 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Text Line Segmentation for Challenging Handwritten Document Images Using Fully Convolutional Network
Jan 20, 2021



This paper presents a method for text line segmentation of challenging historical manuscript images. These manuscript images contain narrow interline spaces with touching components, interpenetrating vowel signs and inconsistent font types and sizes. In addition, they contain curved, multi-skewed and multi-directed side note lines within a complex page layout. Therefore, bounding polygon labeling would be very difficult and time consuming. Instead we rely on line masks that connect the components on the same text line. Then these line masks are predicted using a Fully Convolutional Network (FCN). In the literature, FCN has been successfully used for text line segmentation of regular handwritten document images. The present paper shows that FCN is useful with challenging manuscript images as well. Using a new evaluation metric that is sensitive to over segmentation as well as under segmentation, testing results on a publicly available challenging handwritten dataset are comparable with the results of a previous work on the same dataset.
Realtime CNN-based Keypoint Detector with Sobel Filter and CNN-based Descriptor Trained with Keypoint Candidates
Nov 04, 2020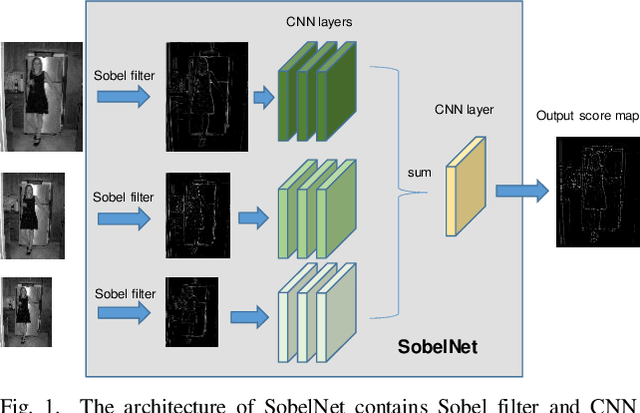
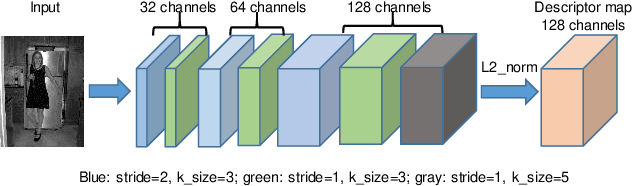
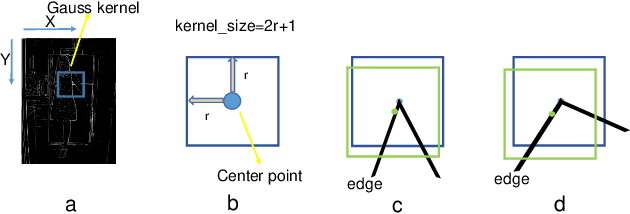
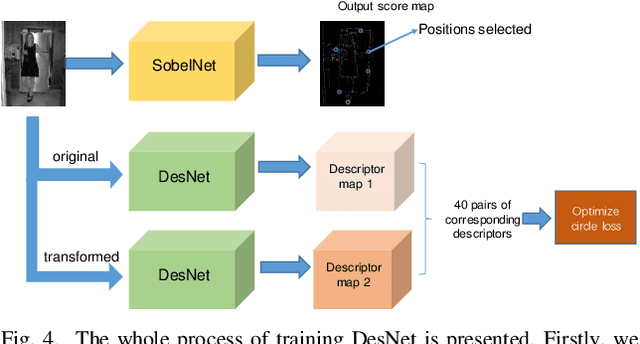
The local feature detector and descriptor are essential in many computer vision tasks, such as SLAM and 3D reconstruction. In this paper, we introduce two separate CNNs, lightweight SobelNet and DesNet, to detect key points and to compute dense local descriptors. The detector and the descriptor work in parallel. Sobel filter provides the edge structure of the input images as the input of CNN. The locations of key points will be obtained after exerting the non-maximum suppression (NMS) process on the output map of the CNN. We design Gaussian loss for the training process of SobelNet to detect corner points as keypoints. At the same time, the input of DesNet is the original grayscale image, and circle loss is used to train DesNet. Besides, output maps of SobelNet are needed while training DesNet. We have evaluated our method on several benchmarks including HPatches benchmark, ETH benchmark, and FM-Bench. SobelNet achieves better or comparable performance with less computation compared with SOTA methods in recent years. The inference time of an image of 640x480 is 7.59ms and 1.09ms for SobelNet and DesNet respectively on RTX 2070 SUPER.
