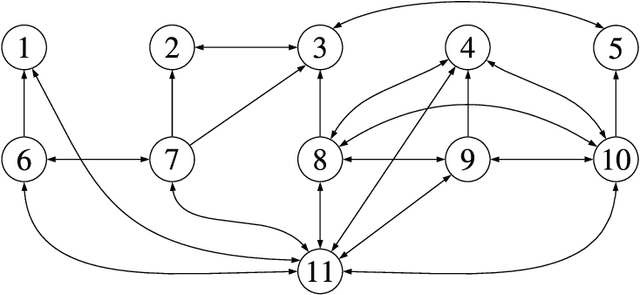
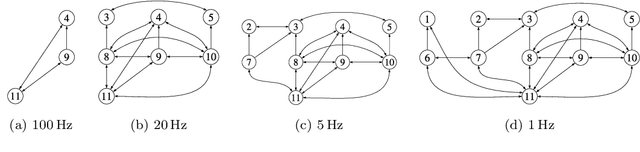
Perception is a critical component of high-integrity applications of robotics and autonomous systems, such as self-driving vehicles. In these applications, failure of perception systems may put human life at risk, and a broad adoption of these technologies requires the development of methodologies to guarantee and monitor safe operation. Despite the paramount importance of perception systems, currently there is no formal approach for system-level monitoring. In this work, we propose a mathematical model for runtime monitoring and fault detection and identification in perception systems. Towards this goal, we draw connections with the literature on diagnosability in multiprocessor systems, and generalize it to account for modules with heterogeneous outputs that interact over time. The resulting temporal diagnostic graphs (i) provide a framework to reason over the consistency of perception outputs -- across modules and over time -- thus enabling fault detection, (ii) allow us to establish formal guarantees on the maximum number of faults that can be uniquely identified in a given perception system, and (iii) enable the design of efficient algorithms for fault identification. We demonstrate our monitoring system, dubbed PerSyS, in realistic simulations using the LGSVL self-driving simulator and the Apollo Auto autonomy software stack, and show that PerSyS is able to detect failures in challenging scenarios (including scenarios that have caused self-driving car accidents in recent years), and is able to correctly identify faults while entailing a minimal computation overhead (< 5ms on a single-core CPU).
Serverless Model Serving for Data Science
Mar 04, 2021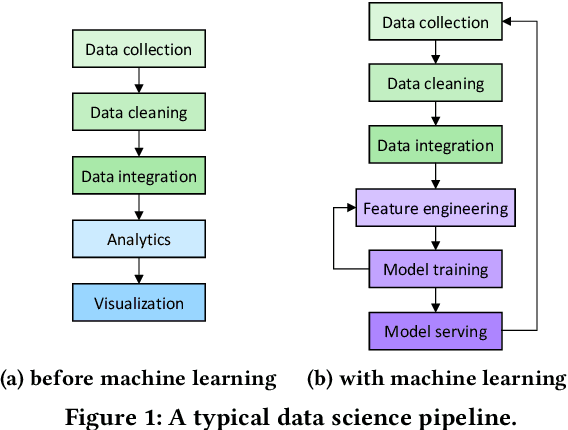
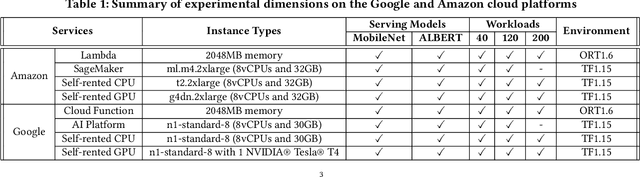
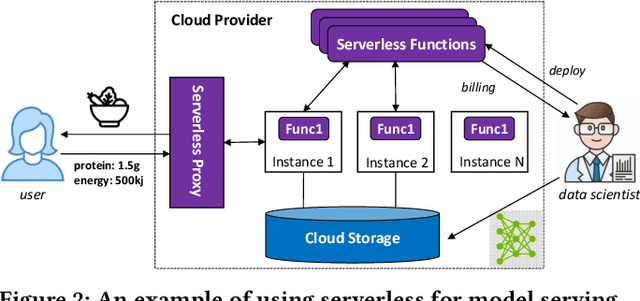
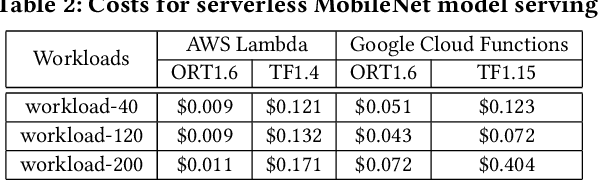
Machine learning (ML) is an important part of modern data science applications. Data scientists today have to manage the end-to-end ML life cycle that includes both model training and model serving, the latter of which is essential, as it makes their works available to end-users. Systems for model serving require high performance, low cost, and ease of management. Cloud providers are already offering model serving options, including managed services and self-rented servers. Recently, serverless computing, whose advantages include high elasticity and fine-grained cost model, brings another possibility for model serving. In this paper, we study the viability of serverless as a mainstream model serving platform for data science applications. We conduct a comprehensive evaluation of the performance and cost of serverless against other model serving systems on two clouds: Amazon Web Service (AWS) and Google Cloud Platform (GCP). We find that serverless outperforms many cloud-based alternatives with respect to cost and performance. More interestingly, under some circumstances, it can even outperform GPU-based systems for both average latency and cost. These results are different from previous works' claim that serverless is not suitable for model serving, and are contrary to the conventional wisdom that GPU-based systems are better for ML workloads than CPU-based systems. Other findings include a large gap in cold start time between AWS and GCP serverless functions, and serverless' low sensitivity to changes in workloads or models. Our evaluation results indicate that serverless is a viable option for model serving. Finally, we present several practical recommendations for data scientists on how to use serverless for scalable and cost-effective model serving.
