 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Reinforcement Learning for Dynamic Spectrum Sharing of LTE and NR
Feb 22, 2021
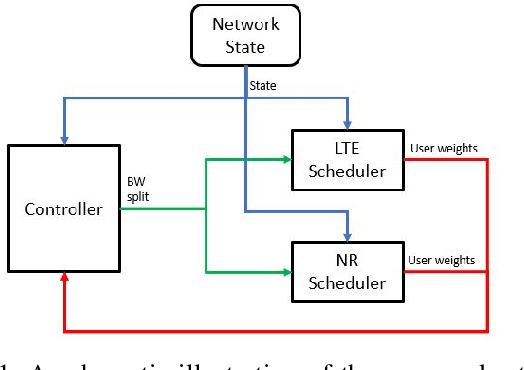
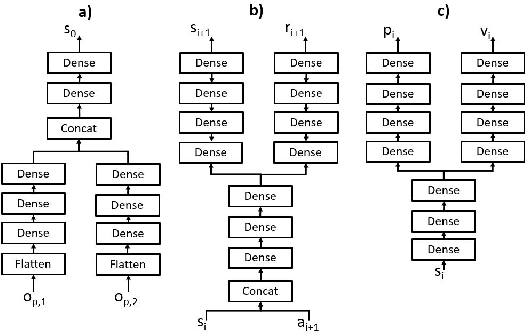
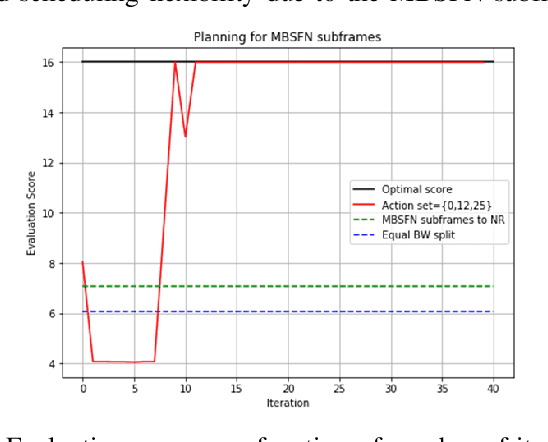
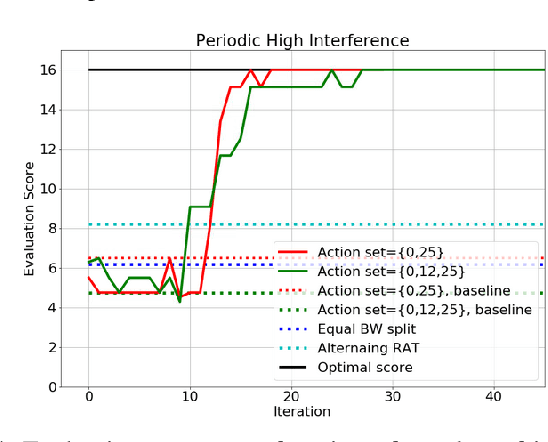
In this paper, a proactive dynamic spectrum sharing scheme between 4G and 5G systems is proposed. In particular, a controller decides on the resource split between NR and LTE every subframe while accounting for future network states such as high interference subframes and multimedia broadcast single frequency network (MBSFN) subframes. To solve this problem, a deep reinforcement learning (RL) algorithm based on Monte Carlo Tree Search (MCTS) is proposed. The introduced deep RL architecture is trained offline whereby the controller predicts a sequence of future states of the wireless access network by simulating hypothetical bandwidth splits over time starting from the current network state. The action sequence resulting in the best reward is then assigned. This is realized by predicting the quantities most directly relevant to planning, i.e., the reward, the action probabilities, and the value for each network state. Simulation results show that the proposed scheme is able to take actions while accounting for future states instead of being greedy in each subframe. The results also show that the proposed framework improves system-level performance.