Improving Visual Place Recognition Performance by Maximising Complementarity
Feb 16, 2021
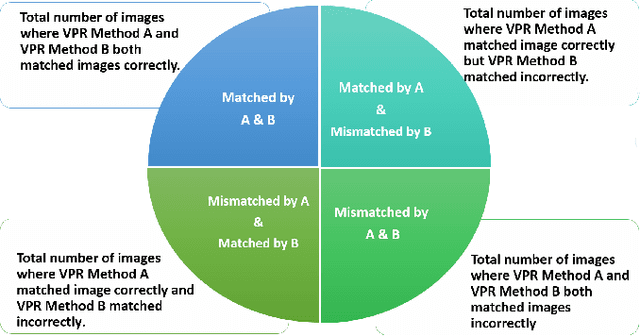
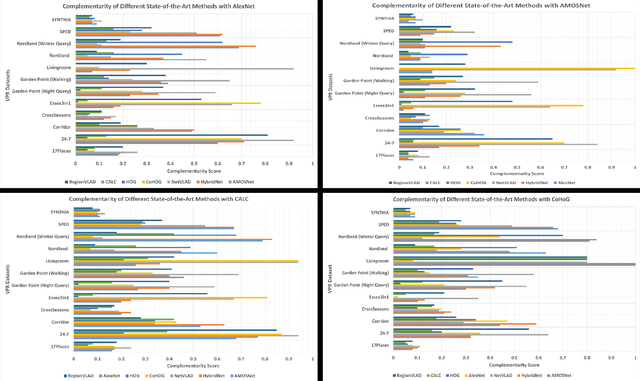
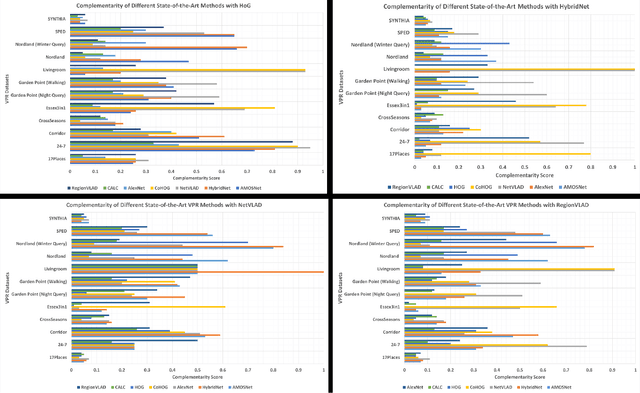
Visual place recognition (VPR) is the problem of recognising a previously visited location using visual information. Many attempts to improve the performance of VPR methods have been made in the literature. One approach that has received attention recently is the multi-process fusion where different VPR methods run in parallel and their outputs are combined in an effort to achieve better performance. The multi-process fusion, however, does not have a well-defined criterion for selecting and combining different VPR methods from a wide range of available options. To the best of our knowledge, this paper investigates the complementarity of state-of-the-art VPR methods systematically for the first time and identifies those combinations which can result in better performance. The paper presents a well-defined framework which acts as a sanity check to find the complementarity between two techniques by utilising a McNemar's test-like approach. The framework allows estimation of upper and lower complementarity bounds for the VPR techniques to be combined, along with an estimate of maximum VPR performance that may be achieved. Based on this framework, results are presented for eight state-of-the-art VPR methods on ten widely-used VPR datasets showing the potential of different combinations of techniques for achieving better performance.