Low-Complexity Joint CFO and CIR Estimation for RIS-aided wireless communications using OFDM
Jan 27, 2021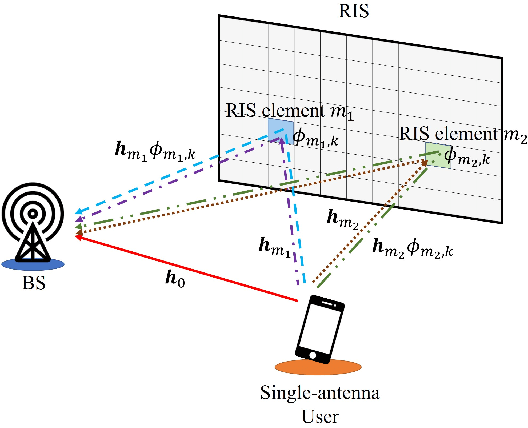
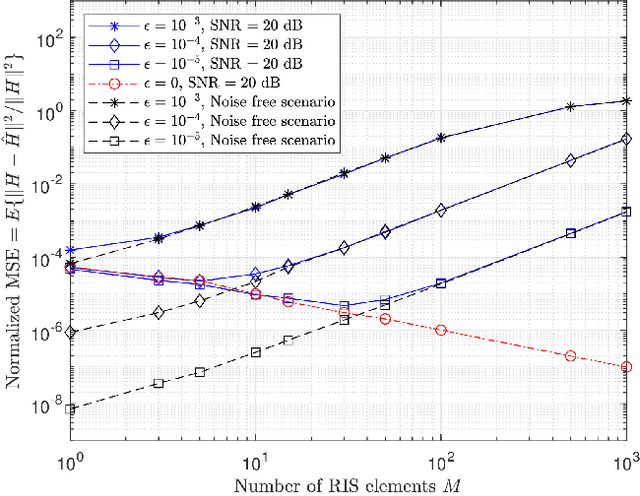
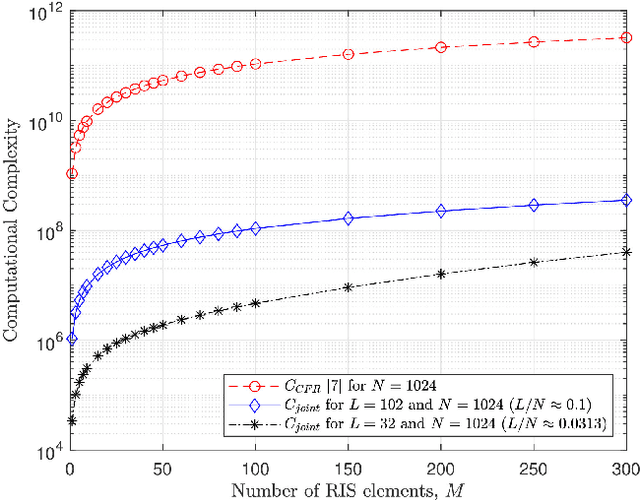
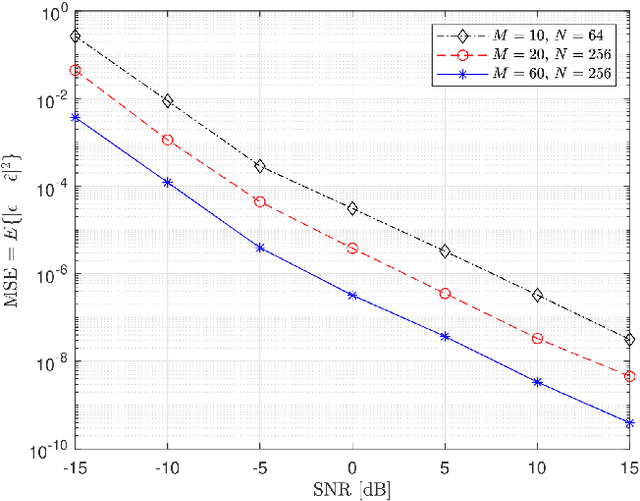
Accurate channel estimation is essential for achieving the performance gains offered by reconfigurable intelligent surface (RIS)-assisted wireless communications. Recently, a large number of channel estimation methods for RIS-assisted wireless communications have been proposed. However, none of the existing methods takes into account the influence of carrier frequency offset (CFO). In general, CFO can significantly degrade channel estimation for orthogonal frequency division multiplexing (OFDM) systems, since it breaks the orthogonality of subcarriers. Motivated by this, we investigate the effect of CFO on channel estimation for RIS-aided OFDM systems. Furthermore, we propose a joint CFO and channel impulse response (CIR) estimation method for RIS-aided OFDM systems. Simulation results demonstrate the effectiveness of our proposed joint CFO and CIR estimation method, and also demonstrate that the use of the time domain for estimation in this context results in a factor of 10 improvement in the mean-squared error (MSE) performance of channel estimation. Finally, the total computational complexity of the proposed method, including both CFO and channel estimation, is lower than the complexity of the conventional frequency-domain channel estimation method without CFO estimation.