LiDAR-based Recurrent 3D Semantic Segmentation with Temporal Memory Alignment
Mar 03, 2021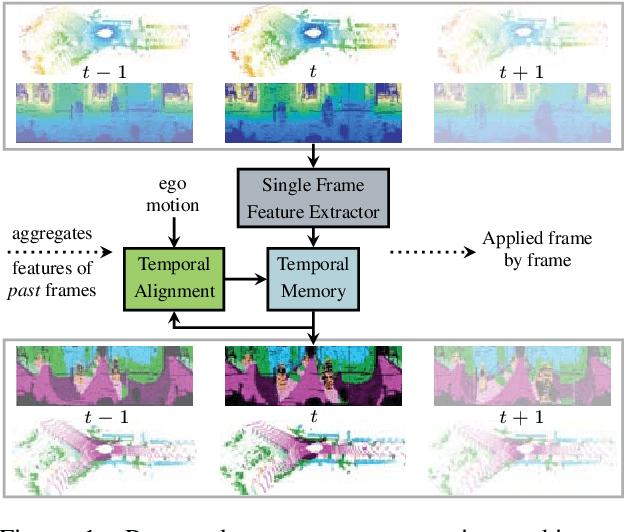
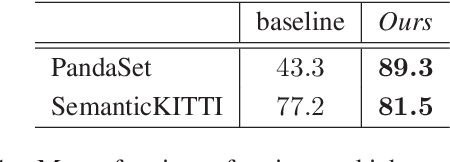
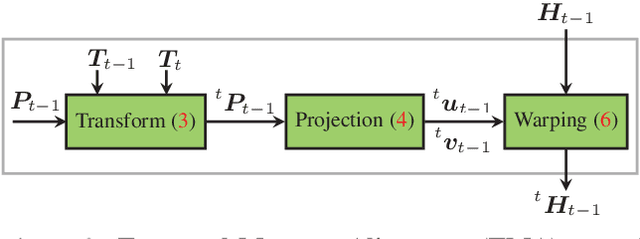
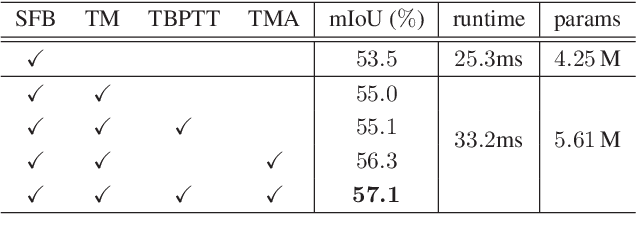
Understanding and interpreting a 3d environment is a key challenge for autonomous vehicles. Semantic segmentation of 3d point clouds combines 3d information with semantics and thereby provides a valuable contribution to this task. In many real-world applications, point clouds are generated by lidar sensors in a consecutive fashion. Working with a time series instead of single and independent frames enables the exploitation of temporal information. We therefore propose a recurrent segmentation architecture (RNN), which takes a single range image frame as input and exploits recursively aggregated temporal information. An alignment strategy, which we call Temporal Memory Alignment, uses ego motion to temporally align the memory between consecutive frames in feature space. A Residual Network and ConvGRU are investigated for the memory update. We demonstrate the benefits of the presented approach on two large-scale datasets and compare it to several stateof-the-art methods. Our approach ranks first on the SemanticKITTI multiple scan benchmark and achieves state-of-the-art performance on the single scan benchmark. In addition, the evaluation shows that the exploitation of temporal information significantly improves segmentation results compared to a single frame approach.
The Role of Edge Robotics As-a-Service in Monitoring COVID-19 Infection
Dec 09, 2020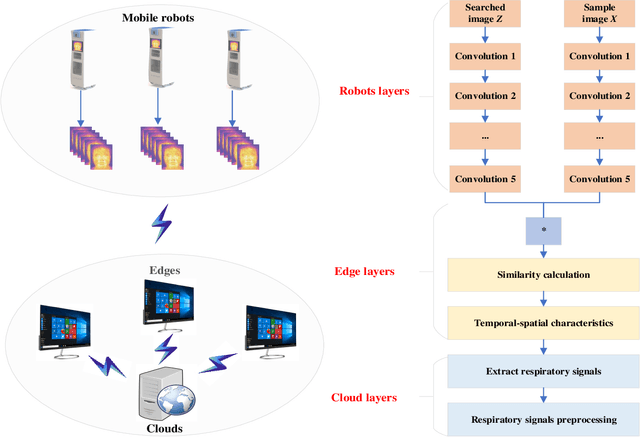
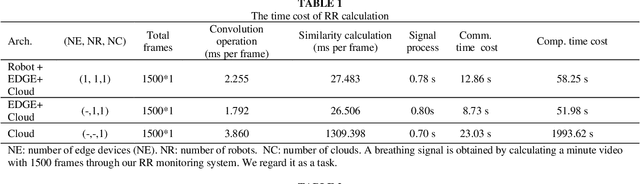
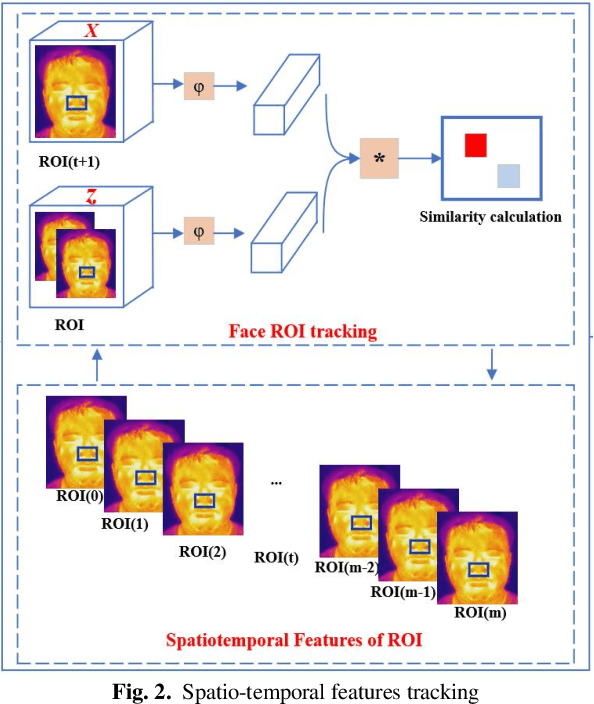
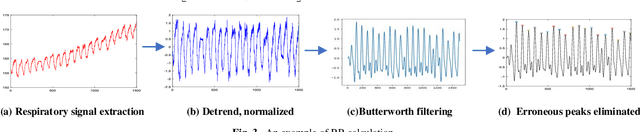
Deep learning technology has been widely used in edge computing. However, pandemics like covid-19 require deep learning capabilities at mobile devices (detect respiratory rate using mobile robotics or conduct CT scan using a mobile scanner), which are severely constrained by the limited storage and computation resources at the device level. To solve this problem, we propose a three-tier architecture, including robot layers, edge layers, and cloud layers. We adopt this architecture to design a non-contact respiratory monitoring system to break down respiratory rate calculation tasks. Experimental