Fast and Scalable Earth Texture Synthesis using Spatially Assembled Generative Adversarial Neural Networks
Nov 13, 2020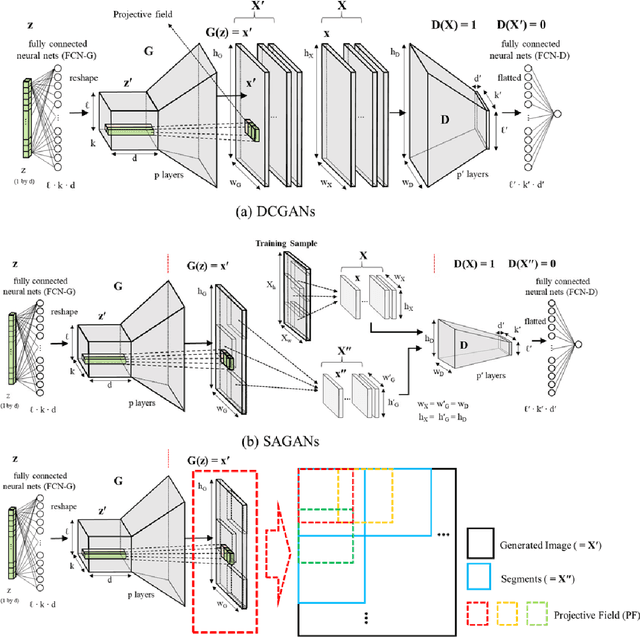
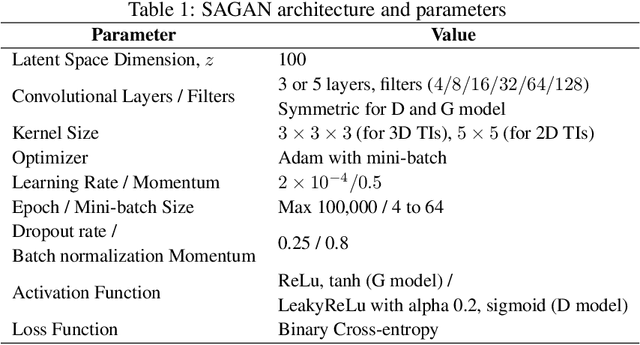

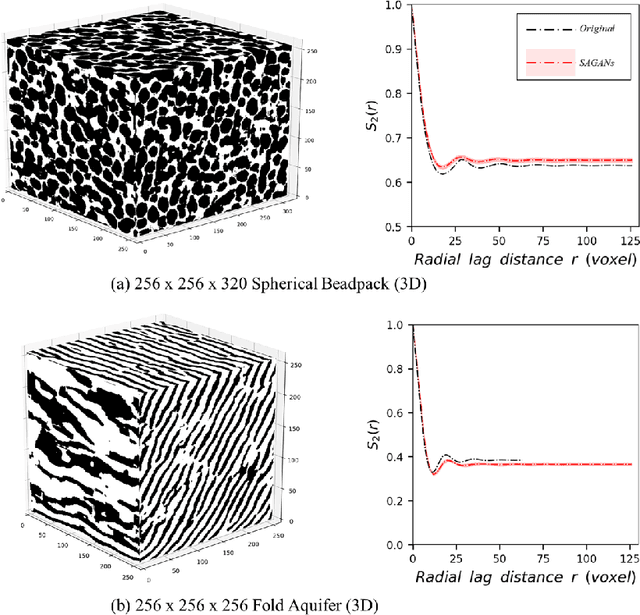
The earth texture with complex morphological geometry and compositions such as shale and carbonate rocks, is typically characterized with sparse field samples because of an expensive and time-consuming characterization process. Accordingly, generating arbitrary large size of the geological texture with similar topological structures at a low computation cost has become one of the key tasks for realistic geomaterial reconstruction. Recently, generative adversarial neural networks (GANs) have demonstrated a potential of synthesizing input textural images and creating equiprobable geomaterial images. However, the texture synthesis with the GANs framework is often limited by the computational cost and scalability of the output texture size. In this study, we proposed a spatially assembled GANs (SAGANs) that can generate output images of an arbitrary large size regardless of the size of training images with computational efficiency. The performance of the SAGANs was evaluated with two and three dimensional (2D and 3D) rock image samples widely used in geostatistical reconstruction of the earth texture. We demonstrate SAGANs can generate the arbitrary large size of statistical realizations with connectivity and structural properties similar to training images, and also can generate a variety of realizations even on a single training image. In addition, the computational time was significantly improved compared to standard GANs frameworks.
