 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAKES: Scalable Vector Database for Embedding Search Service
May 18, 2025Modern deep learning models capture the semantics of complex data by transforming them into high-dimensional embedding vectors. Emerging applications, such as retrieval-augmented generation, use approximate nearest neighbor (ANN) search in the embedding vector space to find similar data. Existing vector databases provide indexes for efficient ANN searches, with graph-based indexes being the most popular due to their low latency and high recall in real-world high-dimensional datasets. However, these indexes are costly to build, suffer from significant contention under concurrent read-write workloads, and scale poorly to multiple servers. Our goal is to build a vector database that achieves high throughput and high recall under concurrent read-write workloads. To this end, we first propose an ANN index with an explicit two-stage design combining a fast filter stage with highly compressed vectors and a refine stage to ensure recall, and we devise a novel lightweight machine learning technique to fine-tune the index parameters. We introduce an early termination check to dynamically adapt the search process for each query. Next, we add support for writes while maintaining search performance by decoupling the management of the learned parameters. Finally, we design HAKES, a distributed vector database that serves the new index in a disaggregated architecture. We evaluate our index and system against 12 state-of-the-art indexes and three distributed vector databases, using high-dimensional embedding datasets generated by deep learning models. The experimental results show that our index outperforms index baselines in the high recall region and under concurrent read-write workloads. Furthermore, \namesys{} is scalable and achieves up to $16\times$ higher throughputs than the baselines. The HAKES project is open-sourced at https://www.comp.nus.edu.sg/~dbsystem/hakes/.
Serverless Model Serving for Data Science
Mar 04, 2021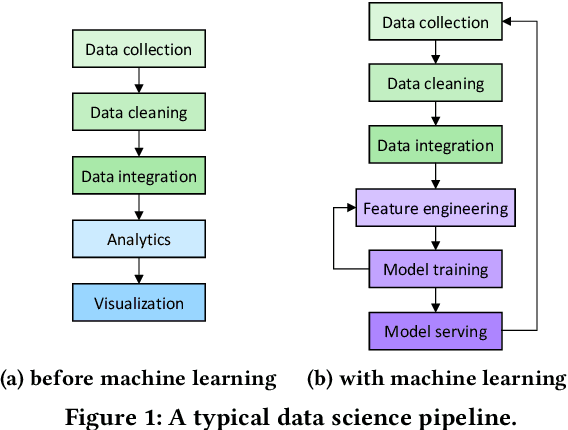
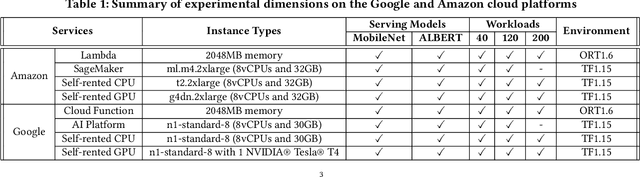
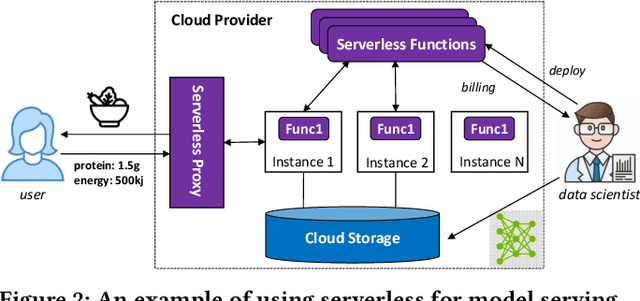
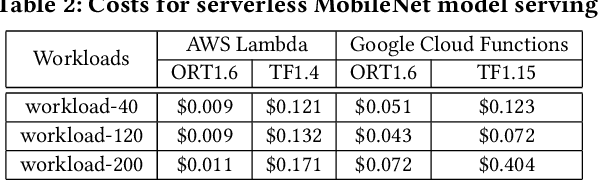
Machine learning (ML) is an important part of modern data science applications. Data scientists today have to manage the end-to-end ML life cycle that includes both model training and model serving, the latter of which is essential, as it makes their works available to end-users. Systems for model serving require high performance, low cost, and ease of management. Cloud providers are already offering model serving options, including managed services and self-rented servers. Recently, serverless computing, whose advantages include high elasticity and fine-grained cost model, brings another possibility for model serving. In this paper, we study the viability of serverless as a mainstream model serving platform for data science applications. We conduct a comprehensive evaluation of the performance and cost of serverless against other model serving systems on two clouds: Amazon Web Service (AWS) and Google Cloud Platform (GCP). We find that serverless outperforms many cloud-based alternatives with respect to cost and performance. More interestingly, under some circumstances, it can even outperform GPU-based systems for both average latency and cost. These results are different from previous works' claim that serverless is not suitable for model serving, and are contrary to the conventional wisdom that GPU-based systems are better for ML workloads than CPU-based systems. Other findings include a large gap in cold start time between AWS and GCP serverless functions, and serverless' low sensitivity to changes in workloads or models. Our evaluation results indicate that serverless is a viable option for model serving. Finally, we present several practical recommendations for data scientists on how to use serverless for scalable and cost-effective model serving.
