 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM4CodeRE: Generative AI for Code Decompilation Analysis and Reverse Engineering
Apr 07, 2026Code decompilation analysis is a fundamental yet challenging task in malware reverse engineering, particularly due to the pervasive use of sophisticated obfuscation techniques. Although recent large language models (LLMs) have shown promise in translating low-level representations into high-level source code, most existing approaches rely on generic code pretraining and lack adaptation to malicious software. We propose LLM4CodeRE, a domain-adaptive LLM framework for bidirectional code reverse engineering that supports both assembly-to-source decompilation and source-to-assembly translation within a unified model. To enable effective task adaptation, we introduce two complementary fine-tuning strategies: (i) a Multi-Adapter approach for task-specific syntactic and semantic alignment, and (ii) a Seq2Seq Unified approach using task-conditioned prefixes to enforce end-to-end generation constraints. Experimental results demonstrate that LLM4CodeRE outperforms existing decompilation tools and general-purpose code models, achieving robust bidirectional generalization.
Automated Malware Family Classification using Weighted Hierarchical Ensembles of Large Language Models
Apr 02, 2026Malware family classification remains a challenging task in automated malware analysis, particularly in real-world settings characterized by obfuscation, packing, and rapidly evolving threats. Existing machine learning and deep learning approaches typically depend on labeled datasets, handcrafted features, supervised training, or dynamic analysis, which limits their scalability and effectiveness in open-world scenarios. This paper presents a zero-label malware family classification framework based on a weighted hierarchical ensemble of pretrained large language models (LLMs). Rather than relying on feature-level learning or model retraining, the proposed approach aggregates decision-level predictions from multiple LLMs with complementary reasoning strengths. Model outputs are weighted using empirically derived macro-F1 scores and organized hierarchically, first resolving coarse-grained malicious behavior before assigning fine-grained malware families. This structure enhances robustness, reduces individual model instability, and aligns with analyst-style reasoning.
CIC-Trap4Phish: A Unified Multi-Format Dataset for Phishing and Quishing Attachment Detection
Feb 09, 2026Phishing attacks represents one of the primary attack methods which is used by cyber attackers. In many cases, attackers use deceptive emails along with malicious attachments to trick users into giving away sensitive information or installing malware while compromising entire systems. The flexibility of malicious email attachments makes them stand out as a preferred vector for attackers as they can embed harmful content such as malware or malicious URLs inside standard document formats. Although phishing email defenses have improved a lot, attackers continue to abuse attachments, enabling malicious content to bypass security measures. Moreover, another challenge that researches face in training advance models, is lack of an unified and comprehensive dataset that covers the most prevalent data types. To address this gap, we generated CIC-Trap4Phish, a multi-format dataset containing both malicious and benign samples across five categories commonly used in phishing campaigns: Microsoft Word documents, Excel spreadsheets, PDF files, HTML pages, and QR code images. For the first four file types, a set of execution-free static feature pipeline was proposed, designed to capture structural, lexical, and metadata-based indicators without the need to open or execute files. Feature selection was performed using a combination of SHAP analysis and feature importance, yielding compact, discriminative feature subsets for each file type. The selected features were evaluated by using lightweight machine learning models, including Random Forest, XGBoost, and Decision Tree. All models demonstrate high detection accuracy across formats. For QR code-based phishing (quishing), two complementary methods were implemented: image-based detection by employing Convolutional Neural Networks (CNNs) and lexical analysis of decoded URLs using recent lightweight language models.
FlexiDataGen: An Adaptive LLM Framework for Dynamic Semantic Dataset Generation in Sensitive Domains
Oct 21, 2025Dataset availability and quality remain critical challenges in machine learning, especially in domains where data are scarce, expensive to acquire, or constrained by privacy regulations. Fields such as healthcare, biomedical research, and cybersecurity frequently encounter high data acquisition costs, limited access to annotated data, and the rarity or sensitivity of key events. These issues-collectively referred to as the dataset challenge-hinder the development of accurate and generalizable machine learning models in such high-stakes domains. To address this, we introduce FlexiDataGen, an adaptive large language model (LLM) framework designed for dynamic semantic dataset generation in sensitive domains. FlexiDataGen autonomously synthesizes rich, semantically coherent, and linguistically diverse datasets tailored to specialized fields. The framework integrates four core components: (1) syntactic-semantic analysis, (2) retrieval-augmented generation, (3) dynamic element injection, and (4) iterative paraphrasing with semantic validation. Together, these components ensure the generation of high-quality, domain-relevant data. Experimental results show that FlexiDataGen effectively alleviates data shortages and annotation bottlenecks, enabling scalable and accurate machine learning model development.
