 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecurity Threat Modeling for Emerging AI-Agent Protocols: A Comparative Analysis of MCP, A2A, Agora, and ANP
Feb 11, 2026The rapid development of the AI agent communication protocols, including the Model Context Protocol (MCP), Agent2Agent (A2A), Agora, and Agent Network Protocol (ANP), is reshaping how AI agents communicate with tools, services, and each other. While these protocols support scalable multi-agent interaction and cross-organizational interoperability, their security principles remain understudied, and standardized threat modeling is limited; no protocol-centric risk assessment framework has been established yet. This paper presents a systematic security analysis of four emerging AI agent communication protocols. First, we develop a structured threat modeling analysis that examines protocol architectures, trust assumptions, interaction patterns, and lifecycle behaviors to identify protocol-specific and cross-protocol risk surfaces. Second, we introduce a qualitative risk assessment framework that identifies twelve protocol-level risks and evaluates security posture across the creation, operation, and update phases through systematic assessment of likelihood, impact, and overall protocol risk, with implications for secure deployment and future standardization. Third, we provide a measurement-driven case study on MCP that formalizes the risk of missing mandatory validation/attestation for executable components as a falsifiable security claim by quantifying wrong-provider tool execution under multi-server composition across representative resolver policies. Collectively, our results highlight key design-induced risk surfaces and provide actionable guidance for secure deployment and future standardization of agent communication ecosystems.
CIC-Trap4Phish: A Unified Multi-Format Dataset for Phishing and Quishing Attachment Detection
Feb 09, 2026Phishing attacks represents one of the primary attack methods which is used by cyber attackers. In many cases, attackers use deceptive emails along with malicious attachments to trick users into giving away sensitive information or installing malware while compromising entire systems. The flexibility of malicious email attachments makes them stand out as a preferred vector for attackers as they can embed harmful content such as malware or malicious URLs inside standard document formats. Although phishing email defenses have improved a lot, attackers continue to abuse attachments, enabling malicious content to bypass security measures. Moreover, another challenge that researches face in training advance models, is lack of an unified and comprehensive dataset that covers the most prevalent data types. To address this gap, we generated CIC-Trap4Phish, a multi-format dataset containing both malicious and benign samples across five categories commonly used in phishing campaigns: Microsoft Word documents, Excel spreadsheets, PDF files, HTML pages, and QR code images. For the first four file types, a set of execution-free static feature pipeline was proposed, designed to capture structural, lexical, and metadata-based indicators without the need to open or execute files. Feature selection was performed using a combination of SHAP analysis and feature importance, yielding compact, discriminative feature subsets for each file type. The selected features were evaluated by using lightweight machine learning models, including Random Forest, XGBoost, and Decision Tree. All models demonstrate high detection accuracy across formats. For QR code-based phishing (quishing), two complementary methods were implemented: image-based detection by employing Convolutional Neural Networks (CNNs) and lexical analysis of decoded URLs using recent lightweight language models.
Robust Black-box Watermarking for Deep NeuralNetwork using Inverse Document Frequency
Mar 09, 2021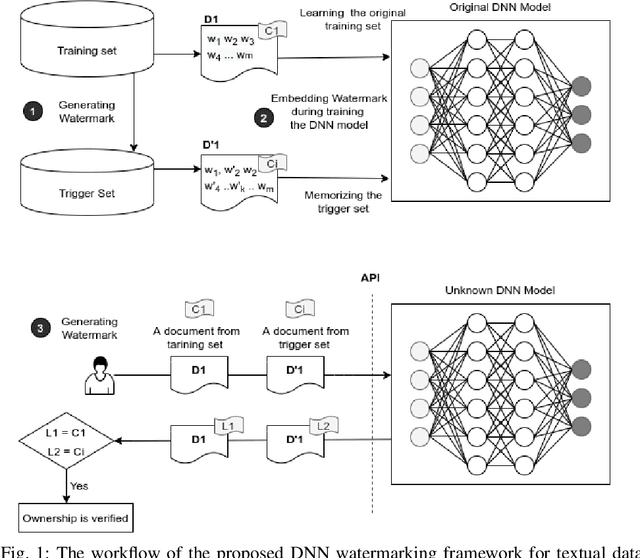
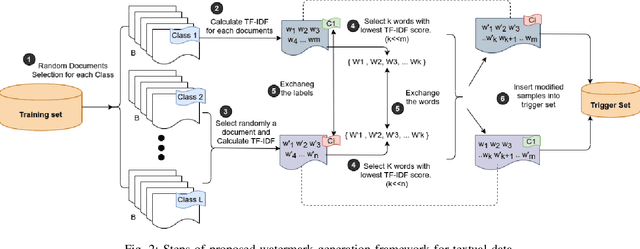

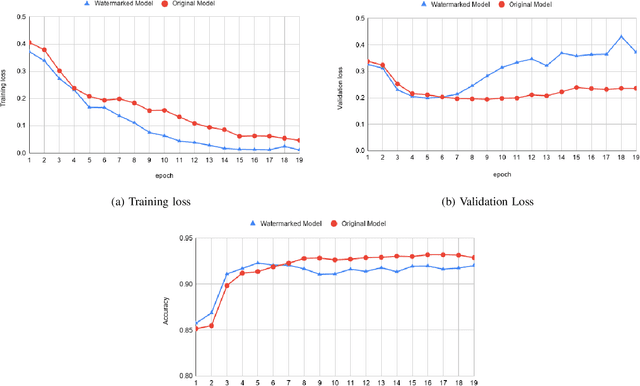
Deep learning techniques are one of the most significant elements of any Artificial Intelligence (AI) services. Recently, these Machine Learning (ML) methods, such as Deep Neural Networks (DNNs), presented exceptional achievement in implementing human-level capabilities for various predicaments, such as Natural Processing Language (NLP), voice recognition, and image processing, etc. Training these models are expensive in terms of computational power and the existence of enough labelled data. Thus, ML-based models such as DNNs establish genuine business value and intellectual property (IP) for their owners. Therefore the trained models need to be protected from any adversary attacks such as illegal redistribution, reproducing, and derivation. Watermarking can be considered as an effective technique for securing a DNN model. However, so far, most of the watermarking algorithm focuses on watermarking the DNN by adding noise to an image. To this end, we propose a framework for watermarking a DNN model designed for a textual domain. The watermark generation scheme provides a secure watermarking method by combining Term Frequency (TF) and Inverse Document Frequency (IDF) of a particular word. The proposed embedding procedure takes place in the model's training time, making the watermark verification stage straightforward by sending the watermarked document to the trained model. The experimental results show that watermarked models have the same accuracy as the original ones. The proposed framework accurately verifies the ownership of all surrogate models without impairing the performance. The proposed algorithm is robust against well-known attacks such as parameter pruning and brute force attack.