results of respiratory rate monitoring show that the proposed approach in this paper significantly outperforms other approaches. It is supported by computation time costs with 2.26 ms per frame, 27.48 ms per frame, 0.78 seconds for convolution operation, similarity calculation, processing one-minute length respiratory signals, respectively. And the computation time costs of our three-tier architecture are less than that of edge+cloud architecture and cloud architecture. Moreover, we use our three-tire architecture for CT image diagnosis task decomposition. The evaluation of a CT image dataset of COVID-19 proves that our three-tire architecture is useful for resolving tasks on deep learning networks by edge equipment. There are broad application scenarios in smart hospitals in the future.
Boosting One-Point Derivative-Free Online Optimization via Residual Feedback
Oct 14, 2020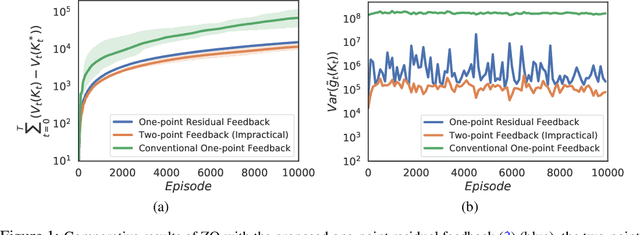
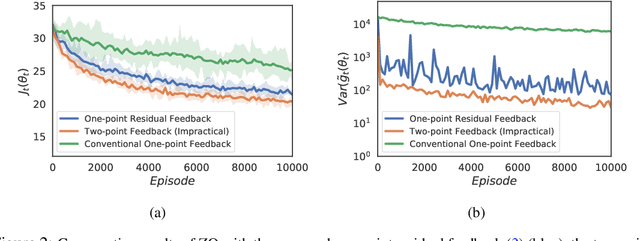
Zeroth-order optimization (ZO) typically relies on two-point feedback to estimate the unknown gradient of the objective function. Nevertheless, two-point feedback can not be used for online optimization of time-varying objective functions, where only a single query of the function value is possible at each time step. In this work, we propose a new one-point feedback method for online optimization that estimates the objective function gradient using the residual between two feedback points at consecutive time instants. Moreover, we develop regret bounds for ZO with residual feedback for both convex and nonconvex online optimization problems. Specifically, for both deterministic and stochastic problems and for both Lipschitz and smooth objective functions, we show that using residual feedback can produce gradient estimates with much smaller variance compared to conventional one-point feedback methods. As a result, our regret bounds are much tighter compared to existing regret bounds for ZO with conventional one-point feedback, which suggests that ZO with residual feedback can better track the optimizer of online optimization problems. Additionally, our regret bounds rely on weaker assumptions than those used in conventional one-point feedback methods. Numerical experiments show that ZO with residual feedback significantly outperforms existing one-point feedback methods also in practice.