Lossless Compression of Efficient Private Local Randomizers
Feb 24, 2021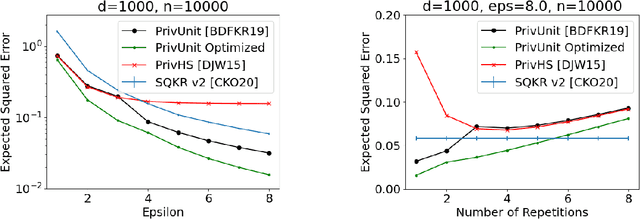
Locally Differentially Private (LDP) Reports are commonly used for collection of statistics and machine learning in the federated setting. In many cases the best known LDP algorithms require sending prohibitively large messages from the client device to the server (such as when constructing histograms over large domain or learning a high-dimensional model). This has led to significant efforts on reducing the communication cost of LDP algorithms. At the same time LDP reports are known to have relatively little information about the user's data due to randomization. Several schemes are known that exploit this fact to design low-communication versions of LDP algorithm but all of them do so at the expense of a significant loss in utility. Here we demonstrate a general approach that, under standard cryptographic assumptions, compresses every efficient LDP algorithm with negligible loss in privacy and utility guarantees. The practical implication of our result is that in typical applications the message can be compressed to the size of the server's pseudo-random generator seed. More generally, we relate the properties of an LDP randomizer to the power of a pseudo-random generator that suffices for compressing the LDP randomizer. From this general approach we derive low-communication algorithms for the problems of frequency estimation and high-dimensional mean estimation. Our algorithms are simpler and more accurate than existing low-communication LDP algorithms for these well-studied problems.
mt5b3: A Framework for Building AutonomousTraders
Jan 20, 2021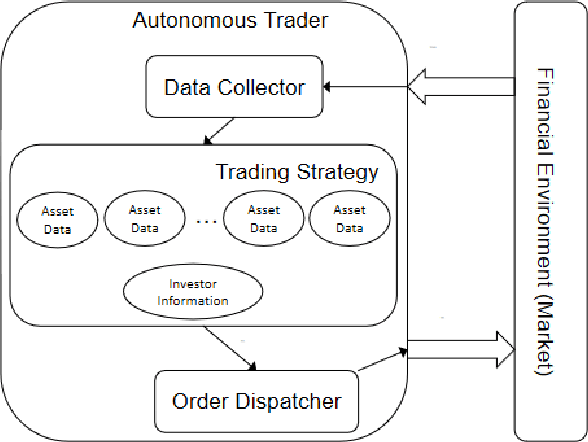
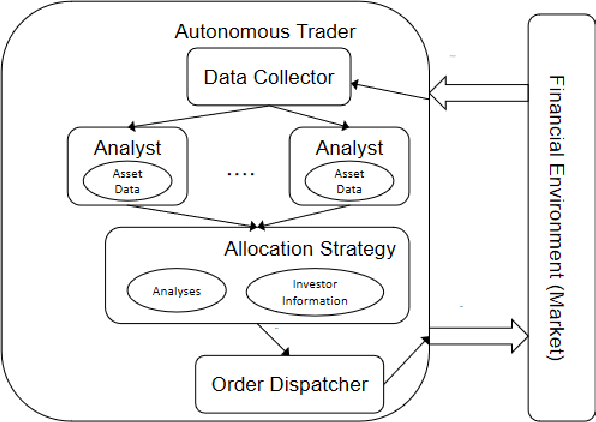
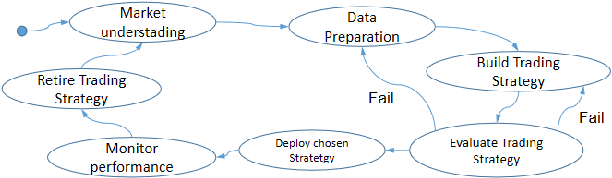
Autonomous trading robots have been studied in ar-tificial intelligence area for quite some time. Many AI techniqueshave been tested in finance field including recent approaches likeconvolutional neural networks and deep reinforcement learning.There are many reported cases, where the developers are suc-cessful in creating robots with great performance when executingwith historical price series, so called backtesting. However, whenthese robots are used in real markets or data not used intheir training or evaluation frequently they present very poorperformance in terms of risks and return. In this paper, wediscussed some fundamental aspects of modelling autonomoustraders and the complex environment that is the financialworld. Furthermore, we presented a framework that helps thedevelopment and testing of autonomous traders. It may also beused in real or simulated operation in financial markets. Finally,we discussed some open problems in the area and pointed outsome interesting technologies that may contribute to advancein such task. We believe that mt5b3 may also contribute todevelopment of new autonomous traders.
