 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePositive Alignment: Artificial Intelligence for Human Flourishing
May 11, 2026Existing alignment research is dominated by concerns about safety and preventing harm: safeguards, controllability, and compliance. This paradigm of alignment parallels early psychology's focus on mental illness: necessary but incomplete. What we call Positive Alignment is the development of AI systems that (i) actively support human and ecological flourishing in a pluralistic, polycentric, context-sensitive, and user-authored way while (ii) remaining safe and cooperative. It is a distinct and necessary agenda within AI alignment research. We argue that several existing failures of alignment (e.g., engagement hacking, loss of human autonomy, failures in truth-seeking, low epistemic humility, error correction, lack of diverse viewpoints, and being primarily reactive rather than proactive) may be better addressed through positive alignment, including cultivating virtues and maximizing human flourishing. We highlight a range of challenges, open questions, and technical directions (e.g., data filtering and upsampling, pre- and post-training, evaluations, collaborative value collection) for different phases of the LLM and agents lifecycle. We end with design principles for promoting disagreement and decentralization through contextual grounding, community customization, continual adaptation, and polycentric governance; that is, many legitimate centers of oversight rather than one institutional or moral chokepoint.
AI in a vat: Fundamental limits of efficient world modelling for agent sandboxing and interpretability
Apr 06, 2025



Recent work proposes using world models to generate controlled virtual environments in which AI agents can be tested before deployment to ensure their reliability and safety. However, accurate world models often have high computational demands that can severely restrict the scope and depth of such assessments. Inspired by the classic `brain in a vat' thought experiment, here we investigate ways of simplifying world models that remain agnostic to the AI agent under evaluation. By following principles from computational mechanics, our approach reveals a fundamental trade-off in world model construction between efficiency and interpretability, demonstrating that no single world model can optimise all desirable characteristics. Building on this trade-off, we identify procedures to build world models that either minimise memory requirements, delineate the boundaries of what is learnable, or allow tracking causes of undesirable outcomes. In doing so, this work establishes fundamental limits in world modelling, leading to actionable guidelines that inform core design choices related to effective agent evaluation.
Mobile Cellular-Connected UAVs: Reinforcement Learning for Sky Limits
Sep 21, 2020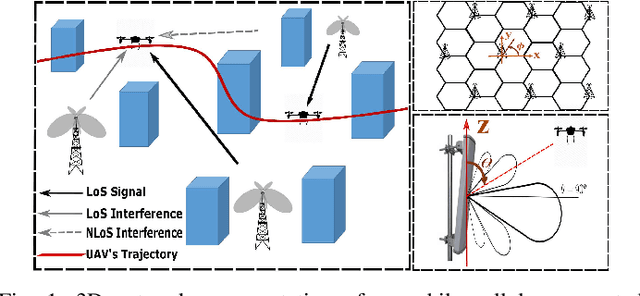
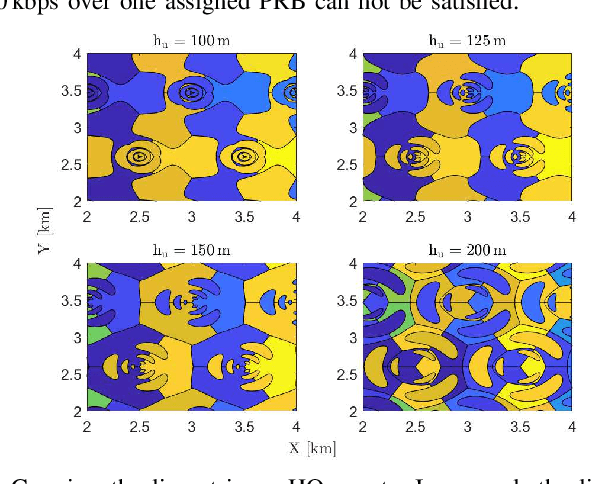
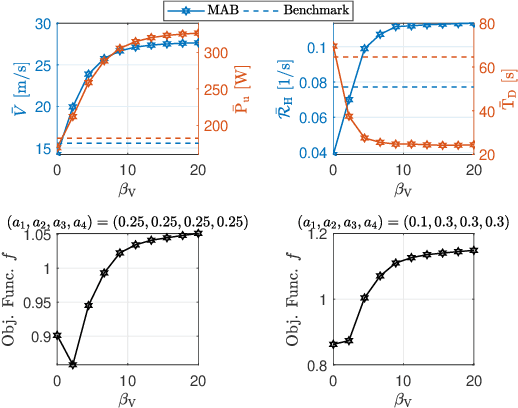
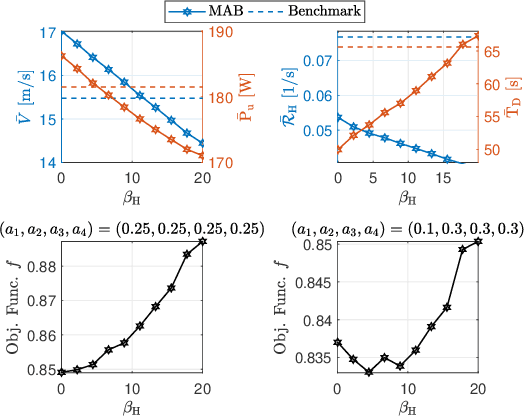
A cellular-connected unmanned aerial vehicle (UAV)faces several key challenges concerning connectivity and energy efficiency. Through a learning-based strategy, we propose a general novel multi-armed bandit (MAB) algorithm to reduce disconnectivity time, handover rate, and energy consumption of UAV by taking into account its time of task completion. By formulating the problem as a function of UAV's velocity, we show how each of these performance indicators (PIs) is improved by adopting a proper range of corresponding learning parameter, e.g. 50% reduction in HO rate as compared to a blind strategy. However, results reveal that the optimal combination of the learning parameters depends critically on any specific application and the weights of PIs on the final objective function.