PENet: Towards Precise and Efficient Image Guided Depth Completion
Mar 18, 2021



Image guided depth completion is the task of generating a dense depth map from a sparse depth map and a high quality image. In this task, how to fuse the color and depth modalities plays an important role in achieving good performance. This paper proposes a two-branch backbone that consists of a color-dominant branch and a depth-dominant branch to exploit and fuse two modalities thoroughly. More specifically, one branch inputs a color image and a sparse depth map to predict a dense depth map. The other branch takes as inputs the sparse depth map and the previously predicted depth map, and outputs a dense depth map as well. The depth maps predicted from two branches are complimentary to each other and therefore they are adaptively fused. In addition, we also propose a simple geometric convolutional layer to encode 3D geometric cues. The geometric encoded backbone conducts the fusion of different modalities at multiple stages, leading to good depth completion results. We further implement a dilated and accelerated CSPN++ to refine the fused depth map efficiently. The proposed full model ranks 1st in the KITTI depth completion online leaderboard at the time of submission. It also infers much faster than most of the top ranked methods. The code of this work is available at https://github.com/JUGGHM/PENet_ICRA2021.
End-to-End Multi-Channel Transformer for Speech Recognition
Feb 08, 2021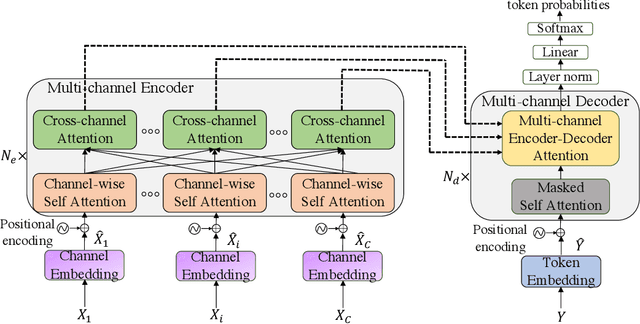
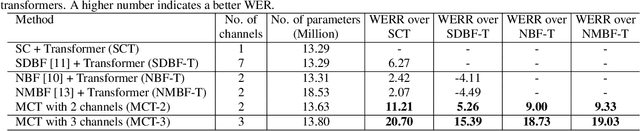
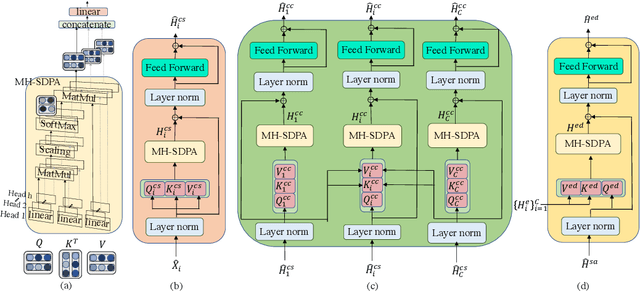

Transformers are powerful neural architectures that allow integrating different modalities using attention mechanisms. In this paper, we leverage the neural transformer architectures for multi-channel speech recognition systems, where the spectral and spatial information collected from different microphones are integrated using attention layers. Our multi-channel transformer network mainly consists of three parts: channel-wise self attention layers (CSA), cross-channel attention layers (CCA), and multi-channel encoder-decoder attention layers (EDA). The CSA and CCA layers encode the contextual relationship within and between channels and across time, respectively. The channel-attended outputs from CSA and CCA are then fed into the EDA layers to help decode the next token given the preceding ones. The experiments show that in a far-field in-house dataset, our method outperforms the baseline single-channel transformer, as well as the super-directive and neural beamformers cascaded with the transformers.