STAN: Spatio-Temporal Attention Network for Next Location Recommendation
Feb 08, 2021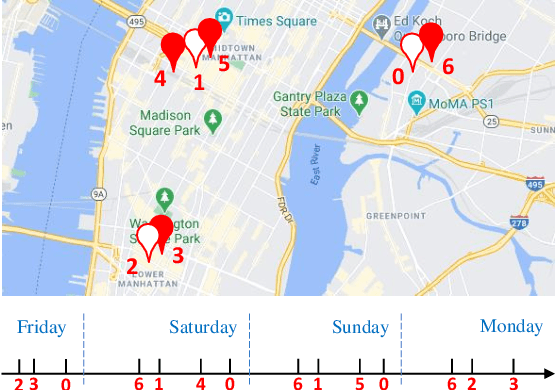
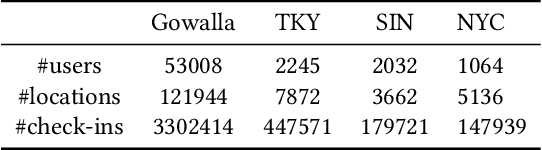
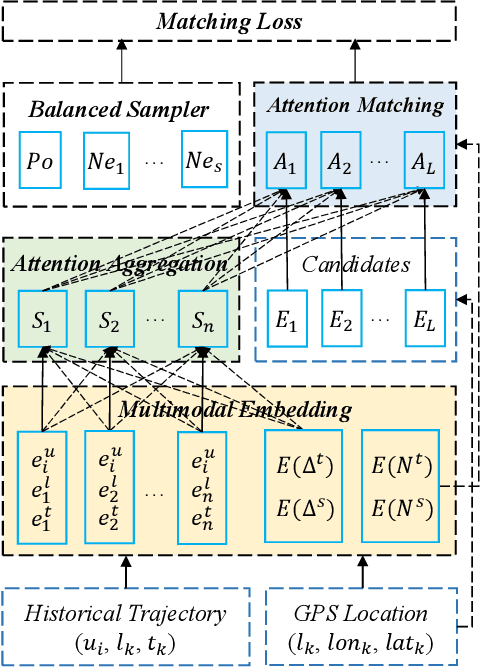
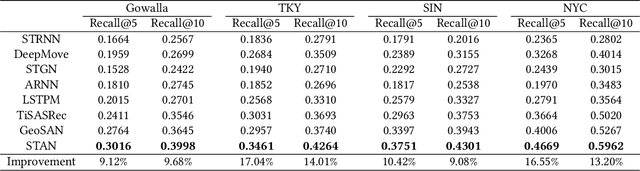
The next location recommendation is at the core of various location-based applications. Current state-of-the-art models have attempted to solve spatial sparsity with hierarchical gridding and model temporal relation with explicit time intervals, while some vital questions remain unsolved. Non-adjacent locations and non-consecutive visits provide non-trivial correlations for understanding a user's behavior but were rarely considered. To aggregate all relevant visits from user trajectory and recall the most plausible candidates from weighted representations, here we propose a Spatio-Temporal Attention Network (STAN) for location recommendation. STAN explicitly exploits relative spatiotemporal information of all the check-ins with self-attention layers along the trajectory. This improvement allows a point-to-point interaction between non-adjacent locations and non-consecutive check-ins with explicit spatiotemporal effect. STAN uses a bi-layer attention architecture that firstly aggregates spatiotemporal correlation within user trajectory and then recalls the target with consideration of personalized item frequency (PIF). By visualization, we show that STAN is in line with the above intuition. Experimental results unequivocally show that our model outperforms the existing state-of-the-art methods by 9-17%.