SBAN: A Framework \& Multi-Dimensional Dataset for Large Language Model Pre-Training and Software Code Mining
Oct 21, 2025This paper introduces SBAN (Source code, Binary, Assembly, and Natural Language Description), a large-scale, multi-dimensional dataset designed to advance the pre-training and evaluation of large language models (LLMs) for software code analysis. SBAN comprises more than 3 million samples, including 2.9 million benign and 672,000 malware respectively, each represented across four complementary layers: binary code, assembly instructions, natural language descriptions, and source code. This unique multimodal structure enables research on cross-representation learning, semantic understanding of software, and automated malware detection. Beyond security applications, SBAN supports broader tasks such as code translation, code explanation, and other software mining tasks involving heterogeneous data. It is particularly suited for scalable training of deep models, including transformers and other LLM architectures. By bridging low-level machine representations and high-level human semantics, SBAN provides a robust foundation for building intelligent systems that reason about code. We believe that this dataset opens new opportunities for mining software behavior, improving security analytics, and enhancing LLM capabilities in pre-training and fine-tuning tasks for software code mining.
XGen-Q: An Explainable Domain-Adaptive LLM Framework with Retrieval-Augmented Generation for Software Security
Oct 21, 2025Generative AI and large language models (LLMs) have shown strong capabilities in code understanding, but their use in cybersecurity, particularly for malware detection and analysis, remains limited. Existing detection systems often fail to generalize to obfuscated or previously unseen threats, underscoring the need for more adaptable and explainable models. To address this challenge, we introduce XGen-Q, a domain-adapted LLM built on the Qwen-Coder architecture and pretrained on a large-scale corpus of over one million malware samples, spanning both source and assembly code. XGen-Q uses a multi-stage prompt strategy combined with retrieval-augmented generation (RAG) to deliver reliable malware identification and detailed forensic reporting, even in the presence of complex code obfuscation. To further enhance generalization, we design a training pipeline that systematically exposes the model to diverse obfuscation patterns. Experimental results show that XGen-Q achieves significantly lower perplexity than competitive baselines and exhibits strong performance on novel malware samples, demonstrating the promise of LLM-based approaches for interpretable and robust malware analysis.
Dual Explanations via Subgraph Matching for Malware Detection
Apr 29, 2025



Interpretable malware detection is crucial for understanding harmful behaviors and building trust in automated security systems. Traditional explainable methods for Graph Neural Networks (GNNs) often highlight important regions within a graph but fail to associate them with known benign or malicious behavioral patterns. This limitation reduces their utility in security contexts, where alignment with verified prototypes is essential. In this work, we introduce a novel dual prototype-driven explainable framework that interprets GNN-based malware detection decisions. This dual explainable framework integrates a base explainer (a state-of-the-art explainer) with a novel second-level explainer which is designed by subgraph matching technique, called SubMatch explainer. The proposed explainer assigns interpretable scores to nodes based on their association with matched subgraphs, offering a fine-grained distinction between benign and malicious regions. This prototype-guided scoring mechanism enables more interpretable, behavior-aligned explanations. Experimental results demonstrate that our method preserves high detection performance while significantly improving interpretability in malware analysis.
On the Consistency of GNN Explanations for Malware Detection
Apr 22, 2025Control Flow Graphs (CFGs) are critical for analyzing program execution and characterizing malware behavior. With the growing adoption of Graph Neural Networks (GNNs), CFG-based representations have proven highly effective for malware detection. This study proposes a novel framework that dynamically constructs CFGs and embeds node features using a hybrid approach combining rule-based encoding and autoencoder-based embedding. A GNN-based classifier is then constructed to detect malicious behavior from the resulting graph representations. To improve model interpretability, we apply state-of-the-art explainability techniques, including GNNExplainer, PGExplainer, and CaptumExplainer, the latter is utilized three attribution methods: Integrated Gradients, Guided Backpropagation, and Saliency. In addition, we introduce a novel aggregation method, called RankFusion, that integrates the outputs of the top-performing explainers to enhance the explanation quality. We also evaluate explanations using two subgraph extraction strategies, including the proposed Greedy Edge-wise Composition (GEC) method for improved structural coherence. A comprehensive evaluation using accuracy, fidelity, and consistency metrics demonstrates the effectiveness of the proposed framework in terms of accurate identification of malware samples and generating reliable and interpretable explanations.