Thinking Deeply with Recurrence: Generalizing from Easy to Hard Sequential Reasoning Problems
Feb 22, 2021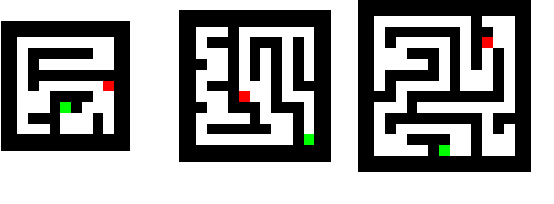
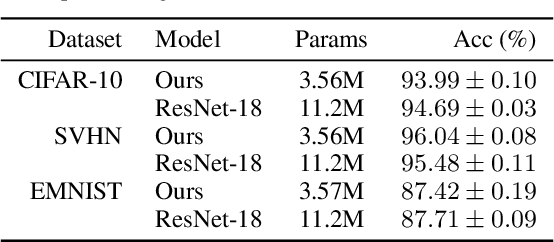
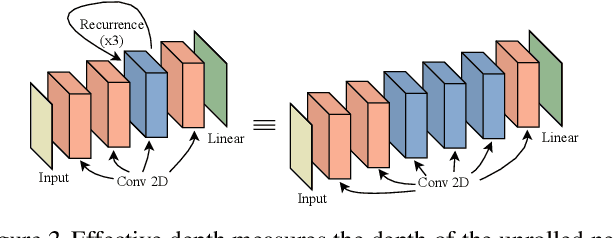

Deep neural networks are powerful machines for visual pattern recognition, but reasoning tasks that are easy for humans may still be difficult for neural models. Humans can extrapolate simple reasoning strategies to solve difficult problems using long sequences of abstract manipulations, i.e., harder problems are solved by thinking for longer. In contrast, the sequential computing budget of feed-forward networks is limited by their depth, and networks trained on simple problems have no way of extending their reasoning capabilities without retraining. In this work, we observe that recurrent networks have the uncanny ability to closely emulate the behavior of non-recurrent deep models, often doing so with far fewer parameters, on both image classification and maze solving tasks. We also explore whether recurrent networks can make the generalization leap from simple problems to hard problems simply by increasing the number of recurrent iterations used as test time. To this end, we show that recurrent networks that are trained to solve simple mazes with few recurrent steps can indeed solve much more complex problems simply by performing additional recurrences during inference.
Automating Program Structure Classification
Jan 15, 2021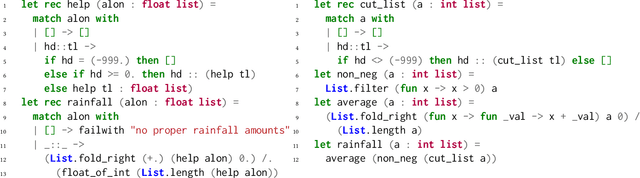

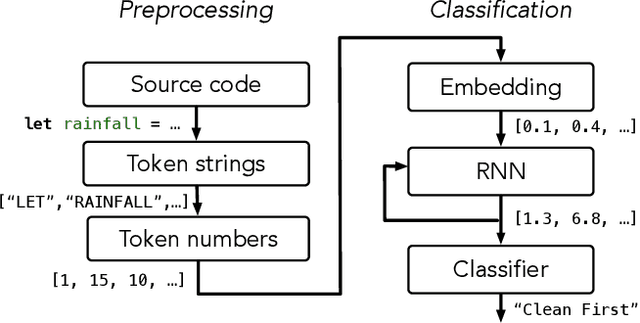
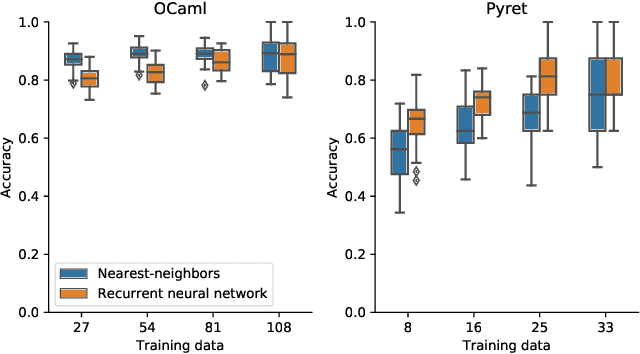
When students write programs, their program structure provides insight into their learning process. However, analyzing program structure by hand is time-consuming, and teachers need better tools for computer-assisted exploration of student solutions. As a first step towards an education-oriented program analysis toolkit, we show how supervised machine learning methods can automatically classify student programs into a predetermined set of high-level structures. We evaluate two models on classifying student solutions to the Rainfall problem: a nearest-neighbors classifier using syntax tree edit distance and a recurrent neural network. We demonstrate that these models can achieve 91% classification accuracy when trained on 108 programs. We further explore the generality, trade-offs, and failure cases of each model.