Extended Vertical Lists for Temporal Pattern Mining from Multivariate Time Series
Apr 26, 2018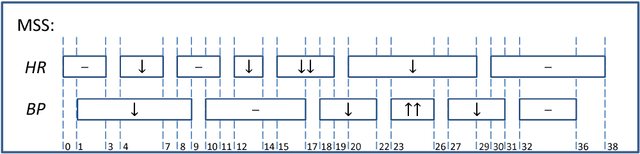
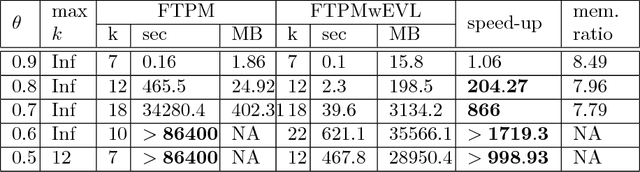
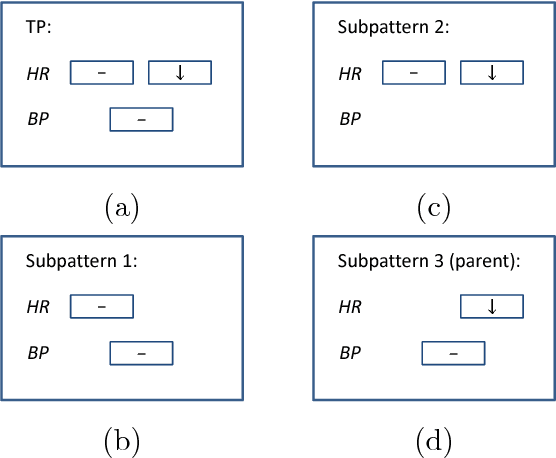
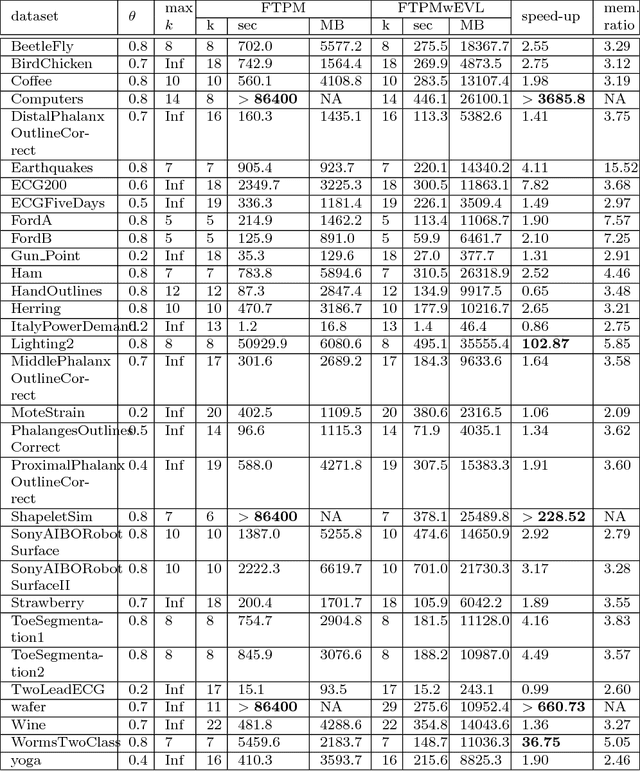
Temporal Pattern Mining (TPM) is the problem of mining predictive complex temporal patterns from multivariate time series in a supervised setting. We develop a new method called the Fast Temporal Pattern Mining with Extended Vertical Lists. This method utilizes an extension of the Apriori property which requires a more complex pattern to appear within records only at places where all of its subpatterns are detected as well. The approach is based on a novel data structure called the Extended Vertical List that tracks positions of the first state of the pattern inside records. Extensive computational results indicate that the new method performs significantly faster than the previous version of the algorithm for TMP. However, the speed-up comes at the expense of memory usage.