Explainable Malware Detection through Integrated Graph Reduction and Learning Techniques
Dec 04, 2024



Control Flow Graphs and Function Call Graphs have become pivotal in providing a detailed understanding of program execution and effectively characterizing the behavior of malware. These graph-based representations, when combined with Graph Neural Networks (GNN), have shown promise in developing high-performance malware detectors. However, challenges remain due to the large size of these graphs and the inherent opacity in the decision-making process of GNNs. This paper addresses these issues by developing several graph reduction techniques to reduce graph size and applying the state-of-the-art GNNExplainer to enhance the interpretability of GNN outputs. The analysis demonstrates that integrating our proposed graph reduction technique along with GNNExplainer in the malware detection framework significantly reduces graph size while preserving high performance, providing an effective balance between efficiency and transparency in malware detection.
Robust Black-box Watermarking for Deep NeuralNetwork using Inverse Document Frequency
Mar 09, 2021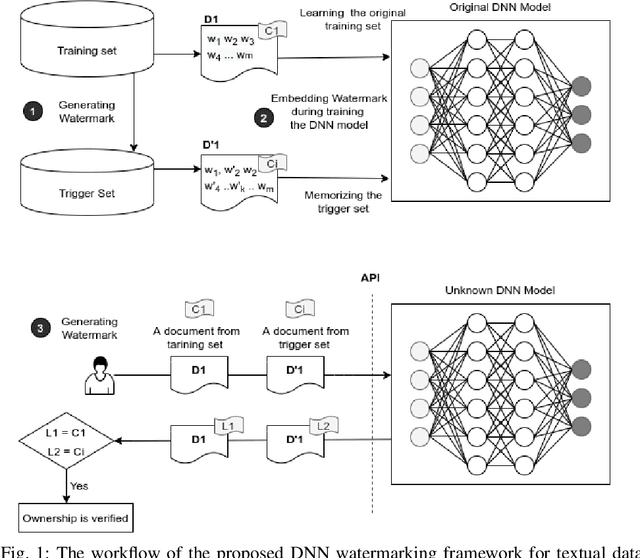
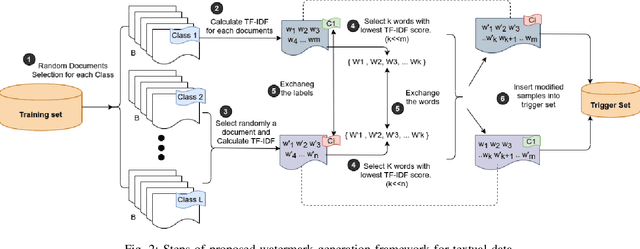

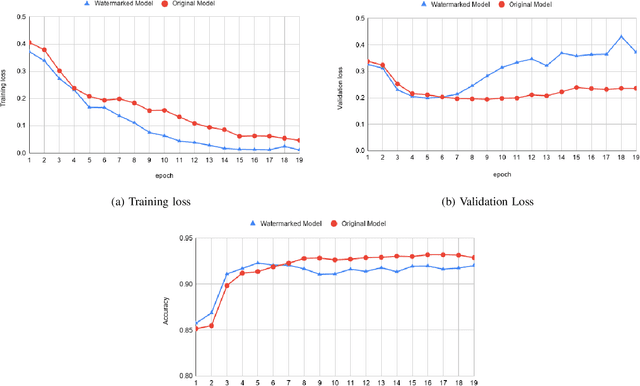
Deep learning techniques are one of the most significant elements of any Artificial Intelligence (AI) services. Recently, these Machine Learning (ML) methods, such as Deep Neural Networks (DNNs), presented exceptional achievement in implementing human-level capabilities for various predicaments, such as Natural Processing Language (NLP), voice recognition, and image processing, etc. Training these models are expensive in terms of computational power and the existence of enough labelled data. Thus, ML-based models such as DNNs establish genuine business value and intellectual property (IP) for their owners. Therefore the trained models need to be protected from any adversary attacks such as illegal redistribution, reproducing, and derivation. Watermarking can be considered as an effective technique for securing a DNN model. However, so far, most of the watermarking algorithm focuses on watermarking the DNN by adding noise to an image. To this end, we propose a framework for watermarking a DNN model designed for a textual domain. The watermark generation scheme provides a secure watermarking method by combining Term Frequency (TF) and Inverse Document Frequency (IDF) of a particular word. The proposed embedding procedure takes place in the model's training time, making the watermark verification stage straightforward by sending the watermarked document to the trained model. The experimental results show that watermarked models have the same accuracy as the original ones. The proposed framework accurately verifies the ownership of all surrogate models without impairing the performance. The proposed algorithm is robust against well-known attacks such as parameter pruning and brute force attack.