Robust learning under clean-label attack
Mar 03, 2021
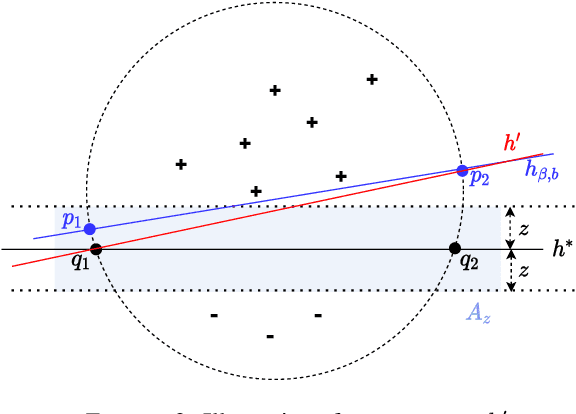
We study the problem of robust learning under clean-label data-poisoning attacks, where the attacker injects (an arbitrary set of) correctly-labeled examples to the training set to fool the algorithm into making mistakes on specific test instances at test time. The learning goal is to minimize the attackable rate (the probability mass of attackable test instances), which is more difficult than optimal PAC learning. As we show, any robust algorithm with diminishing attackable rate can achieve the optimal dependence on $\epsilon$ in its PAC sample complexity, i.e., $O(1/\epsilon)$. On the other hand, the attackable rate might be large even for some optimal PAC learners, e.g., SVM for linear classifiers. Furthermore, we show that the class of linear hypotheses is not robustly learnable when the data distribution has zero margin and is robustly learnable in the case of positive margin but requires sample complexity exponential in the dimension. For a general hypothesis class with bounded VC dimension, if the attacker is limited to add at most $t>0$ poison examples, the optimal robust learning sample complexity grows almost linearly with $t$.
Dynamic Prediction Length for Time Series with Sequence to Sequence Networks
Jul 02, 2018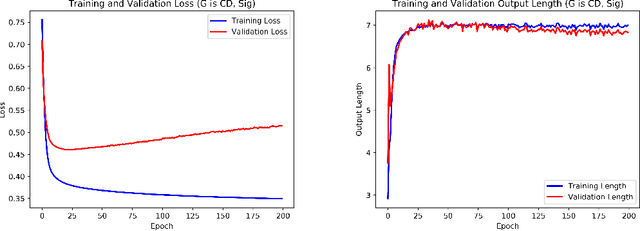
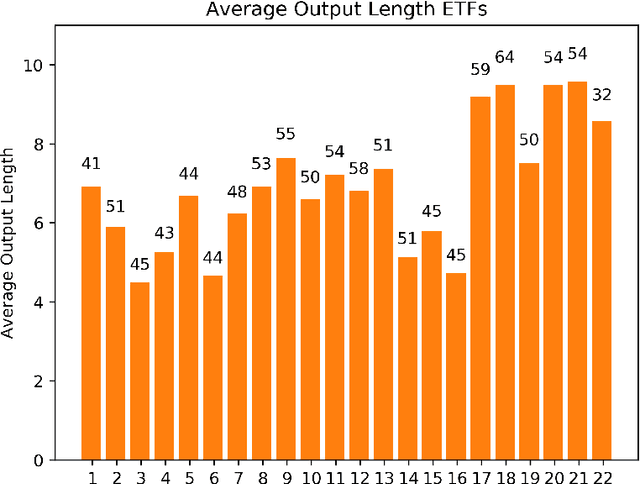
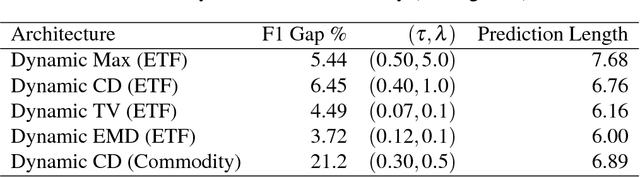
Recurrent neural networks and sequence to sequence models require a predetermined length for prediction output length. Our model addresses this by allowing the network to predict a variable length output in inference. A new loss function with a tailored gradient computation is developed that trades off prediction accuracy and output length. The model utilizes a function to determine whether a particular output at a time should be evaluated or not given a predetermined threshold. We evaluate the model on the problem of predicting the prices of securities. We find that the model makes longer predictions for more stable securities and it naturally balances prediction accuracy and length.