Robust Black-box Watermarking for Deep NeuralNetwork using Inverse Document Frequency
Mar 09, 2021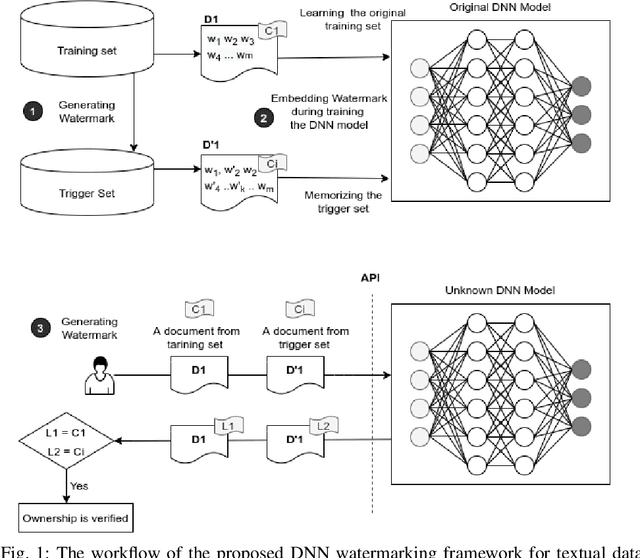
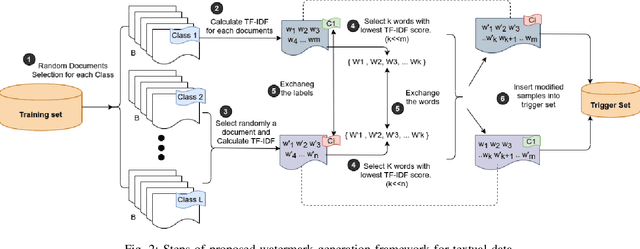

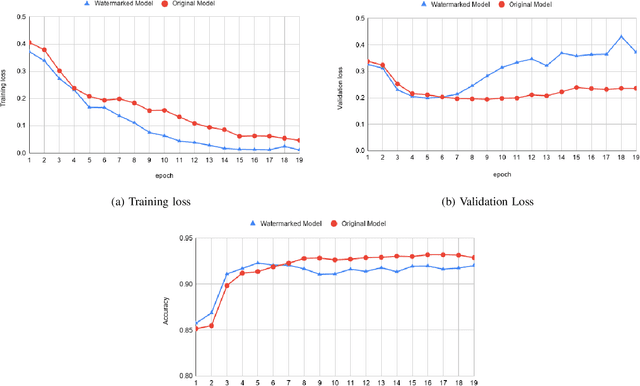
Deep learning techniques are one of the most significant elements of any Artificial Intelligence (AI) services. Recently, these Machine Learning (ML) methods, such as Deep Neural Networks (DNNs), presented exceptional achievement in implementing human-level capabilities for various predicaments, such as Natural Processing Language (NLP), voice recognition, and image processing, etc. Training these models are expensive in terms of computational power and the existence of enough labelled data. Thus, ML-based models such as DNNs establish genuine business value and intellectual property (IP) for their owners. Therefore the trained models need to be protected from any adversary attacks such as illegal redistribution, reproducing, and derivation. Watermarking can be considered as an effective technique for securing a DNN model. However, so far, most of the watermarking algorithm focuses on watermarking the DNN by adding noise to an image. To this end, we propose a framework for watermarking a DNN model designed for a textual domain. The watermark generation scheme provides a secure watermarking method by combining Term Frequency (TF) and Inverse Document Frequency (IDF) of a particular word. The proposed embedding procedure takes place in the model's training time, making the watermark verification stage straightforward by sending the watermarked document to the trained model. The experimental results show that watermarked models have the same accuracy as the original ones. The proposed framework accurately verifies the ownership of all surrogate models without impairing the performance. The proposed algorithm is robust against well-known attacks such as parameter pruning and brute force attack.