Deep Learning At Scale and At Ease
Mar 25, 2016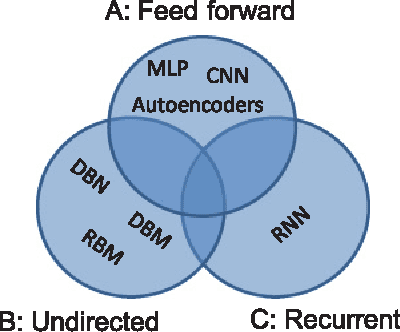
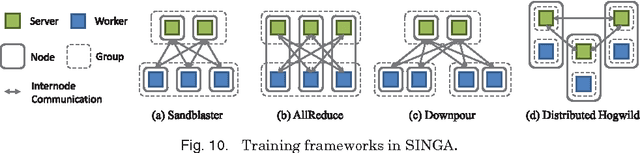
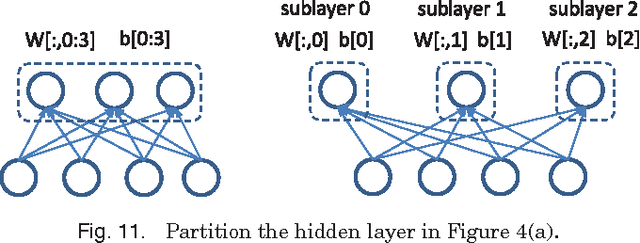
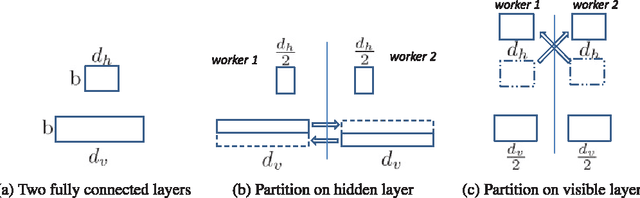
Recently, deep learning techniques have enjoyed success in various multimedia applications, such as image classification and multi-modal data analysis. Large deep learning models are developed for learning rich representations of complex data. There are two challenges to overcome before deep learning can be widely adopted in multimedia and other applications. One is usability, namely the implementation of different models and training algorithms must be done by non-experts without much effort especially when the model is large and complex. The other is scalability, that is the deep learning system must be able to provision for a huge demand of computing resources for training large models with massive datasets. To address these two challenges, in this paper, we design a distributed deep learning platform called SINGA which has an intuitive programming model based on the common layer abstraction of deep learning models. Good scalability is achieved through flexible distributed training architecture and specific optimization techniques. SINGA runs on GPUs as well as on CPUs, and we show that it outperforms many other state-of-the-art deep learning systems. Our experience with developing and training deep learning models for real-life multimedia applications in SINGA shows that the platform is both usable and scalable.