Active Learning for Sequence Tagging with Deep Pre-trained Models and Bayesian Uncertainty Estimates
Jan 20, 2021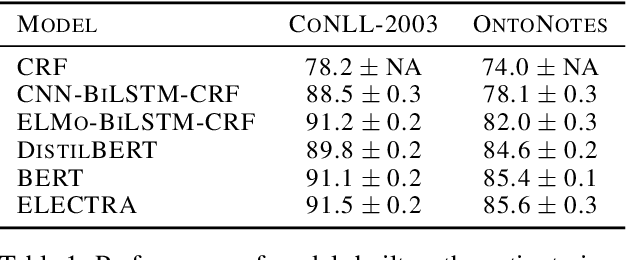
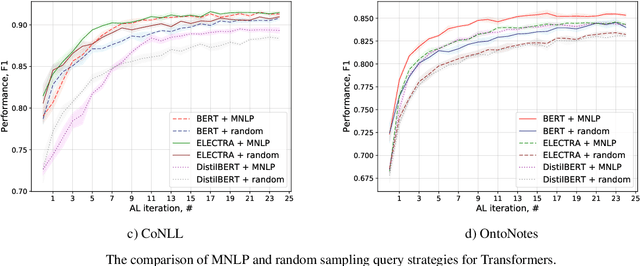
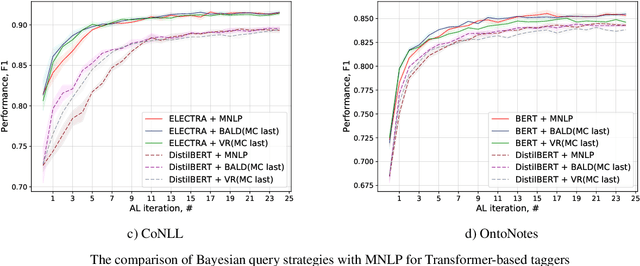
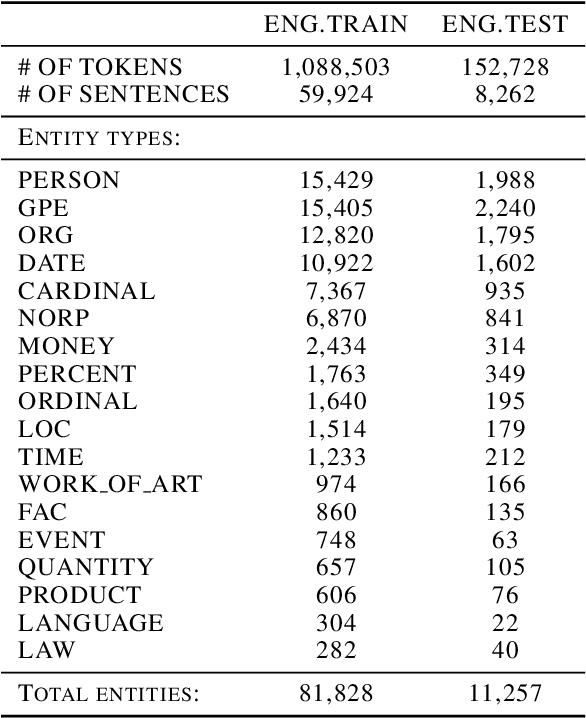
Annotating training data for sequence tagging tasks is usually very time-consuming. Recent advances in transfer learning for natural language processing in conjunction with active learning open the possibility to significantly reduce the necessary annotation budget. We are the first to thoroughly investigate this powerful combination in sequence tagging. We find that taggers based on deep pre-trained models can benefit from Bayesian query strategies with the help of the Monte Carlo (MC) dropout. Results of experiments with various uncertainty estimates and MC dropout variants show that the Bayesian active learning by disagreement query strategy coupled with the MC dropout applied only in the classification layer of a Transformer-based tagger is the best option in terms of quality. This option also has very little computational overhead. We also demonstrate that it is possible to reduce the computational overhead of AL by using a smaller distilled version of a Transformer model for acquiring instances during AL.
Mobile Cellular-Connected UAVs: Reinforcement Learning for Sky Limits
Sep 21, 2020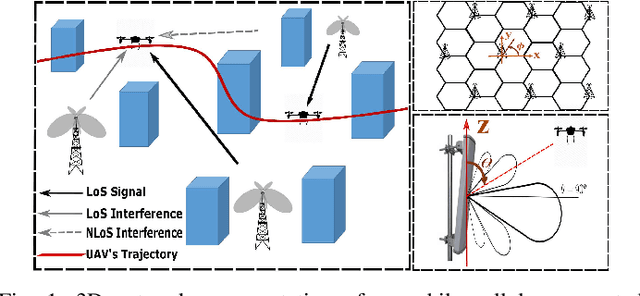
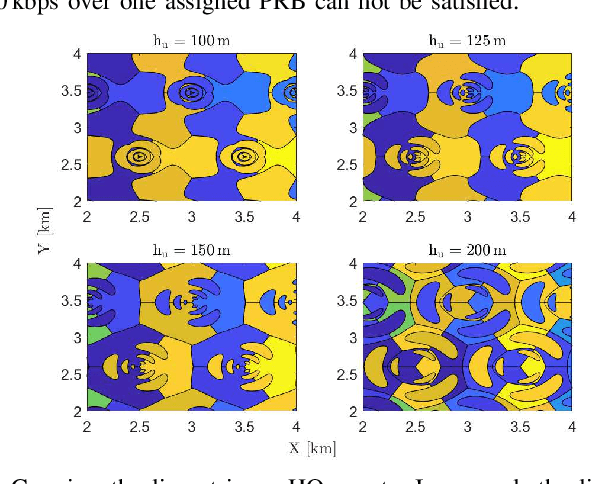
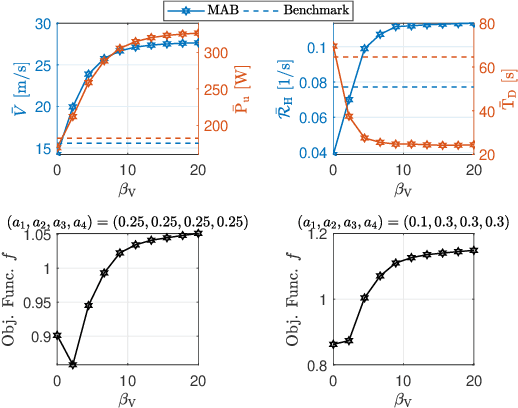
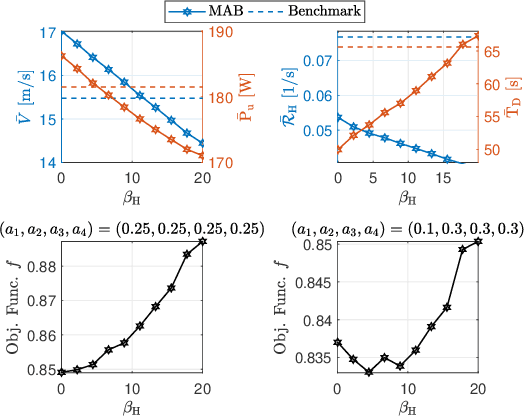
A cellular-connected unmanned aerial vehicle (UAV)faces several key challenges concerning connectivity and energy efficiency. Through a learning-based strategy, we propose a general novel multi-armed bandit (MAB) algorithm to reduce disconnectivity time, handover rate, and energy consumption of UAV by taking into account its time of task completion. By formulating the problem as a function of UAV's velocity, we show how each of these performance indicators (PIs) is improved by adopting a proper range of corresponding learning parameter, e.g. 50% reduction in HO rate as compared to a blind strategy. However, results reveal that the optimal combination of the learning parameters depends critically on any specific application and the weights of PIs on the final objective function.